( NLP) by Tim Dettmers, Ph.D. Deep Learning (DL) is an area with a high demand for computing power, so your choice of GPU will fundamentally determine your experience in this area. But what properties are important to consider when buying a new GPU? Memory, cores, tensor cores? How to make the best choice in terms of value for money? In this article, I will analyze in detail all these questions, common misconceptions, give you an intuitive understanding of the GPU, as well as a few tips to help you make the right choice.
This article is written to give you several different levels of understanding of the GPU, including. new Ampere series from NVIDIA. You have a choice:
- If you are not interested in the details of the GPU, what exactly makes the GPU fast, which is unique in the new GPUs of the NVIDIA RTX 30 Ampere series, you can skip the beginning of the article, right down to the graphs on speed and speed per $ 1 cost, as well as the recommendations section. This is the core of this article and the most valuable content.
- If you are interested in specific questions, then I covered the most frequent of them in the last part of the article.
- If you need a deep understanding of how GPUs and Tensor Cores work, your best bet is to read this article from start to finish. Depending on your knowledge of specific subjects, you can skip a chapter or two.
Each section is preceded by a short summary to help you decide whether to read it in its entirety or not.
Content
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
This article is structured as follows. First I explain what makes a GPU fast. I will describe the difference between processors and GPUs, tensor cores, memory bandwidth, GPU memory hierarchy, and how it all relates to performance in GO tasks. These explanations might help you better understand what GPU parameters you need. Then I will give theoretical estimates of GPU performance and their correspondence with some NVIDIA speed tests to get reliable performance data without bias. I will describe the unique features of the NVIDIA RTX 30 Ampere Series GPUs to consider when purchasing. Then I'll give GPU recommendations for 1-2 chip, 4, 8, and GPU clusters. Then there will be a section of answers to frequently asked questions that I was asked on Twitter.It will also dispel common misconceptions and highlight various problems such as clouds versus desktops, cooling, AMD versus NVIDIA, and others.
How do GPUs work?
If you use GPUs a lot, it's helpful to understand how they work. This knowledge will be useful to you to figure out why in some cases GPUs are slower and in others faster. And then you may understand whether you need a GPU at all, and what hardware options can compete with it in the future. You can skip this section if you just want some useful performance information and arguments for choosing a particular GPU. The best general explanation of how GPUs work is in the answer on Quora .
This is a general explanation, and it explains well the question of why GPUs are better suited for GO than processors. If we study the details, we can understand how GPUs differ from each other.
The most important GPU characteristics affecting processing speed
This section will help you think more intuitively about performance in the field of GO. This understanding will help you evaluate future GPUs yourself.
Tensor cores
Summary:
- Tensor kernels reduce the number of clock cycles required to count multiplications and additions by 16 times - in my example for a 32 × 32 matrix from 128 to 8 clock cycles.
- Tensor kernels reduce the reliance on repeated access to shared memory, saving memory access cycles.
- Tensor kernels are so fast that computation is no longer a bottleneck. The only bottleneck is the transfer of data to them.
There are so many inexpensive GPUs out there today that almost everyone can afford a GPU with tensor cores. Therefore, I always recommend GPUs with Tensor Cores. It is useful to understand how they work in order to appreciate the importance of these computational modules specializing in matrix multiplication. Using a simple example of matrix multiplication A * B = C, where the size of all matrices is 32 × 32, I will show you how multiplication looks like with and without tensor kernels.
To understand this, you first need to understand the concept of bars. If the processor is running at 1 GHz, it does 10 9ticks per second. Each clock is an opportunity for calculations. But for the most part, operations take longer than one clock cycle. It turns out a pipeline - in order to start performing one operation, you first need to wait as many clock cycles as required to complete the previous operation. This is also called delayed operation.
Here are some important durations or delays of an operation in ticks:
- Access to global memory up to 48 GB: ~ 200 clock cycles.
- Shared memory access (up to 164 KB per streaming multiprocessor): ~ 20 clocks.
- Combined multiplication-addition (SUS): 4 measures.
- Matrix multiplication in tensor kernels: 1 clock cycle.
Also, you need to know that the smallest unit of threads in a GPU — a packet of 32 threads — is called a warp. Warps usually work synchronously - all threads inside the warp need to wait for each other. All GPU memory operations are optimized for warps. For example, loading from global memory takes 32 * 4 bytes - 32 floating point numbers, one such number for each thread in the warp. In a streaming multiprocessor (the equivalent of a processor core for a GPU), there can be up to 32 warps = 1024 threads. Multiprocessor resources are shared among all active warps. Therefore, sometimes we need fewer warps to work, so that one warp has more registers, shared memory and tensor core resources.
For both examples, let's assume we have the same computing resources. In this small example of 32 × 32 matrix multiplication, we use 8 multiprocessors (~ 10% of the RTX 3090) and 8 warps on a multiprocessor.
Matrix multiplication without tensor kernels
If we need to multiply matrices A * B = C, each of which has a size of 32 × 32, then we need to load data from memory, which we are constantly accessing, into shared memory, since access delays are about 10 times less (not 200 bars, and 20 bars). A block of memory in shared memory is often called a memory tile, or simply a tile. Loading two 32 × 32 floating point numbers into a shared memory tile can be done in parallel using 2 * 32 warps. We have 8 multiprocessors with 8 warps each, so thanks to parallelization, we need to carry out one sequential load from global to shared memory, which will take 200 clock cycles.
To multiply matrices, we need to load a vector of 32 numbers from shared memory A and shared memory B, and carry out the CMS, and then store the output in registers C. We divide this work so that each multiprocessor deals with 8 scalar products (32 × 32 ) to calculate 8 output data for C. Why there are exactly 8 of them (in old algorithms - 4), this is a purely technical feature. To figure it out, I recommend reading the article by Scott Gray . This means that we will have 8 accesses to the shared memory, costing 20 cycles each, and 8 CMS operations (32 parallel), costing 4 cycles each. In total, the cost will be:
200 ticks (global memory) + 8 * 20 ticks (shared memory) + 8 * 4 ticks (CMS) = 392 ticks
Now let's look at this cost for tensor cores.
Matrix multiplication with tensor kernels
Using tensor kernels, you can multiply 4 × 4 matrices in one cycle. To do this, we need to copy memory to tensor cores. As above, we need to read data from global memory (200 ticks) and store it in shared memory. To multiply 32 × 32 matrices, we need to perform 8 × 8 = 64 operations in tensor kernels. One multiprocessor contains 8 tensor cores. With 8 multiprocessors, we have 64 tensor cores - just as many as we need! We can transfer data from shared memory to tensor cores in 1 transfer (20 clock cycles), and then carry out all these 64 operations in parallel (1 clock cycle). This means that the total cost of matrix multiplication in tensor cores will be:
200 clock cycles (global memory) + 20 clock cycles (shared memory) + 1 clock cycle (tensor cores) = 221 clock cycles
Thus, using tensor kernels, we significantly reduce the cost of matrix multiplication, from 392 to 221 clock cycles. In our simplified example, tensor kernels have reduced the cost of both shared memory access and SNS operations.
Although this example roughly follows the sequence of computational steps with and without tensor kernels, please note that this is a very simplified example. In real cases, matrix multiplication involves much like large memory tiles and slightly different sequences of actions.
However, it seems to me that this example makes it clear why the next attribute, memory bandwidth, is so important for GPUs with tensor cores. Since global memory is the most expensive thing when multiplying matrices with tensor cores, our GPUs would be much faster if we could reduce the latency of access to global memory. This can be done either by increasing the memory clock speed (more clocks per second, but more heat and power consumption), or by increasing the number of elements that can be transferred at a time (bus width).
Memory bandwidth
In the previous section, we saw how fast tensor kernels are. They are so fast that they sit idle most of the time, waiting for data from global memory to arrive. For example, during training for the BERT Large project, where very large matrices were used - the larger, the better for tensor kernels - the utilization of tensor kernels in TFLOPS was about 30%, which means that 70% of the time the tensor kernels were idle.
This means that when comparing two GPUs with tensor cores, one of the best performance indicators for each is memory bandwidth. For example, the A100 GPU has a bandwidth of 1.555 GB / s, while the V100 has 900 GB / s. A simple calculation says that the A100 will be faster than the V100 by 1555/900 = 1.73 times.
Shared Memory / L1 Cache / Registers
Since the speed-limiting factor is the transfer of data to the memory of tensor kernels, we must turn to other properties of the GPU, allowing us to speed up the transfer of data to them. Associated with this are shared memory, L1 cache and number of registers. To understand how the memory hierarchy speeds up data transfers, it is helpful to understand how the matrix multiplies in the GPU.
For matrix multiplication, we use a memory hierarchy that goes from slow global memory to fast local shared memory, and then to ultra-fast registers. However, the faster the memory, the smaller it is. Therefore, we need to divide the matrices into smaller ones, and then multiply these smaller tiles in local shared memory. Then it will happen quickly and closer to the streaming multiprocessor (PM) - the equivalent of the processor core. Tensor cores allow us to take one more step: we take all the tiles and load some of them into tensor cores. Shared memory processes matrix tiles 10-50 times faster than global GPU memory, and tensor core registers process it 200 times faster than global GPU memory.
Increasing the size of the tiles allows us to reuse more memory. I wrote about this in detail in my article TPU vs GPU . In TPU, there is a very, very large tile for each tensor core. TPUs can reuse a lot more memory with each new transfer from global memory, which makes them a little more efficient at handling matrix multiplication compared to GPUs.
Tile sizes are determined by the amount of memory for each PM - the equivalent of a processor core on a GPU. Depending on the architectures, these volumes are:
- Volta: 96KB Shared Memory / 32KB L1
- Turing: 64KB Shared Memory / 32KB L1
- Ampere: 164KB shared memory / 32KB L1
You can see that Ampere has much more shared memory, which allows using larger tiles, which reduces the number of global memory accesses. Therefore, Ampere makes more efficient use of the GPU memory bandwidth. This increases performance by 2-5%. The increase is especially noticeable on huge matrices.
Ampere tensor kernels have another advantage - they have a larger amount of data common to several threads. This reduces the number of register calls. The size of registers is limited to 64 k per PM or 255 per thread. Compared to Volta, Ampere Tensor Cores use 3 times fewer registers, so there are more active Tensor Cores per tile in the shared memory. In other words, we can load 3 times as many tensor cores with the same number of registers. However, since bandwidth remains a bottleneck, the increase in TFLOPS in practice will be negligible compared to theoretical. New tensor kernels have improved performance by about 1-3%.
Overall, it can be seen that the Ampere architecture has been optimized to more efficiently use memory bandwidth through an improved hierarchy - from global memory to shared memory tiles to tensor core registers.
Evaluation of the effectiveness of Ampere in GO
Summary:
- Theoretical estimates based on memory bandwidth and improved memory hierarchy for Ampere GPUs predict 1.78 - 1.87 times acceleration.
- NVIDIA has released data on speed measurements for Tesla A100 and V100 GPUs. They are more marketing, but you can build an unbiased model based on them.
- The unbiased model suggests that compared to the V100, the Tesla A100 is 1.7 times faster in natural language processing and 1.45 times faster in computer vision.
This section is for those looking to delve deeper into the technical details of how I got the Ampere GPU performance scores. If you are not interested, you can safely skip it.
Ampere theoretical speed estimates
Given the above arguments, one would expect that the difference between the two GPU architectures with tensor cores should have been mainly in memory bandwidth. Additional benefits come from increased shared memory and L1 cache, and efficient use of registers.
The bandwidth of the Tesla A100 GPU increases by 1555/900 = 1.73 times compared to the Tesla V100. It is also reasonable to expect a 2-5% increase in speed due to the larger total memory, and 1-3% due to the improvement in tensor cores. It turns out that the acceleration should be from 1.78 to 1.87 times.
Ampere
Let's say we have a single GPU score for an architecture like Ampere, Turing, or Volta. It is easy to extrapolate these results to other GPUs of the same architecture or series. Fortunately, NVIDIA has already conducted benchmarks comparing the A100 and V100 on various tasks related to computer vision and natural language understanding. Unfortunately, NVIDIA has done everything possible so that these numbers cannot be compared directly - in the tests they used different data packet sizes and different number of GPUs so that the A100 could not win. So, in a sense, the obtained performance indicators are partly honest, partly advertising. In general, it can be argued that the increase in data packet size is justified as the A100 has more memory - however,to compare GPU architectures, we need to compare unbiased performance data on tasks with the same data packet size.
To get unbiased estimates, you can scale the V100 and A100 measurements in two ways: take into account the difference in data packet size, or account for the difference in the number of GPUs - 1 versus 8. We are lucky and can find similar estimates for both cases in the data provided by NVIDIA.
Doubling the packet size increases the throughput by 13.6% in images per second (for convolutional neural networks, CNN). I measured the speed of the same task with the Transformer architecture on my RTX Titan and, surprisingly, got the same result - 13.5%. This appears to be a reliable estimate.
By increasing the parallelization of networks, by increasing the number of GPUs, we lose in performance due to the overhead associated with networks. But the A100 8x GPU performs better on networking (NVLink 3.0) compared to the V100 8x GPU (NVLink 2.0) - another confusing factor. If you look at the data from NVIDIA, you can see that for processing the SNS, the system with the 8th A100 has 5% less overhead than the system with the 8th V10000. This means that if the transition from the 1st A10000 to the 8th A10000 gives you an acceleration of, say, 7.0 times, then the transition from the 1st V10000 to the 8th V10000 gives you an acceleration only 6.67 times. For transformers, this figure is 7%.
Using this information, we can estimate the acceleration of some specific GO architectures directly from the data provided by NVIDIA. The Tesla A100 has the following speed advantages over the Tesla V100:
- SE-ResNeXt101: 1.43 times.
- Masked-R-CNN: 1.47 times.
- Transformer (12 layers, machine translation, WMT14 en-de): 1.70 times.
Therefore, for computer vision, the numbers are obtained below the theoretical estimate. This can be due to smaller tensor measurements, the overhead of the operations required to prepare a matrix multiplication like img2col or FFT, or operations that cannot saturate the GPU (the resulting layers are often relatively small). It can also be artifacts of certain architectures (grouped convolution).
The practical assessment of the speed of the transformer is very close to the theoretical one. Probably because the algorithms for working with large matrices are very straightforward. I will use practical estimates to calculate the GPU cost efficiency.
Possible inaccuracies of estimates
The above are comparative ratings for A100 and V100. In the past, NVIDIA secretly worsened the performance of "gaming" RTX GPUs: reduced utilization of tensor cores, added gaming fans for cooling, and prohibited data transfer between GPUs. It is possible that the RT 30 series also made unknown impairments over the Ampere A100.
What else to consider in the case of the Ampere / RTX 30
Summary:
- Ampere allows you to train networks based on sparse matrices, which speeds up the training process up to two times.
- Sparse network training is still rarely used, but thanks to it, Ampere will not soon become obsolete.
- Ampere has new low precision datatypes that make it much easier to use low precision, but it won't necessarily give a speed boost over previous GPUs.
- The new fan design is good if you have free space between the GPUs - however, it is not clear whether GPUs standing close to each other will cool effectively.
- The 3-slot design of the RTX 3090 will be a challenge for 4 GPU builds. Possible solutions are to use 2-slot options or PCIe expanders.
- The four RTX 3090s will need more power than any standard PSU on the market can offer.
The new NVIDIA Ampere RTX 30 have additional advantages over the NVIDIA Turing RTX 20 - sparse training and improved data processing by the neural network. The rest of the properties, such as new data types, can be considered a simple convenience enhancement - they speed things up in the same way as the Turing series, without requiring additional programming.
Sparse learning
Ampere allows you to multiply sparse matrices at high speed and automatically. It works like this - you take a matrix, cut it into pieces of 4 elements, and the tensor kernel supporting sparse matrices allows two of these four elements to be zero. This results in a 2x speedup because the bandwidth requirements during matrix multiplication are halved.
In my research, I've worked with sparse learning networks. The work was criticized, in particular, for the fact that I "reduce the FLOPS required for the network, but do not increase the speed because of this, because GPUs cannot quickly multiply sparse matrices." Well - support for sparse matrix multiplication appeared in tensor kernels, and my algorithm, or any other algorithm ( link, link , link , link ), working with sparse matrices, can now actually work twice as fast during training.
Although this property is currently considered experimental, and sparse network training is not universally applied, if your GPU has support for this technology, then you are ready for the future of sparse training.
Low-precision calculations
I have already demonstrated how new data types can improve the stability of low fidelity backpropagation in my work. So far, the problem with stable backpropagation with 16-bit floating point numbers is that regular data types only support the span [-65,504, 65,504]. If your gradient goes beyond this gap, it will explode, yielding NaN values. To prevent this, we usually scale the values by multiplying them by a small number before backpropagating to avoid the gradient explosion.
The Brain Float 16 (BF16) format uses more bits for the exponent, so the range of possible values is the same as in FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. The BF16 has less precision, i.e. fewer significant digits, but the accuracy of the gradient when training networks is not so important. Therefore, BF16 ensures that you don't have to do scaling or worry about gradient explosion. With this format, we should see an increase in training stability at the expense of a small loss of precision.
What this means for you: BF16 accuracy can be more consistent than FP16 accuracy, but the speed is the same. With TF32 precision, you will get stability almost like FP32, and acceleration almost like FP16. The plus is that when using these data types, you can change FP32 to TF32, and FP16 to BF16, without changing anything in the code!
In general, these new data types can be considered lazy, in the sense that you could get all of their benefits using the old data types and a little programming (scaling correctly, initializing, normalizing, using Apex). Therefore, these data types do not provide acceleration, but make it easier to use low fidelity in training.
New fan design and heat dissipation issues
The new fan design for the RTX 30 series has an air blowing fan and an air pulling fan. The design itself is ingenious, and will work very efficiently if there is free space between the GPUs. However, it is not clear how GPUs will behave if they are forced one to another. The blowing fan will be able to blow air away from other GPUs, but it is impossible to tell how this will work as its shape is different from what it was before. If you are planning to put 1 or 2 GPUs where there are 4 slots then you shouldn't have a problem. But if you want to use 3-4 RTX 30 GPUs side by side, I would first wait for reports on the temperature conditions, and then I decided if I needed more fans, PCIe expanders or other solutions.
In any case, water cooling can help solve the problem with the heat sink. Many manufacturers offer such solutions for RTX 3080 / RTX 3090 cards, and then they will not get warm, even if there are 4. However, do not buy ready-made GPU solutions if you want to build a computer with 4 GPUs, since it will be very difficult in most cases distribute radiators.
Another solution to the cooling problem is to buy PCIe expanders and distribute the cards inside the case. This is very effective - I and other graduate students at Vanington University have used this option with great success. It doesn't look very neat, but GPUs don't get hot! Also, this option will help in case you do not have enough space to accommodate the GPU. If you have room in your case, you can, for example, buy a standard RTX 3090 with three slots, and distribute them using expanders throughout the case. Thus, it is possible to solve simultaneously the problem of space and cooling of 4 RTX 3090s

. Fig. 1: 4 GPU with PCIe Expanders
Three-slot cards and power problems
The RTX 3090 occupies 3 slots, so they cannot be used 4 each with NVIDIA's default fans. This is not surprising since it requires 350W TDP. The RTX 3080 is only slightly inferior, requiring 320W TDP, and cooling a system with four RTX 3080s will be very difficult.
It is also difficult to power a system with 4 cards of 350W = 1400W. There are 1600 W power supplies (PSUs), but 200 W for the processor and motherboard may not be enough. The maximum power consumption occurs only at full load, and during HE the processor is usually lightly loaded. Therefore, a 1600W PSU may be suitable for 4 RTX 3080s, but for 4 RTX 3090s it is better to look for a 1700W or more PSU. There are no such PSUs on the market today. Server PSUs or special blocks for cryptominers may work, but they may have an unusual form factor.
GPU efficiency in deep learning
The next test included not only comparisons of Tesla A100 and Tesla V100 - I built a model that fits into this data and four different tests, where Titan V, Titan RTX, RTX 2080 Ti and RTX 2080 were tested ( link , link , link , link ).
I also scaled the benchmark results for mid-range cards such as the RTX 2070, RTX 2060, or Quadro RTX by interpolating the test data points. Typically in GPU architecture, such data is scaled linearly with respect to matrix multiplication and memory bandwidth.
I only collected data from FP16 training tests with mixed precision as I see no reason to use training with FP32 numbers.

Figure: 2: Performance Normalized by RTX 2080 Ti
Compared to the RTX 2080 Ti, the RTX 3090 runs 1.57 times faster with convolutional networks, 1.5 times faster with transformers, and costs 15% more. It turns out that the Ampere RTX 30 is showing a significant improvement since the Turing RTX 20 series.
GPU deep learning rate per cost
Which GPU would be the best value for money? It all depends on the total cost of the system. If it is expensive, it makes sense to invest in more expensive GPUs.
Below are data on three assemblies on PCIe 3.0, which I use as a baseline for the cost of systems with 2 or 4 GPUs. I take this base cost and add the GPU cost to it. I calculate the latter as the average price between offers from Amazon and eBay. For new Ampere I only use one price. Taken together with the performance data above, this gives the performance values per dollar. For a system with 8 GPUs, I take the Supermicro barebone as an industry standard for RTX servers. The graphs shown do not include memory requirements. You first need to think about what memory you need, and then look for the best options on the graphs. Sample tips for memory:
- Using pre-trained transformers, or training a small transformer from scratch> = 11 GB.
- Training a large transformer or convolutional network in research or production:> = 24 GB.
- Prototyping neural networks (transformer or convolutional network)> = 10 GB.
- Participation in Kaggle contests> = 8 GB.
- Computer vision> = 10 GB.
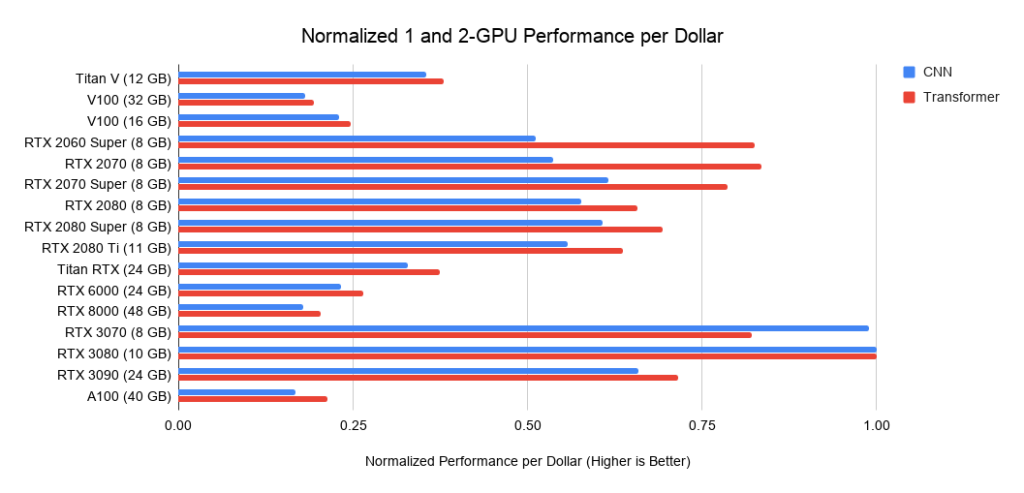
Figure:

Figure 3: Normalized dollar performance versus RTX 3080 . Figure 4: Normalized dollar performance versus RTX 3080
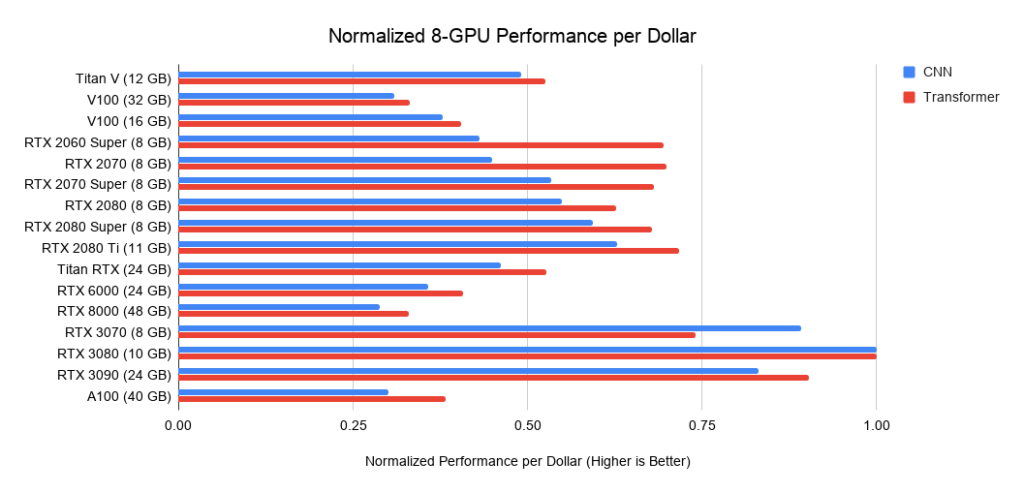
. 5: Normalized dollar performance versus RTX 3080.
GPU recommendations
Once again, I want to emphasize: when choosing a GPU, first make sure that it has enough memory for your tasks. The steps for choosing a GPU should be as follows:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Some of the steps require you to think about what you want and do a little research on how much memory other people are using when doing the same. I can give some advice, but I cannot fully answer all the questions in this area.
When will I need more than 11GB of storage?
I already mentioned that when working with transformers, you will need at least 11 GB, and when doing research in this area, at least 24 GB. Most of the previous pretrained models have very high memory requirements and have been trained on an RTX 2080 Ti or higher GPU with at least 11GB of memory. Therefore, if you have less than 11 GB of memory, launching some models can become difficult or even impossible.
Other areas that require large amounts of memory are medical image processing, advanced computer vision models, and all with large images.
Overall, if you're looking to develop models that can outperform the competition - be it research, industrial applications, or Kaggle competition - the extra memory may give you a competitive edge.
When can you get by with less than 11 GB of memory?
The RTX 3070 and RTX 3080 cards are powerful, but they lack memory. However, for many tasks that amount of memory may not be required.
The RTX 3070 is ideal for GO training. Basic networking skills for most architectures can be acquired by scaling down networks or using smaller images. If I had to learn GO, I would pick the RTX 3070, or even a few if I could afford them.
The RTX 3080 is the most cost-effective card today and is therefore ideal for prototyping. Prototyping requires large amounts of memory, and memory is inexpensive. By prototyping, I mean prototyping in any area - research, Kaggle competitions, trying ideas for a startup, experimenting with research code. For all these applications, the RTX 3080 is best suited.
If, for example, I were running a research laboratory or a startup, I would spend 66-80% of the total budget on RTX 3080 machines, and 20-33% on RTX 3090 machines with reliable water cooling. RTX 3080 is more cost effective and can be accessed through Slurm... Since prototyping needs to be done in agile mode, it needs to be done with smaller models and datasets. And the RTX 3080 is perfect for that. Once students / colleagues have built a great prototype model, they can roll it out onto the RTX 3090, scaling up to larger models.
General recommendations
Overall, the RTX 30 series models are very powerful and I definitely recommend them. Consider the memory requirements as stated earlier, as well as the power and cooling requirements. If you have a free slot between the GPUs, there will be no problems with cooling. Otherwise, provide the RTX 30 cards with water cooling, PCIe expanders, or efficient cards with fans.
Overall, I would recommend the RTX 3090 to anyone who can afford it. It will not only suit you now, but it will remain very effective for the next 3-7 years. It is unlikely that in the next three years HBM memory will become much cheaper, so the next GPU will be only 25% better than the RTX 3090. In 5-7 years, we will probably see cheap HBM memory, after which you will definitely need to update the fleet ...
If you are building a system from several RTX 3090s, provide them with sufficient cooling and power.
Unless you have strict requirements for competitive advantage, I would recommend the RTX 3080. This is a more cost effective solution and will provide fast training for most networks. If you do the memory tricks you want and don't mind writing extra code, there are plenty of tricks to cram a 24GB network into a 10GB GPU.
The RTX 3070 is also a great card for GO training and prototyping, and is $ 200 cheaper than the RTX 3080. If you can't afford the RTX 3080, then the RTX 3070 is your choice.
If your budget is tight and the RTX 3070 is too expensive for you, you can find a used RTX 2070 on eBay for about $ 260. It is not yet clear if the RTX 3060 will come out, but if your budget is tight it might be worth the wait. If it is priced to match the RTX 2060 and GTX 1060, then it should be around $ 250- $ 300, and it should perform well.
Recommendations for GPU clusters
The GPU cluster layout is highly dependent on its use. For a system with 1,024 GPUs or more, the main thing will be the presence of a network, but if you use no more than 32 GPUs at a time, then it makes no sense to invest in building a powerful network.
In general, RTX cards under the CUDA agreement cannot be used in data centers. However, universities can often be the exception to this rule. If you would like to obtain such permission, it is worth contacting an NVIDIA representative. If you can use RTX cards, then I would recommend Supermicro's standard 8 GPU RTX 3080 or RTX 3090 system (if you can keep them cool). A small set of 8 A10000 nodes ensures efficient use of models after prototyping, especially if cooling servers with 8 RTX 3090s is not possible. In this case, I would recommend the A10000 over the RTX 6000 / RTX 8000 as the A10000s are quite cost effective and won't get old quickly.
If you need to train very large networks on a GPU cluster (256 GPUs or more), I would recommend the NVIDIA DGX SuperPOD system with A10000. from 256 GPUs, networking becomes essential. If you want to expand beyond 256 GPUs, you will need a highly optimized system for which standard solutions will no longer work.
Especially on the 1,024 GPU scale and beyond, the only competitive solutions on the market remain Google TPU Pod and NVIDIA DGX SuperPod. At this scale, I would prefer the Google TPU Pod, as their dedicated networking infrastructure looks better than the NVIDIA DGX SuperPod - although in principle, the two systems are pretty close. In applications and hardware, a GPU system is more flexible than a TPU, while TPU systems support larger models and scale better. Therefore, both systems have their advantages and disadvantages.
Which GPUs are better not to buy
I don't recommend buying multiple RTX Founders Editions or RTX Titans at a time, unless you have PCIe expanders to address their cooling issues. They will just warm up and their speed will drop dramatically compared to what is indicated in the graphs. The four RTX 2080 Ti Founders Editions will quickly heat up to 90 ° C, drop clock speeds, and run slower than a normally cooled RTX 2070.
I recommend buying a Tesla V100 or A100 only in extreme cases, since they are prohibited from being used in companies' data centers. Or buy them if you need to train very large networks on huge GPU clusters - their price / performance ratio is not ideal.
If you can afford something better, don't go for GTX 16 series cards. They do not have tensor cores, so their performance in GO is poor. I would take a used RTX 2070 / RTX 2060 / RTX 2060 Super instead. They can be borrowed if your budget is very limited.
When is it better not to buy new GPUs?
If you already own an RTX 2080 Ti or better, upgrading to an RTX 3090 is almost pointless. Your GPUs are already good, and the speed benefits will be negligible compared to the acquired power and cooling issues - it's not worth it.
The only reason I would want to upgrade from four RTX 2080 Ti to four RTX 3090 is if I was researching very large transformers or other networks that rely heavily on computing power. However, if you have memory problems, you should first consider various tricks in order to cram large models into existing memory.
If you own one or more RTX 2070s, I would think twice if I were you before upgrading. These are pretty good GPUs. It might make sense to sell them on eBay and buy an RTX 3090 if 8GB isn't enough for you - as is the case with many other GPUs. If memory is low, an update is brewing.
Answers to questions and misconceptions
Summary:
- PCIe lanes and PCIe 4.0 are irrelevant for dual GPU systems. For systems with 4 GPUs, they practically do not.
- Cooling down the RTX 3090 and RTX 3080 will be tough. Use water coolers or PCIe expanders.
- NVLink is only needed for GPU clusters.
- Different GPUs can be used on the same computer (for example, GTX 1080 + RTX 2080 + RTX 3090), but efficient parallelization will not work.
- To run more than two machines in parallel, you need Infiniband and a 50 Gbps network.
- AMD processors are cheaper than Intel processors, and the latter have almost no advantages.
- Despite the heroic efforts of engineers, AMD GPU + ROCm will hardly be able to compete with NVIDIA due to the lack of community and equivalent tensor cores in the next 1-2 years.
- Cloud GPUs are beneficial if used for less than a year. After that, the desktop version becomes cheaper.
Do I need PCIe 4.0?
Usually not. PCIe 4.0 is great for a GPU cluster. Useful if you have an 8 GPU machine. In other cases, it has almost no advantages. It improves parallelization and transfers data a little faster. But data transfer is not a bottleneck. In computer vision, the bottleneck may be data storage, but not PCIe data transfer from GPU to GPU. So there is no reason for most people to use PCIe 4.0. It will possibly improve the parallelization of four GPUs by 1-7%.
Do I need PCIe 8x / 16x lanes?
As with PCIe 4.0, usually not. PCIe lanes are required for parallelization and fast data transfer, which is almost never a bottleneck. If you have 2 GPUs, 4 lines are enough for them. For 4 GPUs, I would prefer 8 lines per GPU, but if there are 4 lines, it will decrease performance by only 5-10%.
How do you fit four RTX 3090s when they each take up 3 PCIe slots?
You can buy one of two options for one slot, or distribute them using PCIe expanders. In addition to space, you need to immediately think about cooling and a suitable power supply. Apparently, the easiest solution would be to buy 4 x RTX 3090 EVGA Hydro Coppers with a dedicated water cooling loop. EVGA has been making copper water-cooled versions of cards for many years, and you can trust the quality of their GPUs. Perhaps there are cheaper options.
PCIe expanders can solve space and cooling issues, but your case should have enough room for all the cards. And make sure the extenders are long enough!
How to cool 4 RTX 3090 or 4 RTX 3080?
See the previous section.
Can I use multiple different GPU types?
Yes, but you won't be able to effectively parallelize the work. I can imagine a system running 3 RTX 3070 + 1 RTX 3090. On the other hand, parallelization between four RTX 3070s will work very quickly if you cram your model onto them. And one more reason why you may need it is using old GPUs. This will work, but parallelization will be ineffective, as the fastest GPUs will wait for the slowest GPUs at sync points (usually when the gradient is updated).
What is NVLink and do I need it?
You usually don't need NVLink. It is a high-speed communication between multiple GPUs. It is needed if you have a cluster of 128 or more GPUs. In other cases, it has almost no advantages over standard PCIe data transfer.
I don’t have the money even for your cheapest recommendations. What to do?
Definitely buying a used GPU. Used RTX 2070 ($ 400) and RTX 2060 ($ 300) will do just fine. If you can't afford them, the next best option would be a used GTX 1070 ($ 220) or GTX 1070 Ti ($ 230). If that's too expensive, find a used GTX 980 Ti (6GB $ 150) or GTX 1650 Super ($ 190). If it's expensive too, you're better off using cloud services. They usually provide GPUs with a time or power limit, after which you have to pay. Swap services around until you can afford your own GPU.
What does it take to parallelize a project between two machines?
To speed up work by parallelizing between two machines, you need 50 Gbps or more network cards. I recommend installing at least EDR Infiniband - that is, a network card with a speed of at least 50 Gbps. Two EDR cards with cable on eBay will set you back $ 500.
In some cases, you can get by with 10 Gbps Ethernet, but this usually only works for certain types of neural networks (certain convolutional networks) or for certain algorithms (Microsoft DeepSpeed).
Are sparse matrix multiplication algorithms suitable for any sparse matrix?
Apparently not. Since a matrix is required to have 2 zeros for every 4 elements, sparse matrices must be well structured. It is probably possible to slightly tweak the algorithm by processing 4 values as a compressed representation of two values, but this will mean that the exact multiplication of sparse matrices by Ampere will not be available.
Do I need an Intel processor to run multiple GPUs?
I do not recommend using an Intel processor, unless you are putting a lot of stress on the processor in Kaggle contests (where the processor is loaded with linear algebra calculations). And even for such competitions, AMD processors are great. AMD processors are on average cheaper and better for GO. For a 4-GPU build, Threadripper is my definitive choice. At our university, we have collected dozens of systems based on such processors, and they all work perfectly, without any complaints. For systems with 8 GPUs, I would take the processor that your manufacturer has experience with. Processor and PCIe reliability in 8-card systems is more important than speed or cost efficiency.
Does the shape of the case matter for cooling?
No. Usually GPUs cool perfectly if there are even small gaps between GPUs. Different housings can give you 1-3 ° C difference, and different card spacing can give you 10-30 ° C difference. In general, if there are gaps between your cards, there is no problem with cooling. If there are no gaps, you need the right fans (blowing fan) or another solution (water cooling, PCIe expanders). In any case, the type of case and its fans do not matter.
Will AMD GPU + ROCm Ever Catch NVIDIA GPU + CUDA?
Not in the next couple of years. There are three problems: tensor kernels, software and community.
The GPU crystals themselves from AMD are good: excellent performance on FP16, excellent memory bandwidth. But the absence of tensor cores or their equivalent leads to the fact that their performance suffers in comparison with the GPU from NVIDIA. And without the implementation of tensor cores in hardware, AMD GPUs will never be competitive. According to rumors, some kind of card for data centers with an analogue of tensor cores is planned for 2020, but there is no exact data yet. If they only have a Tensor Core equivalent card for servers, that would mean few people can afford AMD GPUs, giving NVIDIA a competitive edge.
Let's say AMD will introduce hardware with something like tensor cores in the future. Then many will say: “But there are no programs working with AMD GPUs! How can I use them? " This is mostly a misconception. AMD software running ROCm is already well developed, and support in PyTorch is well organized. And although I have not seen many reports on the work of AMD GPU + PyTorch, all software functions are integrated there. Apparently, you can choose any network and run it on an AMD GPU. Therefore, AMD is already well developed in this area, and this problem has been practically solved.
However, having solved the problems with software and the lack of tensor cores, AMD is faced with one more: a lack of community. When you come across an issue with NVIDIA GPUs, you can search Google for a solution and find it. This builds confidence in NVIDIA GPUs. An infrastructure is emerging to facilitate the use of NVIDIA GPUs (any platform for GO works, any scientific task is supported). There are a bunch of hacks and tricks that make it much easier to use NVIDIA GPUs (for example, apex). NVIDIA GPU experts and programmers can be found under every bush, but I know far fewer AMD GPU experts.
In terms of the community, the AMD situation is similar to that of Julia vs Python. Julia has a lot of potential, and many will rightly point out that this programming language is better suited for scientific work. However, Julia is rarely used compared to Python. It's just that the Python community is very large. There are tons of people gathering around powerful packages like Numpy, SciPy, and Pandas. This situation is similar to that of NVIDIA vs AMD.
Therefore, it is very likely that AMD will not catch up with NVIDIA until it introduces the equivalent of tensor cores and a solid community built around ROCm. AMD will always have its market share in specific subgroups (cryptocurrency mining, data centers). But NVIDIA will most likely hold the monopoly for another two years.
When is it better to use cloud services, and when is it better to use a dedicated computer with a GPU?
A simple rule of thumb: if you expect to do GO for more than a year, it's cheaper to buy a computer with a GPU. Otherwise, it is better to use cloud services - unless you have extensive experience in cloud programming and want to take advantage of scaling the number of GPUs at will.
The exact tipping point at which cloud GPUs become more expensive than owning a computer is highly dependent on the services being used. It's better to calculate it yourself. Below is an example calculation for an AWS V100 server with one V100, and comparing it to the cost of a desktop computer with one RTX 3090, which is close in performance. An RTX 3090 PC costs $ 2200 (2-GPU barebone + RTX 3090). If you are in the US, add $ 0.12 per kWh for electricity to that. Compare that to $ 2.14 per hour per server on AWS.
At 15% recycling per year, the computer uses
(350 W (GPU) + 100 W (CPU)) * 0.15 (recycling) * 24 hours * 365 days = 591 kWh per year.
591 kWh per year gives an additional $ 71.
The tipping point, when the computer and the cloud compare in price at 15% utilization, comes around the 300th day ($ 2,311 vs $ 2,270):
$ 2.14 / h * 0.15 (recycling) * 24 hours * 300 days = $ 2,311
If you calculate, that your GO models will last more than 300 days, it is better to buy a computer than to use AWS.
Similar calculations can be made for any cloud service to decide whether to use your computer or the cloud.
Common figures for the utilization of computing power are as follows:
- PhD computer: <15%;
- GPU Cluster on PhD Slurm:> 35%
- Corporate Research Cluster on Slurm:> 60%.
In general, recycling rates are lower in areas where thinking about innovative ideas is more important than developing practical solutions. In some areas the utilization rate is lower (interpretability studies), while in others it is much higher (machine translation, language modeling). In general, recycling of personal cars is usually always overestimated. Typically, most personal systems are 5-10% recycled. Therefore, I highly recommend that research teams and companies organize GPU clusters on Slurm instead of separate desktops.
Tips for those who are too lazy to read
Best GPUs overall : RTX 3080 and RTX 3090.
GPUs to avoid (as a researcher) : Tesla cards, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Good performance / price ratio, but expensive : RTX 3080.
Good performance / price ratio, cheaper : RTX 3070, RTX 2060 Super.
I have little money : Buy used cards. Hierarchy: RTX 2070 ($ 400), RTX 2060 ($ 300), GTX 1070 ($ 220), GTX 1070 Ti ($ 230), GTX 1650 Super ($ 190), GTX 980 Ti (6GB $ 150).
I have almost no money : many startups advertise their cloud services. Use free credits in the clouds, change them in a circle until you can buy a GPU.
I compete in Kaggle competitions: RTX 3070.
I'm trying to win the competition in computer vision, pre-training or machine translation : 4 pieces RTX 3090. But wait until experts confirm that there are assemblies with good cooling and sufficient power.
I'm learning natural language processing : if you're not into machine translation, language modeling, or pre-learning, the RTX 3080 will do.
I started doing GO and got really into it : start with RTX 3070. If you don't get bored in 6-9 months, sell and buy four RTX 3080. Depending on what you choose next (startup, Kaggle, research, applied GO), years in three, sell your GPUs and buy something better (next generation RTX GPUs).
I want to try GO, but I have no serious intentions : RTX 2060 Super will be an excellent choice, however, it may require replacement of the PSU. If you have a PCIe x16 slot on your motherboard, and the PSU produces about 300 watts, then the GTX 1050 Ti will be an excellent option, since it does not require any other investment.
GPU cluster for parallel simulation with less than 128 GPUs : if you are allowed to buy RTX for the cluster: 66% 8x RTX 3080 and 33% 8x RTX 3090 (only if you can cool the assembly well). If cooling isn't enough, buy a 33% RTX 6000 GPU or 8x Tesla A100. If you can't buy an RTX GPU, I would go for 8 Supermicro A100 nodes or 8 RTX 6000 nodes.
GPU cluster for parallel simulation with more than 128 GPUs: Think about cars with 8 Tesla A100. If you need more than 512 GPUs, consider the DGX A100 SuperPOD System.