In Surf, we wrote our own interpreter and use it on the client of the mobile application - although initially, it would seem, this generally has little to do with mobile development. In fact, interpreters and compilers are tools for solving problems that can be found anywhere. Therefore, understanding how it works and being able to write your own is useful.
Today, using the example of translating masks from one format to another, we will get acquainted with the basics of constructing interpreters and see how to use formal grammars, an abstract syntax tree, translation rules - including in order to solve business problems.

A little about masks: what they are and why you need them
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
Why can't you just pick up and describe the mask
Masks are cool and comfortable. But there is a problem that is inevitable in certain conditions: when the client has one mask format, and the server has many different data providers and each has its own format. We cannot count on the fact that we will have the same format. Asking the server: "Fit masks for us as we like" - too. You need to be able to live with it.
The problem arises: there is a backend specification, you need to write a frontend - a mobile application. You can manually write all the masks for the application - and this is a good option when there is only one provider and there are few masks. The programmer, of course, will have to spend time to understand at least two specifications for masks: backend and front. Then he needs to translate specific backend masks into corresponding frontend masks. It also takes time, there is a human factor - you can be wrong. It's not an easy job, translation is hard: some mask languages are written primarily for computers, not for humans.
If suddenly the mask on the server has changed or a new one has appeared, then the application, firstly, may stop working. Secondly, the hard work of translation needs to be done again, a new application must be released, it takes time, effort, and money. The question arises: how to minimize the programmer's work? It seems that all this should be done by a machine, but for some reason a person is doing it.
The answer is yes, we have a solution. Masks are written in the language of computers - and this is one of the reasons why it is difficult for a person to work with him and translate from one language to another. We need to transfer this work to the computer. Since the mask appears to be a formal grammar , the surest way to translate one grammar into another is:
- understand the rules for constructing the original grammar,
- understand the rules for constructing the target grammar,
- write translation rules from the source grammar to the target,
- implement all of this in code.
This is what compilers and translators are written for.
Now let's take a closer look at our solution based on formal grammars.
Background
In our application, there are quite a few different screens that are formed according to the backend driven principle: a complete description of the screen, along with the data, comes from the server.

Most of the screens contain a variety of input forms. The server determines what fields are on the form and how they should be formatted. Masks are also used to describe these requirements.
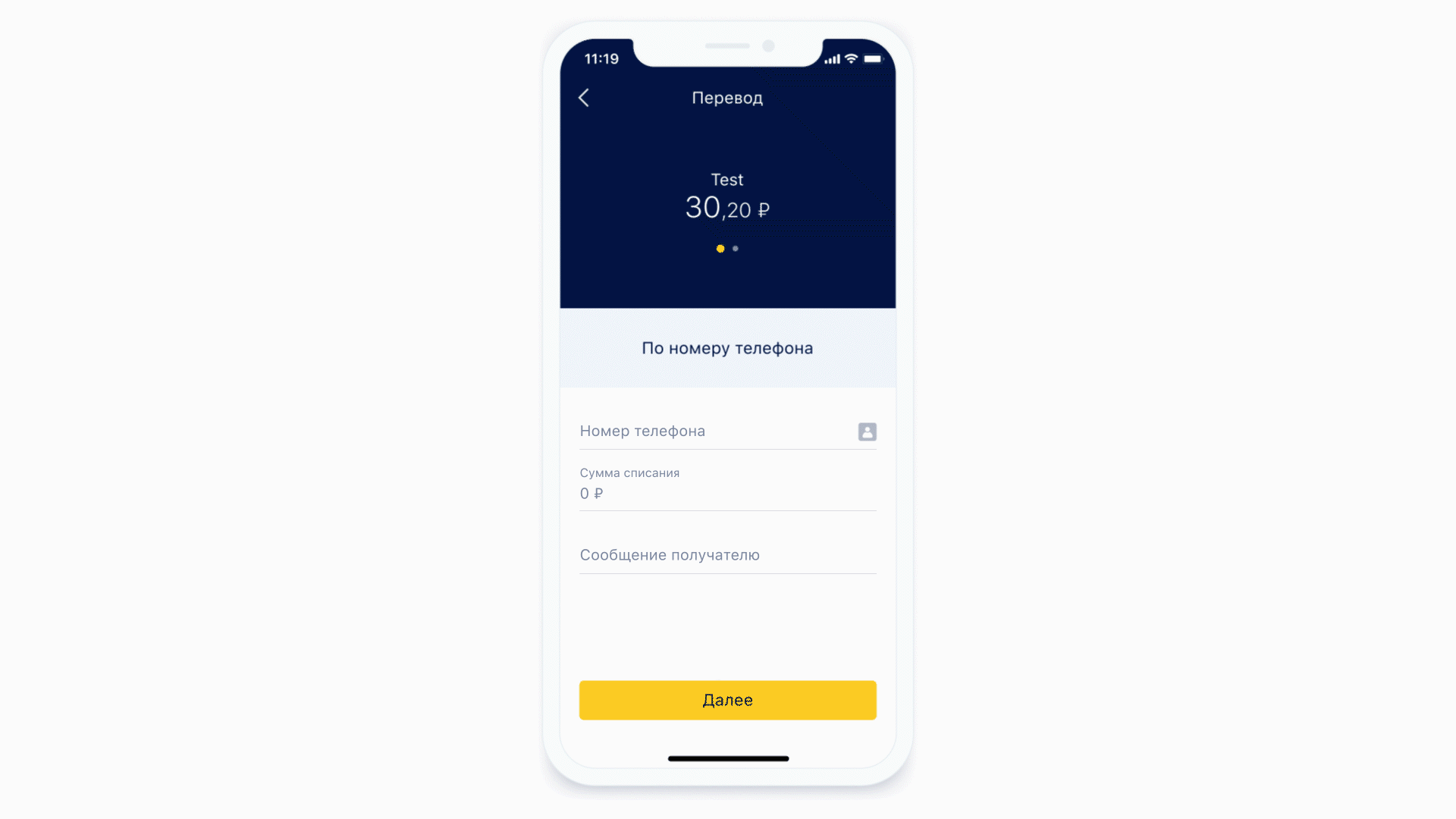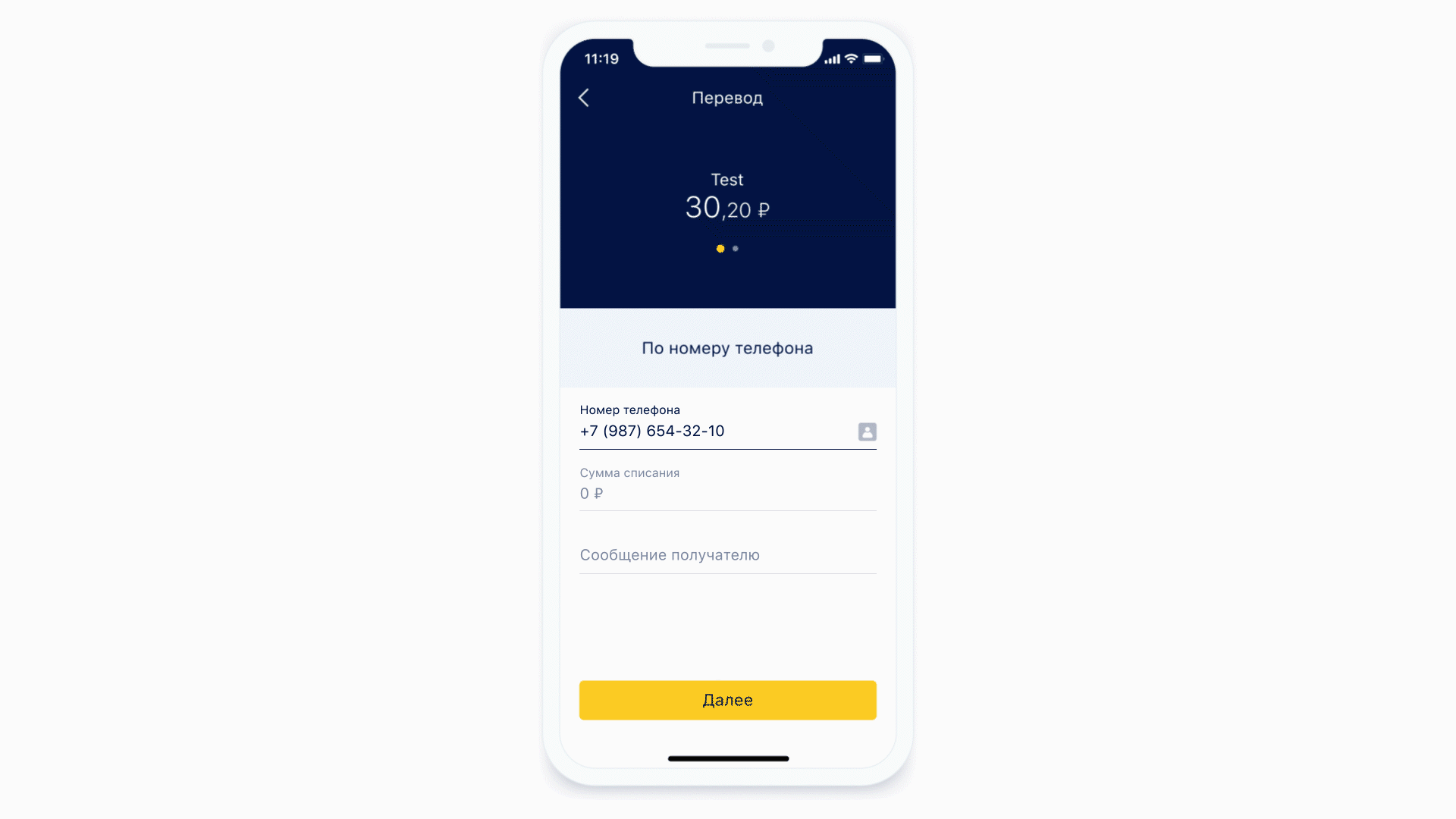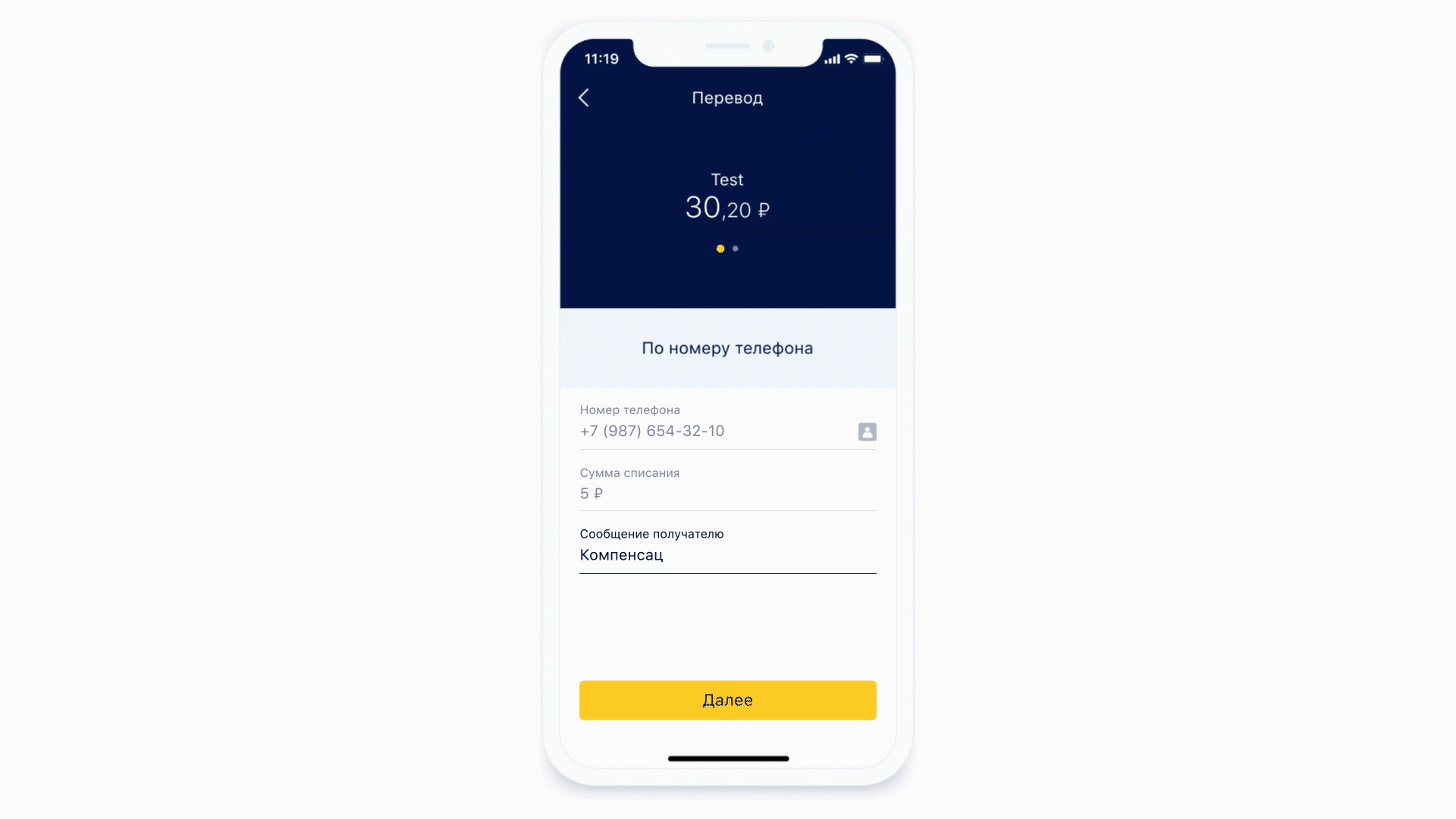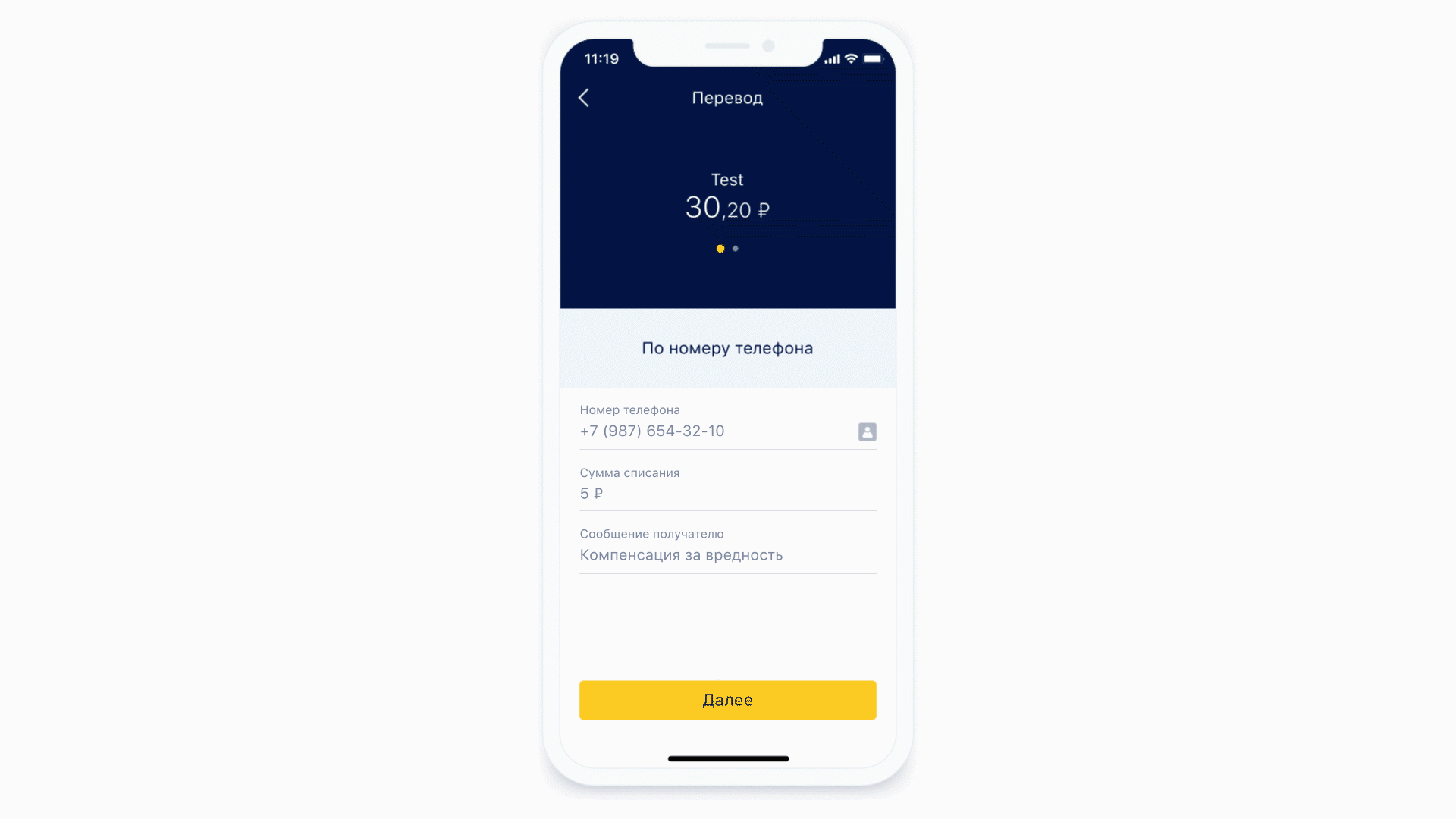
Let's see how the masks work.
Examples of masks in different formats
As a first example, let's take the same form of entering a phone number. The mask for such a shape might look like this.

On the one hand, the mask itself adds delimiters, parentheses and prohibits entering incorrect characters. On the other hand, the same mask extracts useful information from the formatted input to be sent to the server.
The part called the constant is highlighted in red. These are symbols that will appear automatically - the user should not enter them:

Next comes the dynamic part - it is always enclosed in angle brackets:

Further in the text I will call this expression "dynamic expression" - or DW for short
Here is the expression by which we will format our input:

Pieces that are responsible for the contents of the dynamic part are highlighted in red.
\\ d - any digit.
+ - regular repeater: repeat at least once.
$ {3} is a meta information symbol that specifies the number of repetitions. In this case, there should be three characters.
Then the expression \\ d + $ {3} means that there must be three digits.
In this format of masks, there can be only one repeater inside the dynamic part:

This limitation appeared for a reason - now I will explain why.
Let's say we have a DV, in which the size is hard-coded: 4 elements. And we give it 2 elements with a repeater: `<! ^ \\ d + \\ v + $ {4}>`. The following combinations fall under such a DV:
- 1abc
- 12ab
- 123a
It turns out that such a DV does not give us an unambiguous answer, what to expect in the place of the second character: a number or a letter.
Take the mask, add it with user input. We get the formatted phone number:

On the client, the format of the masks may look different. For example, in the Input Mask library from Redmadrobot, the mask for a phone number

looks like this: It looks nicer and easier to understand.
It turns out that the mask for the server and the mask for the client are written differently, but they do the same thing.

Let's reformulate the problem: how to combine masks of different formats
We need to combine these masks with each other - or somehow get the second from one.
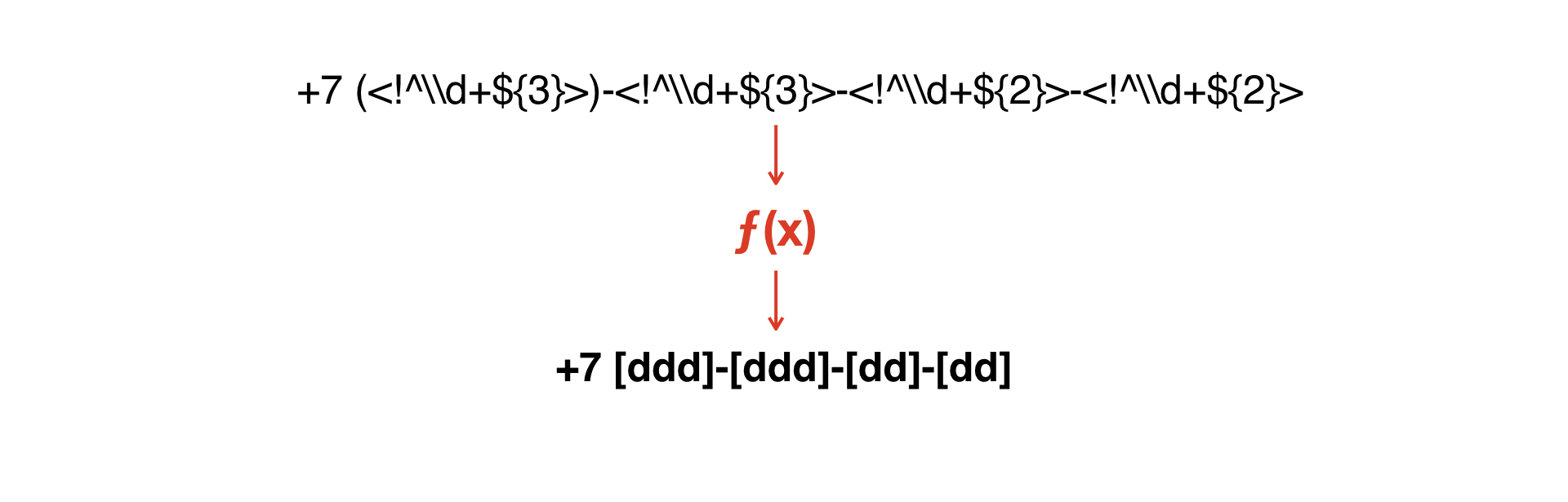
We need to build a function that would convert one mask to the second.
And here the idea came to write a very simple interpreter that would allow getting a second grammar from one grammar.
Since we got to the interpreter, let's talk about grammars.
How parsing is done
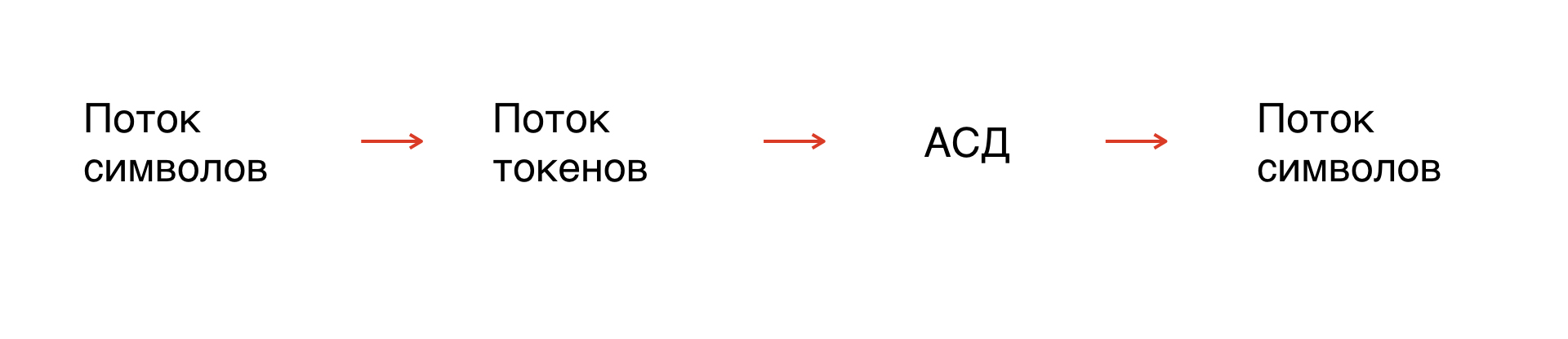
First, we have a stream of characters - our mask. In fact, this is the string that we operate on. But since the symbols are not formalized, you need to formalize the string: break it up into elements that will be understandable to the interpreter.
This process is called tokenization: a stream of symbols turns into a stream of tokens. The number of tokens is limited, they are formalized, therefore, they can be analyzed.
Further, based on the grammar rules, we build an abstract syntax tree along the token flow. From the tree we get a stream of symbols in the grammar we need.
There is an expression. We look at it and see that we have a constant, about which I spoke above: We

represent all constants as a CS token, whose argument is the constant itself:

The next type of tokens is the beginning of the DW:

Further, all such tokens will be interpreted as special characters. In our example, there are not many of them, in real masks there can be much more of them.

Then we have a repeater.
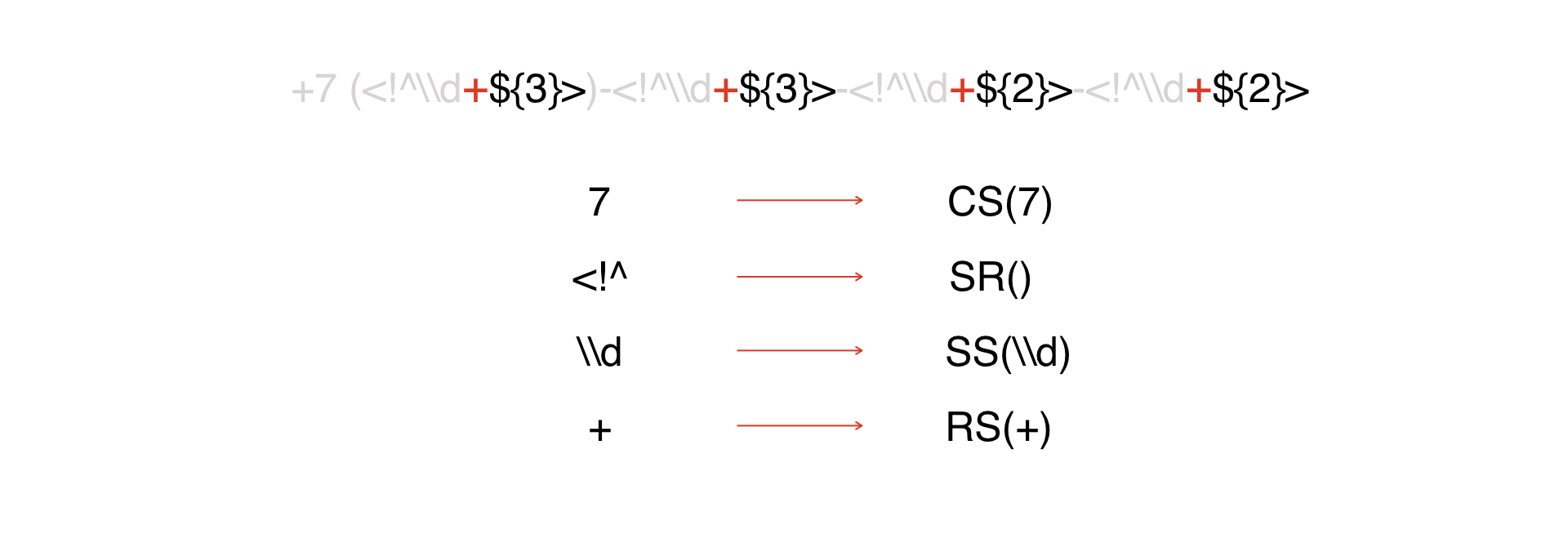
Then - a few characters that are considered metadata. We'll cheat and present them with one token, because it's easier that way.

End of the Far East. Thus, we have decomposed everything into tokens.

An example of tokenizing a mask for a phone number
To see how, in principle, the tokenization process takes place and how the interpreter will work, we take a mask for a phone number and transform it into a stream of tokens.

First, the + symbol. Convert to constant +. Then we do the same for the 7 and for all other symbols. We get an array of tokens. This is not a structure yet - we will analyze this array further.
Lexer and building ASD
Now the tricky part is the lexer.

On the left, a legend is described - special characters that are used to describe lexical rules. On the right are the rules themselves.
The symbolRule describes a symbol. If this rule applies, if it is true, it means that we have encountered either a special character or a constant character. We can say that this is a function.
Next is repeaterRule. This rule describes a situation when a character is encountered, followed by a repeater token.
Then everything looks similar. If it's LW, then it's either symbol or repeater. In our case, this rule is broader. And at the end there must be a token with metadata.
The last rule is maskRule. This is a sequence of symbols and DV.
Now let's buildan abstract syntax tree (AST) from an array of tokens.
Here is a list of tokens. The first node of the tree is the root one, from which we will start building. It doesn't make any sense, it just needs a root.

We have the first token +, which means we just add a child node and that's it.

We do the same with all the other constant symbols, but then it's more complicated. We came across a DV token.

This is not just a regular site - we know that it must have some kind of content.

The content node is just a technical node that we can navigate to in the future. It has its own child nodes and which node will it have next? The next token in our stream is a special character. Will it be a child node?

Actually, in this case, no. We will have a repeater as a child node.

Why? Because it’s more convenient to work with wood in the future. Let's say we want to parse this tree and build some kind of grammar from it. When parsing a tree, we look at the types of nodes. If we have a CS node, then we parse it into the same CS node, but for a different grammar. By convention, we iterate over the tops of the tree and run some kind of logic.
The logic depends on the type of node - or on the type of token that lies in the node. For parsing, it is much more convenient to immediately understand which token is in front of you: composite, like a repeater, or simple, like CS. This is necessary so that there are no double interpretations or constant searches for child nodes.
This would be especially noticeable on groups of characters: for example, [abcde]. In that case, obviously, there must be some kind of parent GROUP node that will have a list of child nodes CS (a) CS (b), etc.
Back to the token with metadata. It is not included in the content, it is on the side.

This is necessary to make it just easier to work with the tree, so that we do not consider this node as content - because in fact it does not belong to it.
The DV ended, and we do not consider it some kind of node: it was a token that can now be thrown away. We will not turn it into a tree node.
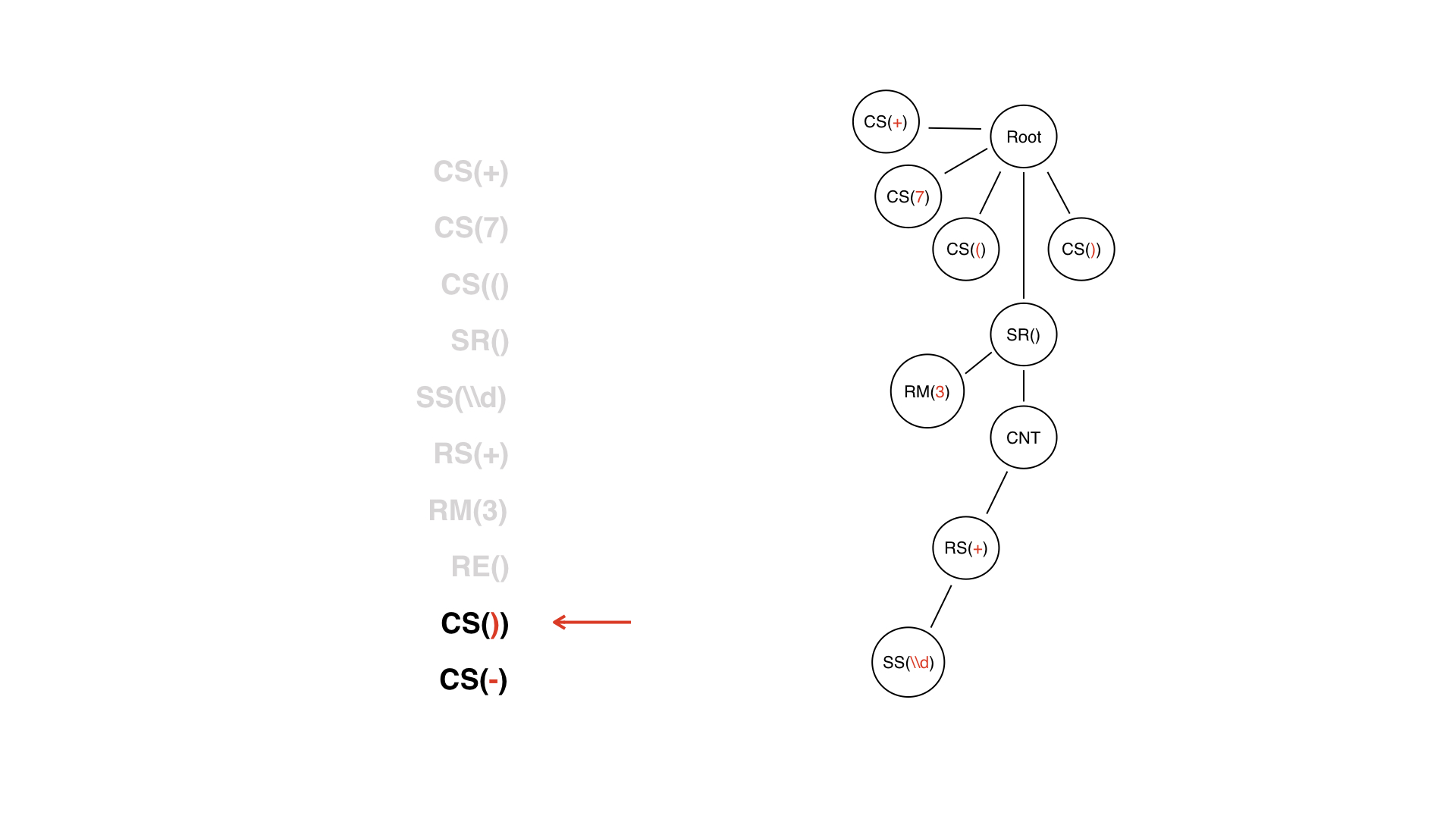
We already have a subtree, the root of which is the SR node - that is, the very dynamic part. The LW end token helps us a lot in the process of tree building - we can understand when the subtree for LW is finished. But this token has no value for logic: looking at a row-by-row tree, we already understand when the DW will end, because it is, as it were, closed by the SR node.
Further - just ordinary constant symbols.

We got a tree. Now let's go through this tree in depth and build on its basis some other grammar: you need to go into a node, see what kind of node it is, and generate an element of another grammar from this node.
Syntax of the InputMask library by Redmadrobot
Let's look at the syntax of the Redmadrobot library.

Here is the same expression. +7 is a constant that will be added automatically. Inside the curly braces, the DV is described - the dynamic part. Inside the DV there is a special character d. Redmadrobot has this default notation that denotes a digit.
This is what the notation looks like:

The notation consists of three parts:
- character is the character we will use to write the mask. What the mask alphabet consists of. For example, d.
- characterSet - which characters typed by the user are matched by this notation. For example, 0, 1, 2, 3, 4, and so on.
- isOptional - whether the user must enter one of the characterSet characters or not enter anything.
Look, we will now have such a mask.

- The "b" character has a special digit notation and is not optional.
- Character "c" has a different notation - CharacterSet is different. It is also not optional.
- And character "C" is the same as "c", only it is optional. This is necessary so that in the mask we look at the metadata and see that there is not a hard limit, but a weak one.
If you need to write a rule when there can be from one to ten characters, then one character will not be optional. And nine characters will be optional. That is, in the notation from the example, they will be written in capital letters. As a result, this rule will look like this: [cCCCCCCCCC]
Example: translating the phone number mask from the backend format to the InputMask format
Here is the tree we got in the last step. We need to walk on it. The first thing we get to is the root.

Further from the root, we find ourselves in the constant symbol + - we immediately generate +. On the right, a mask is written in the InputMask format.

The next character is understandable - just 7, followed by an open parenthesis.
Then a piece of the dynamic part is generated, but it is not yet filled.

We go inside, we have content, this is a technical node. We do not write anything anywhere.

Here we have a repeater, we also do not write anything anywhere, because there is no such symbol in the mask. Such a rule cannot be written down.

Finally, we come to some kind of content symbol.
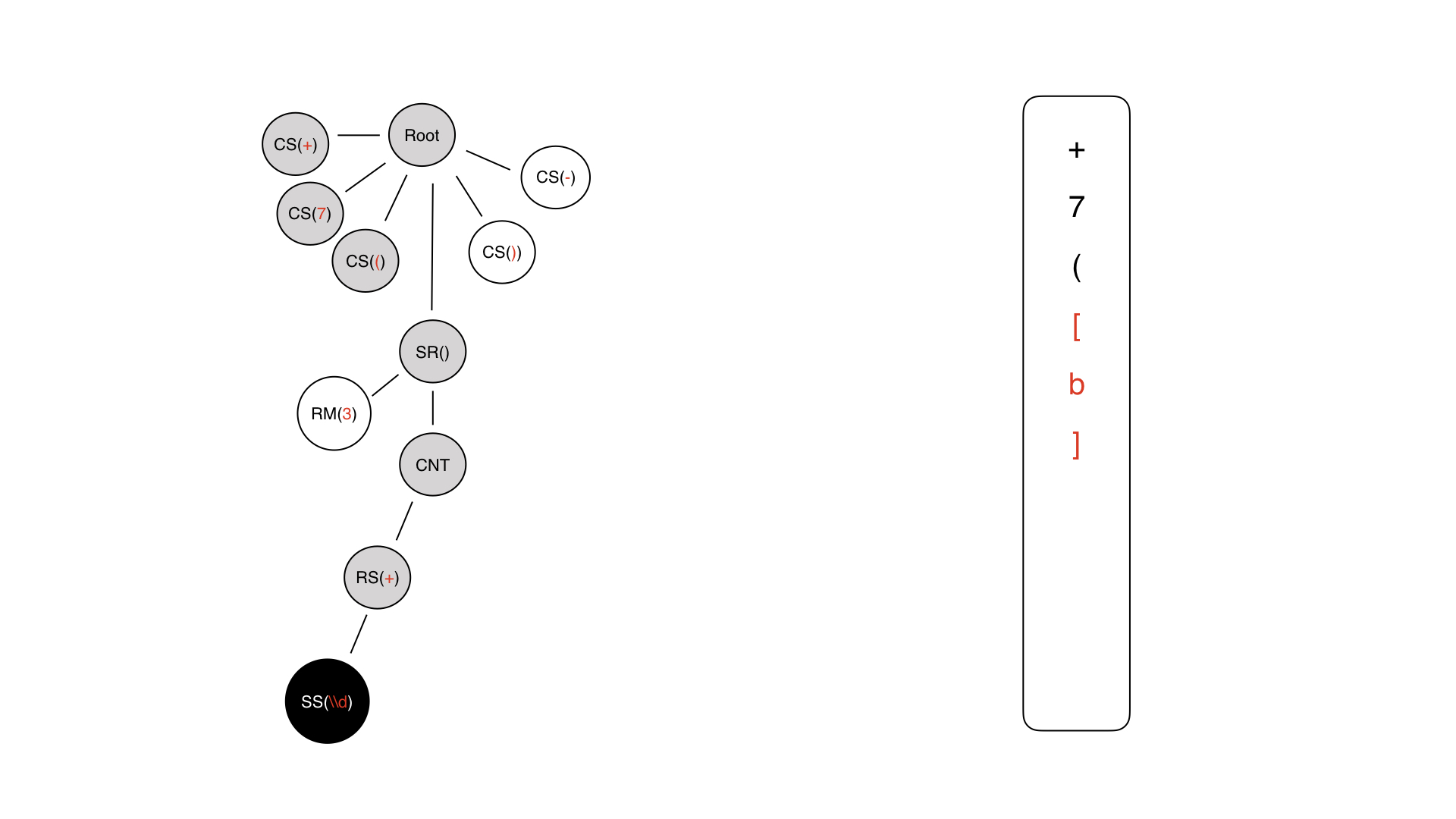
The content symbol can be either a constant symbol or a special symbol. In this case, a special one is used, because only it carries some kind of semantic load for input.
So we wrote it, we come back and go just for the meta information.

Let's see that we had a repeater there and here we have 3 - a hard limit. Therefore, we repeat it three times and get such a dynamic piece. Then we add our constant symbols.

As a result, we get a mask that looks like a mask in the robot format.
In practice, we took one grammar and generated another grammar from it.
Rules for generating client-side grammar from the server-side
Now a little about the generation rules. It is important.
There may be such difficult cases: inside the dynamic part there are several different pieces of DW. Inside curly braces: this is the same as in DV, one of many. Let's see how the interpreter will handle this situation.

First comes the character set, and we have to convert it to some kind of notation in terms of InputMask. Why? Because this is some kind of limited set of characters that we need to match. We need to combine user input and character, and therefore we will have some specific notation written here.
Next we have the \\ d character.
Next - DV with an optional size.

The first, it turns out, is some character b. It will have a Character Set containing abcd.
Further, it is clear that there will be a different symbol already, because you will not patch it differently, or you will patch it incorrectly. And then we have this expression turns into something like this.
The last part must contain at least one symbol. Let's designate this requirement as d. But also the user can enter two additional characters, and then they are designated as DD.
Putting it all together.

Here's an example of the Character Sets that are generated. It can be seen that b corresponds to the Character Set abcd, for digits - the corresponding preset Character Set. For d and D, the corresponding Character Set contains 12vf.
Outcome
We have learned to automatically convert one grammar to another: now masks according to the server specification work in our application.
Another feature that we got for free is the ability to perform static analysis of the mask that came to us. That is, we can understand what type of keyboard is needed for this mask and what the maximum number of characters can be in this mask. And it's even cooler, because now we do not show the same keyboard all the time for each form element - we show the required keyboard under the required form element. And also we can conditionally define exactly that some field is a phone input field.
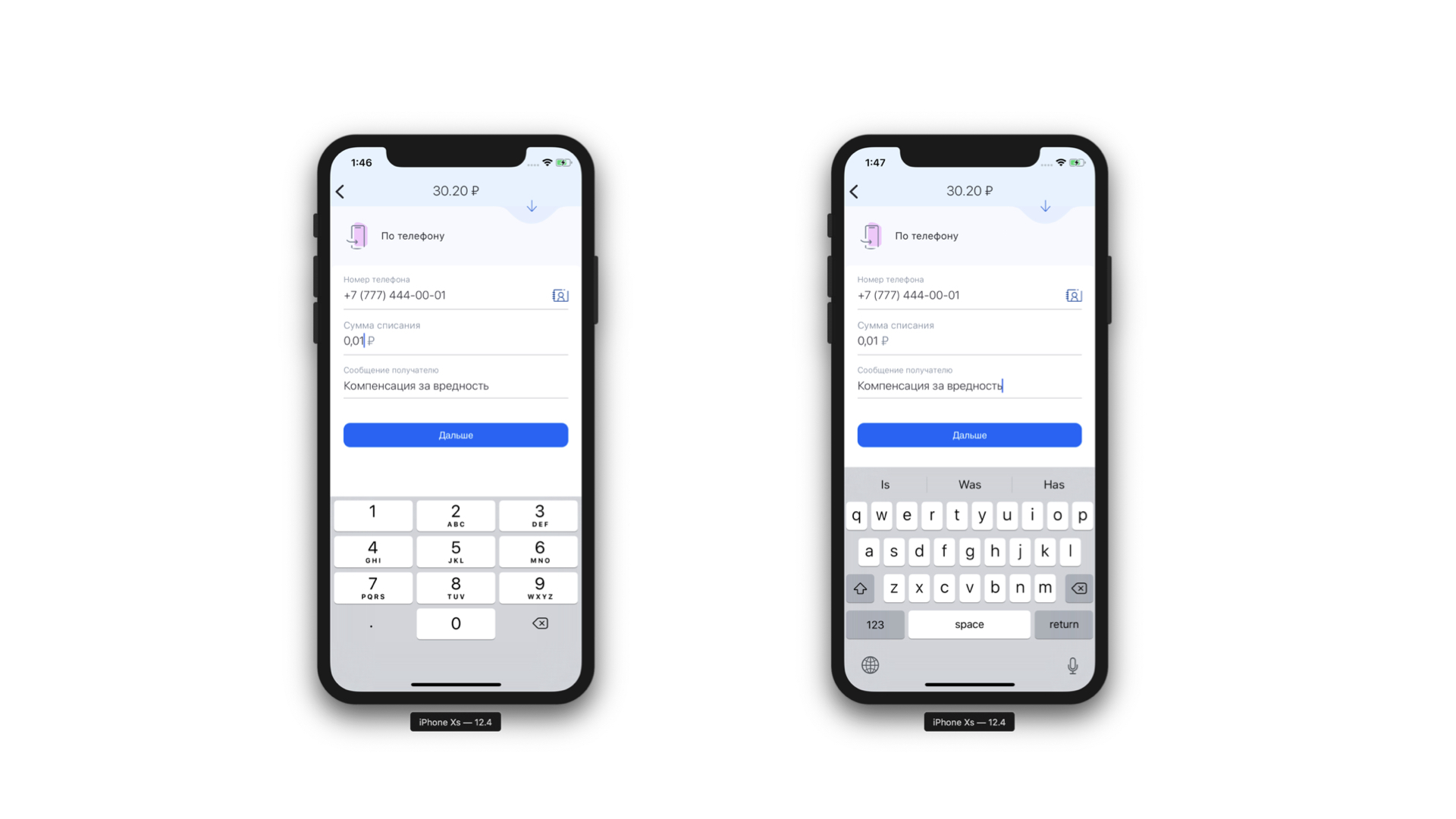
Left: at the top of the phone input field there is an icon (actually a button) that will send the user to the contact list. Right: Example of a keyboard for a regular text message.
Working library for translating masks
You can take a look at how we implemented the above approach. The library is located on Github .
Examples of translating different masks
This is the first mask we looked at at the very beginning. It is interpreted into this RedMadRobot representation.

And this is the second mask - just an input mask for something. It is converted to such a representation.
