
Recently, large Russian companies are increasingly looking towards affordable storage solutions. Open source DBMSs become competitors of Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB, etc. Western giants - Alibaba, Instagram, Skype - have been using them for a long time in their IT landscapes.
In the project for the Russian Union of Auto Insurers (RSA), where Jet Infosystems was building the IT infrastructure for the new AIS OSAGO, the developers used the PostgreSQL DBMS. And we thought about how to ensure maximum database availability and minimum data loss in the event of hardware failures. And this “on paper” description of the solution seems as simple as 2 + 2, in fact, our team had to work hard to achieve fault tolerance.
There are several Failover Clustering tools for PostgreSQL. These are Stolon, Patroni, Repmgr, Pacemaker + Corosync, etc.
We chose Patroni because this project is actively developing, unlike similar projects, it has clear documentation and is increasingly becoming the choice of database administrators.
The composition of the "soup set"
Patroni is a set of python scripts for automating the switching of the leading role of the PostgreSQL database server to the replica. It can also store, modify and apply parameters of the PostgreSQL DBMS itself. It turns out that there is no need to keep the PostgreSQL configuration files up to date on each server separately.
PostgreSQL is an open source relational database. It has proven itself in handling large and complex analytical processes.
Keepalived - in a multi-node configuration, it is used to enable a dedicated IP address on the very node of the cluster where the role of the primary PostgreSQL node is currently used. The IP address serves as the entry point for applications and users.
DCS is a distributed configuration storage. Patroni uses it to store information about the composition of the cluster, the roles of the cluster servers, as well as store its own and PostgreSQL configuration parameters. This article will focus on etcd.
Experiments with nuances
In search of the optimal solution for fault tolerance and in order to test our hypotheses about the operation of different options, we created several test benches. Initially, we considered solutions that were different from the target architecture: for example, we used Haproxy as the primary node of PostgreSQL or DCS was located on the same servers as PostgreSQL. We organized internal hackathons, studied how Patroni would behave in the event of server component failure, network unavailability, file system overflow, etc. That is, they worked out various failure scenarios. As a result of these "scientific studies", the final architecture of the fault-tolerant solution was formed.
Gourmet IT Dish
There are server roles in PostgreSQL: primary - an instance with the ability to write / read data; replica - a read-only instance, constantly synchronized with primary. These roles are static when PostgreSQL is running, and if a server with the primary role fails, the DBA must manually raise the replica role to primary.
Patroni creates failover clusters, that is, it combines servers with the primary and replica roles. There is an automatic role change between them in case of any failure.

The illustration above shows how the application servers connect to one of the servers in the Patroni cluster. This configuration uses one primary node and two replicas, one of which is synchronous. With synchronous replication, PostgreSQL works in such a way that the primary always waits for changes to be written to the replica. If the synchronous replica is unavailable, the primary will not write changes to itself, it will be read-only. This is the architecture of PostgreSQL. To "change its nature", the second replica is used - asynchronous (if synchronous replication is not required, you can limit yourself to one replica).
When using two or more replicas and enabling synchronous replication, Patroni always makes only one synchronous replica. If the primary node fails, Patroni raises the level of the synchronous replica.
The following illustration shows additional Patroni functionality that is vital in industrial enterprise solutions - data replication to a backup site.
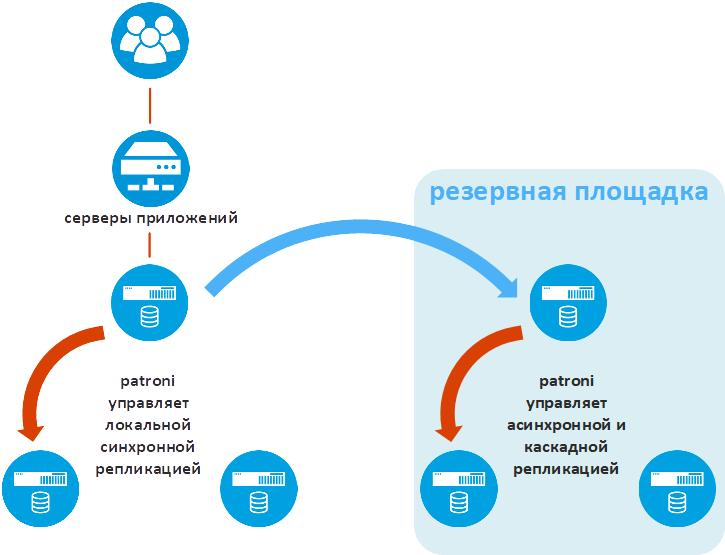
Patroni calls this functionality standby_cluster. It allows a Ratroni cluster to be used at a remote site as an asynchronous replica. If the main site is lost, the Patroni cluster will start working as if it were the main site.
One of the nodes of the backup site cluster is called Standby Leader. It is an asynchronous replica of the primary node of the main site. The two remaining nodes of the backup site cluster receive data from the Standby Leader. This is how cascading replication is implemented, which reduces the volume of traffic between technological sites.
Composition of Patroni cluster applications
Once launched, Patroni creates a separate TCP port. Having made an HTTP request to this port, you can understand which node of the cluster is primary and which is replica.

In keepalived, we have specified a small home-made script as a monitoring object that polls the Patroni TCP port. The script expects an HTTP GET 200 response. The responding cluster node is the Primary node, on which keepalived starts the IP address dedicated to connect to the cluster.
If you configure the second keepalived instance to wait for an HTTP GET 200 response from a synchronous replica, then keepalived on the same cluster node will launch another dedicated IP address. This address can be used by the application to read data from the database. This option is useful, for example, for preparing reports.
Since Patroni is a set of scripts, its instances on each node do not "communicate" directly with each other, but use the configuration store for this. We use etcd as it, which is a quorum for Patroni itself - the current primary node constantly updates the key in the etcd storage, indicating that it is the leading one. The rest of the cluster nodes constantly read this key and "understand" that they are replicas. The etcd service is located on dedicated servers in the amount of 3 or 5. Synchronization of data in the etcd storage between these servers is performed by means of the etcd service itself.
In the course of our experiments, we found out that the etcd service needs to be moved to separate servers. Firstly, etcd is extremely sensitive to network latency and disk subsystem responsiveness, and dedicated servers will not be loaded. Secondly, with a possible network separation of the nodes of the Patroni cluster, a "brain-split" may occur - two primary nodes will appear, which will not know anything about each other, since the etcd cluster will also "disintegrate".
Practice check
On the scale of a project to build an IT infrastructure for AIS OSAGO, achieving fault tolerance of PostgreSQL is one of the tasks of "implanting" an open DBMS into the corporate IT landscape. Next to it are related issues of integrating the PostgreSQL cluster with backup systems, infrastructure monitoring and information security tools, and reliable data safety at the backup site. Each of these directions has its own pitfalls and ways to bypass them. We have already written about one of them - we talked about PostgreSQL backup using enterprise solutions .

The fault-tolerance architecture of PostgreSQL, thought out and tested by us at the stands, has proven its effectiveness in practice. The solution is ready to "transfer" various system and logical failures. Now it runs on 10 highly loaded Patroni clusters and withstands PostgreSQL processing loads of hundreds of gigabytes of data per hour.
Author: Dmitry Erykin, and engineer-designer of computing systems of Jet Infosystems