
One of the first admonitions that a young Padawan receives along with access to git repositories is: "never
git push -f." Since this is one of the hundreds of maxims that a novice software engineer needs to learn, no one takes the time to clarify why this should not be done. It's like babies and fire: "matches are not toys for children" and that's it. But we grow and develop as people and as professionals, and one day the question "why, actually?" rises in full growth. This article is written based on our internal meetup, on the topic: "When can and should you rewrite the history of commits."

I have heard that the ability to answer this question in an interview in some companies is a criterion for interviewing for senior positions. But to better understand the answer to it, you need to figure out why rewriting history is bad at all?
To do this, in turn, we need a quick excursion into the physical structure of the git repository. If you are sure that you know everything about the repo device, you can skip this part, but even in the process of finding out, I learned quite a lot of new things for myself, and some old ones turned out to be not quite relevant.
At the lowest level, a git repo is a collection of objects and pointers to them. Each object has its own unique 40-character hash (20 hexadecimal bytes), which is calculated based on the contents of the object.
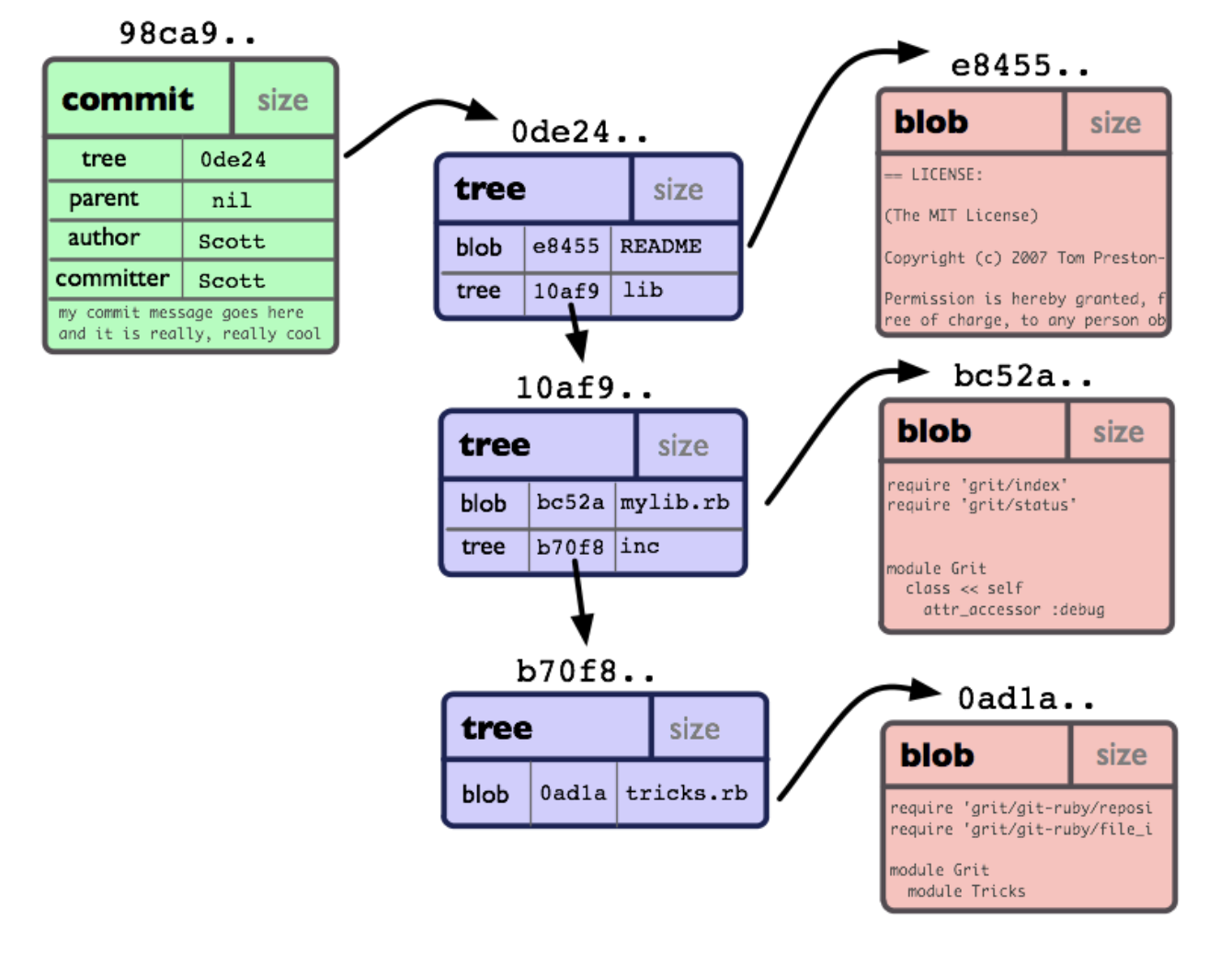
Illustration taken from The Git Community Book
The main object types are blob (just the contents of a file), tree (a collection of pointers to blobs and other trees), and commit. An object of type commit is only a pointer to tree, to the previous commit, and service information: date / time, author and comment.
Where are the branches and tags that we are used to operating with? And they are not objects, they are just pointers: a branch points to the last commit in it, a tag points to an arbitrary commit in the repo. That is, when we see beautifully drawn branches with commit circles on them in the IDE or GUI client, they are built on the fly, running along the commit chains from the ends of the branches down to the "root". The very first commit in the repo has no previous one, instead of a pointer there is null.
An important point to understand: the same commit can appear in several branches at the same time. The commits are not copied when a new branch is created, it just starts "growing" from where HEAD was at the moment the command was issued
git checkout -b <branch-name>.
So why is rewriting the history of a repository harmful?

First, and this is obvious, when you upload a new story to the repository that the engineering team is working with, other people might just lose their changes. The command
git push -f removes from the branch on the server all commits that are not in the local version, and writes new ones.
For some reason, few people know that for a long time the team
git pushhas a "safe" key--force-with-leasewhich causes the command to fail if there are commits added by other users to the remote repository. I always recommend using it instead -f/--force.
The second reason why the command
git push -fis considered harmful is that when trying to merge a branch with a rewritten history with the branches where it was preserved (more precisely, the commits removed from the rewritten history were saved), we will get a hell of a number of conflicts (by the number commits, actually). There is a simple answer to this: if you carefully follow Gitflow or Gitlab Flow , then such situations most likely will not even arise.
And finally, there is an unpleasant side of rewriting history: those commits that are, as it were, removed from the branch, in fact, do not disappear anywhere and simply remain forever in the repo. A trifle, but unpleasant. Fortunately, the git developers have addressed this problem as well with the garbage collection command
git gc --prune. Most git hosts, at least GitHub and GitLab, do this in the background from time to time.
So, having dispelled fears about changing the history of the repository, we can finally move on to the main question: why is it needed and when is it justified?
In fact, I'm sure that almost every more or less active git user has changed history at least once, when it suddenly turned out that something went wrong in the last commit: an annoying typo crept into the code, made a commit on the wrong user (from personal e-mail instead of work or vice versa), forgot to add a new file (if you, like me, like to use
git commit -a). Even changing the description of a commit leads to the need to rewrite it, because the hash is counted from the description too!
But this is a trivial case. Let's look at more interesting ones.
Let's say you made a big feature that you sawed for several days, sending daily results of work to the repository on the server (4-5 commits), and sent your changes for review. Two or three tireless reviewers showered you with large and small recommendations for edits, or even found jambs (4-5 more commits). Then QA found several edge cases that also require fixes (2-3 more commits). And finally, during the integration, some incompatibilities were found out or autotests got in, which also need to be fixed.
If now you press the Merge button without looking, then a dozen and a half commits like “My feature, day 1”, “Day 2”, “Fix tests”, “Fix review” will be added to the main branch (for many it is called master in the old fashioned way) etc. This, of course, helps the squash mode, which is now in both GitHub and GitLab, but you need to be careful with it: firstly, it can replace the commit description with something unpredictable, and secondly, replace the author of the feature on the one who pressed the Merge button (we have it in general a robot helping the release engineer to assemble today's deployment). Therefore, the simplest thing will be, before the final integration into the release, to collapse all the commits of the branch into one using
git rebase.
But it also happens that you have already approached the code review with a repo history reminiscent of Olivier salad. This happens if a feature has been sawing for several weeks, because it was poorly decomposed, or, although decent teams are beaten with a candelabrum for this, the requirements have changed during the development process. For example, here is a real merge request that came to me for a review two weeks ago:
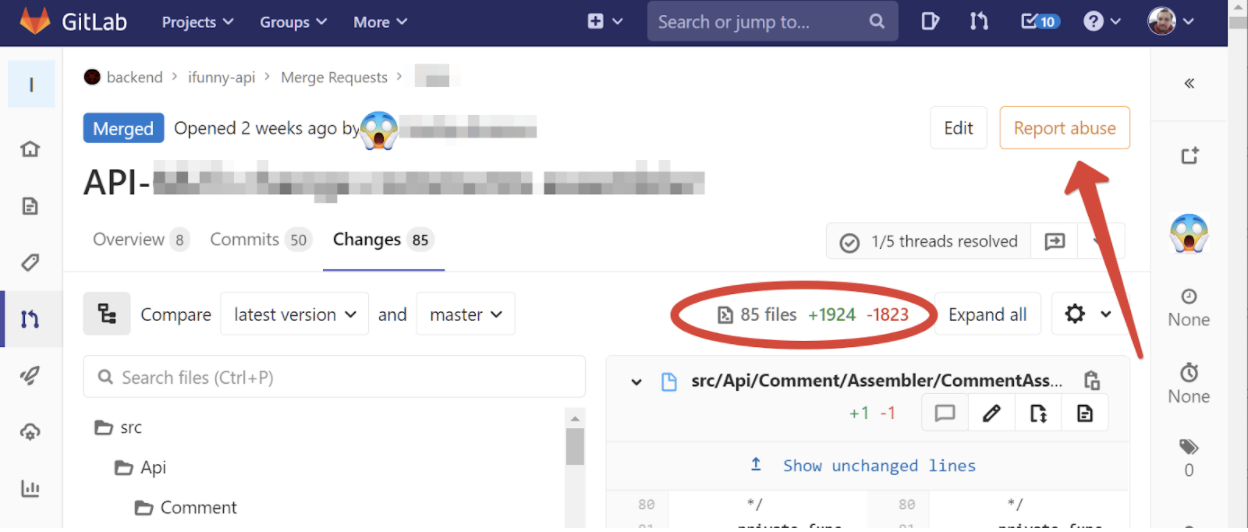
My hand automatically reached for the "Report abuse" button, because how else can you characterize a request of 50 commits with almost 2000 changed lines? And how, one wonders, to review it?
To be honest, it took me two days just to force myself to start this review. And this is a normal reaction for an engineer; someone in a similar situation, just without looking, presses Approve, realizing that in a reasonable time they will still not be able to do the job of reviewing this change with sufficient quality.
But there is a way to make life easier for a friend. In addition to the preliminary work on better decomposition of the problem, after the completion of writing the main code, you can bring the history of its writing into a more logical form, breaking it into atomic commits with green tests in each: "created a new service and a transport layer for it", "built models and wrote checking invariants "," added validation and exception handling "," wrote tests ".
Each of these commits can be reviewed separately (both GitHub and GitLab can do this) and do it in raids when switching between your tasks or in breaks.
The same one
git rebasewith the key will help us to do all this --interactive. As a parameter, you need to pass it the hash of the commit, from which you will need to rewrite the history. If we are talking about the last 50 commits, as in the example in the picture, you can write git rebase --interactive HEAD~50(substitute your number for “50”).
By the way, if you added the master branch to yourself in the process of working on a task, then you will first need to rebase this branch so that merge commits and commits from the master do not get confused under your feet.
Armed with knowledge of the internals of a git repository, it should be easy to understand how rebase works on master. This command takes all the commits in our branch and changes the parent of the first one to the last commit in the master branch. See diagram:
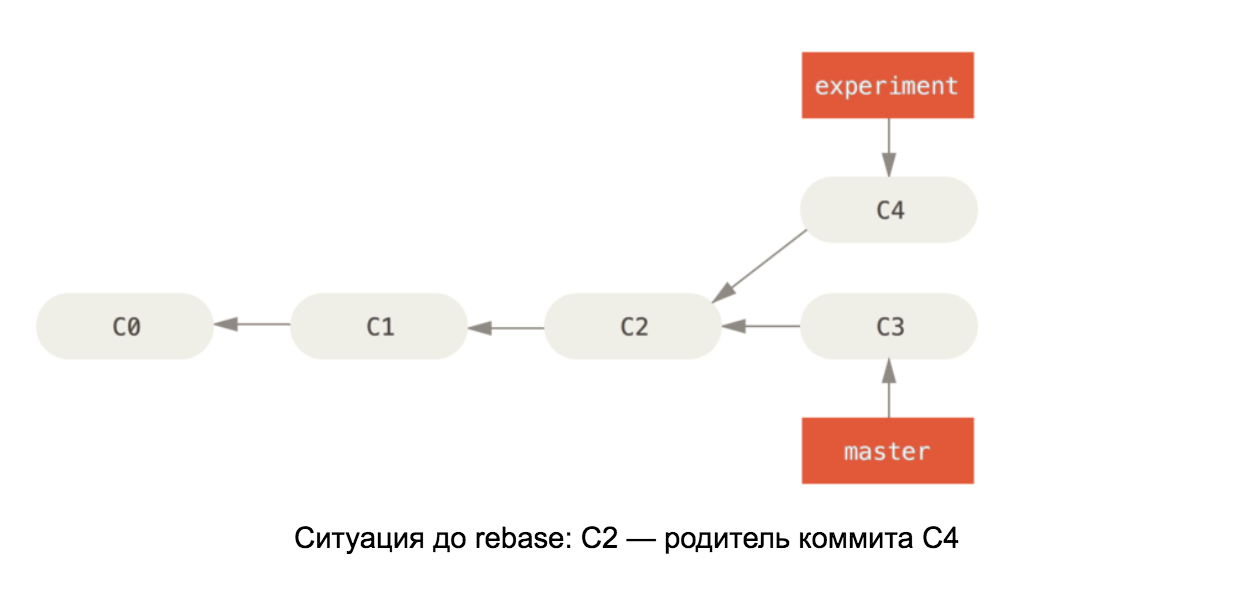
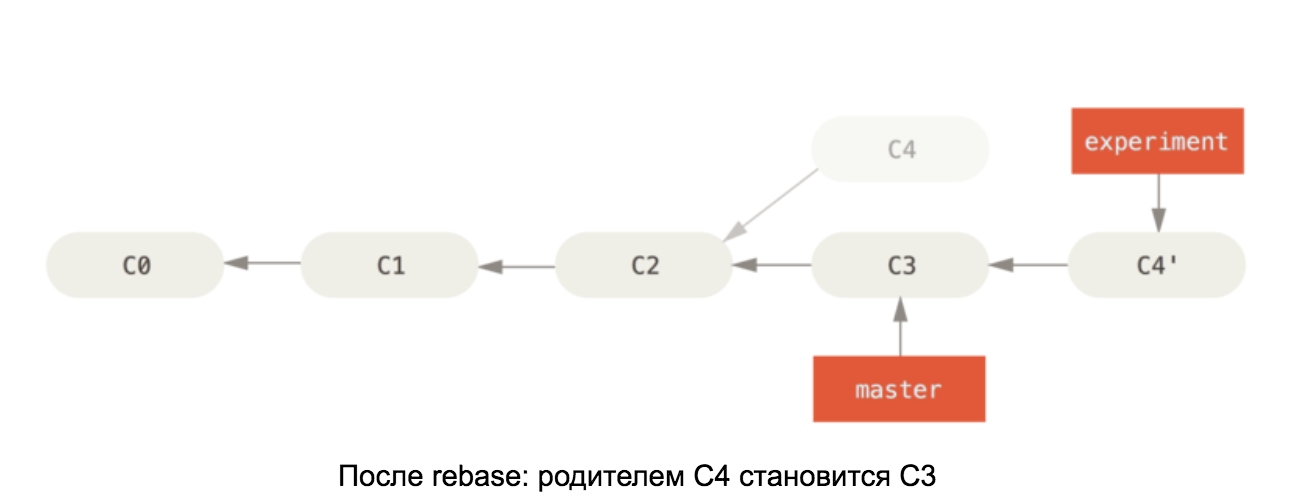
Illustrations are taken from the book Pro Git
If the changes in C4 and C3 conflict, then after resolving the conflicts, the C4 commit will change its content, so it is renamed in the second diagram to C4 '.
This way, you will end up with a branch consisting only of your changes and growing from the top of master. Of course, master must be up to date. You can just use the version from the server:
git pull --rebase origin/master(as you know, is git pullequivalent git fetch && git merge, and the key --rebasewill force git to rebase instead of merge).
Let's finally return to
git rebase --interactive... It was made by programmers for programmers, and realizing what stress people will experience in the process, we tried to preserve the user's nerves as much as possible and save him from the need to strain excessively. This is what you will see on the screen:
This is the repository of the popular Guzzle package. It looks like a rebase would be useful for him ...
The generated file opens in a text editor. Below you will find detailed information on what to do here. Next, in easy edit mode, you decide what to do with the commits in your branch. Everything is as simple as a stick: pick - leave it as it is, reword - change the commit description, squash - merge with the previous one (the process works from the bottom up, that is, the previous one is the line below), drop - delete altogether, edit - and this is the interesting thing is to stop and freeze. After git encounters the edit command, it will take the position where the changes in the commit have already been added to staged mode. You can change anything in this commit, add a few more on top of it, and then command
git rebase --continueto continue the rebase process.
Oh, and by the way, you can swap commits. This may create conflicts, but in general, the rebase process is rarely completely conflict-free. As they say, having taken off their head, they do not cry for their hair.
If you get confused and it seems that everything is gone, you have an emergency ejection button
git rebase --abortthat will immediately return everything to it.
You can repeat the rebase several times, touching only parts of the story and leaving the rest untouched with pick, giving your story a more and more finished look, like a potter's jug. It is good practice, as I wrote above, to make sure that the tests in each commit will be green (for this, edit helps perfectly and on the next pass - squash).
Another aerobatics, useful in case you need to decompose several changes in the same file into different commits -
git add --patch. It can be useful on its own, but in combination with the edit directive, it will allow you to split one commit into several, and do it at the level of individual lines, which, if I'm not mistaken, no GUI client and no IDE does not allow.
Again making sure that everything is in order, you can finally with peace of mind to do something, what started this tutorial:
git push --force. Oh, that is, of course --force-with-lease!

At first, you will most likely spend an hour on this process (including the initial rebase on master), or even two if the feature is really sprawling. But even this is much better than waiting two days for the reviewer to force himself to finally take up your request, and another couple of days until he gets through it. In the future, you will most likely fit in 30-40 minutes. IntelliJ products with built-in conflict resolution tool (full disclosure: FunCorp pays for these products to its employees) are especially helpful in this.
One last word of caution is not to rewrite the branch history during the code review process. Remember that a conscientious reviewer may clone your code locally in order to be able to look at it through the IDE and run tests.
Thanks for your attention to everyone who read to the end! I hope that this article will be useful not only for you, but also for colleagues who receive your code for review. If you have some cool git hacks - share them in the comments!