I continue my story about how to make Exchange and ELK friends (start here ). Let me remind you that this combination is capable of handling a very large number of logs without hesitation. This time we'll talk about how to get Exchange working with the Logstash and Kibana components.
Logstash in the ELK stack is used to intelligently process logs and prepare them for placement in Elastic in the form of documents, on the basis of which it is convenient to build various visualizations in Kibana.
Installation
Consists of two stages:
- Installing and configuring the OpenJDK package.
- Installing and configuring the Logstash package.
Installing and Configuring the OpenJDK
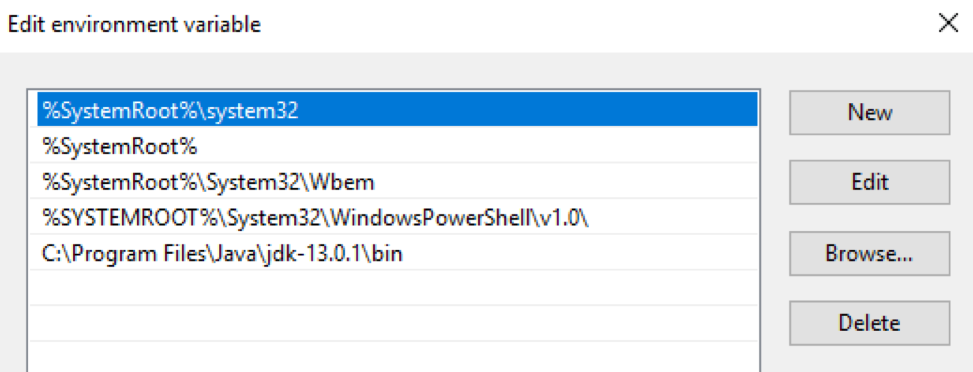
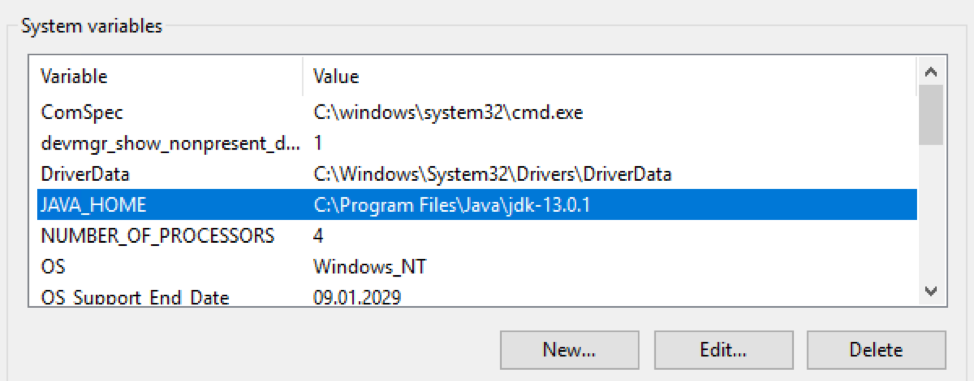
Package The OpenJDK package must be downloaded and unpacked into a specific directory. Then the path to this directory must be entered into the variables $ env: Path and $ env: JAVA_HOME of the Windows operating system:
Check the Java version:
PS C:\> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
Installing and configuring the Logstash package
Download the archive file with the Logstash distribution from here . The archive must be unpacked to the root of the disk.
C:\Program FilesYou should not unpack it into a folder , Logstash will refuse to start normally. Then you need to make jvm.optionschanges to the file that are responsible for allocating RAM for the Java process. I recommend specifying half of the server's RAM. If he has 16 GB of RAM on board, then the default keys are:
-Xms1g
-Xmx1g
must be replaced with:
-Xms8g
-Xmx8g
It is also advisable to comment out the line
-XX:+UseConcMarkSweepGC. Read more about it here . The next step is to create a default configuration in the logstash.conf file:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
With this configuration, Logstash reads data from the console, passes it through an empty filter, and writes back to the console. Applying this configuration will test the functionality of Logstash. To do this, let's launch it interactively:
PS C:\...\bin> .\logstash.bat -f .\logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash successfully launched on port 9600.
The final step of the installation is to launch Logstash as a Windows service. This can be done, for example, using the NSSM package :
PS C:\...\bin> .\nssm.exe install logstash
Service "logstash" installed successfully!
fault tolerance
The Persistent Queues mechanism ensures the safety of logs during transmission from the source server.
How does it work
The layout of queues during log processing: input → queue → filter + output.
The input plugin receives data from the log source, writes it to the queue and sends a confirmation of receipt of the data to the source.
Messages from the queue are processed by Logstash, pass the filter and the output plugin. Upon receiving confirmation from output of sending a log, Logstash removes the processed log from the queue. If Logstash stops, then all unprocessed messages and messages that have not received confirmation of sending remain in the queue, and Logstash will continue to process them the next time it starts.
Setting up
Regulated by keys in the file
C:\Logstash\config\logstash.yml:
queue.type: (possible values arepersistedandmemory (default)).path.queue: (path to the folder with queue files, which are stored in C: \ Logstash \ queue by default).queue.page_capacity: (the maximum page size of the queue, the default is 64mb).queue.drain: (true / false - enables / disables stopping the queue processing before turning off Logstash. I do not recommend turning it on, because this will directly affect the server shutdown speed).queue.max_events: (maximum number of events in the queue, default - 0 (unlimited)).queue.max_bytes: (maximum queue size in bytes, default is 1024mb (1gb)).
If
queue.max_eventsand are configured queue.max_bytes, messages will stop being received in the queue when the value of any of these settings is reached. Read more about Persistent Queues here .
An example of the part of logstash.yml responsible for setting up a queue:
queue.type: persisted
queue.max_bytes: 10gb
Setting up
Logstash configuration usually consists of three parts, responsible for different phases of processing incoming logs: receiving (input section), parsing (filter section) and sending to Elastic (output section). Below we will take a closer look at each of them.
Input
The incoming stream with raw logs is received from the filebeat agents. It is this plugin that we specify in the input section:
input {
beats {
port => 5044
}
}
After this setting, Logstash starts listening on port 5044, and when receiving logs, processes them according to the settings in the filter section. If necessary, you can wrap the channel for receiving logs from filebit in SSL. Read more about the beats plugin settings here .
Filter
All interesting text logs that Exchange generates for processing are in csv format with the fields described in the log file itself. For parsing csv records, Logstash offers us three plugins: dissect , csv and grok. The first is the fastest , but it can only parse the simplest logs.
For example, it will split the following record into two (due to the presence of a comma inside the field), which will cause the log to be parsed incorrectly:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
It can be used when parsing logs, for example, IIS. In this case, the filter section might look like this:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
The Logstash configuration allows conditional statements , so we can only send logs to the dissect plugin that have been marked with a filebeat tag
IIS. Inside the plugin, we match the field values with their names, delete the original field messagethat contained the entry from the log, and we can add an arbitrary field that will, for example, contain the name of the application from which we collect logs.
In the case of tracking logs, it is better to use the csv plugin, it can correctly process complex fields:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
Inside the plugin, we match the field values with their names, delete the original field
message(as well as the tenant-idand fields schema-version) that contained the entry from the log, and we can add an arbitrary field that will, for example, contain the name of the application from which we collect logs.
At the exit from the filtering stage, we will get documents in a first approximation, ready for rendering in Kibana. We will miss the following:
- Numeric fields will be recognized as text, preventing operations from being performed on them. Namely, the
time-takenIIS log fields , as well as the Tracking fieldsrecipient-countandtotal-biteslog. - The standard document timestamp will contain the log processing time, not the server-side recording time.
- The field
recipient-addresswill look like a single construction, which does not allow for analysis with counting the recipients of letters.
Now is the time to add some magic to the log processing process.
Converting numeric fields
The dissect plugin has an option
convert_datatypethat you can use to convert a text field to digital format. For example, like this:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
It is worth remembering that this method is only suitable if the field will definitely contain a string. The option does not process null values from the fields and is thrown into an exception.
For tracking logs, it is better not to use a similar convert method, since the fields
recipient-countand total-bitescan be empty. It's better to use the mutate plugin to convert these fields :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
Splitting recipient_address into individual recipients
This task can also be solved using the mutate plugin:
mutate {
split => ["recipient_address", ";"]
}
Changing the timestamp
In the case of tracking logs, the task is very easily solved by the date plugin , which will help to write the
timestampdate and time in the field in the required format from the field date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
In the case of IIS logs, we will need to combine the field data
dateand time, using the mutate plugin, register the time zone we need and place this time stamp in timestampusing the date plugin:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
Output
The output section is used to send processed logs to the log receiver. In the case of sending directly to Elastic, the elasticsearch plugin is used , which specifies the server address and the template for the index name to send the generated document:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Final configuration
The final configuration will look like this:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Useful links:
- How to install OpenJDK 11 on Windows?
- Download Logstash
- Elastic uses depricated option UseConcMarkSweepGC # 36828
- NSSM
- Persistent queues
- Beats input plugin
- Logstash Dude, where's my chainsaw? I need to dissect my logs
- Dissect filter plugin
- Conditionals
- Mutate filter plugin
- Date filter plugin
- Elasticsearch output plugin