But what if you start using some non-SAP and preferably OpenSource product as a storage? We at X5 Retail Group chose GreenPlum. This, of course, solves the cost issue, but at the same time, questions immediately arise that, when using SAP BW, were solved almost by default.

In particular, how to retrieve data from source systems, which are mostly SAP solutions?
HR Metrics was the first project to address this issue. Our goal was to create a warehouse for HR data and build analytical reporting in the area of work with employees. In this case, the main source of data is the SAP HCM transactional system, in which all personnel, organizational and salary activities are conducted.
Data Extraction
There are standard data extractors in SAP BW for SAP systems. These extractors can automatically collect the necessary data, track their integrity, and determine the deltas of changes. For example, here is a standard data source for employee attributes 0EMPLOYEE_ATTR:

Result of data extraction from it one employee at a time:
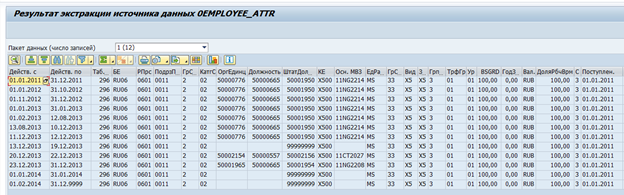
If necessary, such an extractor can be modified to suit your own requirements, or your own extractor can be created.
The first idea arose about the possibility of their reuse. Unfortunately, this turned out to be an impossible task. Most of the logic is implemented on the SAP BW side, and it was not possible to painlessly separate the extractor at the source from SAP BW.
It became obvious that it would be necessary to develop a custom mechanism for extracting data from SAP systems.
Data storage structure in SAP HCM
To understand the requirements for such a mechanism, you first need to determine what kind of data we need.
Most of the data in SAP HCM is stored in flat SQL tables. Based on this data, SAP applications visualize organizational structures, employees and other HR information to the user. For example, this is how an organizational structure looks in SAP HCM:
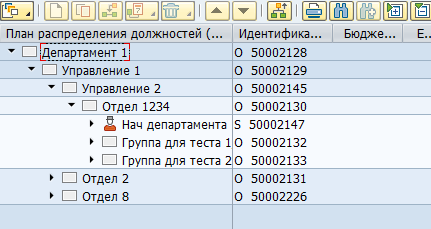
Physically, such a tree is stored in two tables - in hrp1000 objects and in hrp1001 the links between these objects.
Objects "Department 1" and "Office 1":

Relationship between objects:

There can be a huge number of both types of objects and types of communication between them. There are both standard links between objects, and customized for your own specific needs. For example, the standard B012 relationship between an organizational unit and a full-time position indicates the head of the department.
Manager mapping in SAP:
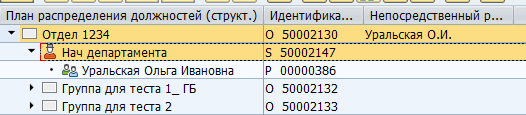
Storage in DB table:

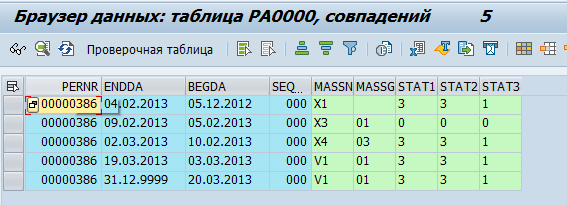
Employee data is stored in pa * tables. For example, data on staffing activities for an employee is stored in the pa0000 table.
We have decided that GreenPlum will take "raw" data, i.e. just copy them from SAP tables. And already directly in GreenPlum they will be processed and converted into physical objects (for example, Department or Employee) and metrics (for example, average headcount).
About 70 tables were defined, the data from which must be transferred to GreenPlum. After that, we started to work out a way to transfer this data.
SAP offers a fairly large number of integration mechanisms. But the easiest way - direct access to the database is prohibited due to licensing restrictions. Thus, all integration flows must be implemented at the application server level.
The next problem was the lack of data about deleted records in the SAP database. When a row is deleted in the database, it is physically deleted. Those. the formation of a delta of changes over the time of change was not possible.
Of course, SAP HCM has mechanisms for committing data changes. For example, for subsequent transmission to systems, recipients have change pointers that record any changes and on the basis of which an Idoc is formed (an object for transmission to external systems).
Example of IDoc for changing infotype 0302 for employee with personnel number 1251445:
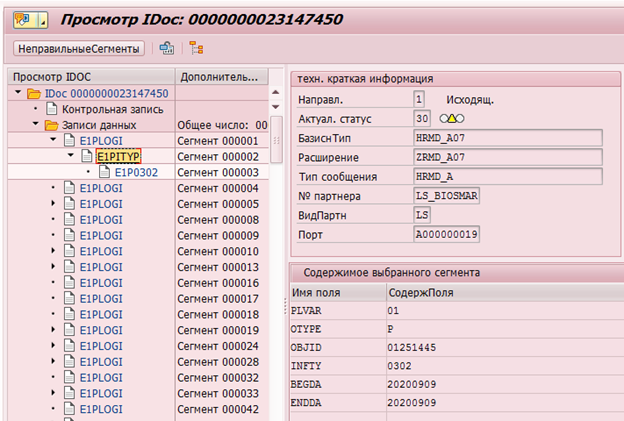
Or maintaining data change logs in table DBTABLOG.
An example of a log for deleting an entry with the QK53216375 key from the hrp1000 table:

But these mechanisms are not available for all the necessary data and their processing at the application server level can consume a lot of resources. Therefore, the massive inclusion of logging on all the necessary tables can lead to a noticeable degradation of system performance.
Clustered tables were the next major problem. Time estimate and payroll data in the RDBMS version of SAP HCM is stored as a set of logical tables per employee per payroll. These logical tables are stored as binary data in the pcl2 table.
Payroll Cluster:
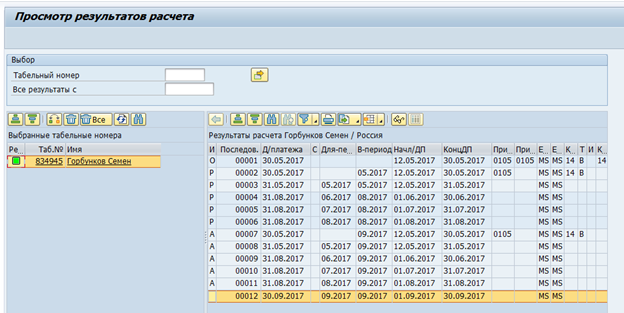
Data from clustered tables cannot be read by SQL command and requires the use of SAP HCM macros or special function modules. Accordingly, the speed of reading such tables will be quite low. On the other hand, such clusters store data that is only needed once a month - the final payroll and time estimate. So the speed in this case is not so critical.
Evaluating the options with the formation of a delta of data change, we decided to also consider the option with full unloading. The option to transfer gigabytes of unchanged data between systems every day cannot look pretty. However, it also has a number of advantages - there is no need for both the implementation of the delta on the source side and the implementation of embedding this delta on the receiver side. Accordingly, the cost and implementation time are reduced, and the integration reliability is increased. At the same time, it was determined that almost all changes in SAP HR occur in the horizon of three months before the current date. Thus, it was decided to stop at a daily full download of data from SAP HR N months before the current date and at a monthly full download. The parameter N depends on the specific table
and ranges from 1 to 15.
The following scheme was proposed for data extraction:

An external system generates a request and sends it to SAP HCM, where this request is checked for completeness of data and authorization to access tables. If the check is successful, SAP HCM runs a program that collects the necessary data and transfers it to the Fuse integration solution. Fuse defines the required topic in Kafka and passes data there. Next, data from Kafka is transferred to the Stage Area GP.
In this chain, we are interested in the issue of extracting data from SAP HCM. Let's dwell on it in more detail.
SAP HCM-FUSE interaction diagram.
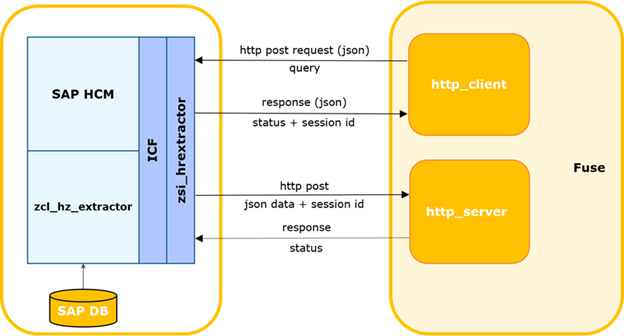
The external system determines the time of the last successful request to SAP.
The process can be started by a timer or other event, including a timeout for waiting for a response with data from SAP and initiation of a repeated request. Then it generates a delta request and sends it to SAP.
Request data is passed in body in json format.
The http: POST method.
Sample request:

The SAP service checks the request for completeness, compliance with the current SAP structure, and the availability of permission to access the requested table.
In case of errors, the service returns a response with the appropriate code and description. In case of successful control, it creates a background process to generate a selection, generates and synchronously returns a unique session id.
The external system will log it in the event of an error. In case of a successful response, it sends the session id and the name of the table on which the request was made.
The external system registers the current session as open. If there are other sessions for this table, they are closed with a warning logged.
The SAP background job generates a cursor according to the specified parameters and a data packet of the specified size. Packet size - the maximum number of records that the process reads from the database. By default, it is assumed to be 2000. If there are more records in the database sample than the used packet size, after the first packet is transmitted, the next block is formed with the corresponding offset and the incremented packet number. The numbers are incremented by 1 and sent strictly sequentially.
Next, SAP passes the packet as input to the external system web service. And it is the system that controls the incoming packet. A session with the received id must be registered in the system and it must be in an open state. If the package number is> 1, the system must record the successful receipt of the previous package (package_id-1).
In case of successful control, the external system parses and saves the table data.
Additionally, if the final flag is present in the package and serialization was successful, the integration module is notified about the successful completion of session processing and the module updates the session status.
In the event of a control / parsing error, the error is logged and packets for this session will be rejected by the external system.
Likewise, in the opposite case, when the external system returns an error, it is logged and the transmission of packets is stopped.
An integration service was implemented to request data on the SAP HM side. The service is implemented on the ICF framework (SAP Internet Communication Framework - help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html ). It allows you to query data from the SAP HCM system on specific tables. When forming a data request, it is possible to specify a list of specific fields and filtering parameters in order to obtain the necessary data. At the same time, the implementation of the service does not imply any business logic. Algorithms for calculating delta, request parameters, integrity control, etc. are also implemented on the side of the external system.
This mechanism allows you to collect and transfer all the necessary data in a few hours. This speed is on the verge of acceptable, therefore, we consider this solution as temporary, which made it possible to cover the need for an extraction tool on the project.
In the target picture for solving the data extraction problem, the options for using CDC systems such as Oracle Golden Gate or ETL tools such as SAP DS are being worked out.