The story described is not a fantasy, but a collective description of a couple of events in 2020. In large companies, a disaster recovery plan (DRP) is always at hand for this case. In corporations, business continuity specialists are responsible for this. But in medium and small companies, the solution to such problems falls on the IT department. You need to understand the business logic yourself, understand what can fall and where, come up with protection and implement.
It's great if the IT professional manages to negotiate with the business and discuss the need for protection. But I have seen more than once how the company economized on a disaster recovery (DR) solution, as it considered it redundant. When an accident struck, a long recovery threatened with losses, and the business was not ready. You can repeat as much as you like: “But I told you” - the IT service will still have to restore the services.

From the perspective of an architect, I will tell you how to avoid this situation. In the first part of the article I will show the preparatory work: how to discuss three questions with the customer for choosing protection tools:
- What are we protecting?
- What are we protecting from?
- How strong are we protecting?
In the second part, we'll talk about the options for answering the question: what to defend with. I will give examples of cases of how different customers build their protection.
What we protect: clarifying critical business functions
It is best to start preparation by discussing the disaster plan with the business client. The main difficulty here is to find a common language. The customer usually doesn't care how the IT solution works. He cares if the service can perform business functions and make money. For example: if the site is working, and the payment system is “lying”, there are no receipts from clients, and “extreme” ones are still IT specialists.
An IT professional may find it difficult to negotiate for several reasons:
- The IT service is not fully aware of the role of the information system in business. For example, if there is no available description of business processes or a transparent business model.
- Not the entire process depends on the IT department. For example, when some of the work is done by contractors, and the IT specialists have no direct influence on them.
I would structure the conversation like this:
- We explain to business that accidents happen to everyone, and recovery takes time. The best thing is to demonstrate the situation, how it happens and what consequences are possible.
- We show that not everything depends on the IT service, but you are ready to help with an action plan in your area of responsibility.
- We ask the business customer to answer: if an apocalypse happens, which process should be restored first? Who participates in it and how?
The business needs a simple answer, for example: the call center needs to continue to register requests 24/7.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- We find out the possible points of failure: the nodes of the system on which the service performance depends. Separately, we mark the nodes that are supported by other companies: telecom operators, hosting providers, data centers, and so on. With this, you can go back to the business customer for the next step.
What we protect from: risks
Then we find out from the business customer what risks we are protecting against in the first place. We will conditionally divide all risks into two groups:
- loss of time due to service downtime;
- loss of data due to physical impact, human factors, etc.
Business is scared to lose both data and time - all this leads to a loss of money. So again we ask questions about each risk group:
- Can we estimate for this process how much data loss and time wasted are worth?
- What data can we not lose?
- Where can we not allow downtime?
- What events are most likely and more threatening to us?
After discussion, we will understand how to prioritize points of failure.
How strong we protect: RPO and RTO
When the critical points of failure are understood, we calculate the RTO and RPO metrics.
Let me remind you that RTO (recovery time objective) is the allowable time from the moment of the accident to the full recovery of the service. In business language, this is the acceptable downtime. If we know how much money the process brought in, then we can calculate the losses from each minute of downtime and calculate the allowable loss.
RPO (recovery point objective) is a valid data recovery point. It determines the time in which we can lose data. From a business perspective, data loss can lead to, for example, fines. Such losses can also be converted into money.
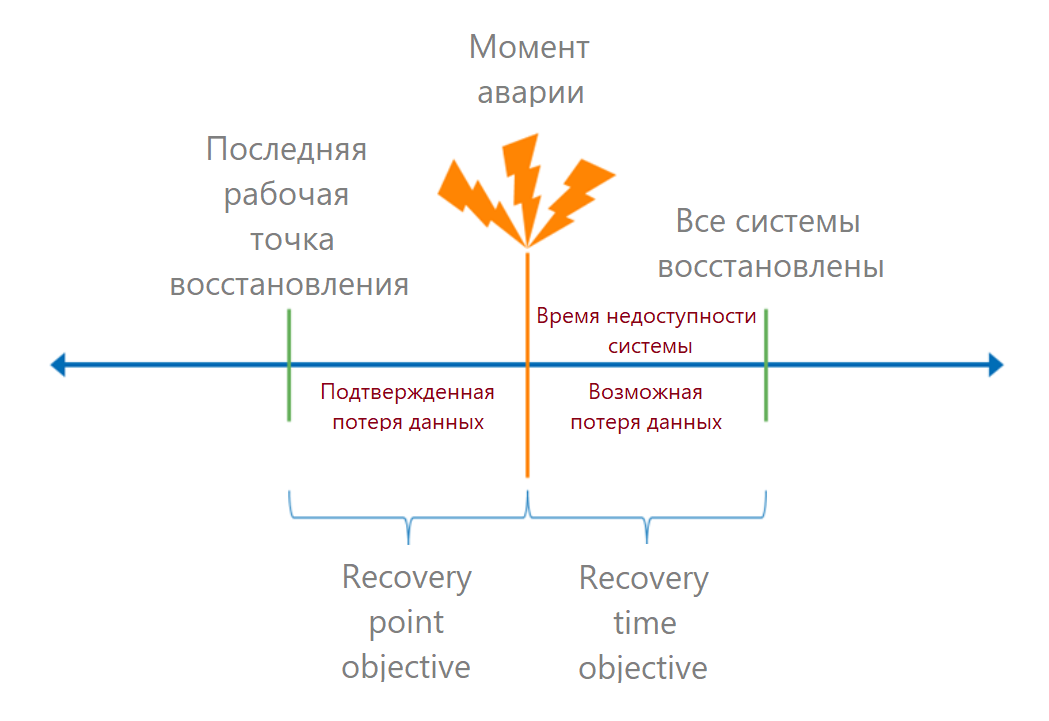
The recovery time should be calculated for the end user: how long it will take to log on to the system. So first we add the recovery times of all the links in the chain. Here they often make a mistake: they take the RTO provider from the SLA, and forget about the other terms.
Let's look at a specific example. The user enters 1C, the system opens with a database error. He contacts the system administrator. The base is in the cloud, the sysadmin reports the problem to the service provider. Let's say all communications take 15 minutes. In the cloud, a database of this size will be restored from a backup in an hour, therefore, RTO on the side of the service provider - an hour. But this is not the final deadline, for the user 15 minutes were added to it to detect the problem.These calculations will show the business on what external factors the recovery time depends. For example, if the office is flooded, then first you need to detect the leak and fix it. It will take time that does not depend on IT.
Next, the system administrator needs to check that the database is correct, connect it to 1C and start the services. It takes another hour, which means that the RTO on the administrator's side is already 2 hours 15 minutes. The user needs another 15 minutes: log in, check that the necessary transactions have appeared. 2 hours 30 minutes is the total recovery time for the service in this example.
How we protect: choosing tools for different risks
After discussing all the points, the customer already understands the cost of the accident for the business. Now you can select tools and discuss the budget. I will show by examples of client cases what tools we offer for different tasks.
Let's start with the first group of risks: losses due to service downtime. The solutions for this task should provide a good RTO.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
All considered solutions provide high availability, but do not save you from data loss due to an encryption virus or accidental employee error. In this case, we need backups that provide the required RPO.
5. Don't forget about backups
Everyone knows that you need to make backups, even if you have the coolest disaster recovery solution. So I will just briefly recall a few points.
Strictly speaking, backup is not DR. And that's why:
- It takes a long time. If the data is measured in terabytes, it will take more than one hour to recover. You need to restore, assign a network, check what turns on, see that the data is in order. So you can only achieve a good RTO if there is little data.
- Data may not be restored the first time, and you need to set aside time for a second action. For example, there are times when we do not know exactly when the data was lost. Let's say the loss was noticed at 15.00, and copies are made every hour. From 15.00 we watch all recovery points: 14:00, 13:00, and so on. If the system is critical, we try to minimize the age of the restore point. But if the necessary data was not found in the fresh backup, we take the next point - this is additional time.
That being said, the backup schedule can provide the required RPO . For backups, it is important to provide geo-redundancy in case of problems with the main site. It is recommended to keep some of the backups separately.
The final disaster recovery plan should include at least 2 tools:
- One of the options 1-4, which will protect systems from crashes and crashes.
- Backup to protect data from loss.
It is also worth taking care of a backup communication channel in case the main Internet provider crashes. And voila! - DR on minimum salaries is already ready.