
DBMS in this respect work according to the same principles - " they said to dig, and I dig ". Your request can not only slow down neighboring processes, constantly occupying processor resources, but also "drop" the entire database entirely, "eating" all available memory. Therefore, protecting against infinite recursion is the responsibility of the developer himself.
In PostgreSQL, the ability to use recursive queries through has
WITH RECURSIVEappeared since time immemorial in version 8.4, but you can still regularly encounter potentially vulnerable "defenseless" queries. How to save yourself from these kinds of problems?
Don't write recursive queries
And write non-recursive. Respectfully yours K.O.In fact, PostgreSQL provides a fairly large amount of functionality that you can use to avoid recursion.
Use a fundamentally different approach to the task
Sometimes you can just look at the problem "from the other side". I gave an example of such a situation in the article "SQL HowTo: 1000 and one way of aggregation" - multiplication of a set of numbers without using custom aggregate functions:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Such a request can be replaced with a variant from experts in mathematics:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Use generate_series instead of loops
Let's say we are faced with the task of generating all possible prefixes for a string
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Exactly, do you need recursion here? .. If you use
LATERALand generate_series, then even CTEs are not needed:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Change the database structure
For example, you have a table of forum posts with links to who replied to, or a thread on a social network :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);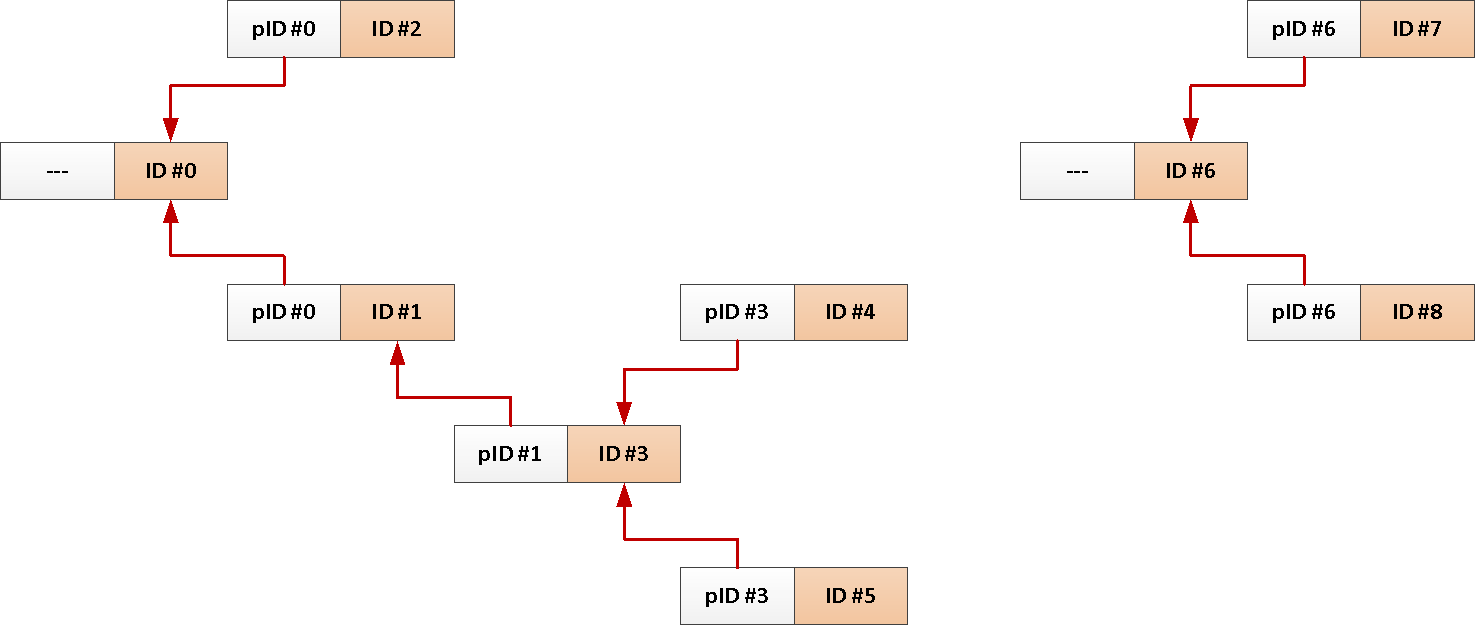
Well, a typical request to download all messages on one topic looks something like this:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;But since we always need the whole subject from the root message, why not add its identifier to each post automatically?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();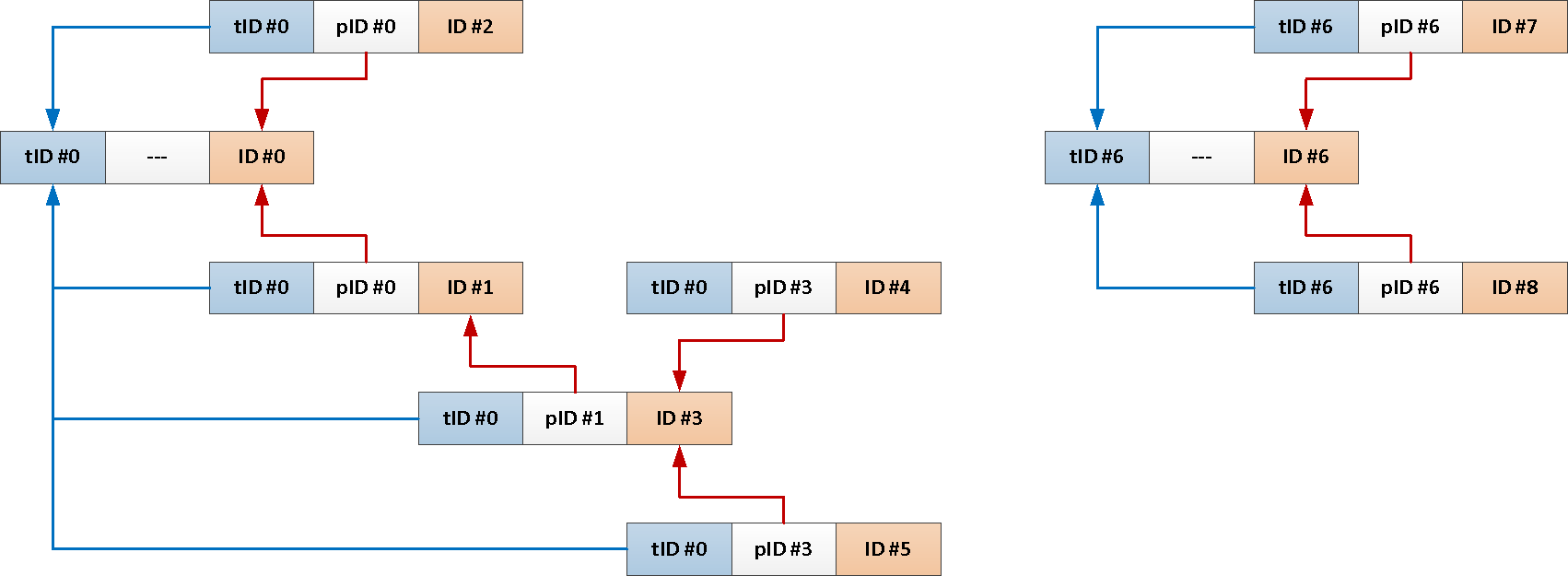
Now our entire recursive query can be reduced to just this:
SELECT
*
FROM
message
WHERE
theme_id = $1;Use applied "constraints"
If we are unable to change the structure of the database for some reason, let's see what we can rely on so that even the presence of an error in the data does not lead to infinite recursion.
Recursion "depth" counter
We just increase the counter by one at each step of the recursion until the limit is reached, which we consider to be obviously inadequate:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Pro: When we try to loop, we will still make no more than the specified limit of iterations "in depth".
Contra: There is no guarantee that we will not process the same record again - for example, at depths of 15 and 25, and then there will be every +10. And no one promised anything about "breadth".
Formally, such a recursion will not be infinite, but if at each step the number of records increases exponentially, we all know well how it ends ...

Guardian of the "way"
One by one we add all the object identifiers we encountered along the recursion path into an array, which is a unique "path" to it:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Pro: If there is a loop in the data, we absolutely will not re-process the same record within the same path.
Contra: But at the same time we can bypass, literally, all the records without repeating.
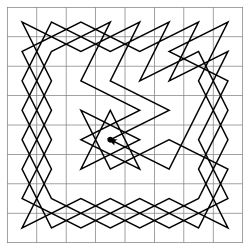
Path length limitation
To avoid the situation of recursion "wandering" at an incomprehensible depth, we can combine the two previous methods. Or, if we do not want to support unnecessary fields, supplement the recursion continuation condition with an estimate of the path length:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Choose the method to your taste!