For about a year now, our infrastructure division has been migrating all services running on GitLab.com to Kubernetes. During this time, we faced problems not only with moving services to Kubernetes, but also with managing hybrid deployment during the transition. The valuable lessons we have learned will be discussed in this article.
From the very beginning of GitLab.com, its servers ran in the cloud on virtual machines. These virtual machines are managed by Chef and installed using our official Linux package . The deployment strategy in case an application needs to be updated is to simply update the server fleet in a coordinated sequential manner using the CI pipeline. This method - while slow and a bit boring - ensures that GitLab.com uses the same installation and configuration methods as users of self-managed GitLab installations using our Linux packages.
We use this method because it is extremely important to experience all the sadness and joys that ordinary members of the community experience when installing and configuring their copies of GitLab. This approach worked well for some time, but as the number of projects on GitLab surpassed 10 million, we realized that it no longer met our scaling and deployment needs.
Getting started with Kubernetes and cloud-native GitLab
In 2017, the GitLab Charts project was created to prepare GitLab for deployment in the cloud, as well as to enable users to install GitLab on Kubernetes clusters. We knew then that moving GitLab to Kubernetes would increase the scalability of the SaaS platform, simplify deployments, and improve compute efficiency. At the same time, many features of our application depended on mounted NFS partitions, which slowed down the transition from virtual machines.
The pursuit of cloud native and Kubernetes allowed our engineers to plan a gradual transition, during which we ditched some of the application's NAS dependencies while continuing to develop new features along the way. Since we started planning our migration in summer 2019, many of these restrictions have been removed, and the process of migrating GitLab.com to Kubernetes is now in full swing!
Features of GitLab.com in Kubernetes
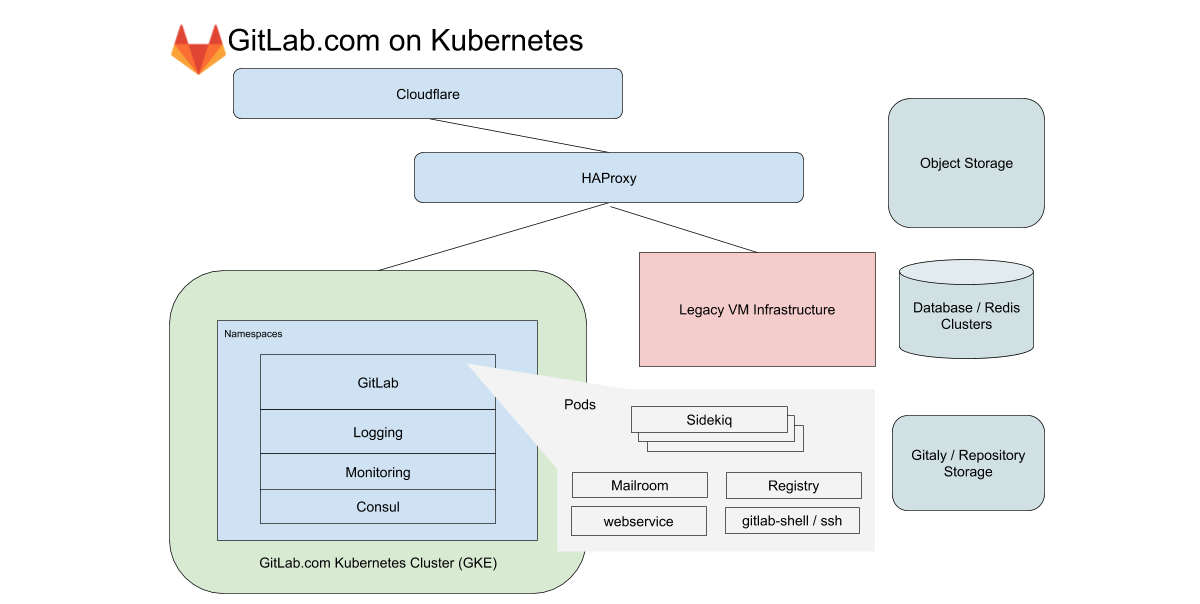
For GitLab.com, we use a single regional GKE cluster that handles all application traffic. To minimize the complexity of the (already tricky) migration, we focus on services that don't rely on local storage or NFS. GitLab.com uses a predominantly monolithic Rails codebase, and we route traffic based on the characteristics of the workload to various endpoints, isolated into our own node pools.
In the case of the frontend, these types are divided into requests to the web, API, Git SSH / HTTPS, and Registry. In the case of the backend, we queue jobs up according to different characteristics depending on predefined resource boundaries that allow us to set Service-Level Objectives (SLOs) for different workloads.
All of these GitLab.com services are configured using an unmodified GitLab Helm chart. The configuration is done in subcharts, which can be selectively enabled as we gradually migrate services to the cluster. Even though it was decided not to include some of our stateful services such as Redis, Postgres, GitLab Pages, and Gitaly in the migration, Kubernetes dramatically reduces the number of VMs Chef currently manages.
Kubernetes transparency and configuration management
All settings are controlled by GitLab itself. For this, three configuration projects based on Terraform and Helm are used. We try to use GitLab itself whenever possible to run GitLab, but for operational tasks we have a separate GitLab installation. It is needed to be independent of GitLab.com availability for GitLab.com deployments and updates.
Although our pipelines for the Kubernetes cluster run on a separate GitLab installation, the code repos have mirrors publicly available at the following addresses:
- k8s-workloads / gitlab-com - GitLab.com configuration binding for the GitLab Helm chart;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

When changes are made, a publicly available short summary is shown with a link to a detailed diff that SRE analyzes before making changes to the cluster.
For SRE, the link points to a detailed diff in the GitLab installation that is being used for production and access to which is limited. This allows employees and the community without access to the operational project (it is open only to the SRE) to view the proposed configuration changes. By combining a public instance of GitLab for code with a private instance for CI pipelines, we maintain a single workflow, while ensuring independence from GitLab.com for configuration updates.
What we found out during the migration
During the move, experience has been accumulated, which we apply to new migrations and deployments in Kubernetes.
1. -

Daily egress statistics (bytes per day) for the Git repository park on GitLab.com
Google divides its network into regions. Those, in turn, are divided into availability zones (AZ). Git hosting is associated with large amounts of data, so it is important for us to control the network egress. For internal traffic, egress is free only if it remains within the same AZ. At the time of this writing, we are serving roughly 100 TB of data on a typical business day (and that's only for Git repositories). Services that, in our old VM-based topology, were on the same virtual machines, now run in different Kubernetes pods. This means that some of the traffic that was previously local to the VM can potentially go outside of Availability Zones.
Regional GKE clusters allow you to span multiple Availability Zones for redundancy. We are considering splitting the regional GKE cluster into single-zone clusters for services that generate large amounts of traffic. This will reduce egress costs while maintaining cluster redundancy.
2. Limits, resource requests and scaling

The number of replicas processing production traffic at registry.gitlab.com. Traffic peaks at ~ 15:00 UTC.
Our migration story began in August 2019, when we ported our first service, the GitLab Container Registry, to Kubernetes. This high-traffic, mission-critical service was well suited for the first migration because it is a stateless application with few external dependencies. The first problem we encountered was the large number of preempted pods due to insufficient memory on the nodes. Because of this, we had to change requests and limits.
It was found that in the case of application in which the memory consumption increases with time, low values for request'ov (for each redundant memory pod'a) coupled with "generous" rigid limit'om to use lead to saturation (saturation) units and a high level of displacement. To cope with this problem, it was decided to increase requests and lower limits . This took the pressure off the nodes and ensured a pod lifecycle that did not put too much pressure on the node. We now start migrations with generous (and nearly identical) request and limit values, adjusting them as needed.
3. Metrics and logs

Infrastructure focuses on latency, error rates and saturation with established service level objectives (SLOs) tied to the overall availability of our system .
Over the past year, one of the key developments in the infrastructure division has been improvements in monitoring and working with SLOs. SLOs allowed us to set goals for individual services, which we closely monitored during the migration. But even with such improved observability, it is not always possible to immediately see problems using metrics and alerts. For example, by focusing on latency and error rates, we do not fully cover all use cases for a service undergoing migration.
This issue was discovered almost immediately after moving some of the workloads to the cluster. It became especially acute when it was necessary to check functions, the number of requests to which is small, but which have very specific configuration dependencies. One of the key lessons from the migration results was the need to take into account when monitoring not only metrics, but also logs and the "long tail" (we are talking about their distribution on the graph - approx. Transl.) . Now, for each migration, we include a detailed list of log queries and plan clear rollback procedures that can be passed from one shift to another in case of problems.
Serving the same requests in parallel on the old VM infrastructure and the new one based on Kubernetes was a unique challenge. Unlike lift-and-shift migration (quick transfer of applications "as is" to a new infrastructure; you can read more, for example, here - approx. Transl.) , Parallel work on "old" VMs and Kubernetes requires tools for monitoring systems were compatible with both environments and were able to combine metrics into one view. It is important that we use the same dashboards and log queries to achieve consistent observability during the transition.
4. Switching traffic to a new cluster
For GitLab.com, some of the servers are allocated for the canary stage . Canary Park caters to our in-house projects and can also be enabled by users . But first and foremost, it is intended to validate changes made to the infrastructure and application. The first service migrated started by accepting a limited amount of internal traffic, and we continue to use this method to ensure that the SLO is met before forwarding all traffic to the cluster.
In the case of migration, this means that first requests to internal projects are sent to Kubernetes, and then we gradually switch the rest of the traffic to the cluster by changing the weight for the backend through HAProxy. In the process of moving from VM to Kubernetes, it became clear that it was very beneficial to have a simple way to redirect traffic between the old and new infrastructure and, accordingly, keep the old infrastructure ready for rollback in the first few days after the migration.
5. Reserve power of pods and their use
Almost immediately, the following problem was identified: the pods for the Registry service started quickly, but the pods for Sidekiq took up to two minutes to start . Long running pods for Sidekiq became a problem when we started migrating workloads to Kubernetes for workers who need to process jobs quickly and scale quickly.
In this case, the lesson was that while the Horizontal Pod Autoscaler (HPA) in Kubernetes handles traffic growth well, it is important to take into account the characteristics of the workloads and allocate spare pod capacity (especially in an environment of uneven demand distribution). In our case, there was a sudden spike in jobs, entailing rapid scaling, which led to saturation of CPU resources before we had time to scale the node pool.
There is always a temptation to squeeze as much out of the cluster as possible, however, we, initially faced with performance problems, now start with a generous pod budget and scale it down later, keeping a close eye on the SLO. Launching pods for the Sidekiq service has significantly accelerated and now takes about 40 seconds on average.Both GitLab.com and our users of self-managed installations, working with the official GitLab Helm chart, have benefited from the reduction in pod launch times.
Conclusion
After migrating each service, we enjoyed the benefits of using Kubernetes in production: faster and safer application deployment, scaling, and more efficient resource allocation. Moreover, the advantages of migration go beyond the GitLab.com service. Every improvement to the official Helm chart also benefits its users.
I hope you enjoyed the story of our Kubernetes migration adventures. We continue to migrate all new services to the cluster. Additional information can be obtained from the following publications:
- « Why are migrating to Kubernetes <br> we? ";
- " GitLab.com on Kubernetes ";
- Epic on Migrating GitLab.com to Kubernetes .
PS from translator
Read also on our blog: