
More and more often the following requests are received from customers: “We want it like Amazon RDS, but cheaper”; "We want it like RDS, but everywhere, in any infrastructure." To implement such a managed solution on Kubernetes, we looked at the current state of the most popular operators for PostgreSQL (Stolon, operators from Crunchy Data and Zalando) and made our choice.
This article is our experience both from a theoretical point of view (review of solutions) and from a practical point of view (what was chosen and what came of it). But first, let's determine what the general requirements are for a potential replacement for RDS ...
What is RDS
When people talk about RDS, in our experience they mean a managed DBMS service that:
- easily customizable;
- has the ability to work with snapshots and recover from them (preferably with PITR support );
- allows you to create master-slave topologies;
- has a rich list of extensions;
- provides auditing and user / access management.
Generally speaking, the approaches to the implementation of the task can be very different, but the path with conditional Ansible is not close to us. (A similar conclusion was reached by colleagues at 2GIS as a result of their attempt to create a "tool for quickly deploying a failover cluster based on Postgres.")
Operators are the generally accepted approach for solving such problems in the Kubernetes ecosystem. More details about them in relation to databases running inside Kubernetes have already been told by the Flant tech department,distol, in one of his reports .
NB : To quickly create simple operators, we recommend paying attention to our open source shell-operator utility . Using it, you can do this without knowledge of Go, but in ways more familiar to sysadmins: in Bash, Python, etc.
There are several popular K8s operators for PostgreSQL:
- Stolon;
- Crunchy Data PostgreSQL Operator;
- Zalando Postgres Operator.
Let's take a closer look at them.
Operator selection
In addition to the important capabilities already mentioned above, we - as infrastructure operations engineers at Kubernetes - also expected the following from operators:
- deploy from Git and from Custom Resources ;
- pod anti-affinity support;
- installing node affinity or node selector;
- setting tolerations;
- availability of tuning opportunities;
- understandable technologies and even commands.
Without going into details on each of the points (ask in the comments if you have any questions about them after reading the entire article), I note in general that these parameters are needed for a more detailed description of the specialization of cluster nodes in order to order them for specific applications. This way we can achieve the optimal balance between performance and cost.
Now for the PostgreSQL operators themselves.
1. Stolon
Stolon from the Italian company Sorint.lab in the already mentioned report was considered as a kind of benchmark among operators for DBMS. This is a rather old project: its first public release took place back in November 2015 (!), And the GitHub repository boasts almost 3000 stars and 40+ contributors.
Indeed, Stolon is a great example of well thought out architecture:
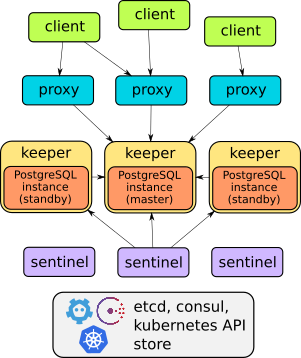
The details of this operator's device can be found in the report or project documentation . In general, suffice it to say that he can do everything described: failover, proxies for transparent client access, backups ... Moreover, proxies provide access through one endpoint service - unlike the other two solutions considered further (they have two services for accessing base).
However, Stolon does not have Custom Resources , which is why it cannot be deployed in such a way as to easily and quickly - "like hot cakes" - create DBMS instances in Kubernetes. Management is carried out through the utility
stolonctl, deployment - through the Helm-chart, and user settings are defined in ConfigMap.
On the one hand, it turns out that the operator is not very much an operator (after all, it does not use CRD). But on the other hand, it is a flexible system that allows you to customize resources in K8s the way you like.
To summarize, for us personally, it didn’t seem to be the optimal way to create a separate chart for each database. Therefore, we began to look for alternatives.
2. Crunchy Data PostgreSQL Operator
The operator from Crunchy Data , a young American startup, looked like a logical alternative. Its public history begins with the first release in March 2017, since then the GitHub repository has received just under 1300 stars and 50+ contributors. The latest release from September was tested to work with Kubernetes 1.15-1.18, OpenShift 3.11+ and 4.4+, GKE and VMware Enterprise PKS 1.3+.
The Crunchy Data PostgreSQL Operator architecture also meets the stated requirements:
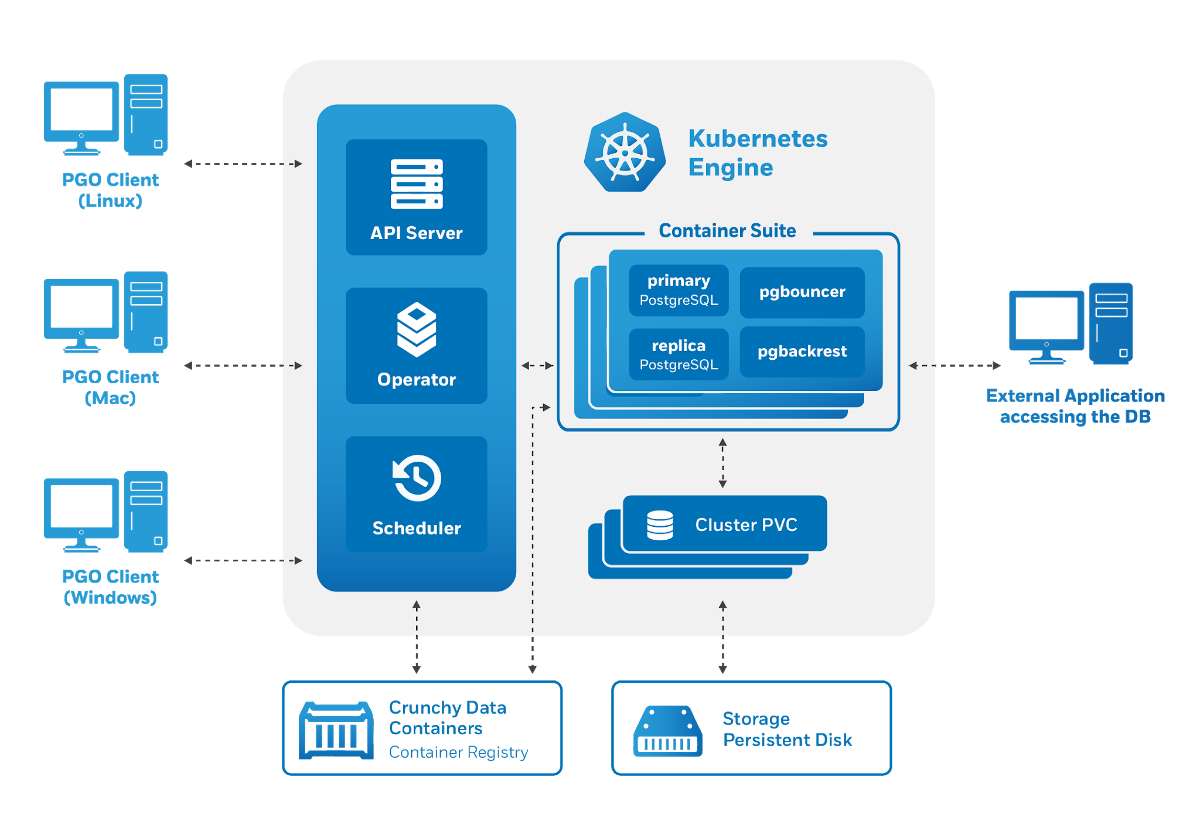
Management is done through a utility
pgo, but it in turn generates Custom Resources for Kubernetes. Therefore, the operator pleased us as potential users:
- there is control via CRD;
- convenient user management (also via CRD);
- integration with other components of the Crunchy Data Container Suite - a specialized collection of container images for PostgreSQL and utilities for working with it (including pgBackRest, pgAudit, contrib extensions, etc.).
However, attempts to start using the operator from Crunchy Data revealed several problems:
- There was no possibility of tolerations - only nodeSelector is provided.
- The pods we created were part of the Deployment, despite the fact that we deployed a stateful application. Unlike StatefulSets, Deployments cannot create disks.
The last drawback leads to funny moments: on the test environment, it was possible to run 3 replicas with one local storage disk , as a result of which the operator reported that 3 replicas were working (although this was not the case).
Another feature of this operator is its ready-made integration with various auxiliary systems. For example, it is easy to install pgAdmin and pgBounce, and the documentation covers the pre-configured Grafana and Prometheus. The recent release 4.5.0-beta1 separately notes improved integration with the pgMonitor project , thanks to which the operator offers a visual visualization of PgSQL metrics out of the box.
However, the strange choice of generated Kubernetes resources led us to find another solution.
3. Zalando Postgres Operator
We have known Zalando products for a long time: we have experience using Zalenium and, of course, we tried Patroni - their popular HA solution for PostgreSQL. One of its authors, Aleksey Klyukin, spoke about the company's approach to the creation of Postgres Operator on Postgres-Tuesday # 5 , and we liked it.
This is the youngest solution discussed in the article: the first release took place in August 2018. However, even with a small number of formal releases, the project has come a long way, already surpassing the popularity of the solution from Crunchy Data with 1300+ stars on GitHub and the maximum number of contributors (70+).
Under the hood of this operator, time-tested solutions are used:
This is how Zalando's operator architecture is presented:
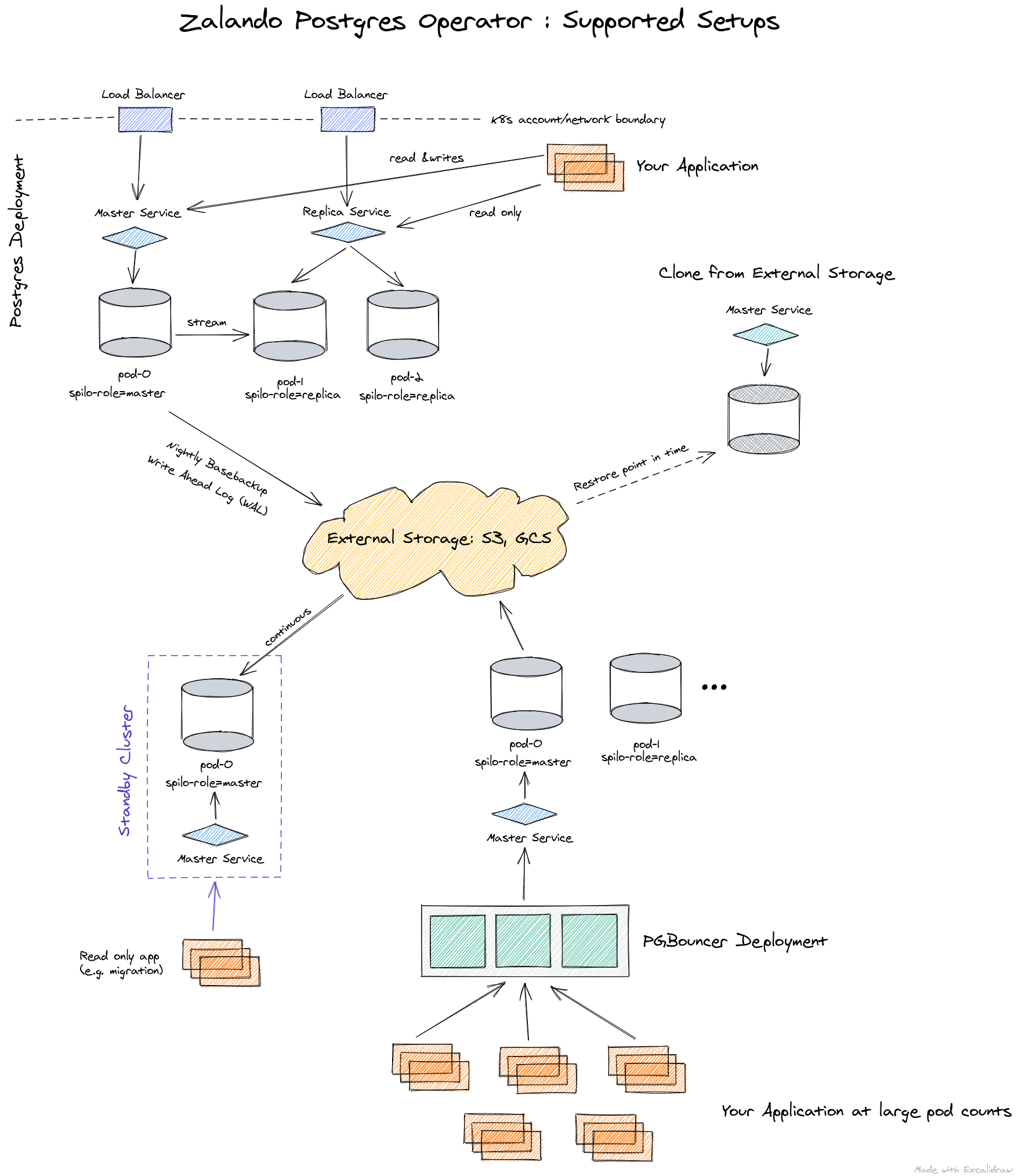
The operator is fully managed through Custom Resources, automatically creates a StatefulSet from containers, which can then be customized by adding various sidecars to the pods. All this is a significant plus in comparison with the operator from Crunchy Data.
Since it was the solution from Zalando that we chose among the 3 options under consideration, a further description of its capabilities will be presented below, immediately along with the practice of application.
Practice with Zalando's Postgres Operator
Deploying an operator is very simple: just download the current release from GitHub and apply the YAML files from the manifests directory . Alternatively, you can also use OperatorHub .
After installation, you should worry about setting up storages for logs and backups . It is done via ConfigMap
postgres-operatorin the namespace where you installed the statement. With the repositories configured, you can deploy your first PostgreSQL cluster.
For example, our standard deployment looks like this:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
This manifest deploys a cluster of 3 instances with a sidecar in the form of postgres_exporter , from which we take application metrics. As you can see, everything is very simple, and if you wish, you can create literally an unlimited number of clusters.
It is worth paying attention to the web administration panel - postgres-operator-ui . It comes with the operator and allows you to create and delete clusters, as well as work with backups made by the operator.
PostgreSQL Cluster List
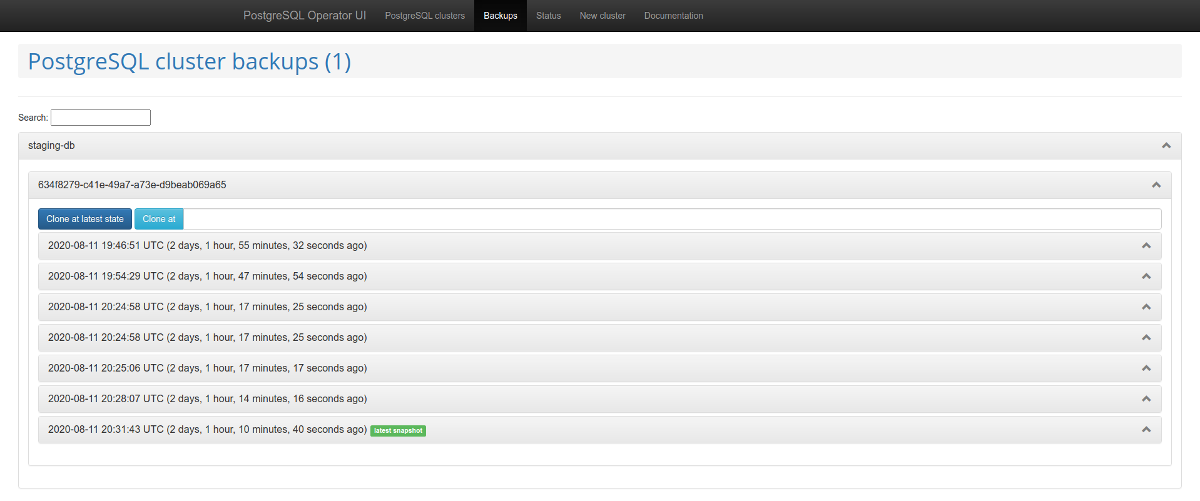
Backups Management
Another interesting feature is Teams API support . This mechanism automatically creates roles in PostgreSQLbased on the resulting list of usernames. After that, the API allows you to return a list of users for whom roles are automatically created.
Problems and solutions
However, the use of the operator soon revealed several significant disadvantages:
- lack of nodeSelector support;
- inability to disable backups;
- when using the database creation function, default privileges do not appear;
- periodically there is not enough documentation or it is out of date.
Fortunately, many of them can be resolved. Let's start at the end - problems with documentation .
Most likely, you will come across the fact that it is not always clear how to register a backup and how to connect a backup bucket to the Operator UI. The documentation talks about this in passing, but the real description is in the PR :
- you need to make a secret;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
However, as it turned out, this is currently impossible. That is why we have put together our own version of the operator with some additional third-party developments. See below for more details.
If you pass the parameters for the backup to the operator, namely, the
wal_s3_bucketaccess keys in AWS S3, then he will backup everything : not only the bases in production, but also staging. It didn't suit us.
In the description of the parameters to Spilo, which is the basic Docker wrapper for PgSQL when using the operator, it turned out that you can pass the parameter
WAL_S3_BUCKETempty, thereby disabling backups. Moreover, to great joy, a ready-made PR was found , which we immediately accepted into our fork. Now it is enough to simply add the enableWALArchiving: falsePostgreSQL cluster to the resource.
Yes, there was an opportunity to do it differently by running 2 operators: one for staging (without backups), and the second for production. But so we were able to get by with one.
Ok, we learned how to transfer access for S3 to the databases and backups began to get into the storage. How to make backup pages work in Operator UI?

In Operator UI, you need to add 3 variables:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
After that, managing backups will become available, which in our case will simplify work with staging, allowing you to deliver slices from production there without additional scripts.
Another plus was called the work with the Teams API and the wide possibilities for creating databases and roles using operator tools. However, the roles that were created did not have default rights . Accordingly, a user with read rights could not read the new tables.
Why is that? Despite the fact that the code contains the necessary ones
GRANT, they are not always used. There are 2 methods: syncPreparedDatabasesand syncDatabases. B syncPreparedDatabases- despite the fact that preparedDatabases there is a condition in the section defaultRolesanddefaultUsersto create roles, the default rights are not applied. We are in the process of preparing a patch so that these rights are automatically applied.
And the last moment in the improvements that are relevant for us is a patch that adds Node Affinity to the created StatefulSet. Our clients often prefer to cut costs by using spot instances, and they clearly shouldn't host database services. This issue could be solved through tolerations, but the presence of Node Affinity gives a lot of confidence.
What happened?
As a result of solving the above problems, we forked Postgres Operator from Zalando into our repository , where it is built with such useful patches. And for the sake of convenience, we also assembled a Docker image .
Forked PR list:
- building in Docker a secure lightweight image for the operator ;
- disable backups ;
- updating resource versions for current k8s versions ;
- implementation of Node Affinity .
It will be great if the community supports these PRs so that they get upstream with the next version of the operator (1.6).
Bonus! Production migration success story
If you are using Patroni, live production can be migrated to the operator with minimal downtime.
Spilo allows you to make standby clusters through S3 storages with Wal-E , when the PgSQL binary log is first saved to S3 and then downloaded by the replica. But what if you don't have Wal-E in your old infrastructure? The solution to this problem has already been proposed on Habré.
PostgreSQL logical replication comes to the rescue. However, we will not go into details on how to create publications and subscriptions, because ... our plan has failed.
The fact is that the database had several loaded tables with millions of rows, which, moreover, were constantly replenished and deleted. Simple subscription with
copy_data, when a new replica copies all content from the master, it simply did not keep up with the master. Copying the content worked for a week, but it never caught up with the master. As a result, an article by colleagues from Avito helped to deal with the problem : you can transfer data using pg_dump. I will describe our (slightly modified) version of this algorithm.
The idea is that you can make an off subscription tied to a specific replication slot and then fix the transaction number. There were replicas for production work. This is important because the replica will help create a consistent dump and continue to receive changes from the master.
In subsequent commands describing the migration process, the following host notations will be used:
- master - source server;
- replica1 - streaming replica on old production;
- replica2 is a new logical replica.
Migration plan
1. In the wizard, create a subscription to all tables in the
publicdatabase schema dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Let's create a replication slot on the master:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Stop replication on the old replica:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Get the transaction number from the master:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Dump the old replica. We will do this in several threads, which will help speed up the process:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Upload dump to the new server:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. After downloading the dump, you can start replication on the streaming replica:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Let's create a subscription on a new logical replica:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Get
oidsubscriptions:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Let's say it was received
oid=1000. Let's apply the transaction number to the subscription:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Let's start replication:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Check the subscription status, replication should work:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. After replication has started and the databases are synchronized, you can switch over.
13. After disabling replication, you need to correct the sequences. This is well documented in an article on wiki.postgresql.org .
Thanks to this plan, the switchover went through with minimal delays.
Conclusion
Kubernetes operators allow you to simplify various activities by reducing them to creating K8s resources. However, having achieved remarkable automation with their help, it is worth remembering that it can bring a number of unexpected nuances, so choose your operators wisely.
After reviewing the three most popular Kubernetes operators for PostgreSQL, we opted for a project from Zalando. And we had to overcome certain difficulties with him, but the result was really pleased, so we plan to expand this experience to some other PgSQL installations. If you have experience using similar solutions, we will be glad to see the details in the comments!
PS
Read also on our blog: