Introduction
This article is a compilation of another article . In it, I intend to concentrate on tools for working with Big data focused on data analysis.
So, let's say you accepted the raw data, processed it, and now it's ready for further use.
There are many tools used to manipulate data, each with their own advantages and disadvantages. Most of them are OLAP oriented, but some are also OLTP optimized. Some of them use standard formats and focus only on the execution of queries, others use their own format or storage to transfer the processed data to the source in order to improve performance. Some are optimized for storing data using certain schemas, such as star or snowflake, but others are more flexible. Summing up, we have the following oppositions:
- Data Warehouse vs. Lake
- Hadoop vs. Offline Storage
- OLAP vs OLTP
- Query engine versus OLAP mechanisms
We will also look at tools for processing data with query capabilities.
Data processing tools
Most of the tools mentioned can connect to a metadata server like Hive and run queries, create views, etc. This is often used to create additional (improved) reporting levels.
Spark SQL provides a way to seamlessly mix SQL queries with Spark programs, so you can mix the DataFrame API with SQL. It has Hive integration and a standard JDBC or ODBC connection, so you can connect Tableau, Looker, or any BI tool to your data through Spark.

Apache Flinkalso provides SQL API. Flink's SQL support is based on Apache Calcite, which implements the SQL standard. It also integrates with Hive via HiveCatalog. For example, users can store their Kafka or ElasticSearch tables in the Hive Metastore using the HiveCatalog and reuse them later in SQL queries.
Kafka also provides SQL capabilities. In general, most data processing tools provide SQL interfaces.
Query Tools
This type of tool is focused on a unified query to different data sources in different formats. The idea is to route queries to your data lake using SQL as if it were a regular relational database, although it has some limitations. Some of these tools can also query NoSQL databases and much more. These tools provide a JDBC interface to external tools like Tableau or Looker to securely connect to your data lake. Query tools are the slowest option, but provide the most flexibility.
Apache Pig: one of the first tools alongside Hive. Has its own language other than SQL. A distinctive feature of the programs created by Pig is that their structure lends itself to significant parallelization, which, in turn, allows them to process very large data sets. Because of this, it is still not outdated compared to modern SQL-based systems.
Presto: An open source platform from Facebook. It is a distributed SQL query engine for performing interactive analytic queries against data sources of any size. Presto allows you to query data wherever it is, including Hive, Cassandra, relational databases, and file systems. It can query large datasets in seconds. Presto is independent of Hadoop, but integrates with most of its tools, especially Hive, to execute SQL queries.
Apache Drill: Provides a schema-free SQL query engine for Hadoop, NoSQL, and even cloud storage. It doesn't depend on Hadoop, but it has many integrations with ecosystem tools like Hive. A single query can combine data from multiple stores, performing optimizations specific to each of them. This is very good because allows analysts to treat any data as a table, even if they are actually reading the file. Drill fully supports standard SQL. Business users, analysts, and data scientists can use standard business intelligence tools such as Tableau, Qlik, and Excel to interact with non-relational data stores using Drill JDBC and ODBC drivers. Besides,developers can use the simple REST API Drill in their custom applications to create beautiful visualizations.
OLTP databases
Although Hadoop is optimized for OLAP, there are still situations where you want to run OLTP queries against an interactive application.
HBase has very limited ACID properties by design as it was built to scale and does not provide ACID capabilities out of the box, but it can be used for some OLTP scenarios.
Apache Phoenix is built on top of HBase and provides a way to make OTLP queries across the Hadoop ecosystem. Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce. It can also store metadata, support table creation and incremental versioning changes using DDL commands. It works quite fast, faster than using Drill or other
mechanism of requests.
You can use any large scale database outside of the Hadoop ecosystem like Cassandra, YugaByteDB, ScyllaDB for OTLP.
Finally, it is very common that fast databases of any type, such as MongoDB or MySQL, have a slower subset of data, usually the most recent. The query engines mentioned above can combine data between slow and fast storage in a single query.
Distributed Indexing
These tools provide ways to store and retrieve unstructured text data, and they live outside the Hadoop ecosystem as they require specialized structures to store the data. The idea is to use an inverted index to do fast searches. In addition to text search, this technology can be used for a variety of purposes, such as storing logs, events, etc. There are two main options:
Solr: It is a popular, very fast open source enterprise search platform built on Apache Lucene. Solr is a robust, scalable, and resilient tool, providing distributed indexing, load-balanced replication and queries, automatic failover and recovery, centralized provisioning, and more. It's great for text search, but its use cases are limited compared to ElasticSearch.
ElasticSearch: It is also a very popular distributed index, but has grown into an ecosystem of its own that spans many use cases such as APM, search, text storage, analytics, dashboards, machine learning, and more. It is definitely a tool to have in your toolbox for either DevOps or a data pipeline as it is very versatile. It can also store and search videos and images.
ElasticSearchcan be used as a fast storage layer for your data lake for advanced search functionality. If you are storing your data in a large key-value database like HBase or Cassandra, which provide very limited search capabilities due to lack of connections, you can put ElasticSearch in front of them to run queries, return IDs, and then perform a quick search in your database.
It can also be used for analytics. You can export your data, index it and then query it using KibanaBy creating dashboards, reports and more, you can add histograms, complex aggregations, and even run machine learning algorithms on top of your data. The ElasticSearch ecosystem is huge and well worth exploring.
OLAP databases
Here we look at databases that can also provide a metadata store for query schemas. Compared to query execution systems, these tools also provide data storage and can be applied to specific storage schemes (star schema). These tools use SQL syntax. Spark or other platforms can interact with them.
Apache hive: We've already discussed Hive as a central schema repository for Spark and other tools so they can use SQL, but Hive can store data as well, so you can use it as a repository. He can access HDFS or HBase. When requested by Hive, it uses Apache Tez, Apache Spark or MapReduce, being much faster than Tez or Spark. It also has a procedural language called HPL-SQL. Hive is an extremely popular meta data store for Spark SQL.
Apache Impala: It is a native analytic database for Hadoop that you can use to store data and efficiently query it. She can connect to Hive to get metadata using Hcatalog. Impala provides low latency and high concurrency for business intelligence and analytics queries in Hadoop (which is not provided by packaged platforms such as Apache Hive). Impala also scales linearly, even in multi-user environments, which is a better query alternative than Hive. Impala is integrated with proprietary Hadoop and Kerberos security for authentication, so you can securely manage data access. It uses HBase and HDFS for data storage.

Apache Tajo: This is another data warehouse for Hadoop. Tajo is designed to run ad-hoc queries with low latency and scalability, online aggregation and ETL for large datasets stored in HDFS and other data sources. It supports integration with the Hive Metastore to access common schemas. It also has many query optimizations, it is scalable, fault-tolerant, and provides a JDBC interface.
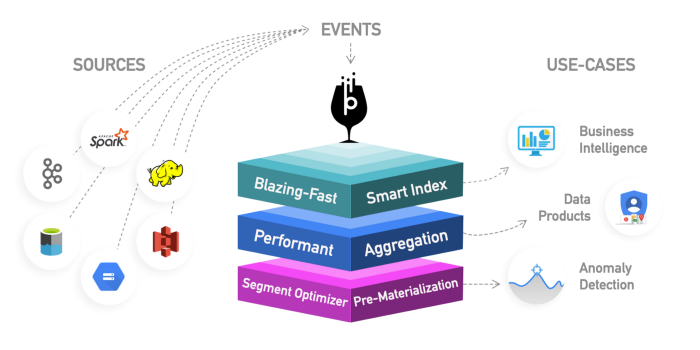
Apache Kylin: This is a new distributed analytical data warehouse. Kylin is extremely fast, so it can be used to complement some other databases like Hive for use cases where performance is critical, such as dashboards or interactive reports. This is probably the best OLAP data warehouse, but difficult to use. Another problem is that more storage space is required due to the high stretch. The idea is that if the query engines or Hive are not fast enough, you can create a "Cube" in Kylin, which is an OLAP-optimized multidimensional table with pre-computed
values that you can query from dashboards or interactive reports. It can create cubes directly from Spark and even near real-time from Kafka.
OLAP tools
In this category, I include newer engines, which are evolutions of previous OLAP databases, that provide more functionality, creating a comprehensive analytics platform. In fact, they are a hybrid of the two previous categories that add indexing to your OLAP databases. They live outside of the Hadoop platform but are tightly integrated. In this case, you usually skip the processing step and use these tools directly.
They try to solve the problem of querying real-time data and historical data in a uniform way, so you can immediately query real-time data as soon as it becomes available, along with low-latency historical data so you can build interactive applications and dashboards. These tools allow, in many cases, to query raw data with little or no ELT-style transformation, but with high performance, better than conventional OLAP databases.
What they have in common is that they provide a unified view of data, live and batch data ingestion, distributed indexing, native data format, SQL support, JDBC interface, hot and cold data support, multiple integrations, and metadata storage.
Apache Druid: This is the most famous real-time OLAP engine. It is focused on time series data, but can be used for any data. It uses its own columnar format that can compress data a lot, and it has many built-in optimizations such as inverted indices, text encoding, auto-collapsing data, and more. Data is loaded in real time using Tranquility or Kafka, which have very low latency, is stored in memory in a write-optimized string format, but as soon as it arrives, it becomes available for querying, just like the previous downloaded data. The background process is responsible for moving data asynchronously to a deep storage system such as HDFS. When data is moved into deep storage, it is split into smaller chunks,time segregated, called segments, which are well optimized for low latency queries. This segment has a time stamp for several dimensions that you can use to filter and aggregate, and metrics, which are pre-computed states. In burst reception, data is saved directly into segments. Apache Druid supports push and pull swallowing, integration with Hive, Spark, and even NiFi. It can use the Hive metadata store and supports Hive SQL queries, which are then translated into JSON queries used by Druid. The Hive integration supports JDBC, so you can plug in any BI tool. It also has its own metadata repository, usually MySQL is used for this.It can accept huge amounts of data and scales very well. The main problem is that it has many components and is difficult to manage and deploy.
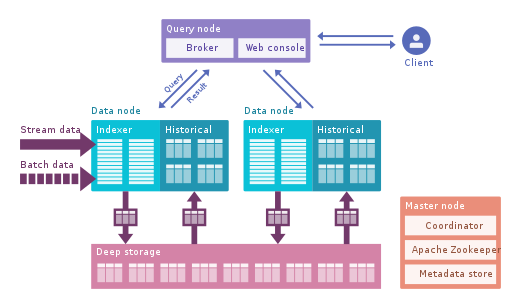
Apache Pinot : This is a newer open source Druid alternative from LinkedIn. Compared to Druid, it offers lower latency thanks to the Startree index, which does partial pre-computation, so it can be used for user-centric applications (it was used to get LinkedIn feeds). It uses a sorted index instead of an inverted one, which is faster. It has an extensible plugin architecture and also has a lot of integrations, but does not support Hive. It also integrates batch and real-time processing, provides fast loading, smart index, and stores data in segments. It is easier and faster to deploy compared to Druid, but looks a little immature at the moment.
ClickHouse: written in C ++, this engine provides incredible performance for OLAP queries, especially for aggregates. It's like a relational database, so you can model the data easily. It is very easy to set up and has many integrations.
Read this article which compares the 3 engines in detail.
Start small by examining your data before making a decision. These new mechanisms are very powerful, but difficult to use. If you can wait for hours, use batch processing and a database like Hive or Tajo; then use Kylin to speed up OLAP queries and make them more interactive. If that's not enough and you need even less latency and real-time data, consider OLAP engines. Druid is more suited for real-time analysis. Kaileen is more focused on OLAP cases. Druid has good integration with Kafka as live streaming. Kylin is receiving data from Hive or Kafka in batches, although live reception is planned.
Finally, Greenplum Is another OLAP engine, more focused on artificial intelligence.
Data visualization
There are several commercial tools for visualization such as Qlik, Looker, or Tableau.
If you prefer Open Source, look towards SuperSet. It is a great tool that supports all the tools we mentioned, has a great editor and is really fast, it uses SQLAlchemy to provide support for many databases.
Other interesting tools are Metabase or Falcon .
Conclusion
There are a wide variety of tools that can be used to manipulate data, from flexible query engines like Presto to high-performance storage like Kylin. There is no one-size-fits-all solution, I advise you to study the available data and start small. Query engines are a good starting point because of their flexibility. Then, for different use cases, you may need to add additional tools to achieve the service level you want.
Pay special attention to new tools like Druid or Pinot, which provide an easy way to analyze huge amounts of data with very low latency, bridging the gap between OLTP and OLAP in terms of performance. You might be tempted to think about processing, pre-calculating aggregates, and the like, but consider these tools if you want to simplify your work.