
Imagine a 2.5 gigabyte log after a failed build. That's three million lines. You're looking for a bug or regression that shows up on the millionth line. It is probably simply impossible to find one such line manually. One option is a diff between the last successful and failed builds in the hope that the bug writes unusual lines to the logs. Netflix's solution is faster and more accurate than LogReduce - under the cut.
Netflix and the line in the log stack
The standard md5 diff is fast, but it prints at least hundreds of thousands of candidate lines for viewing because it shows line differences. A variation of logreduce is a fuzzy diff using a k-nearest neighbor search that finds about 40,000 candidates, but it takes one hour. The solution below finds 20,000 candidate strings in 20 minutes. Thanks to the magic of open source, this is only about a hundred lines of Python code.
Solution - a combination of vector word representations that encode the semantic information of words and sentences, and a location-based hash(LSH - Local Sensitive Hash), which effectively distributes approximately close elements into some groups and distant elements into other groups. Combining vector representations of words and LSH is a great idea less than ten years ago .
Note: we ran Tensorflow 2.2 on CPU and with immediate execution for transfer learning and scikit-learnNearestNeighborfor k nearest neighbors. There are complex approximations of nearest neighbors that would be better for solving the model-based nearest neighbor problem.
Vector word representation: what is it and why?
Building a bag of words with k categories (k-hot encoding, a generalization of unitary encoding) is a typical (and useful) starting point for deduplication, search, and similarity problems between unstructured and semi-structured text. This type of bag of words coding looks like a dictionary with individual words and their number. Example with the sentence "log in error, check log".
{"log": 2, "in": 1, "error": 1, "check": 1}
This encoding is also represented by a vector, where the index corresponds to a word and the value corresponds to the number of words. Shown below is the phrase ”log in error, check log” as a vector, where the first entry is reserved for counting the words “log”, the second for counting the words “in”, and so on:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Please note: the vector consists of many zeros. Zeros are all other words in the dictionary that are not in this sentence. The total number of possible vector entries, or the dimension of a vector, is the size of your language's vocabulary, which is often millions of words or more, but shrinks to hundreds of thousands with clever tricks .
Let's look at the dictionary and vector representations of the phrase "problem authentificating". Words matching the first five vector entries do not appear in the new sentence at all.
{"problem": 1, "authenticating": 1}
It turns out:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
The statements "problem authentificating" and "log in error, check log" are semantically similar. That is, they are essentially the same thing, but lexically as different as possible. They have no common words. In terms of fuzzy diff, we could say that they are too similar to distinguish them, but the md5 encoding and the document processed by k-hot with kNN do not support this.
Dimension reduction uses linear algebra or artificial neural networks to place semantically similar words, sentences, or log lines next to each other in a new vector space. Vector representations are used. In our example, "log in error, check log" can have a five-dimensional vector to represent:
[0.1, 0.3, -0.5, -0.7, 0.2]
The phrase "problem authentificating" can be
[0.1, 0.35, -0.5, -0.7, 0.2]
These vectors are close to each other in terms of measures such as cosine similarity , as opposed to their wordbag vectors. Dense, low-dimensional views are really useful for short documents like assembly lines or syslog.
In fact, you would replace thousands or more of the dimensions of the dictionary with just a 100-dimensional representation that is rich in information (not five). Modern approaches to dimensionality reduction include singular value decomposition of the word co-occurrence matrix ( GloVe ) and specialized neural networks ( word2vec , BERT , ELMo ).
What about clustering? Let's go back to the build log
We joke that Netflix is a log production service that occasionally streams videos. Logging, streaming, exception handling - these are hundreds of thousands of requests per second. Therefore, scaling is necessary when we want to apply applied ML in telemetry and logging. For this reason, we are careful about scaling text deduplication, looking for semantic similarities, and detecting text outliers. When business problems are solved in real time, there is no other way.
Our solution involves representing each row in a low-dimensional vector and optionally "fine-tuning" or simultaneously updating the embed model, assigning it to a cluster, and defining the lines in different clusters as "different". Location-aware hashing- a probabilistic algorithm that allows you to assign clusters in constant time and search for nearest neighbors in almost constant time.
LSH works by mapping a vector representation to a set of scalars. Standard hashing algorithms tend to avoid collisions between any two matching inputs. LSH seeks to avoid collisions if the inputs are far apart and promotes them if they are different but close to each other in vector space.
The vector representing the phrase "log in error, check error" can be matched with a binary number
01. Then01represents a cluster. The vector "problem authentificating" with a high probability can also be displayed in 01. So LSH provides a fuzzy comparison and solves the inverse problem - a fuzzy difference. Early applications of LSH were over multidimensional vector spaces from a set of words. We could not think of a single reason why he would not work with spaces of vector representation of words. There are indications that others thought the same .

The above shows the use of LSH when placing characters in the same group, but upside down.
The work we did to apply LSH and vector cutaways by detecting text outliers in build logs now allows the engineer to view a small portion of the log lines to identify and fix potential business-critical errors. It also allows you to achieve semantic clustering of almost any log line in real time.
This approach now works in every build of Netflix. The semantic part allows you to group seemingly dissimilar elements based on their meaning and display these elements in emissions reports.
A few examples
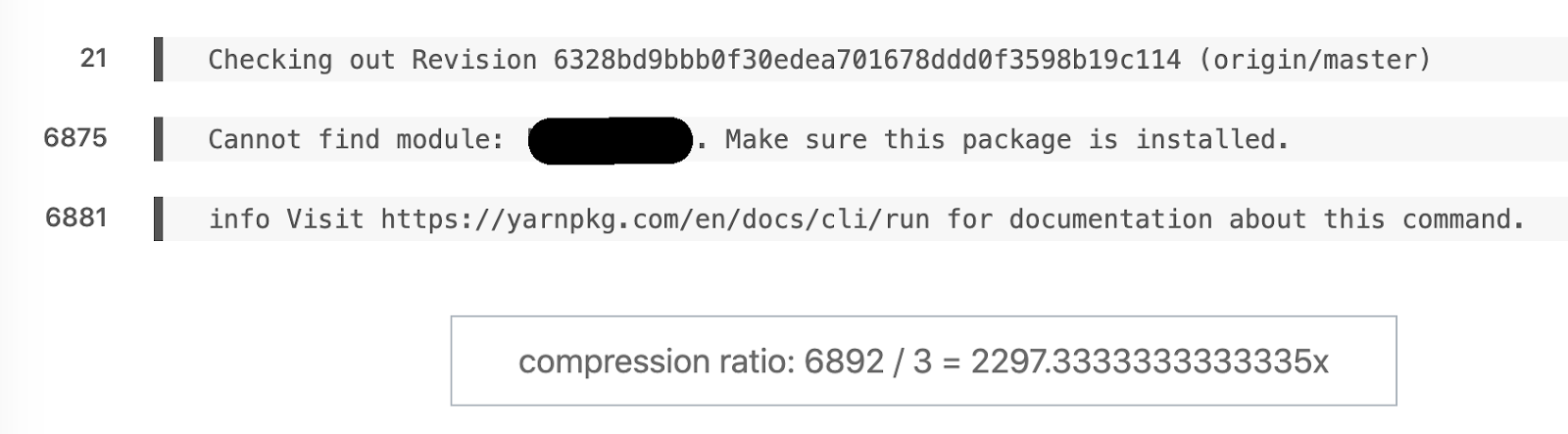
Favorite example of semantic diff. 6892 lines turned into 3.
Another example: this assembly recorded 6044 lines, but 171 remained in the report. The main problem surfaced almost immediately on line 4036.

Of course, it is faster to parse 171 lines than 6044. But how did we get such large assembly logs? Some of the thousands of build tasks that are stress tests for consumer electronics are performed in trace mode. It is difficult to work with such a volume of data without preliminary processing.

Compression ratio: 91366/455 = 205.3.
There are various examples that reflect the semantic differences between frameworks, languages, and build scripts.
Conclusion
The maturity of the open source transfer learning products and SDK has allowed LSH to solve the semantic nearest neighbor search problem in very few lines of code. We were interested in the special benefits that transfer learning and fine tuning bring to the app. We are happy to be able to solve such problems and help people do what they do better and faster.
We hope you are considering joining Netflix and becoming one of the great colleagues whose lives we make life easier with machine learning. Engagement is Netflix's core value, and we are particularly interested in shaping different perspectives on tech teams. Therefore, if you are in analytics, engineering, data science or any other field and have a background not typical of the industry, we would especially love to hear from you!
If you have any questions about the Netflix features, please contact the LinkedIn contributors : Stanislav Kirdey , William High How do you solve the log
search problem?
Find out the details of how to get a high-profile profession from scratch or Level Up in skills and salary by taking online SkillFactory courses:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
- «Python -» (9 )
- - (8 )
- (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
