This article is a translation of one of the neptune.ai posts and highlights the most interesting deep learning tools presented at the ICLR 2020 machine learning conference .

Where is advanced deep learning created and discussed?
One of the main places for discussion of Deep Learning is ICLR - the leading conference on deep learning, which took place on April 27-30, 2020. With over 5,500 attendees and nearly 700 presentations and talks, this is a great success for a fully online event. You can find comprehensive information about the conference here , here or here .
Virtual social meetings were one of the highlights of ICLR 2020. The organizers decided to launch a project called “Open source tools and practices in state-of-the-art DL research”. The topic was chosen due to the fact that the corresponding toolkit is an inevitable part of the work of a deep learning researcher. Advances in this area have led to the proliferation of large ecosystems (TensorFlow , PyTorch , MXNet), as well as smaller targeted tools that address the specific needs of researchers.
The purpose of the mentioned event was to meet with the creators and users of open source tools, as well as to share experiences and impressions among the Deep Learning community. In total, more than 100 people were brought together, including the main inspirers and project leaders, whom we gave short periods of time to present their work. Participants and organizers were surprised by the wide variety and creativity of the tools and libraries presented.
This article contains bright projects presented from a virtual stage.
Tools and Libraries
The following are eight tools that were demonstrated at ICLR with a detailed overview of the capabilities.
Each section presents answers to a number of points in a very succinct manner:
- What problem does the tool / library solve?
- How do I run or create a minimal use case?
- External resources for a deeper dive into the library / tool.
- Profile of the project representatives in case there is a desire to contact them.
You can jump to a specific section below or just browse them all one by one. Enjoy reading!
AmpliGraph
Topic: Knowledge Graph-based Embedding Models.
Programming language: Python
By: Luca Costabello
Twitter | LinkedIn | GitHub | Website
Knowledge graphs are a versatile tool for representing complex systems. Whether it's a social network, a bioinformatics dataset, or retail purchase data, knowledge modeling in graph form enables organizations to identify important connections that would otherwise be overlooked.
Revealing the relationships between data requires special machine learning models specially designed for working with graphs.
AmpliGraphIs a set of machine learning models licensed by Apache2 for extracting embeddings from knowledge graphs. Such models encode the nodes and edges of the graph in a vector form and combine them to predict missing facts. Graph embeddings are used in tasks such as top of the knowledge graph, knowledge discovery, link-based clustering, and others.
AmpliGraph lowers the barrier to entry for the graph embedding topic for researchers by making these models available to inexperienced users. Taking advantage of the open source API, the project supports a community of enthusiasts using graphs in machine learning. The project allows you to learn how to create and visualize embeddings from knowledge graphs based on real-world data and how to use them in subsequent machine learning tasks.
To get started, below is a minimal piece of code that trains a model on one of the reference datasets and predicts missing links:


AmpliGraph was originally developed at Accenture Labs Dublin , where it is used in various industrial projects.
Automunge
Tabular data preparation platform
Programming language: Python
Posted by Nicholas Teague
Twitter | LinkedIn | GitHub | Automunge website
Is a Python library to help prepare tabular data for use in machine learning. Through the toolkit of the package, simple transformations for feature engeenering are possible to normalize, encode and fill in the gaps. The transformations are applied to the training subsample and then applied in a similar manner to the data from the test subsample. Conversions can be performed automatically, assigned from an internal library, or flexibly configured by the user. Population options include “machine learning-based infill,” in which models are trained to predict missing information for each column of data.
Simply put:
automunge (.) Prepares tabular data for use in machine learning,
postmunge (.)additional data is processed sequentially and with high efficiency.
Automunge is available for installation via pip:

After installation, just import the library into Jupyter Notebook for initialization:

To automatically process data from a training sample with default parameters, it is enough to use the command:

Further, for the subsequent processing of data from the test subsample, it is enough to run a command using the postprocess_dict dictionary obtained by calling automunge (.) Above:

The assigncat and assigninfill parameters in the automunge (.) Call can be used to define conversion details and data types to fill in the gaps. For example, for a dataset with columns 'column1' and 'column2', you can assign scaling based on minimum and maximum values ('mnmx') with ML padding for column1 and one-hot encoding ('text') with padding based on the most common value for column2. Data from other columns not specified explicitly will be processed automatically.

Resources and Links
Website | GitHub | Brief presentation
DynaML
Machine Learning for Scala
Programming language: Scala
Posted by: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML is a Scala-based research and machine learning toolbox. It aims to provide the user with an end-to-end environment that can help in:
- development / prototyping of models,
- working with bulky and complex pipelines,
- visualization of data and results,
- reuse of code in the form of scripts and Notebooks.
DynaML leverages the strengths of the Scala language and ecosystem to create an environment that delivers performance and flexibility. It is based on excellent projects like Ammonite scala, Tensorflow-Scala and the Breeze high performance numerical computation library .
The key component of DynaML is the REPL / shell, which has syntax highlighting and an advanced autocomplete system.
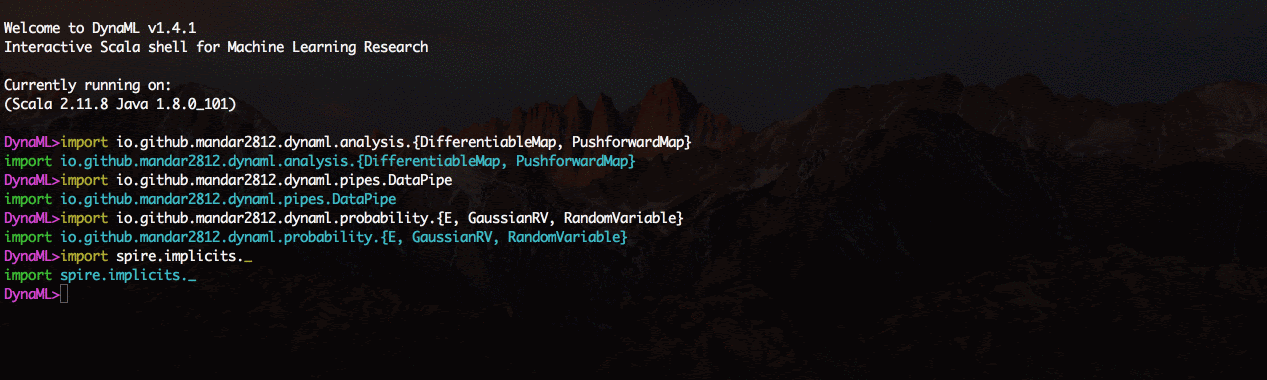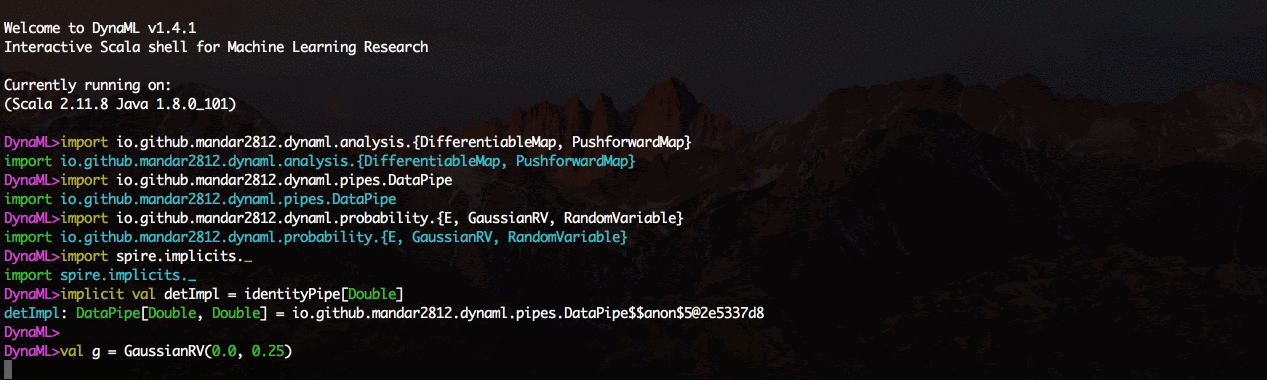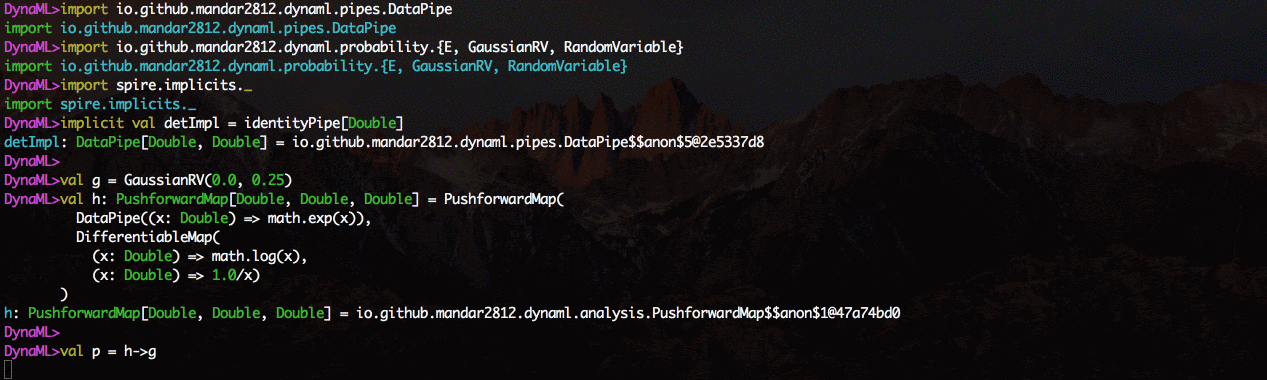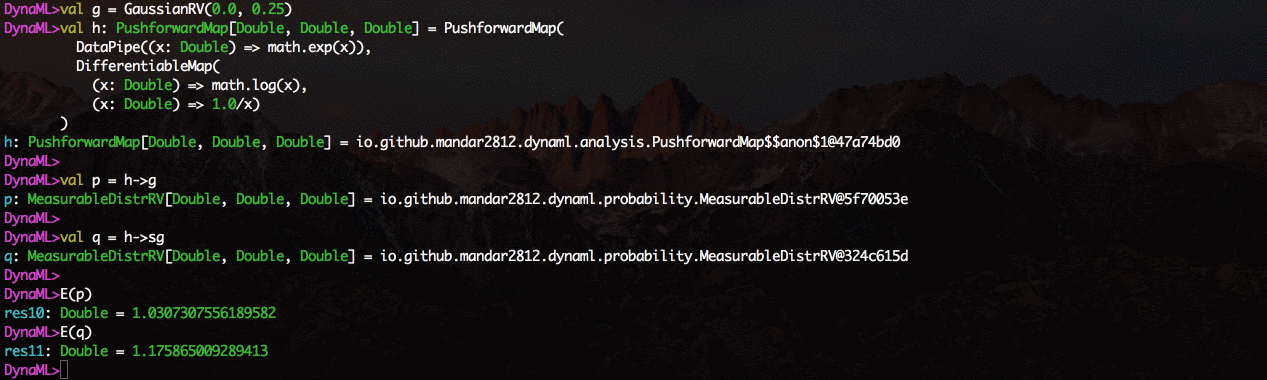
The environment comes with support for 2D and 3D visualization, the results can be displayed directly from the command shell.

The data pipes module makes it easy to create data processing pipelines in a layout-friendly modular fashion. Create functions, wrap them using the DataPipe constructor, and construct function blocks using the> operator.
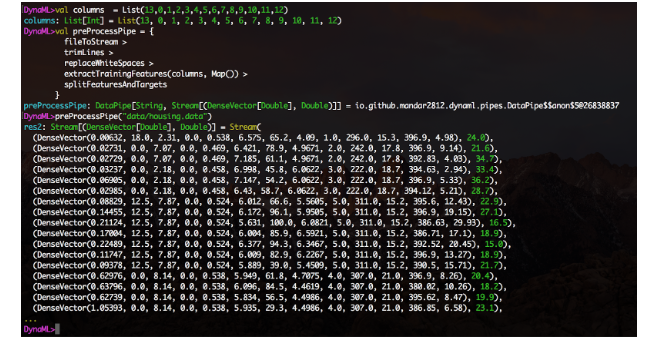
An experimental Jupyter notebook integration feature is also available, and the repository's notebooks directory contains several examples of using the DynaML-Scala Jupyter core.

The User Guide contains extensive reference and documentation to help you master and get the most out of the DynaML environment.
Below are some interesting applications that highlight the strengths of DynaML:
- physics inspired neural networks to solve the Burger equation and the Fokker-Planck system ,
- Deep Learning training,
- Gaussian process models for autoregressive time series forecasting.
GitHub Resources and Links | User's manual
Hydra
Configuration and parameters manager
Programming language: Python
Posted by Omry Yadan
Twitter | GitHub
Developed by Facebook AI, Hydra is a Python platform that simplifies development of research applications by providing the ability to create and override configurations using config files and the command line. The platform also provides support for automatic parameter expansion, remote and parallel execution via plug-ins, automatic working directory management, and dynamically suggesting complement options by pressing the TAB key.
Using Hydra also makes your code more portable across different machine learning environments. Allows you to switch between personal workstations, public and private clusters without changing your code. The above is achieved through a modular architecture.
Basic Example
This example uses a database configuration, but you can easily replace it with models, datasets, or whatever else you need.
config.yaml:

my_app.py:

You can override anything in the configuration from the command line:

Composition example:
You might want to switch between two different database configurations.
Create this directory structure:

config.yaml:
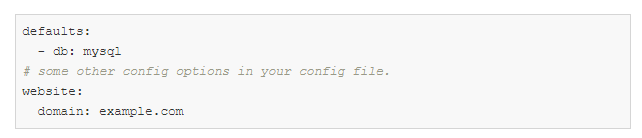
defaults is a special directive that tells Hydra to use db / mysql.yaml when composing a configuration object.
Now you can choose which database configuration to use, as well as override parameter values from the command line:

Check out the tutorial to find out more.
In addition, new interesting features are coming soon:
- strongly typed configurations (structured configuration files),
- optimization of hyperparameters using Ax and Nevergrad plugins,
- launching AWS with the Ray launcher plugin,
- local parallel launch via joblib plugin and much more.
Larq
Binarized Neural Networks
Programming language: Python
Posted by: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq is an open source Python package ecosystem for building, training, and deploying binarized neural networks (BNNs). BNNs are deep learning models in which activations and weights are not encoded using 32, 16, or 8 bits, but using only 1 bit. This can dramatically speed up inference time and reduce power consumption, making BNN ideal for mobile and peripheral applications.
The open source Larq ecosystem has three main components.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
The authors of the project are constantly creating faster models and expanding the Larq ecosystem to new hardware platforms and deep learning applications. For example, work is currently underway to integrate 8-bit quantization end-to-end to be able to train and deploy combinations of binary and 8-bit networks using Larq.
Resources and Links
Website | GitHub larq / larq | GitHub larq / zoo | GitHub larq / compute-engine | Textbooks | Blog | Twitter
McKernel
Nuclear Methods in Logarithmically Linear Time
Programming language: C / C ++
Posted by J. de Curtó i Díaz
Twitter | Website
The first open source C ++ library providing both a random-feature approximation of kernel methods and a full-fledged Deep Learning framework.
McKernel provides four different uses.
- Self-contained lightning-fast open source Hadamard code. For use in areas such as compression, encryption, or quantum computing.
- Extremely fast nuclear techniques. Can be used wherever SVM methods (Support Vector Method: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) are superior to Deep Learning. For example, some robotics applications and some machine learning use cases in healthcare and other areas include Federated Learning and channel selection.
- Integration of Deep Learning and nuclear methods allows the development of Deep Learning architecture in an a priori anthropomorphic / mathematical direction.
- Deep Learning research framework for solving a number of open questions in machine learning.
The equation describing all calculations is as follows:

Here the authors as pioneers formalism used to explain using random symptoms as methods Deep Learning , and nuclear techniques . The theoretical basis is based on four giants: Gauss, Wiener, Fourier and Kalman. The foundation for this was laid by Rahimi and Rekht (NIPS 2007) and Le et al. (ICML 2013).
Targeting the typical user
McKernel's primary audiences are researchers and practitioners in the fields of robotics, machine learning for healthcare, signal processing and communications who need efficient and fast implementation in C ++. In the described case, most of the Deep Learning libraries do not meet the given conditions, since they are mostly based on high-level Python implementations. In addition, the audience may be representatives of the broader machine learning and Deep Learning community, who are in search of improving the architecture of neural networks using nuclear methods.
A super simple visual example for running a library without spending time looks like this:

What's next?
End-to-End Learning, Self-Supervised Learning, Meta-Learning, Integration with Evolutionary Strategies, Significantly Reducing Search Space with NAS, ...
Resources and Links
GitHub | Full presentation
SCCH Training Engine
Automation routines for Deep Learning
Programming language: Python
Posted by: Natalya Shepeleva
Twitter | LinkedIn | Website
Developing a typical Deep Learning pipeline is fairly standard: data preprocessing, task design / implementation, model training, and outcome evaluation. Nevertheless, from project to project, its use requires the participation of an engineer at every stage of development, which leads to repetition of the same actions, duplication of code and, in the end, leads to errors.
The goal of the SCCH Training Engine is to unify and automate the Deep Learning development process for the two most popular frameworks PyTorch and TensorFlow. The single-entry architecture minimizes development time and protects against bugs.
For whom?
The flexible architecture of the SCCH Training Engine has two levels of user experience.
Main. At this level, the user must provide data for training and write the training parameters of the model in the configuration file. After that, all processes, including data processing, model training and validation of the results, will be performed automatically. As a result, a trained model will be obtained within one of the main frameworks.
Advanced.Thanks to the modular component concept, the user can modify the modules according to their needs, deploying their own models and using various loss functions and quality metrics. This modular architecture allows you to add additional features without interfering with the operation of the main pipeline.
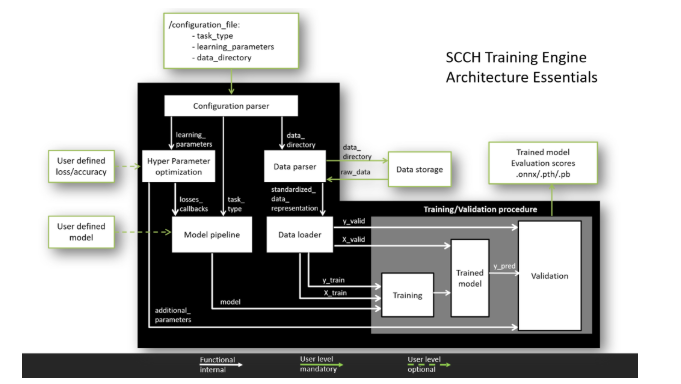
What can he do?
Current capabilities:
- work with TensorFlow and PyTorch,
- a standardized pipeline for parsing data from various formats,
- a standardized pipeline for model training and validation of results,
- support for classification, segmentation and detection tasks,
- cross-validation support.
Features under development:
- search for optimal model hyperparameters,
- loading model weights and training from a specific control point,
- GAN architecture support.
How it works?
To see the SCCH Training Engine in all its glory, you need to take two steps.
- Just copy the repository and install the required packages using the command: pip install requirements.txt.
- Run python main.py to see an MNIST case study with processing and training on a LeNet-5 model.
All information on how to create a config file and how to use advanced features can be found on the GitHub page .
Stable release with core features: scheduled for late May 2020.
Resources and Links
GitHub | Web site
Tokenizers
Text tokenizers
Programming language: Rust with Python API
Posted by: Anthony Mua
Twitter | LinkedIn | GitHub
huggingface / tokenizers provides access to the most modern tokenizers, with a focus on performance and multipurpose use. Tokenizers allows you to train and use tokenizers effortlessly. Tokenizers can help you regardless of whether you are a scholar or practitioner in the NLP field.
Key features
- Extreme speed: Tokenization shouldn't be a bottleneck in your pipeline, and you don't need to pre-process your data. Thanks to the native Rust implementation, tokenization of gigabytes of text takes only a few seconds.
- Offsets / Alignment: Provides offset control even when processing text with complex normalization procedures. This makes it easy to extract text for tasks like NER or question answering.
- Preprocessing: takes care of any preprocessing needed before feeding data into your language model (truncation, padding, adding special tokens, etc.).
- Ease of Learning: Train any tokenizer on a new chassis. For example, learning a tokenizer for BERT in a new language has never been easier.
- Multi-languages: a bundle with multiple languages. You can start using it right now with Python, Node.js, or Rust. Work in this direction continues!
Example:

And soon:
- serialization to a single file and loading in one line for any tokenizer,
- Unigram support.
Hugging Face sees their mission as helping to promote and democratize NLP. GitHub
Resources and Links
huggingface / transformers | GitHub huggingface / tokenizers | Twitter
Conclusion
In conclusion, it should be noted that there are a large number of libraries that are useful for Deep Learning and machine learning in general, and there is no way to describe all of them in one article. Some of the projects described above will be useful in specific cases, some are already well-known, and some wonderful projects, unfortunately, did not make it into the article.
We at CleverDATA strive to keep up with the emergence of new tools and useful libraries, as well as actively apply fresh approaches in our work related to the use of Deep Learning and Machine Learning. For my part, I would like to draw the attention of readers to these two libraries, which are not included in the main article, but significantly help in working with neural networks: Catalyst (https://catalyst-team.com ) and Albumentation ( https://albumentations.ai/ ).
I am sure that every practicing specialist has his own favorite tools and libraries, including those little known to a wide audience. If you think that any useful tools in your work have been in vain ignored, then please write them in the comments: even a mention in the discussion will help promising projects to attract new followers, and the increase in popularity, in turn, leads to improved functionality and development libraries.
Thank you for your attention and I hope that the presented set of libraries will be useful in your work!