Hello! My name is Igor Narazin, I am the team leader of the Delivery Club logistics team. I want to tell you how we build and transform our architecture and how it affects our development processes.
Now Delivery Club (like the entire foodtech market) is growing very rapidly, which creates a huge number of challenges for the technical team, which can be summarized by two of the most important criteria:
- It is necessary to ensure high stability and availability of all parts of the platform.
- At the same time, keep a high pace of development of new features.
It seems that these two problems are mutually exclusive: we either transform the platform, trying to make new changes as little as possible until we finish, or we quickly develop new features without drastic changes in the system.
But we succeed (so far) both. How we do this will be discussed further.
First, I will tell you about our platform : how we transform it taking into account the constantly growing volumes of data, what criteria we apply to our services and what problems we face along the way.
Secondly, I will share how we solve the problem of delivering features without conflicting with changes in the platform and without unnecessary degradation of the system.
Let's start with the platform.
In the beginning there was a monolith
The first lines of Delivery Club code were written 11 years ago, and in the best traditions of the genre, the architecture was a monolith in PHP. For 7 years it was filled with more and more functionality until it faced the classic problems of monolithic architecture.
At first, we were completely satisfied with it: it was easy to maintain, test and deploy. And he coped with the initial loads without problems. But, as is usually the case, at some point we reached such growth rates that our monolith became a very dangerous bottleneck:
- any failure or problem in the monolith will affect absolutely all of our processes;
- the monolith is rigidly tied to a specific stack that cannot be changed;
- taking into account the growth of the development team, it becomes difficult to make changes: the high connectivity of the components does not allow fast delivery of features
- the monolith cannot be flexibly scaled.
This led us to the (surprise) microservice architecture - a lot has been said and written about its advantages and disadvantages. The main thing is that it solves one of our main problems and allows us to achieve maximum availability and fault tolerance of the entire system. I will not dwell on this in this article, instead I will tell you with examples how we did it and why.
Our main problem was the size of the monolith codebase and the poor expertise of the team in it (the platform is what we call old). Of course, at first we just wanted to take and cut the monolith in order to completely resolve the issue. But we realized very quickly that it would take more than one year, and the number of changes that were made there would never allow it to end.
Therefore, we went the other way: we left it as it is, and decided to build the rest of the services around the monolith. It continues to be the main point of order processing logic and data master, but starts streaming data for other services.
Ecosystem
As Andrey Evsyukov said in an article about our teams, we have highlighted the main areas of domain areas: R&D, Logistics, Consumer, Vendor, Internal, Platform. Within these areas, the main domain areas with which the services work are already concentrated: for example, for Logistics, these are couriers and orders, and for Vendor - restaurants and positions.
Next, we need to rise to a higher level and build an ecosystem of our services around the platform: order processing is in the center and is the data master, the rest of the services are built around it. At the same time, it is important for us to make our directions autonomous: if one part fails, the rest continue to function.
At low loads, it is quite simple to build the necessary ecosystem: our processing processes and stores data, and referral services turn to them as needed.
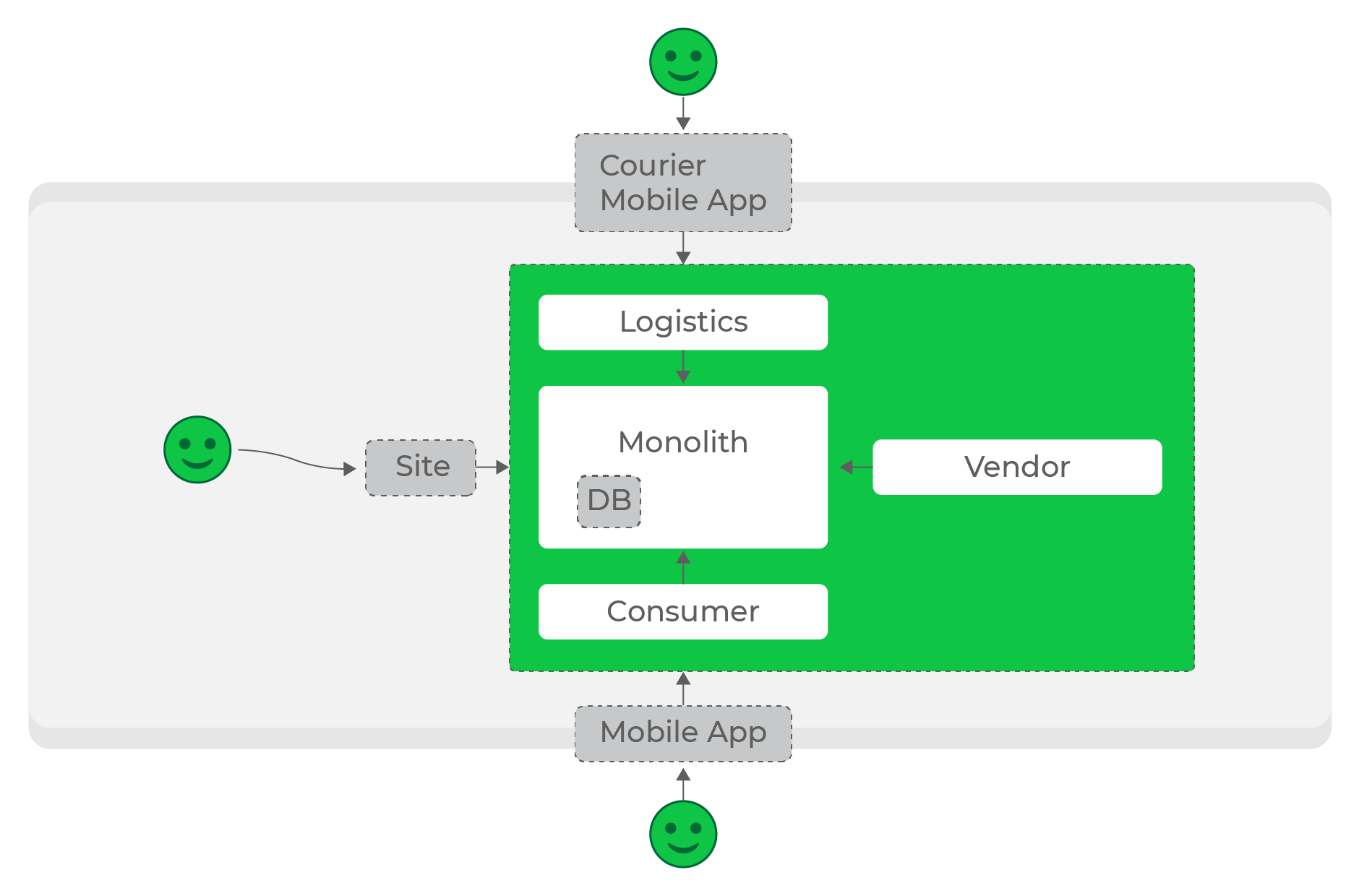 Low loads, synchronous requests, everything works great.
Low loads, synchronous requests, everything works great.
At the first stages, we did just that: most of the services communicated with each other with synchronous HTTP requests. Under a certain load, this was permissible, but the more the project and the number of services grew, the more problem it became.
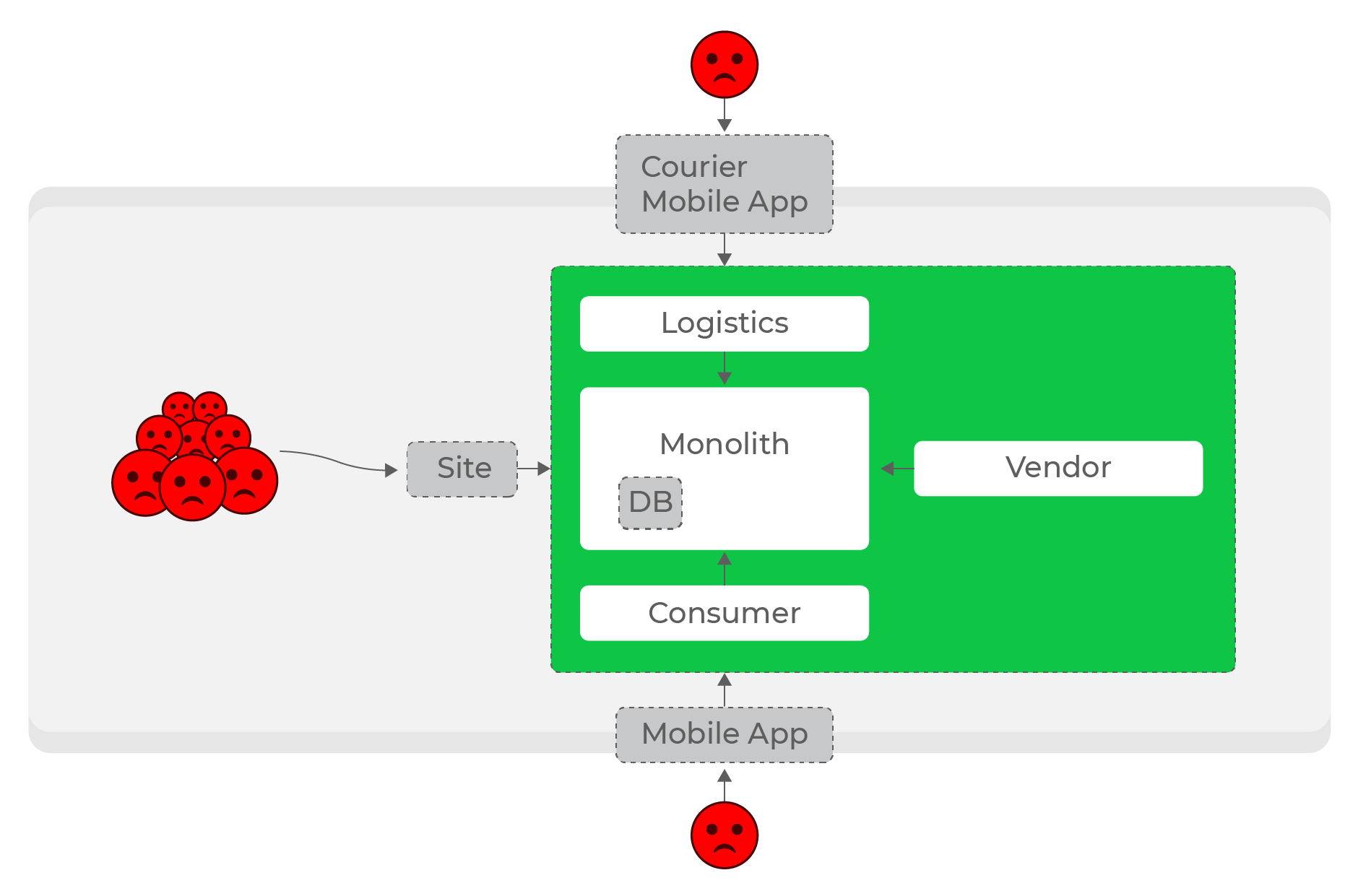
High loads, synchronous requests: everyone suffers, even users of completely different domains - couriers.
It is even more difficult to make services autonomous within directions: for example, an increase in the load on logistics should not affect the rest of the system. With any number of synchronous requests, this is an unsolvable problem. Obviously, it was necessary to abandon synchronous requests and move on to asynchronous communication.
Data bus
Thus, we got a lot of bottlenecks, where we accessed data in a synchronous mode. These places were very dangerous in terms of increased load.
Here's an example. Whoever made an order through Delivery Club at least once knows that after the courier picks up the order, the card becomes visible. On it you can track the movement of the courier in real time. For this feature, several microservices are involved, the main ones are:
mobile-gatewaywhich is a backend for frontend for a mobile application;courier-tracker, which stores the logic of receiving and sending coordinates;logistics-courierswhich stores these coordinates. They are sent from courier mobile applications.
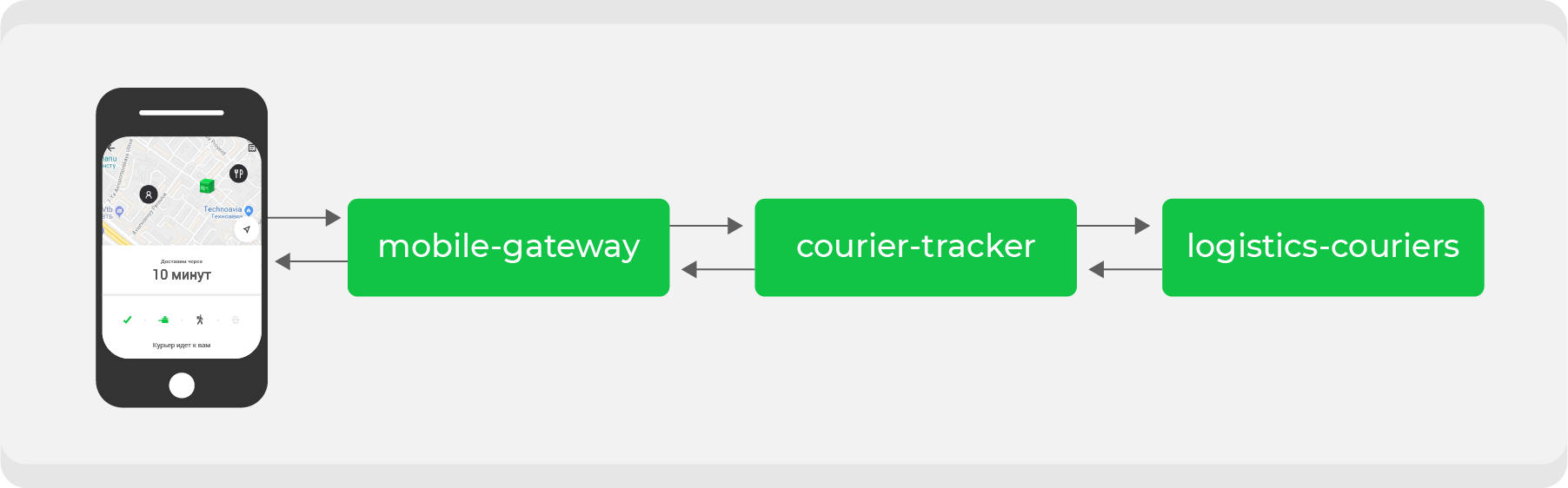
In the original scheme, this all worked synchronously: requests from the mobile application once a minute went through
mobile-gatewayto the service courier-trackerthat accessed logistics-couriersand received coordinates. Of course, in this scheme it was not so simple, but in the end it all boiled down to a simple conclusion: the more active orders we have, the more requests for coordinates were received in logistics-couriers.
Our growth is sometimes unpredictable and, most importantly, fast - a matter of time before such a scheme fails. This means that we need to redo the process for asynchronous interaction: to make the request for coordinates as cheap as possible. To do this, we need to transform our data streams.
Transport
We have already used RabbitMQ, including for communication between services. But as the main mode of transport, we settled on the already well-proven tool - Apache Kafka. We will write a separate detailed article about it, but now I would like to briefly talk about how we use it.
When we first started implementing Kafka as a transport, we used it in its raw form, connecting directly to brokers and sending messages to them. This approach allowed us to quickly test Kafka in combat and decide whether to continue using it as our primary mode of transport.
But this approach has a significant drawback: messages do not have any typing and validation - we do not know for sure which message format we read from the topic.
This increases the risk of errors and inconsistencies between the services that provide the data and those that consume it.
To solve this problem, we wrote a wrapper - a microservice in Go, which hides Kafka behind its API. This added two benefits:
- data validation at the time of sending and receiving. In fact, these are the same DTOs, so we are always confident in the format of the expected data.
- fast integration of our services with this transport.
Thus, working with Kafka has become as abstract as possible for our services: they only work with the top-level API of this wrapper.
Let's go back to the example
By transferring synchronous communication to the event bus, we need to invert the data flow: what we asked for should now reach us through Kafka itself. In the example, we are talking about the coordinates of the courier, for which we will now create a special topic and will produce them as we receive them from the couriers by the service
logistics-couriers.
The service
courier-trackeronly has to accumulate coordinates in the required amount and for the required period. As a result, our endpoint becomes as simple as possible: take data from the service database and give it to a mobile application. The increase in the load on it is now safe for us.
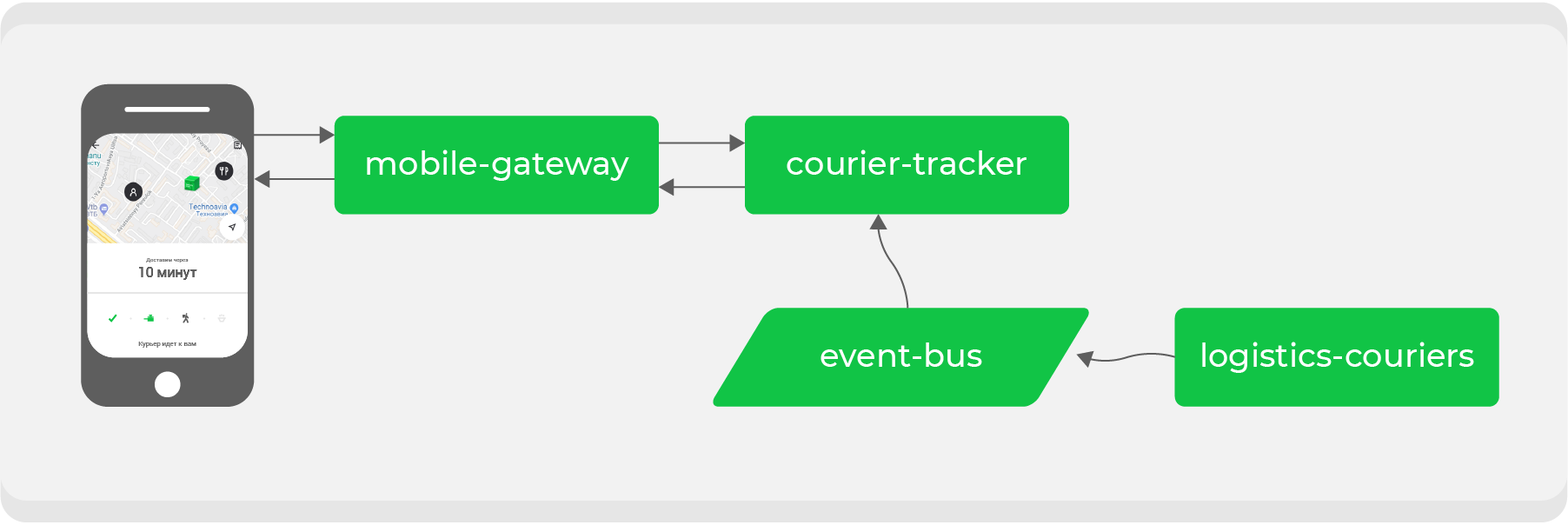
In addition to solving a specific problem, as a result, we get a data topic with the actual coordinates of couriers, which any of our services can use for their own purposes.
Eventually consistency
In this example, everything works cool, except that the coordinates of the couriers will not always be up-to-date compared to the synchronous option: in the architecture built on asynchronous interaction, the question arises about the relevance of the data at each moment in time. But we don't have a lot of critical data that we need to keep always fresh, so this scheme is ideal for us: we sacrifice the relevance of some information in order to increase the level of system availability. But we guarantee that in the end, in all parts of the system, all data will be relevant and consistent (eventually consistency).
This denormalization of data is necessary when it comes to a high-load system and microservice architecture: each service itself ensures the storage of the data that it needs to work. For example, one of the main entities of our domain is the courier. Many services operate with it, but they all need a different set of data: someone needs personal data, and someone only needs information about the type of movement. The data master of this domain will produce the entire entity into the stream, and the services accumulate the necessary parts:
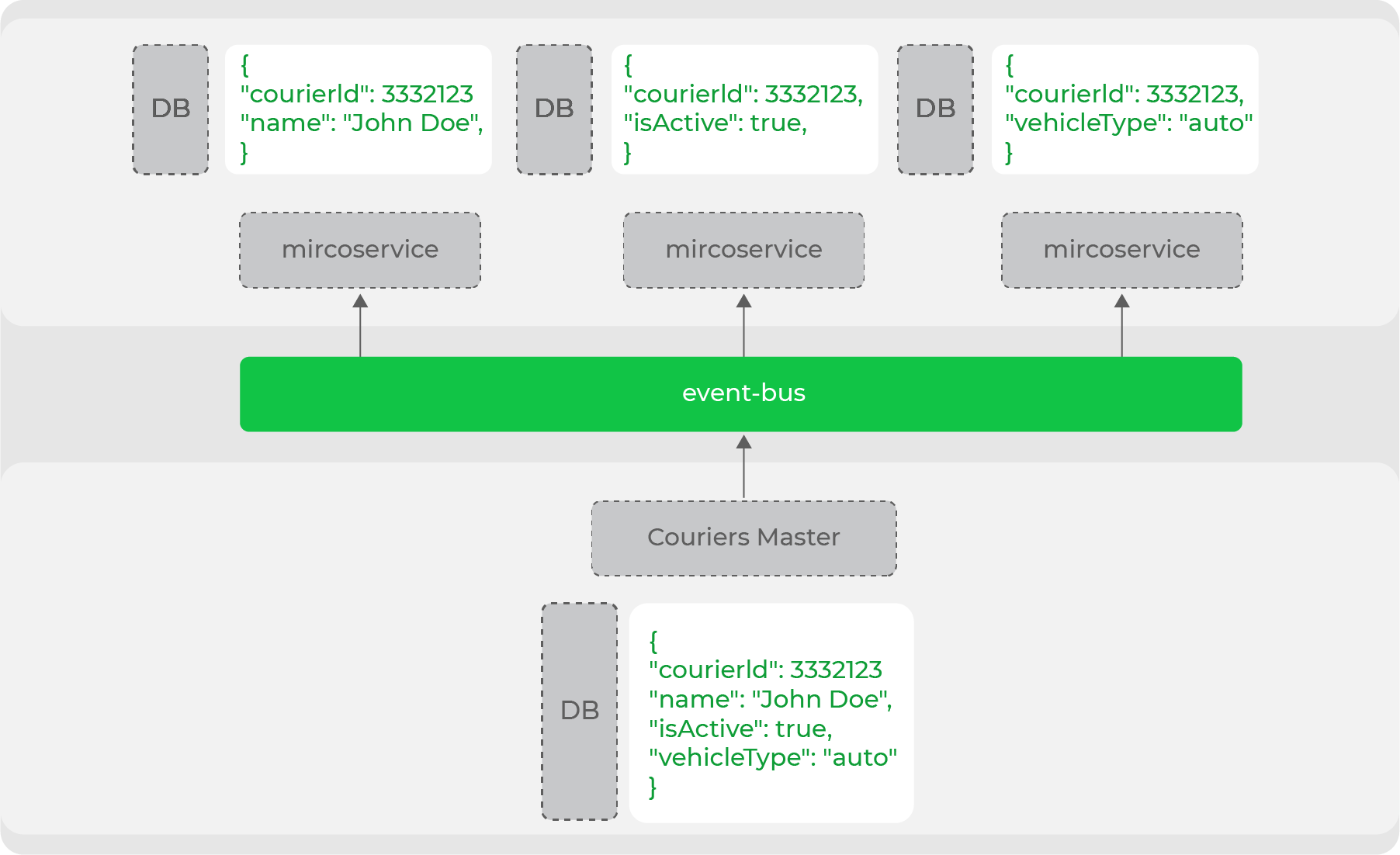
Thus, we clearly divide our services into those who are data masters and those who use this data. In fact, this is headless commerce from the evolutionary archicture - we have clearly separated all "storefronts" (website, mobile applications) from the producers of this data.
Denormalization
Another example: we have a mechanism for targeted notifications to couriers - these are messages that will come to them in the application. On the backend side, there is a powerful API for sending such notifications. In it, you can configure mailing filters: from a specific courier to groups of couriers based on certain criteria.
The service is responsible for these notifications
logistics-courier-notifications. After he has received a request to send, his task is to generate messages for those couriers who have been targeted. To do this, he needs to know the necessary information on all Delivery Club couriers. And we have two options for solving this problem:
- make an endpoint on the service side - the courier data wizard (
logistics-couriers), which will be able to filter and return the necessary couriers by the transmitted fields; - store all the necessary information directly in the service, consuming it from the relevant topic and storing the data by which we will need to filter in the future.
Some of the logic for generating messages and filtering couriers is not loaded, it is executed in the background, so there is no question of service loads
logistics-couriers. But if we choose the first option, we are faced with a set of problems:
- you will have to support a highly specialized endpoint in a third-party service, which, most likely, only we will need;
- If you select a filter that is too wide, then all couriers that simply do not fit into the HTTP response will be included in the sample, and you will have to implement pagination (and iterate over it when polling the service).
Obviously, we stopped at storing data in the service itself. It autonomously and in isolation performs all the work, not accessing anywhere, but only accumulating all the necessary data from itself from the Kafka topic. There is a risk that we will receive a message about the creation of a new courier later, and it will not be included in some selection. But this disadvantage of an asynchronous architecture is inevitable.
As a result, we have formulated several important principles for designing services:
- The service must have a specific responsibility. If a service is needed for its full-fledged functioning, then this is a design mistake, they must either be combined or the architecture must be revised.
- We look critically at any synchronous calls. For services in one direction, this is acceptable, but for communication between services in different directions - no
- Share nothing. We do not go to the database of services bypassing them. All requests only through the API.
- Specification First. First, we describe and approve the protocols.
Thus, by iteratively transforming our system according to the accepted principles and approaches, we came to the following architecture:
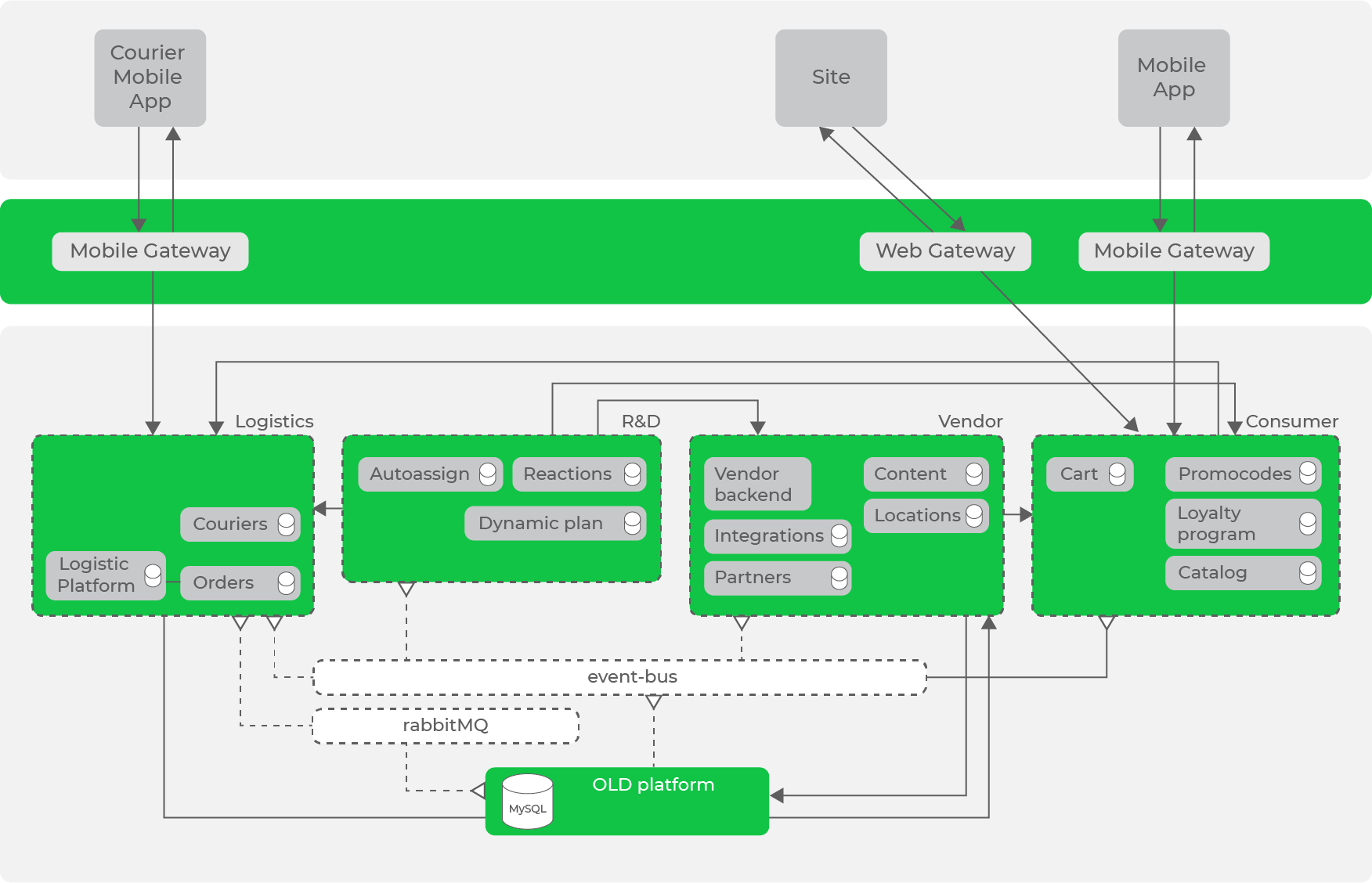
We already have a data bus in the form of Kafka, which already has a significant number of data streams, but there are still synchronous requests between directions.
How we plan to develop our architecture
Delivery club, as I said at the beginning, is growing rapidly, we are releasing a huge number of new features into production. And we experiment even more ( Nikolay Arkhipov spoke about this in detail ) and test hypotheses. This all gives rise to a huge number of data sources and even more options for their use. And the correct management of data flows, which is very important to correctly build - this is our task.
From now on, we will continue to implement the developed approaches to all Delivery Club services: to build service ecosystems around a platform with transport in the form of a data bus.
The primary task is to ensure that information on all domains in the system is supplied to the data bus. For new services with new data, this is not a problem: at the stage of preparing the service, he will be obliged to stream his domain data to Kafka.
But besides the new ones, we have large legacy services with data on our main domains: orders and couriers. It is problematic to stream this data “as is”, since it is stored spread over dozens of tables, and it will be very expensive to build the final entity to produce all the changes each time.
Therefore, we decided to use Debezium for old services ., which allows you to stream information directly from tables based on bin-log: as a result, you get a ready-made topic with raw data from the table. But they are unsuitable for use in their original form, therefore, through the transformers at the Kafka level, they will be converted into a format that is understandable for consumers and pushed into a new topic. Thus, we will have a set of private topics with raw data from tables, which will be transformed into a convenient format and broadcast to a public topic for use by consumers.
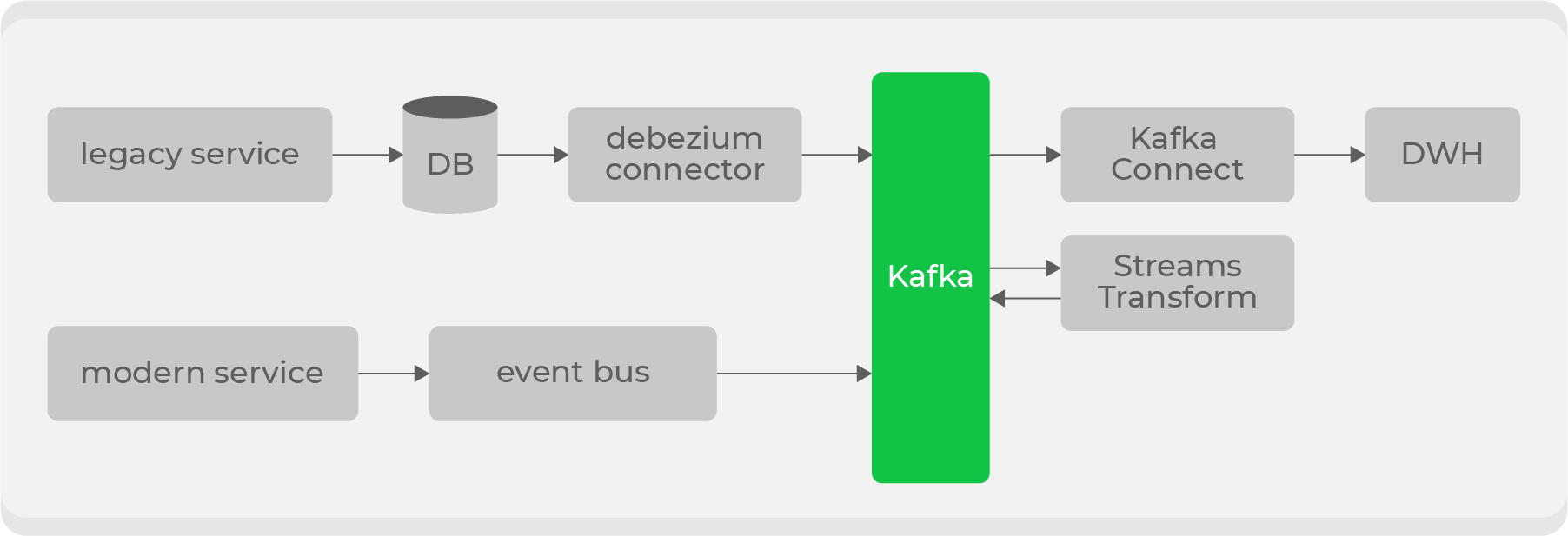
There will be several entry points for writing to Kafka and different types of topics, so further we will implement access rights by role on the storage side and add schema validation on the data bus side via Confluent .
Further from the data bus, services will consume data from the necessary topics. And we ourselves will use this data for our systems: for example, stream through Kafka Connect to ElasticSearch or DWH. With the latter, the process will be more complicated: in order for the information in it to be available to everyone, it must be cleared of any personal data.
We also need to finally resolve the issue with the monolith: there are still critical processes that we will endure in the near future. More recently, we have already rolled out a separate service that deals with the first stage of creating an order: forming a basket, a receipt and payment. Then he sends this data to the monolith for further processing. Well, all other operations no longer require synchronization.
How to do this refactoring transparently for clients
I'll tell you about one more example: a restaurant catalog. Obviously, this is a very busy place, and we decided to move it to a separate service on Go. To speed up development, we have divided the takeaway into two stages:
- First, inside the service, we go directly to a replica of the base of our monolith and get data from there.
- Then we start streaming the data we need through Debezium and accumulating it in the database of the service itself.
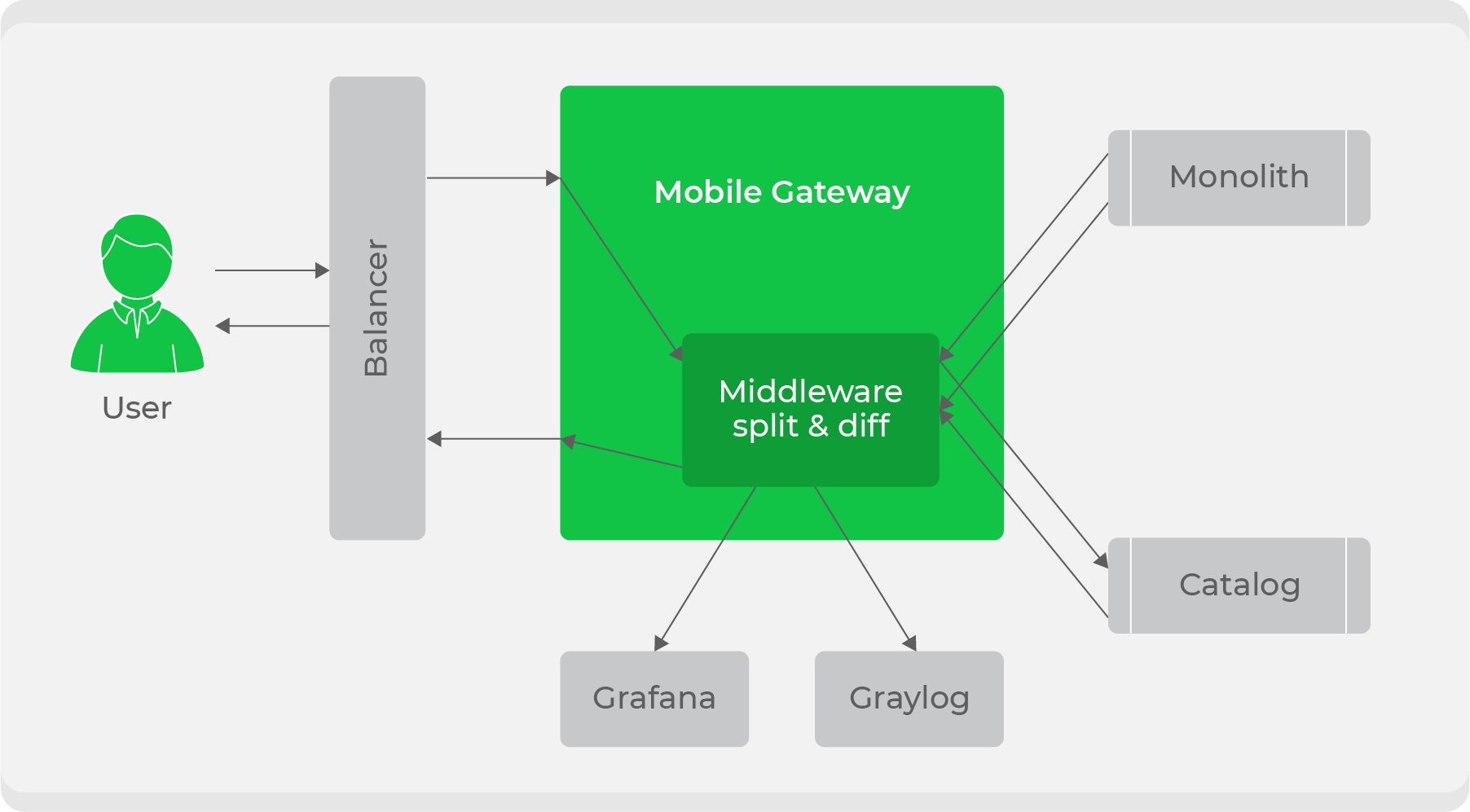
When the service is ready, the question arises of how to transparently integrate it into the current workflow. We used a traffic split scheme: all traffic from clients went to the service
mobile-gateway, and then it was divided between the monolith and the new service. Initially, we continued to process all traffic through the monolith, but we duplicated some of them into a new service, compared their responses and wrote down logs about discrepancies in our metrics. With this, we ensured the transparency of testing the service in combat conditions. After that, it only remained to gradually switch and increase traffic on it until the new service completely replaces the monolith.
In general, we have a lot of ambitious plans and ideas. We are only at the beginning of developing our further strategy, while its final form is not clear and it is not known whether it will all work as we expect. As soon as we implement and draw conclusions, we will definitely share the results.
Along with all these conceptual changes, we continue to actively develop and deliver features to the product, which takes most of the time. Here we come to the second problem, which I talked about at the beginning: taking into account the number of developers (180 people), the issue of validating the architecture and quality of new services arises. The new should not degrade the system, it should be built in correctly from the beginning. But how to control this on an industrial scale?
Architectural Committee
The need for it did not arise immediately. When the development team was small, any changes to the system were easy to control. But the more people there are, the harder it is to do it.
This gives rise to both real problems (the service could not withstand the load due to improper design) and conceptual ones (“let's walk here synchronously, the load is small”).
It is clear that most of the issues are resolved at the team level. But if we are talking about some kind of complex integration into the current system, then the team may simply not have enough expertise. Therefore, I wanted to create some kind of association of people from all directions, to which one could come with any question about architecture and get an exhaustive answer.
So we came to the creation of an architectural committee, which includes team leaders, direction leaders and CTOs. We meet every two weeks and discuss the planned major changes in the system or just solve specific issues.
As a result, we closed the problem with controlling large changes, the question of the general approach to the quality of the code in Delivery Club remains: specific problems of the code or framework in different teams can be solved in different ways. We came to guilds on the Spotify model: these are unions of people who are not indifferent to some technology. For example, there are guilds Go, PHP and Frontend.
They develop uniform programming styles, approaches to design and architecture, help to form and maintain an engineering cultureon the highest level. They also have their own backlog, within which they improve internal tools, for example, our Go-template for microservices.
Product code
In addition to the fact that major changes go through the architectural committee, and guilds monitor the culture of the code in general, we still have an important stage in preparing the service for production: drawing up a checklist in Confluence. First, when drawing up a checklist, the developer evaluates his decision again; secondly, this is an operational requirement, since they need to understand what kind of new service appears in production.
The checklist usually indicates:
- responsible for the service (this is usually the technical lead of the service);
- links to the dashboard with customized alerts;
- service description and link to Swagger;
- a description of the services with which it will interact;
- estimated load on the service;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Service alerts are designed at the stage of architectural approval. It is important that the developer understands that the service is alive and takes into account not only technical metrics, but also product ones. This does not mean any business conversions, but metrics that show that the service is working as it should.
For example, you can take the service already discussed above
courier-tracker, which tracks couriers on the map. One of the main metrics in it is the number of couriers whose coordinates are updated. If suddenly some routes are not updated for a long time, an alert “something went wrong” comes. Maybe somewhere they didn't go to get the data, or they entered the database incorrectly, or some other service fell off. This is not a technical metric or a product metric, but it shows the viability of the service.
For metrics, we use Graylog and Prometheus, build dashboards and set up alerts in Grafana.
Despite the amount of preparation, the delivery of services to production is quite fast: all services are initially packaged in Docker, are rolled out to the stage automatically after the typed chart for Kubernetes is formed, and then everything is decided by a button in Jenkins.
The roll-out of a new service to prod consists in assigning a task to admins in Jira, which provides all the information that we prepared earlier.
Under the hood
We now have 162 microservices written in PHP and Go. They were distributed between services approximately 50% to 50%. Initially, we rewrote some high-load services in Go. Then it became clear that Go is easier to maintain and monitor in production, it has a low entry threshold, so recently we have been writing services only in it. There is no purpose to rewrite the remaining PHP services in Go: it copes with its functions quite successfully.
In PHP services, we have Symfony, on top of which we use our own little framework. It imposes a common architecture on services, thanks to which we lower the threshold for entering the source code of services: no matter what service you open, it will always be clear what is in it and where. And the framework also encapsulates the transport layer of communication between services, for the developer, a request to a third-party service looks at a high level of abstraction:
Here we form the DTO of the request ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), call the method of the protocol object of a specific service, which is a wrapper over a specific endpoint. Under the hood, our object is $courierRequestconverted into a request object, which is filled with fields from the DTO. This is all flexible: fields can be inserted both in the headers and in the request URL itself. Next, the request is sent through cURL, we get the Response object and transform it back into the object we expect $courierResponse.
This allows developers to focus on the business logic, with no interaction details at a low level. Objects of protocols, requests and responses of services are in a separate repository - the SDK of this service. Thanks to this, any service that wants to use its protocols will receive the entire typed protocol package after importing the SDK.
But this process has a big drawback: repositories with the SDK are difficult to maintain, because all DTOs are written manually, and convenient code generation is not easy: there were attempts, but in the end, given the transition to Go, they did not invest time in it.
As a result, changes in the service protocol can turn into several pull requests: into the service itself, into its SDK, and into a service that needs this protocol. In the latter, we need to raise the version of the imported SDK so that the changes will get there. This often raises questions from new developers: "I just changed the parameter, why do I need to make three requests to three different repositories ?!"
In Go, everything is much simpler: we have an excellent code generator (Sergey Popov wrote a detailed article about this), thanks to which the entire protocol is typed, and now even the option of storing all specifications in a separate repository is being discussed. Thus, if someone changes the spec, all services depending on it will immediately start using the updated version.
Technical radar
In addition to the already mentioned Go and PHP, we use a huge number of other technologies. They vary from direction to direction and depend on specific tasks. Basically, on the backend we use:
Python, on which the Data Science team writes.KotlinandSwift- for the development of mobile applications.PostgreSQLas a database, but some older services still run MySQL. In microservices, we use several approaches: each service has its own database and share nothing - we do not go to databases bypassing services, only through their API.ClickHouse- for highly specialized services related to analytics.RedisandMemcachedas in-memory storage.
When choosing a technology, we are guided by special principles . One of the main requirements is Ease of use: we use the most simple and understandable technology for the developer, as much as possible adhering to the accepted stack. For those who want to know the entire stack of specific technologies, we have compiled a very detailed technical radar .
Long story short
As a result, we moved from a monolithic architecture to a microservice one, and now we already have groups of services united by directions (domain areas) around the platform, which is the core and data master.
We have a vision of how to reorganize our data streams and how to do it without affecting the speed of new features development. In the future, we will definitely tell you about where this led us.
And thanks to the active transfer of knowledge and a formalized process of making changes, we are able to deliver a large number of features that do not slow down the process of transforming our architecture.
That's all for me, thanks for reading!