- Hello! I will tell you what issues you have to solve when you need to prepare your service for loads of several hundred gigabits, or even terabits per second. We first encountered such a problem in 2018, when we were preparing for the broadcasts of the FIFA World Cup.
Let's start with what streaming protocols are and how they work - the most superficial overview option.

Any streaming protocol is based on a manifest or playlist. It is a small text file that contains meta information about the content. It describes the type of content - live broadcast or VoD broadcast (video on demand). For example, in the case of a live it is a football match or an online conference, as we have now with you, and in the case of VoD, your content is prepared in advance and lies on your servers, ready for distribution to users. The same file describes the duration of the content, information about DRM.

It also describes content variations - video tracks, audio tracks, subtitles. Video tracks can be represented in different codecs. For example, universal H.264 is supported on any device. With it, you can play videos on any iron in your home. Or there are more modern and more efficient HEVC and VP9 codecs that let you stream 4K HDR images.
Audio tracks can also be presented in different codecs with different bitrates. And there may be several of them - the original audio track of the film in English, translation into Russian, intershum, or, for example, a recording of a sports event directly from the stadium without commentators.

What does the player do with all this? The player's task is, first of all, to select those variations of content that it can play, simply because not all codecs are universal, not all can be played on a specific device.
After that, he needs to select the quality of video and audio from which he will start playing. He can do this based on the conditions of the network, if he knows them, or on the basis of some very simple heuristic. For example, start playing with low quality and, if the network allows, slowly increase the resolution.
Also at this stage, he chooses the audio track from which he will start playing. Suppose you have English in your operating system. Then he can choose the English audio track by default. Perhaps it will be more convenient for you.
After that, it begins to generate links to video and audio segments. In fact, these are regular HTTP links, the same as in all other scenarios on the Internet. And he starts downloading video and audio segments, putting them into the buffer one after another and playing seamlessly. Such video segments are usually 2, 4, 6 seconds long, maybe 10 seconds depending on your service.

What are the important points here that we need to think about when we design our CDN? First of all, we have a user session.
We can't just give a file to a user and forget about that user. He constantly comes back and downloads new and new segments to his buffer.
It is important to understand here that the server response time also matters. If we are showing some kind of live broadcast in real time, then we cannot make a large buffer simply because the user wants to watch the video as close to real time as possible. In principle, your buffer cannot be large. Accordingly, if the server does not have time to respond while the user has time to view the content, the video will simply freeze at some point. Plus, the content is pretty heavyweight. Standard bitrate for Full HD 1080p is 3-5 Mbps. Accordingly, on one gigabit server, you cannot serve more than 200 users at the same time. And this is a perfect picture, because, as a rule, users do not follow their requests evenly over time.

At what point does a user generally interact with your CDN? Interaction occurs mainly in two places: when the player downloads the manifest (playlist), and when it downloads segments.
We have already talked about manifests, these are small text files. There are no particular problems with the distribution of such files. If you want, distribute them from at least one server. And if they are segments, then they make up the majority of your traffic. We will talk about them.
The task of our entire system is reduced to the fact that we want to form the correct link to these segments and substitute the correct domain of some of our CDN host there. At this point, we use the following strategy: immediately in the playlist we give the desired CDN host, where the user will go. This approach is devoid of many disadvantages, but has one important nuance. You need to ensure that you have a mechanism to take the user away from one host to another seamlessly during playback without interrupting the viewing. In fact, all modern streaming protocols have this capability, both HLS and DASH support it. A nuance: quite often, even in very popular open source libraries, such a possibility is not implemented, although it exists by the standard. We ourselves had to send bundles to the Shaka open source library,it is javascript, used for web player, for playing DASH.
There is one more scheme - anycast-scheme, when you use one single domain and give it in all links. In this case, you do not need to think about any nuances - you give away one domain, and everyone is happy. (...)
Now let's talk about how we will form our links.
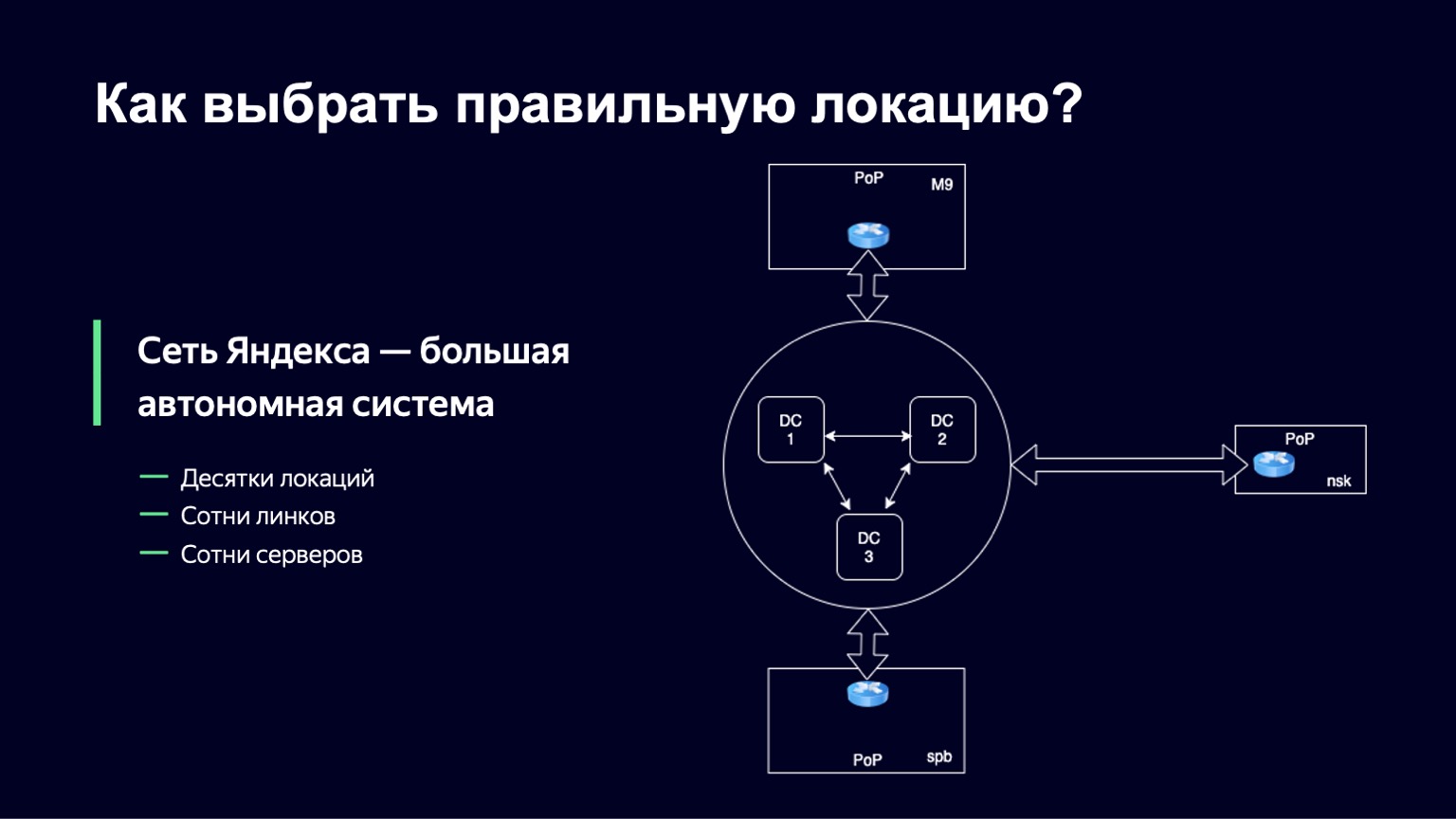
From a network point of view, any large company is organized as an autonomous system, and often not even one. In fact, an autonomous system is a system of IP networks and routers that are controlled by a single operator and provide a single routing policy with the external network, with the Internet. Yandex is no exception. The Yandex network is also an autonomous system, and communication with other autonomous systems takes place outside Yandex data centers at points of presence. Physical cables of Yandex, physical cables of other operators come to these points of presence, and they are switched on site, on iron equipment. It is at such points that we have the opportunity to put several of our servers, hard drives, SSDs. This is where we will direct user traffic.
We will call this set of servers a location. And in each such location, we have a unique identifier. We will use it as part of the domain name of the hosts on this site and just to uniquely identify it.
There are several dozen such sites in Yandex, there are several hundred servers on them, and links from several operators come to each location, so we also have about several hundred links.
How will we choose which location to send a particular user to?

There are not very many options at this stage. We can only use the IP address to make decisions. A separate Yandex Traffic Team helps us with this, which knows everything about how traffic and network work in the company, and it is she who collects the routes of other operators so that we can use this knowledge in the process of balancing users.
It collects a set of routes using BGP. We will not talk about BGP in detail, it is a protocol that allows network participants at the borders of their autonomous systems to announce what routes their autonomous system can serve. The Traffic Team collects all this information, aggregates, analyzes and builds a complete map of the entire network, which we use for balancing.
We receive from the Traffic Team a set of IP networks and links through which we can serve clients. Next, we need to understand which IP subnet is suitable for a particular user.
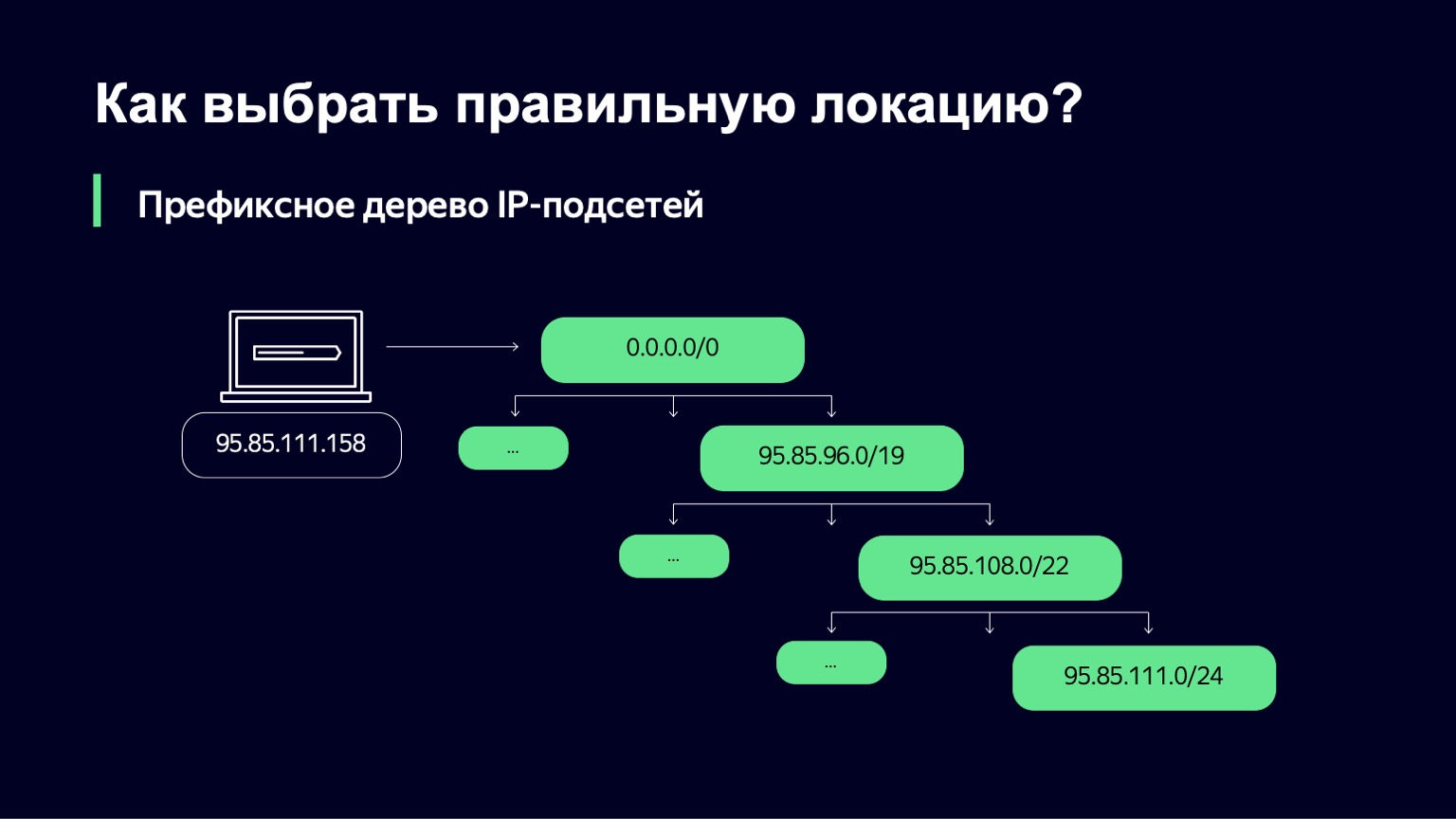
We do this in a fairly simple way - we build a prefix tree. And then our task is to use the user's IP address as a key to find which subnet most closely matches this IP address.
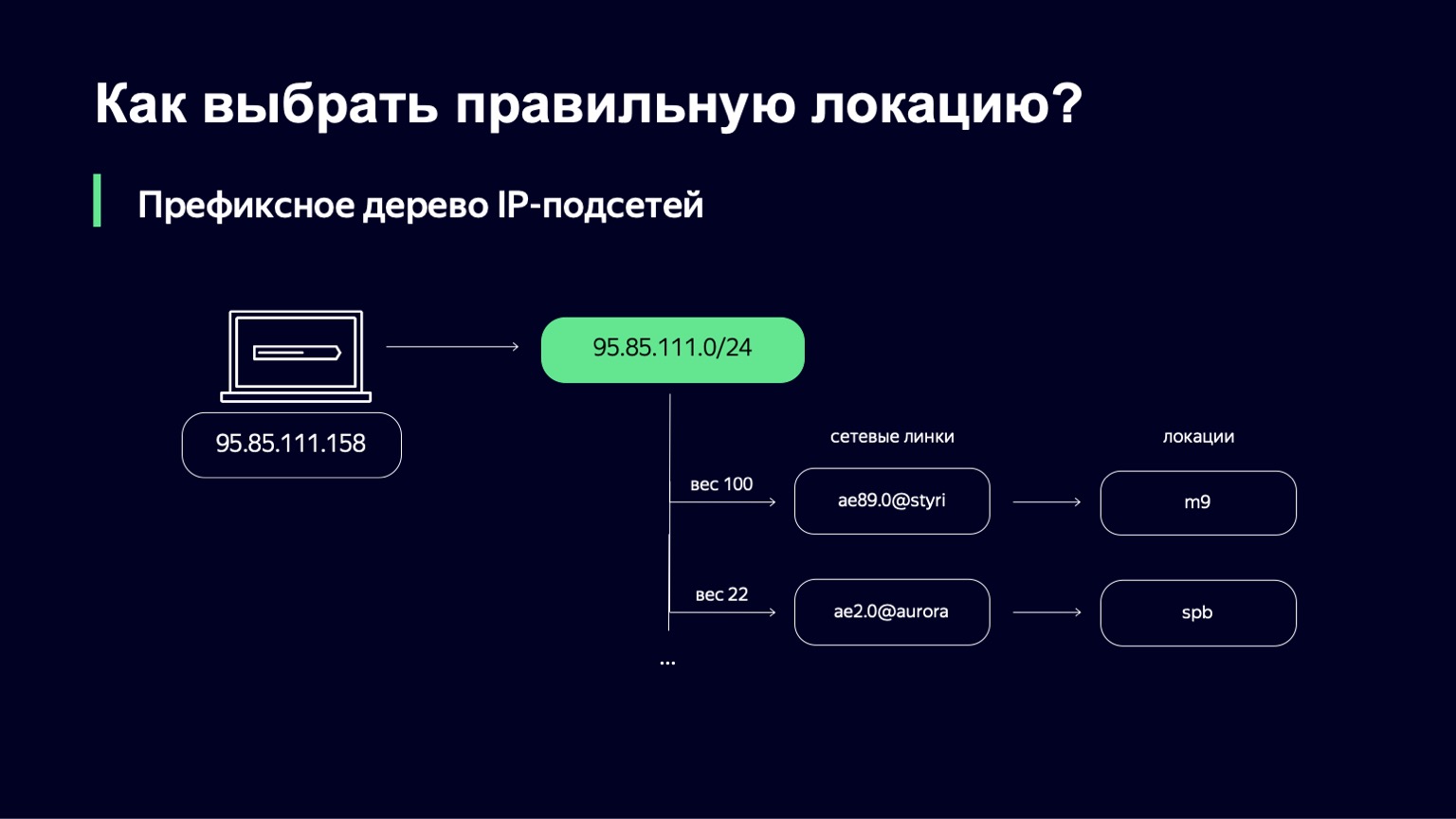
When we found it, we have a list of links, their weights, and by links we can uniquely determine the location where we will send the user.

What is the weight in this place? This is a metric that allows you to manage the distribution of users across different locations. We can have links, for example, of different capacities. We can have a 100 Gigabit link and a 10 Gigabit link on the same site. Obviously, we want to send more users to the first link, because it is more capacious. This weight takes into account the network topology, because the Internet is a complex graph of interconnected network equipment, your traffic can go along different paths, and this topology must also be taken into account.
Be sure to watch how users actually download data. This can be done on both the server and client side. On the server, we are actively collecting user connections in the TCP info logs, looking at the round-trip time. From the user side, we actively collect browser and player perf logs. These perf logs contain detailed information about how the files were downloaded from our CDN.
If we analyze all this, aggregate, then with the help of this data we can improve the weights that were selected at the first stage by the Traffic Team.

Let's say we have selected a link. Can we send users there right at this stage? We cannot, because the weight is quite static over a long period of time, and it does not take into account any real dynamics of the load. We want to determine in real time whether we can now use a link that is, say, 80% loaded, when there is a slightly lower priority link nearby that is only 10% loaded. Most likely, in this case, we just want to use the second.

What else needs to be taken into account in this place? We must take into account the bandwidth of the link, understand its current status. It may work or be technically defective. Or, maybe we want to take it to the service in order not to let users there and serve it, expand it, for example. We must always take into account the current load of this link.
There are some interesting nuances here. You can collect information about link loading at several points - for example, on network equipment. This is the most accurate way, but its problem is that on the network equipment you cannot get a fast update period for this download. For example, in Yandex, the network equipment is quite varied, and we cannot collect this data more often than once a minute. If the system is fairly stable in terms of load, this is not a problem at all. Everything will work great. But as soon as you have sudden influxes of load, you simply do not have time to react, and this leads, for example, to package drops.
On the other hand, you know how many bytes were sent to the user. You can collect this information on the distributing machines themselves, make a byte counter directly. But it won't be that accurate. Why?
There are other users on our CDN. We are not the only service that uses these dispensing machines. And against the background of our load, the load of other services is not so significant. But even against our background, it can be quite noticeable. Their distributions do not go through our circuit, so we cannot control this traffic.
Another point: even if you think on the sending machine that you have sent traffic to one specific link, this is far from a fact, because BGP as a protocol does not give you such a guarantee. And there are ways to increase the likelihood that you will guess, but that is a subject for another discussion.

Let's say we calculated the metrics, collected everything. Now we need an algorithm for making a decision when balancing. It must have four important properties:
- Provide the link bandwidth.
- Prevent link overload, simply because if you have loaded a link at 95% or 98%, then the buffers on the network equipment begin to overflow, packet drops, retransmits begin, and users do not get anything good from this.
- To warn "drank" loads, we'll talk about this a little later.
“In an ideal world, it would be great if we could learn to recycle a link to a certain level that we think is right. For example, 85% download.

We took the following idea as a basis. We have two different classes of user sessions. The first class is new sessions, when the user has just opened the movie, has not watched anything yet, and we are trying to figure out where to send it. Or the second class, when we have a current session, the user is already served on the link, occupies a certain part of the bandwidth, is served on a specific server.
What are we going to do with them? We introduce one probabilistic value for each such class of the session. We will have a value called Slowdown, which determines the percentage of new sessions that we will not allow on this link. If Slowdown is zero, then we accept all new sessions, and if it is 50%, then, roughly speaking, every second session we refuse to serve on this link. At the same time, our balancing algorithm at a higher level will check alternatives for this user. Drop is the same, only for current sessions. We can take some of the user sessions off the site somewhere else.
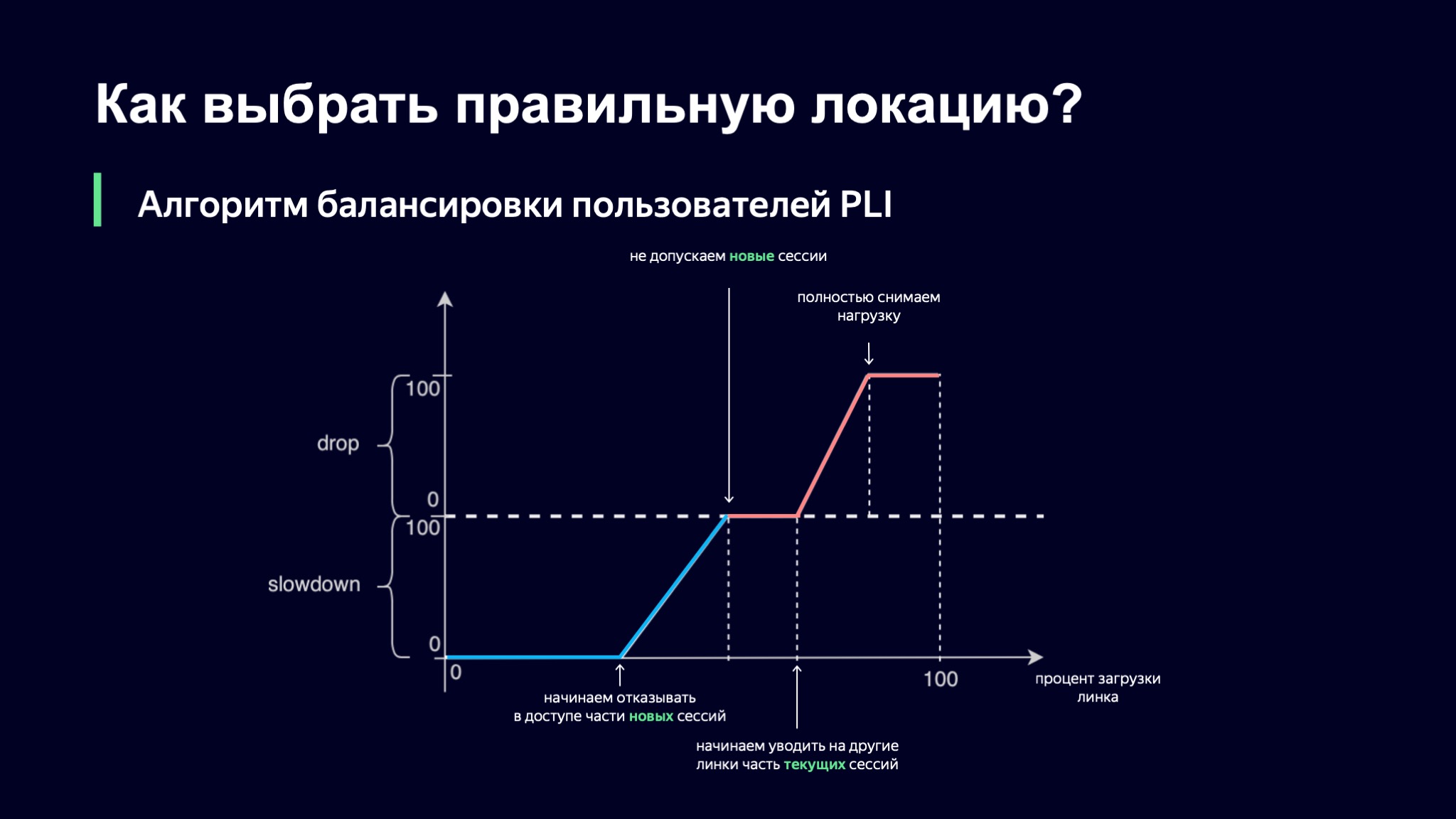
How do we choose what the value of our probabilistic metrics will be? Let's take the percentage of the link load as a basis, and then our first idea was this: let's use piecewise linear interpolation.
We took such a function, which has several refraction points, and we look at the value of our coefficients using it. If the download level of the link is minimal, then everything is fine, Slowdown and Drop are equal to zero, we let all new users in. As soon as the load level goes over a certain threshold, we begin to deny service to some users on this link. At some point, if the load continues to grow, we simply stop launching new sessions.
There is an interesting nuance here: current sessions have priority in this scheme. I think it is clear why this happens: if your user already provides you with a stable load pattern, you do not want to take him anywhere, because in this way you increase the dynamics of the system, and the more stable the system, the easier it is for us to control it.
However, the download may continue to grow. At some point, we can start to take away some of the sessions or even completely remove the load from this link.
It is in this form that we launched this algorithm in the first matches of the FIFA World Cup. It's probably interesting to see what kind of picture we saw. She was about the following.
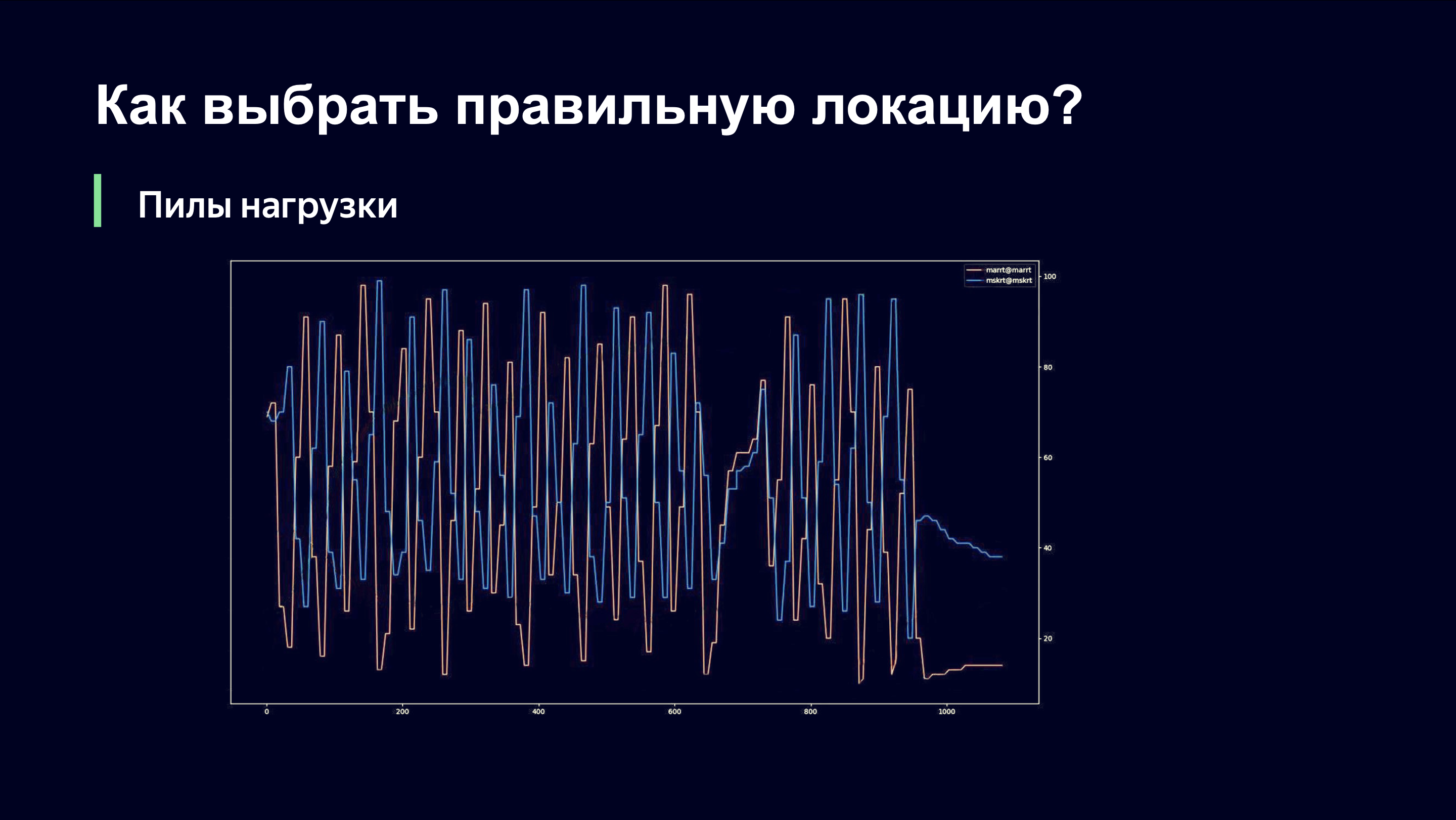
Even with the naked eye, an outside observer can understand that something is probably wrong here, and ask me: "Andrey, are you doing well?" And if you were my boss, you would run around the room and shout: “Andrey, my God! Roll it all back! Return everything as it was! " Let's tell you what's going on here.
On the X-axis, time, on the Y-axis, we observe the level of link load. There are two links that serve the same site. It is important to understand that at this moment we only used the link load monitoring scheme that is removed from the network equipment, and therefore could not quickly respond to the load dynamics.
When we send users to one of the links, there is a sharp increase in traffic on that link. The link is overloaded. We take the load off and find ourselves on the right side of the function that we saw in the previous graph. And we start dropping old users and stop letting in new ones. They need to go somewhere, and they go, of course, to the next link. Last time it may have been a lower priority, but now they have it in priority.
The second link repeats the same picture. We sharply increase the load, notice that the link is overloaded, remove the load, and these two links are in antiphase in terms of the load level.
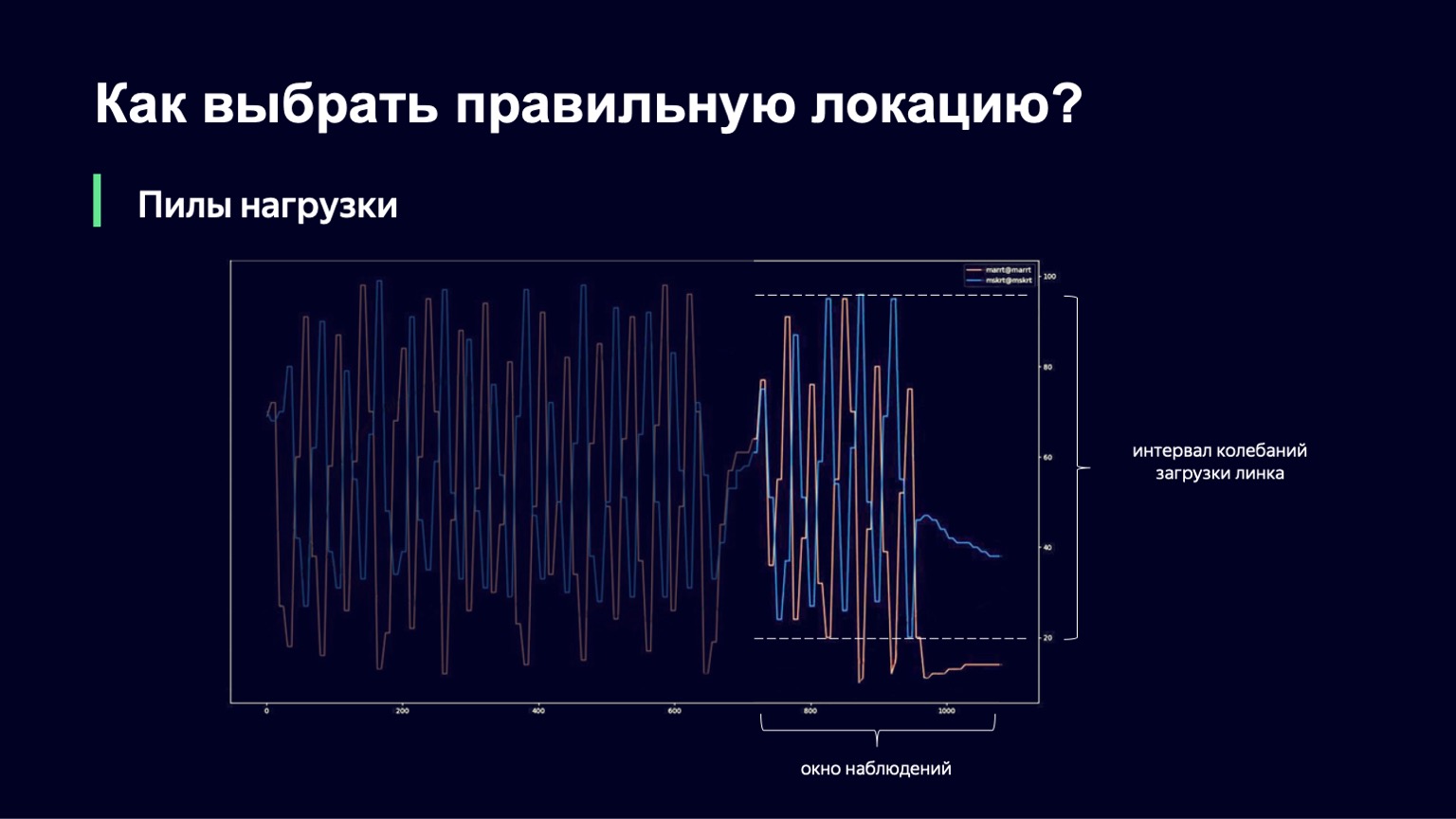
What can be done? We can analyze the dynamics of the system, notice this with a large increase in the load and damp it a little. This is exactly what we did. We took the current moment, took the observation window into the past for a few minutes, for example 2-3 minutes, and looked at how much the link load changes in this interval. The difference between the minimum and maximum values will be called the oscillation interval of this link. And if this oscillation interval is large, we will add damping, thus increasing our Slowdown and starting to run fewer sessions.
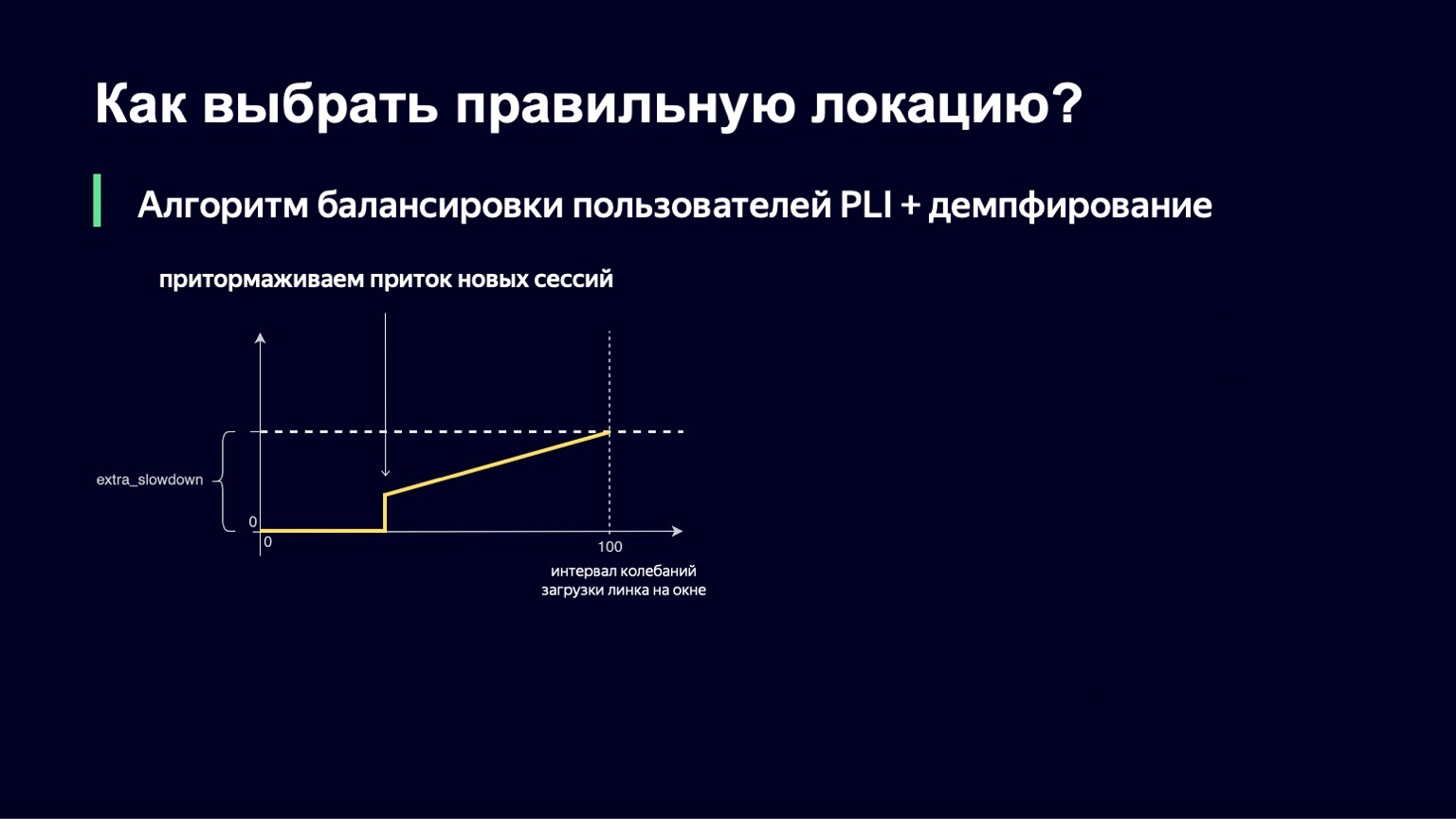
This function looks about the same as the previous one, with slightly fewer fractures. If we have a small interval for downloading oscillations, then we will not add any extra_slowdown. And if the oscillation interval begins to grow, then extra_slowdown takes on non-zero values, later we will add it to the main Slowdown.
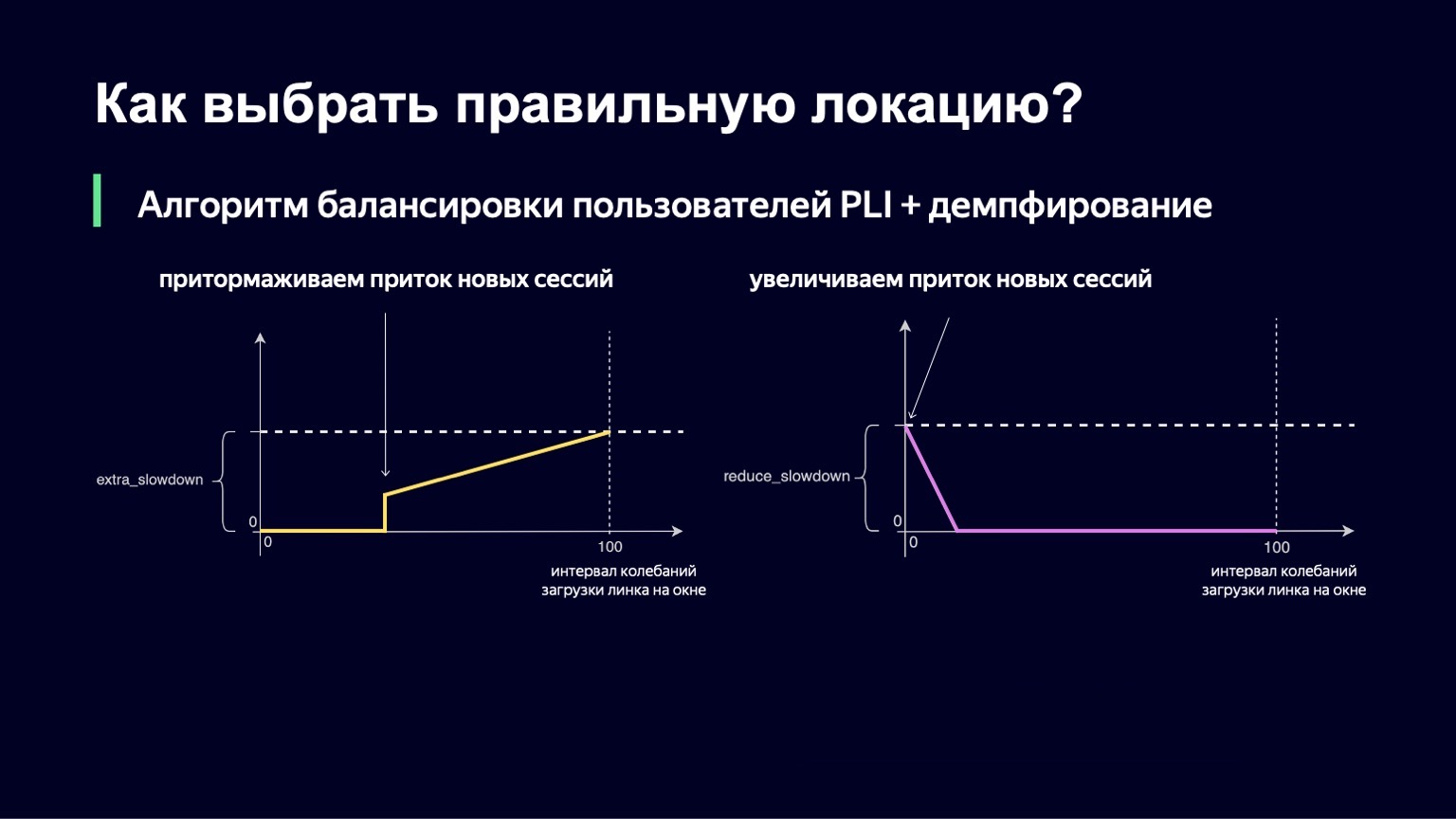
The same logic works at low values of the oscillation interval. If you have minimal fluctuations on the link, then, on the contrary, you want to let in a little more users there, reduce Slowdown and thereby better utilize your link.
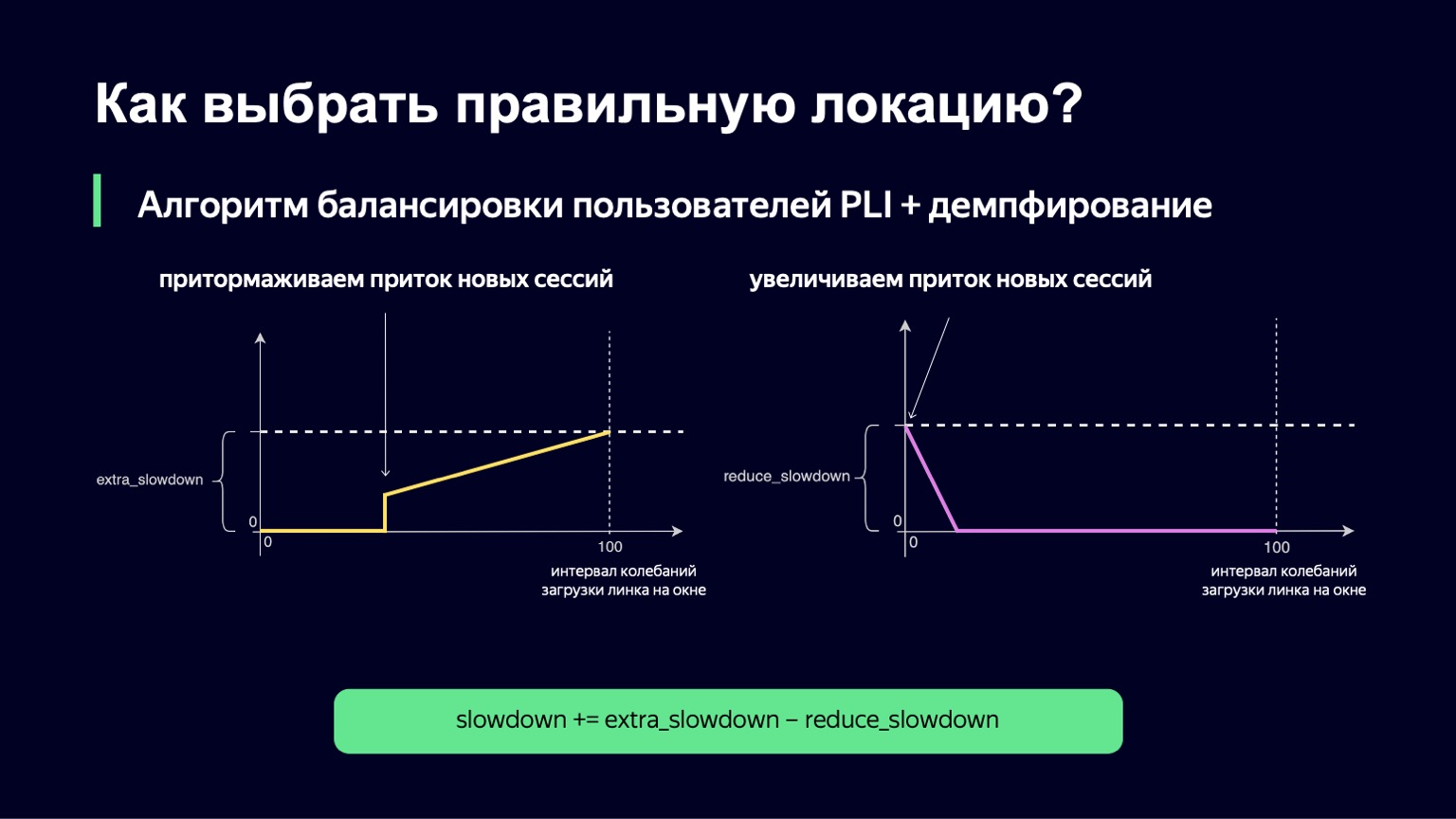
We have also implemented this part. The final formula looks like this. At the same time, we guarantee that both of these values - extra_slowdown and reduce_slowdown - never have a non-zero value at the same time, so only one of them works effectively. It is in this form that this balancing formula has survived all the top matches of the FIFA World Cup. Even at the most popular matches, she worked quite well: these are "Russia - Croatia", "Russia - Spain". During these matches, we distributed a record for Yandex traffic volumes - 1.5 terabits per second. We went through it calmly. Since then, the formula has not changed in any way, because there has been no such traffic on our service since then - until a certain moment.
Then a pandemic came to us. People were sent to sit at home, and at home there is good internet, TV, tablet and a lot of free time. The traffic to our services began to grow organically, rather quickly and significantly. Now this kind of load, as it was during the World Cup, is our daily routine. We've since expanded our channels with operators a bit, but nevertheless started thinking about the next iteration of our algorithm, what it should be and how we can better utilize our network.

What are the disadvantages of our previous algorithm? We haven't solved two problems. We have not completely got rid of the "saw" loads. We have greatly improved the picture and the amplitude of these fluctuations is minimal, the period has increased greatly, which also allows better utilization of the network. But all the same they appear from time to time, remain. We have not learned how to utilize the network to the level we would like. For example, we cannot use the configuration to set the desired maximum link load level of 80-85%.

What thoughts do we have for the next iteration of the algorithm? How do we envision the ideal network utilization? One of the promising areas, it would seem, is the option when you have a single place for making decisions about traffic. You collect all the metrics in one place, a user request for downloading segments comes there, and at every moment in time you have a complete state of the system, it is very easy for you to make decisions.
But there are two nuances here. First, it is not customary in Yandex to write “common decision-making points”, simply because with our load levels, with our traffic, such a place quickly becomes a bottleneck.
There is one more nuance - it is also important to write fault-tolerant systems in Yandex. We often completely shut down data centers, while your component should continue to work without errors, without interruptions. And in this form, this single place becomes, in fact, a distributed system that you need to control, and this is a slightly more difficult task than the one that we would like to solve in this place.

We definitely need fast metrics. Without them, the only thing you can do to avoid user suffering is to underutilize the network. But that doesn't suit us either.
If you look at our system at a high level, it becomes clear that our system is a dynamic system with feedback. We have a custom load, which is an input signal. People come and go. We have a control signal - the very two values that we can change in real time. For such dynamical systems with feedback, the theory of automatic control has been developed for a long time, several decades. And it is its components that we would like to use in order to stabilize our system.
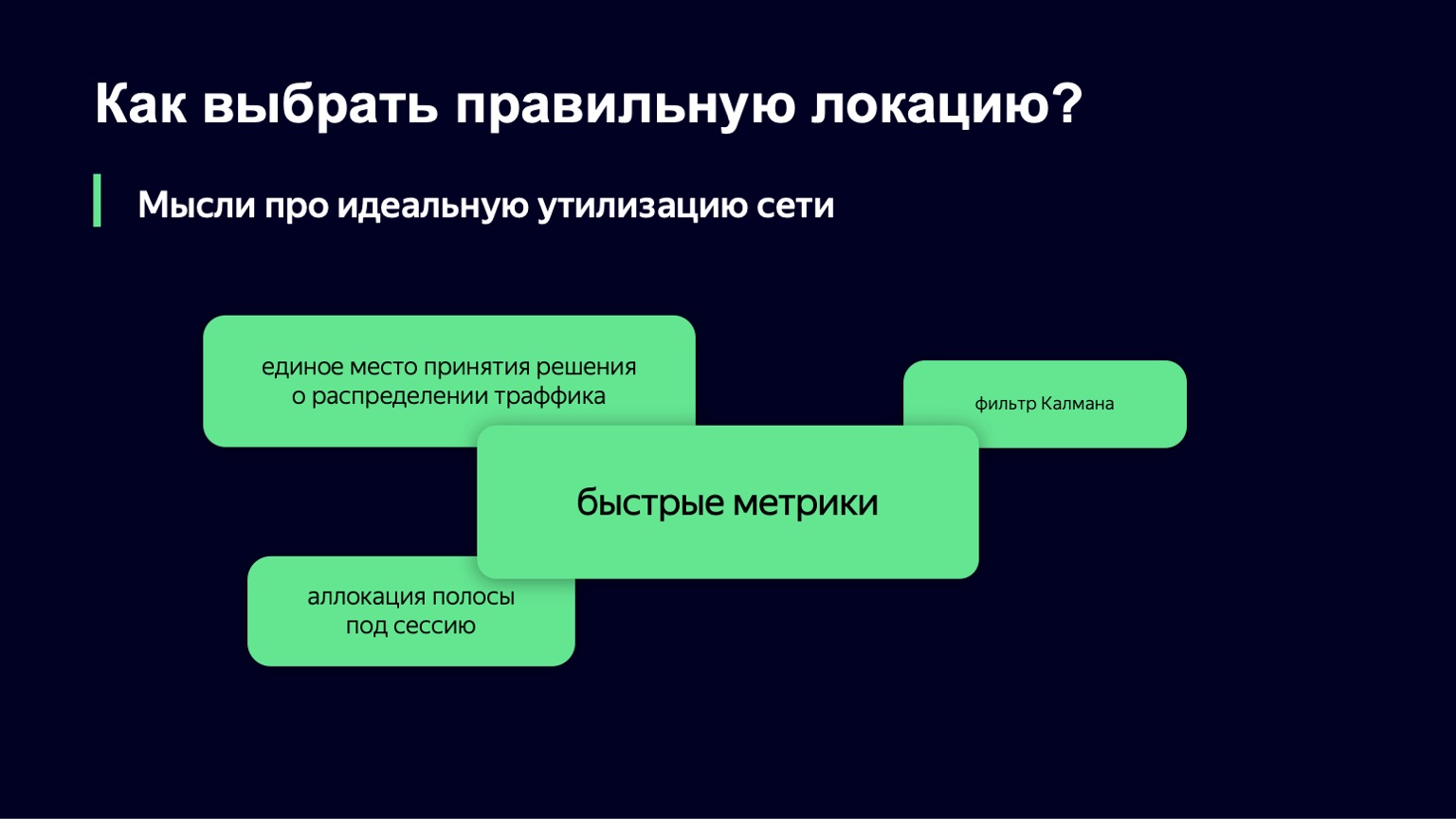
We looked at the Kalman filter. This is such a cool thing that allows you to build a mathematical model of the system and, with noisy metrics or in the absence of some classes of metrics, improve the model using your real system. And then make a decision about a real system based on a mathematical model. Unfortunately, it turned out that we do not have many classes of metrics that we can use, and this algorithm cannot be applied.
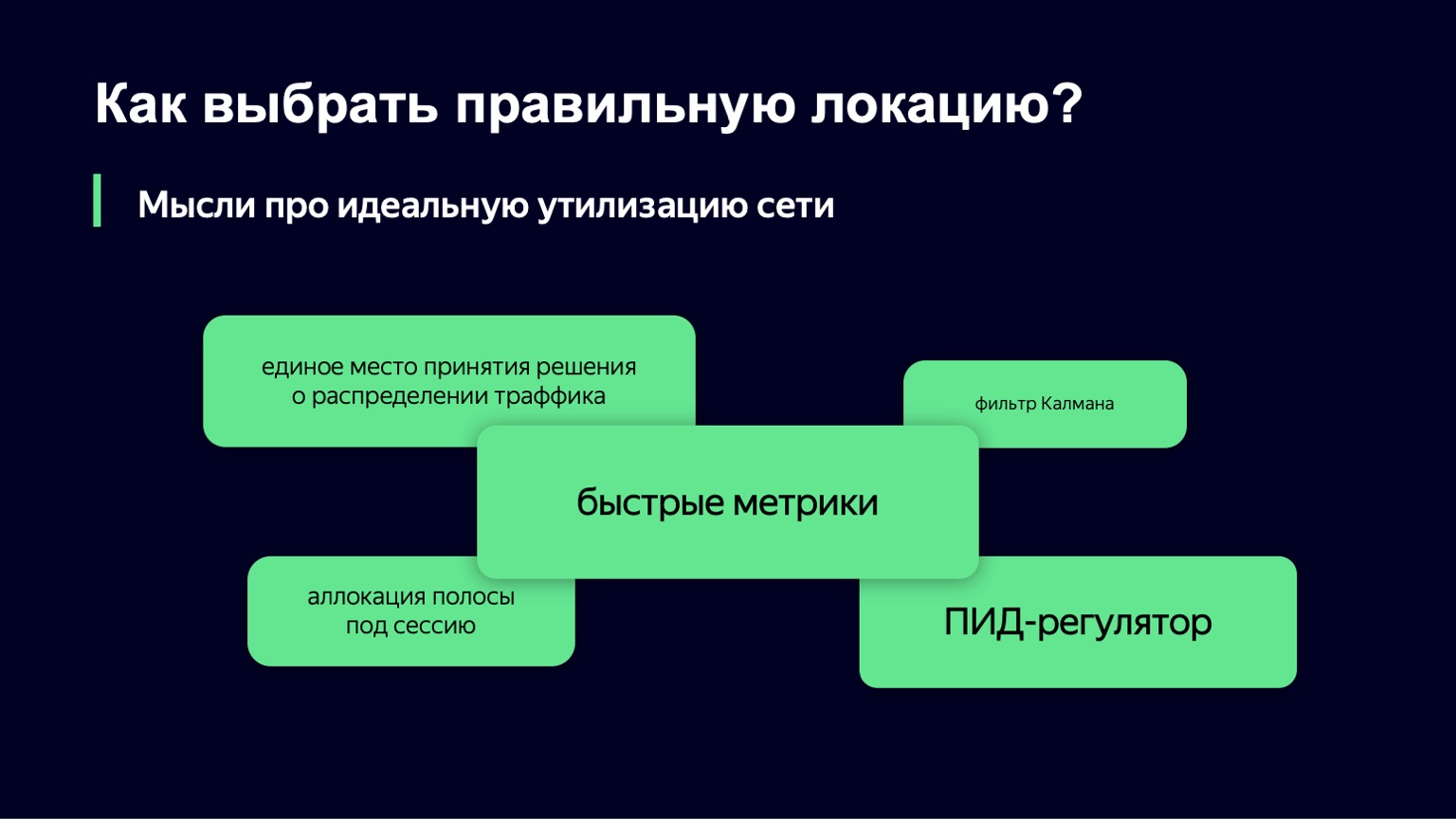
We approached from the other side, we took as a basis another component of this theory - the PID controller. He doesn't know anything about your system. Its task is to know the ideal state of the system, that is, our desired load level, and the current state of the system, for example, the load level. He considers the difference between these two states to be an error and, using his internal algorithms, controls the control signal, that is, our Slowdown and Drop values. Its purpose is to minimize the error in the system.
We will try this PID controller in production from day to day. Perhaps in a few months we will be able to tell you about the results.
On this we will probably finish about the network. I would very much like to tell you about how we distribute traffic within the location itself, when we have already chosen it between the hosts. But there is no time for that. This is probably a topic for a separate large report.

Therefore, in the next series, you will learn how to optimally utilize the cache on hosts, what to do with hot and cold traffic, as well as where the warm traffic comes from, how the type of content affects the algorithm for its distribution and which video gives the highest cache hit on the service, and who who sings a song.
I have another interesting story. In the spring, as you know, the quarantine began. Yandex has long had an educational platform called Yandex.Tutorial, which allows teachers to upload videos and lessons. Students come there and watch the content. During the pandemic, Yandex began to support schools, actively invite them to its platform so that students can study remotely. And at some point we saw a pretty good growth in traffic, a fairly stable picture. But on one of the April evenings, we saw something like the following on the charts.
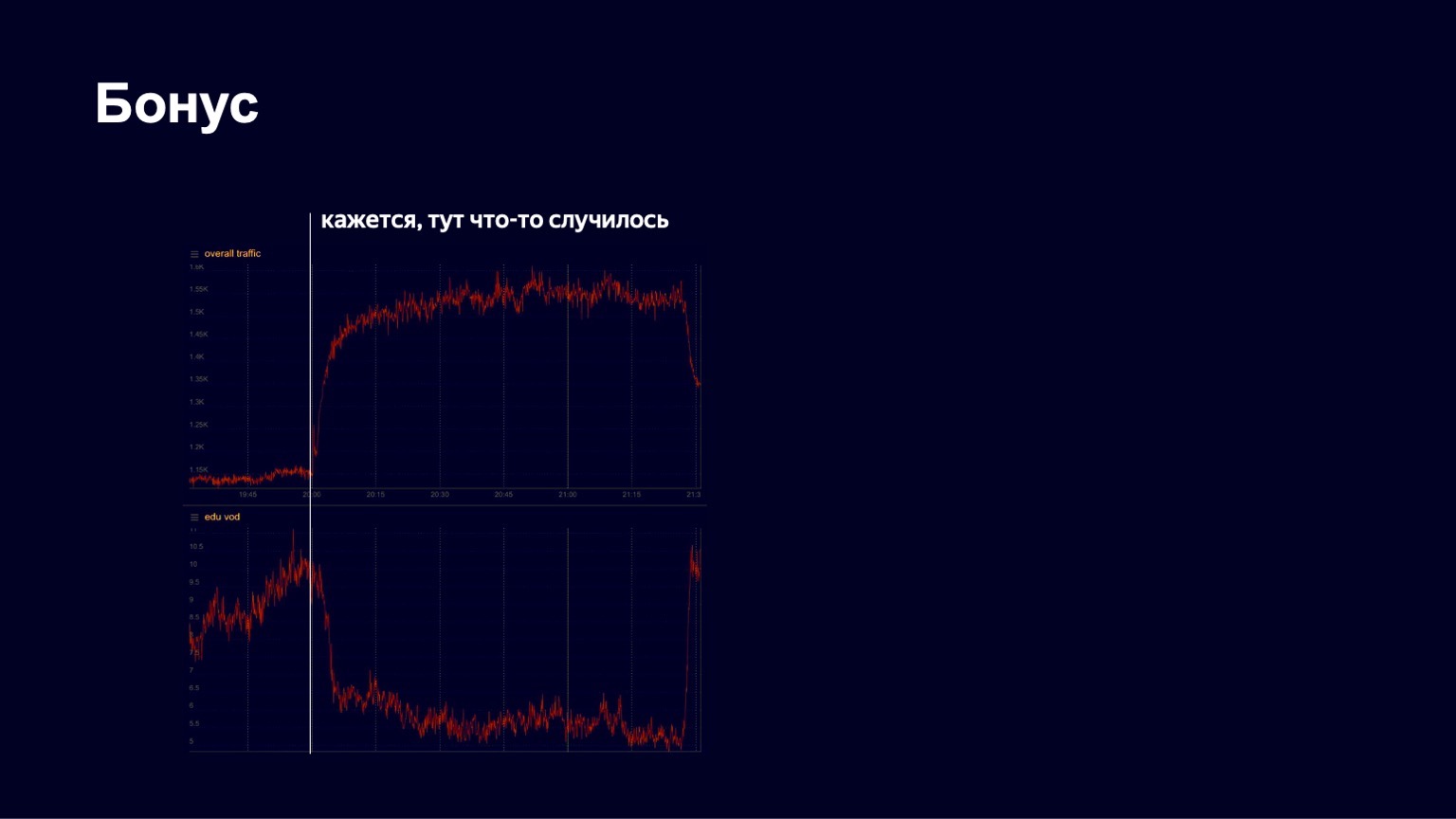
Below is a picture of traffic on educational content. We saw that he fell sharply at some point. We began to panic, to find out what was going on in general, what was broken. Then we noticed that the total traffic to the service began to grow. Obviously, something interesting has happened.
In fact, at that moment the following happened.
This is how fast the man dances.
The Little Big concert began, and all the students left to watch it. But after the end of the concert, they returned and successfully continued to study further. We see such pictures quite often on our service. Therefore, I think our work is quite interesting. Thanks to all! I will probably end with this about CDN.