
Let's talk about a neural network that uses deep learning and reinforcement learning to play Snake. You will find the code on Github, analysis of errors, demonstrations of AI and experiments on it under the cut.
Ever since I watched the Netflix documentary about AlphaGo, I've been fascinated by reinforcement learning. Such learning is comparable to human learning: you see something, you do something, and your actions have consequences. Good or bad. You learn from the consequences and correct actions. Reinforcement learning has many applications: autonomous driving, robotics, trading, games. If you are familiar with reinforcement learning, skip the next two sections.
Reinforcement learning
The principle is simple. The agent learns through interaction with the environment. He chooses an action and receives a response from the environment in the form of states (or observations) and rewards. This cycle continues continuously or until it is interrupted. Then a new episode begins. Schematically it looks like this:

The goal of the agent is to get the maximum rewards per episode. At the beginning of training, the agent examines the environment: tries different actions in the same state. As the learning progresses, the agent researches less and less. Instead, he chooses the most rewarding action based on his own experience.
Deep Reinforcement Learning
Deep learning uses neural networks to generate outputs from inputs. With just one hidden layer, deep learning can zoom in on any feature. How it works? A neural network is layers with nodes. The first layer is the input data layer. The hidden second layer transforms the data using weights and an activation function. The last layer is the forecast layer.

As the name suggests, deep reinforcement learning is a combination of deep learning and reinforcement learning. The agent learns to predict the best action for a given state using states as inputs, values for actions as outputs, and rewards to adjust the weights in the right direction. Let's write a Snake using deep reinforcement learning.

Defining actions, rewards, and conditions
To prepare the game for the agent, we formalize the problem. Defining actions is easy. The agent can choose the direction: up, right, down or left. The rewards and state of the space are a little more complicated. There are many solutions and one will work better and the other worse. I will describe one of them below and let's try it.
If Snake picks up an apple, her reward is 10 points. If the Snake dies, subtract 100 points from the award. To help the agent, add 1 point when the Snake passes close to the apple and subtract one point when the Snake moves away from the apple.
The state has many options. You can take the coordinates of the Snake and the apple or the direction to the apple. It is important to add the location of obstacles, that is, the walls and body of the Snake, so that the agent learns to survive. Below is a summary of actions, conditions and rewards. We will see later how state adjustments affect performance.

Create environment and agent
By adding methods to the Snake program, we create a reinforcement learning environment. The methods are as follows:
reset(self), step(self, action)and get_state(self). In addition, you need to calculate the reward at every step of the agent. Take a look at run_game(self).
The agent works with the Deep Q network to find the best action. Model parameters below:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
If you are interested in looking at the code, you can find it on GitHub .
Agent plays Snake
And now - the key question! Will the agent learn to play? Let's see how it interacts with the environment. Below are the first games. The agent does not understand anything:

The first apple! But it still looks like the neural network doesn't know what it is doing.

Finds the first apple ... and later hits the wall. The beginning of the fourteenth game:

The agent learns: his path to the apple is not the shortest, but he finds the apple. Below is the thirtieth game:

After only 30 games, Snake avoids collisions with itself and finds a quick way to the apple.
Let's play with space
It may be possible to change the state space and achieve similar or better performance. Below are the possible options.
- No Directions: Do not tell the agent the directions in which the Snake is moving.
- State with coordinates: replace the position of the apple (up, right, down, and / or left) with the coordinates of the apple (x, y) and the snake (x, y). Coordinate values are on a scale from 0 to 1.
- Direction 0 or 1 state.
- Wall only state: Reports only if there is a wall. But not about where the body is: below, above, right or left.

Below are performance graphs for different states:
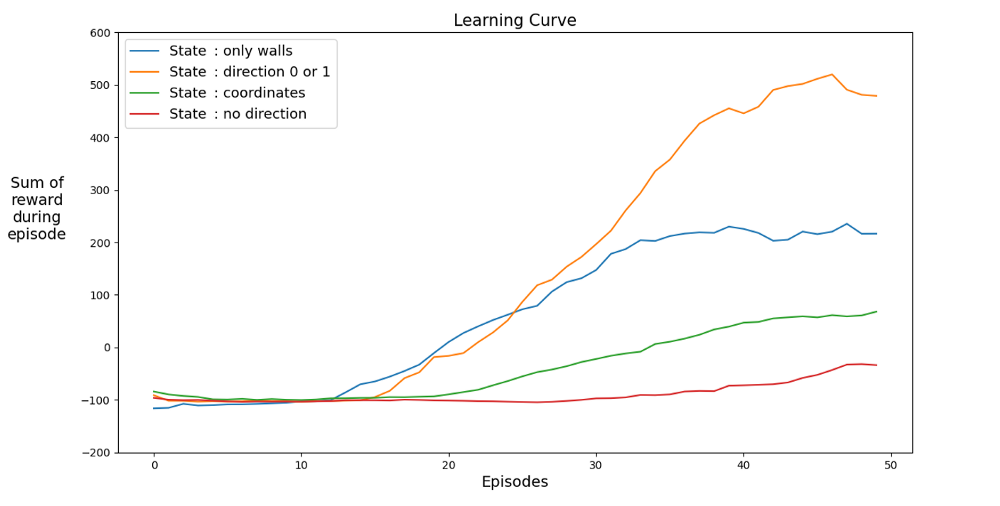
Let's find a space that speeds up learning. The graph shows the average achievements of the last 12 games with different states.
It is clear that when the state space has directions, the agent learns quickly, achieving the best results. But space with coordinates is better. Maybe you can achieve better results by training the network for longer. The reason for the slow learning may be the number of possible states: 20⁴ * 2⁴ * 4 = 1,024,000. A 20 by 20 course, 64 obstacle options and 4 current heading options. For the original variant space, 3² * 2⁴ * 4 = 576. This is more than 1700 times less than 1,024,000 and of course affects learning.
Let's play with awards
Is there a better internal reward logic? Let me remind you that the Snake is awarded like this:

First mistake. Walking in circles
What if you changed -1 to +1? This can slow down the learning curve, but in the end the Snake does not die. And this is very important for the game. The agent quickly learns to avoid death.

At one time interval, the agent receives one point for survival.
Second mistake. Hit the wall
Change the number of points for passing around the apple to -1. Let's set the reward for the apple itself at 100 points. What will happen? The agent receives a penalty for each movement, so he moves to the apple as quickly as possible. It can happen, but there is another option.

AI walks along the nearest wall to minimize losses.
Experience
You only need 30 games. The secret of artificial intelligence is the experience of previous games, which is taken into account so that the neural network learns faster. At each regular step, a series of replay steps (parameter
batch_size) are performed . This works so well because, for a given pair of action and state, the difference in reward and the next state is small.
Mistake number 3. No experience Is experience
really that important? Let's take it out. And take the 100 point reward for the apple. Below is an agent with no experience who has played 2500 games.

Although the agent played 2500 (!) Games, he does not play the snake. The game ends quickly. Otherwise 10,000 games would have taken days. After 3000 games we only have 3 apples. After 10,000 games, apples are still 3. Is it luck or a learning outcome?
Indeed, experience helps a lot. At least an experience that takes into account rewards and type of space. How many replays do you need per step? The answer may be surprising. To answer this question, let's play with the batch_size parameter. In the original experiment it was set to 500. Overview of results with different experiences:

200 games with different experience: 1 game (no experience), 2 and 4. Average for 20 games.
Even with experience in 2 games, the agent is already learning to play. In the graph you see the impact
batch_size, the same performance is achieved for 100 games if 4 is used instead of 2. The solution in the article gives the result. The agent learns to play Snake and achieves good results, collecting 40 to 60 apples in 50 games.
An attentive reader may say: the maximum number of apples in a snake is 399. Why doesn't AI win? The difference between 60 and 399 is, in fact, small. And this is true. And there is a problem here: The snake does not avoid collisions when looping back.
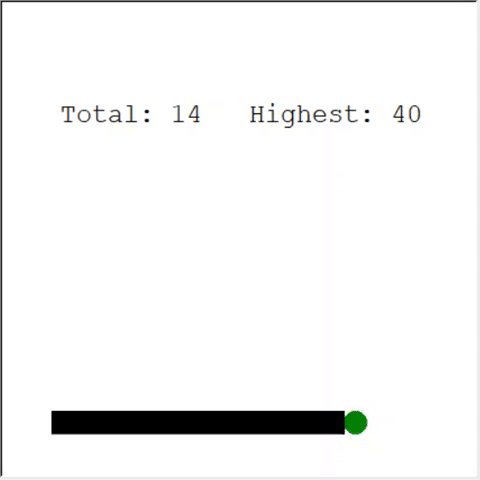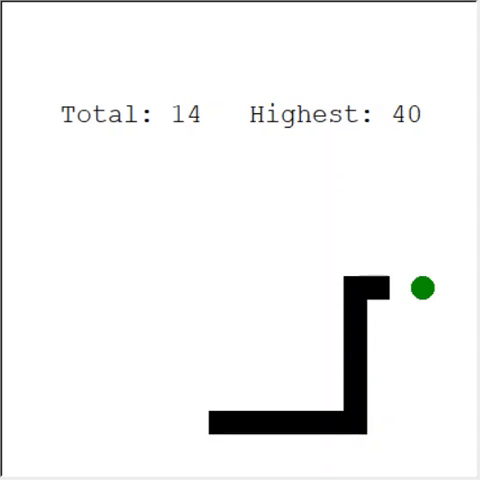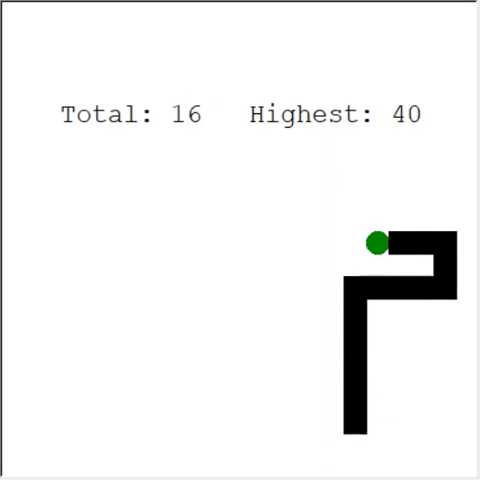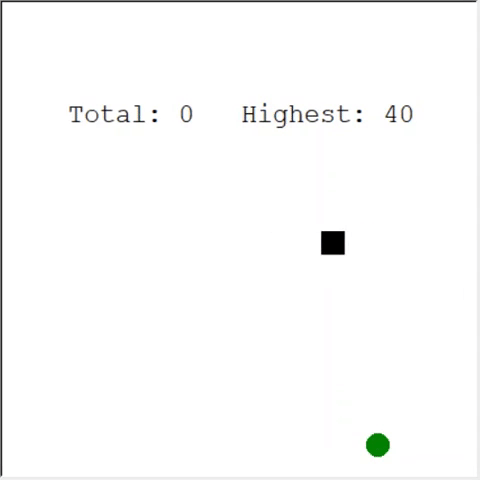
An interesting way to solve the problem is to use CNN for the field of play. This way the AI can see the entire game, not just the nearby obstacles. He will be able to recognize the places that need to be avoided in order to win.
Bibliography
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
