
WebAssembly (abbreviated WASM) is a technology for running pre-compiled binary code in a browser on the client side. It was first introduced in 2015 and is currently supported by most modern browsers.
One common use case is client-side preprocessing of data before sending files to the server. In this article, we will understand how this is done.
Before the beginning
The WebAssembly architecture and general steps are described in more detail here and here . We will go over only the basic facts.
Working with WebAssembly begins with pre-assembling the artifacts required to run the compiled code on the client side. There are two of them: the binary WASM file itself and a JavaScript layer through which you can call the methods exported to it.
An example of the simplest C ++ code for compilation
#include <algorithm>
extern "C" {
int calculate_gcd(int a, int b) {
while (a != 0 && b != 0) {
a %= b;
std::swap(a, b);
}
return a + b;
}
}For assembly, Emscripten is used , which, in addition to the main interface of such compilers, contains additional flags through which the virtual machine configuration and exported methods are set. The simplest launch looks like this:
em++ main.cpp --std=c++17 -o gcd.html \
-s EXPORTED_FUNCTIONS='["_calculate_gcd"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]'By specifying a * .html file as an object , it tells the compiler to create a simple html markup with a js console as well. Now, if we start the server on the received files, we will see this console with the ability to run _calculate_gcd:
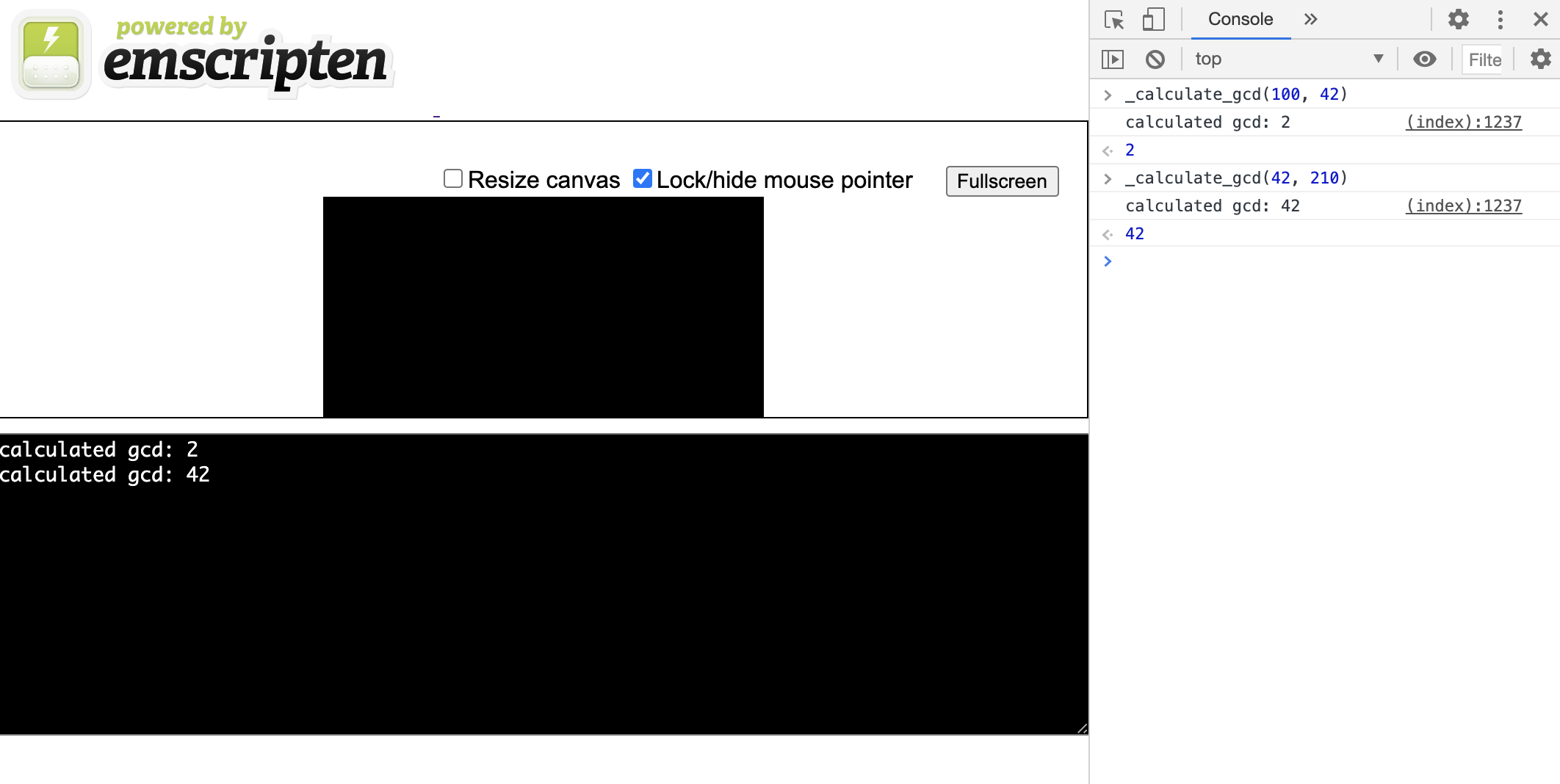
Data processing
Let's analyze it using a simple example of lz4 compression using a library written in C ++. Note that the many languages supported do not end there.
Despite the simplicity and some synthetics of the example, this is a rather useful illustration of how to work with data. Similarly, you can perform any actions on them for which the client's power is sufficient: image preprocessing before sending to the server, audio compression, counting various statistics, and much more.
The entire code can be found here.
C ++ part
We use a ready-made implementation of lz4 . Then the main file will look very laconic:
#include "lz4.h"
extern "C" {
uint32_t compress_data(uint32_t* data, uint32_t data_size, uint32_t* result) {
uint32_t result_size = LZ4_compress(
(const char *)(data), (char*)(result), data_size);
return result_size;
}
uint32_t decompress_data(uint32_t* data, uint32_t data_size, uint32_t* result, uint32_t max_output_size) {
uint32_t result_size = LZ4_uncompress_unknownOutputSize(
(const char *)(data), (char*)(result), data_size, max_output_size);
return result_size;
}
}As you can see, it simply declares external (using the extern keyword ) functions that internally call the corresponding methods from the library with lz4.
Generally speaking, in our case, the file is useless: you can immediately use the native interface of lz4.h . However, in more complex projects (for example, combining the functionality of different libraries), it is convenient to have such a common entry point listing all the functions used.
Next, we compile the code using the already mentioned Emscripten compiler :
em++ main.cpp lz4.c -o wasm_compressor.js \
-s EXPORTED_FUNCTIONS='["_compress_data","_decompress_data"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]' \
-s WASM=1 -s ALLOW_MEMORY_GROWTH=1The size of the artifacts received is alarming:
$ du -hs wasm_compressor.*
112K wasm_compressor.js
108K wasm_compressor.wasm
If you open the JS file-layer, you can see something like the following:

It contains a lot of unnecessary things: from comments to service functions, most of which are not used. The situation can be corrected by adding the -O2 flag, in the Emscripten compiler, it also includes js code optimization.
After that, the js code looks nicer:

Client code
You need to call the client side handler somehow. First of all, load the file provided by the user through
FileReader, we will store the raw data in a primitive Uint8Array:
var rawData = new Uint8Array(fileReader.result);Next, you need to transfer the downloaded data to the virtual machine. To do this, first we allocate the required number of bytes using the _malloc method, then copy the JS array there using the set method. For convenience, let's separate this logic into the arrayToWasmPtr (array) function:
function arrayToWasmPtr(array) {
var ptr = Module._malloc(array.length);
Module.HEAP8.set(array, ptr);
return ptr;
}After loading the data into the memory of the virtual machine, you need to somehow call the function from processing. But how to find this function? The cwrap method will help us - the first argument in it specifies the name of the required function, the second - the return type, and the third - a list with input arguments.
compressDataFunction = Module.cwrap('compress_data', 'number', ['number', 'number', 'number']);Finally, you need to return the finished bytes from the virtual machine. To do this, we write another function that copies them into a JS array using the method
subarray
function wasmPtrToArray(ptr, length) {
var array = new Int8Array(length);
array.set(Module.HEAP8.subarray(ptr, ptr + length));
return array;
}The complete script for processing incoming files is here . HTML markup containing file upload form and wasm artifacts upload here .
Outcome
You can play around with the prototype here .
The result is a working backup using WASM. Of the minuses - the current implementation of the technology does not allow freeing memory allocated in the virtual machine. This creates an implicit leak when a large number of files are loaded in one session, but can be fixed by reusing existing memory instead of allocating new one.

