This article will be about this nuance.
I run selenium as usual, and after the first click on the link where the required table with the election results of the Republic of Tatarstan is located, it crashes

As you understand, the nuance lies in the fact that after each click on the link, a captcha appears.
After analyzing the structure of the site, it was found that the number of links reaches about 30 thousand.
I had no choice but to search the Internet for ways to recognize captcha. Found one service
+ Captcha is recognized 100%, just like a person
- The average recognition time is 9 seconds, which is very long, since we have about 30 thousand different links, which we need to follow and recognize the captcha.
I immediately gave up on this idea. After several attempts to get the captcha, I noticed that it does not change much, all the same black numbers on a green background.
And since I have long wanted to touch the "vision computer" with my hands, I decided that I had a great chance to try everyone's favorite MNIST problem myself.
It was already 17:00 on the clock, and I started looking for pre-trained models for recognizing numbers. After checking them on this captcha, the accuracy did not satisfy me - well, it's time to collect pictures and train your neural network.
First, you need to collect a training sample.
I open the Chrome web driver and screen 1000 captchas in my folder.
from selenium import webdriver
i = 1000
driver = webdriver.Chrome('/Users/aleksejkudrasov/Downloads/chromedriver')
while i>0:
driver.get('http://www.vybory.izbirkom.ru/region/izbirkom?action=show&vrn=4274007421995®ion=27&prver=0&pronetvd=0')
time.sleep(0.5)
with open(str(i)+'.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
i = i - 1Since we have only two colors, I converted our captchas to bw:
from operator import itemgetter, attrgetter
from PIL import Image
import glob
list_img = glob.glob('path/*.png')
for img in list_img:
im = Image.open(img)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
#
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
im2.save(img)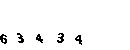
Now we need to cut our captchas into numbers and convert them to a single size of 10 * 10.
First, we cut the captcha into numbers, then, since the captcha is shifted along the OY axis, we need to crop all unnecessary and rotate the image by 90 °.
def crop(im2):
inletter = False
foundletter = False
start = 0
end = 0
count = 0
letters = []
name_slise=0
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
# OX
if foundletter == False and inletter == True:
foundletter = True
start = y
# OX
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
for letter in letters:
#
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
# 90°
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
#
for y in range(im3.size[0]): # slice across
for x in range(im3.size[1]): # slice down
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
#
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
#
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
resized_img.save(path+name_slise+'.png')
name_slise+=1
“It's already time, 18:00, it's time to finish this problem,” I thought, scattering the numbers in the folders with their numbers along the way.
We declare a simple model that accepts an expanded matrix of our picture as input.
To do this, create an input layer of 100 neurons, since the image size is 10 * 10. As an output layer there are 10 neurons, each of which corresponds to a digit from 0 to 9.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
def mnist_make_model(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(image_w*image_h, activation='relu', input_shape=(image_h*image_h)))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
return model
We split our data into training and test sets:
list_folder = ['0','1','2','3','4','5','6','7','8','9']
X_Digit = []
y_digit = []
for folder in list_folder:
for name in glob.glob('path'+folder+'/*.png'):
im2 = Image.open(name)
X_Digit.append(np.array(im2))
y_digit.append(folder)We split it into training and test set:
from sklearn.model_selection import train_test_split
X_Digit = np.array(X_Digit)
y_digit = np.array(y_digit)
X_train, X_test, y_train, y_test = train_test_split(X_Digit, y_digit, test_size=0.15, random_state=42)
train_data = X_train.reshape(X_train.shape[0], 10*10) # 100
test_data = X_test.reshape(X_test.shape[0], 10*10) # 100
# 10
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
We train the model.
Empirically select the parameters of the number of epochs and the size of the "batch":
model = mnist_make_model(10,10)
model.fit(train_data, train_labels_cat, epochs=20, batch_size=32, verbose=1, validation_data=(test_data, test_labels_cat))
We save the weights:
model.save_weights("model.h5")
The accuracy at the 11th epoch turned out to be excellent: accuracy = 1.0000. Satisfied, I'm going home to rest at 19:00, tomorrow I still need to write a parser to collect information from the CEC website.
Morning the next day.
The matter remained small, it remains to go through all the pages on the CEC website and pick up the data:
Load the weights of the trained model:
model = mnist_make_model(10,10)
model.load_weights('model.h5')
We write a function to save captcha:
def get_captcha(driver):
with open('snt.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
im2 = Image.open('path/snt.png')
return im2
Let's write a function for captcha prediction:
def crop_predict(im):
list_cap = []
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
count = 0
letters = []
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
for letter in letters:
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
for y in range(im3.size[0]):
for x in range(im3.size[1]):
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
img_arr = np.array(resized_img)/255
img_arr = img_arr.reshape((1, 10*10))
list_cap.append(model.predict_classes([img_arr])[0])
return ''.join([str(elem) for elem in list_cap])
Add a function that downloads the table:
def get_table(driver):
html = driver.page_source #
soup = BeautifulSoup(html, 'html.parser') # " "
table_result = [] #
tbody = soup.find_all('tbody') #
list_tr = tbody[1].find_all('tr') #
ful_name = list_tr[0].text #
for table in list_tr[3].find_all('table'): #
if len(table.find_all('tr'))>5: #
for tr in table.find_all('tr'): #
snt_tr = []#
for td in tr.find_all('td'):
snt_tr.append(td.text.strip())#
table_result.append(snt_tr)#
return (ful_name, pd.DataFrame(table_result, columns = ['index', 'name','count']))
We collect all links for September 13:
df_table = []
driver.get('http://www.vybory.izbirkom.ru')
driver.find_element_by_xpath('/html/body/table[2]/tbody/tr[2]/td/center/table/tbody/tr[2]/td/div/table/tbody/tr[3]/td[3]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
list_a = soup.find_all('table')[1].find_all('a')
for a in list_a:
name = a.text
link = a['href']
df_table.append([name,link])
df_table = pd.DataFrame(df_table, columns = ['name','link'])
By 13:00, I finish writing the code with a traversal of all pages:
result_df = []
for index, line in df_table.iterrows():#
driver.get(line['link'])#
time.sleep(0.6)
try:#
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:#
pass
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
if soup.find('select') is None:#
time.sleep(0.6)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
for i in range(len(soup.find_all('tr'))):#
if '\n \n' == soup.find_all('tr')[i].text:# ,
rez_link = soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
time.sleep(0.6)
try:
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)#
head_name = line['name']
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
else:# ,
options = soup.find('select').find_all('option')
for option in options:
if option.text == '---':#
continue
else:
link = option['value']
head_name = option.text
driver.get(link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html2 = driver.page_source
second_soup = BeautifulSoup(html2, 'html.parser')
for i in range(len(second_soup.find_all('tr'))):
if '\n \n' == second_soup.find_all('tr')[i].text:
rez_link = second_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
if second_soup.find('select') is None:
continue
else:
options_2 = second_soup.find('select').find_all('option')
for option_2 in options_2:
if option_2.text == '---':
continue
else:
link_2 = option_2['value']
child_name = option_2.text
driver.get(link_2)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html3 = driver.page_source
thrid_soup = BeautifulSoup(html3, 'html.parser')
for i in range(len(thrid_soup.find_all('tr'))):
if '\n \n' == thrid_soup.find_all('tr')[i].text:
rez_link = thrid_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
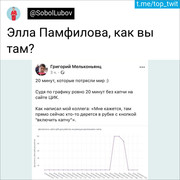
And then comes the tweet that changed my life