
Hello, Khabrovites! We've decoded for you a part of the MongoDB tutorial from Evgeny Aristov, a 20-year-old developer and author of the online course "Non-Relational Databases" . The material, like the course itself, will be useful to specialists who come across NoSQL and who want to learn how to optimize their databases and work with them.
Why replicate?
- High availability. A backup is good, but it takes time to deploy.
- Horizontal scaling. In the case when the server runs out of physical cores and memory.
- It is better to make a backup from a replica, and not from a master.
- Load geo-distribution.
In MongoDB, there are not many types of replication out of the box: the most relevant at the moment is Replicaset, and the second is Master-slave, which is limited to version 3.6 and will not be discussed in detail in this article.
# 1. Writing and reading from the main server
We have a client application driver that reads and writes to the Primary node. Further, according to the replication protocol, the information that is written to the Primary node is sent to the Secondary nodes.

# 2. Reading from a cue
An alternative to reading and writing from Primary is when the driver can read information from Secondary. In this case, the settings can be different, for example, "it is preferable to read information from Secondary, and then from Primary" or "read information from the nearest node on the network map", etc. Such configuration options are used more often than the first replication option, where everything goes through the Primary.

3 ways to make a replica readable:
- Specify
db.slaveOk() - Specify the required parameters in the driver connection string
- Specify everything, and then write more precisely in the query itself, for example, read from Secondary in the South region:
db.collection.find({}).readPref( “secondary”, [ { “region”: “South”} ] )
Replica read problems
- Since the recording is asynchronous, it can already be made on the Primary, but not reach the Secondary, so the old data from the Secondary will be read.
- , , .
, . MongoDB , , , . - , () — «».
A) Nodes "listen" to each other, this connection is called Heartbeat. That is, each node is constantly checked by others for the subject of "living / non-living", in order to take some action if something happens.

B) One Secondary node is changed to Arbiter. This is a very lightweight application, runs like Mongo, practically does not eat resources and is responsible for determining which node to recognize as the main one at the time of voting. And this is generally the recommended configuration.
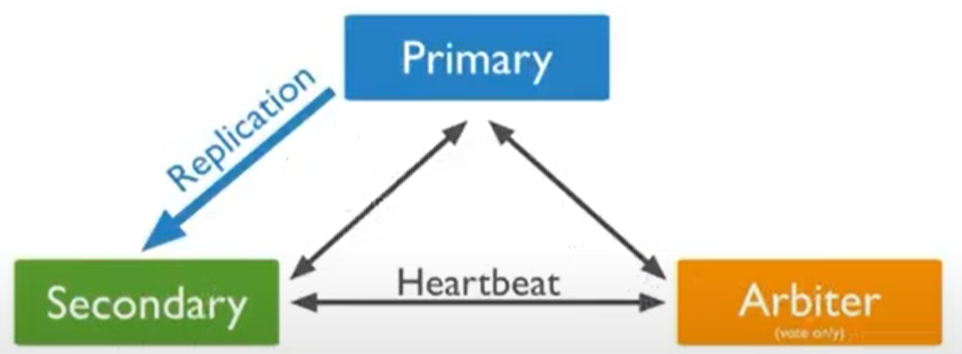
The main features of this configuration
- Asynchronous replication
- The arbiter is data-free and therefore very lightweight
- Primary can become Secondary and vice versa. The Arbiter cannot become either Primary or Secondary
- The maximum number of replies is 50 and only 7 of them are eligible to vote
- Arbiter Primary Secondary, , .. , Arbiter .
If you are interested in learning more about the clustering capabilities of MongoDB, you can watch a recording of the entire demo lesson here . In the lesson, Evgeny Aristov demonstrates the differences between Replicaset and Master-slave, explains the quorum process, scaling, sharding and the correct selection of the key to sharding.
Exploring MongoDB's capabilities is part of the Non-Relational Databases Online Course. The course is intended for developers, administrators, and other professionals who come across NoSQL. In the classroom, students in practice master the most relevant tools today: Cassandra, MongoDB, Redis, ClickHouse, Tarantool, Kafka, Neo4j, RabbitMQ.
The start is already on September 30, but during the first month you can join the group. Study the program, go throughentrance test and join!