
Hello!
My name is Nikita, and I oversee the development of several projects at DomClick. Today I want to continue the theme of "funny pictures" in the RabbitMQ world. In his article, Alexey Kazakov considered such a powerful tool as deferred queues and different implementations of the Retry strategy. Today we'll talk about how to use RabbitMQ to schedule periodic tasks.
Why did we need to create our own bike and why did we abandon Celery and other task management tools? The fact is that they did not fit our tasks and requirements for fault tolerance, which are quite strict in our company.
When switching to Docker and Kubernetes, many developers are faced with the problems of organizing periodic tasks, crowns are launched with a tambourine, and the control of the process leaves much to be desired. And then there are problems with peak loads during the daytime.
My task was to implement in the project a reliable system for processing periodic tasks, while easily scalable and fault-tolerant. Our project is in Python, so it was logical to see how Celery suits us. This is a good tool, but with it we have often encountered reliability, scalability, and seamless release issues. One pod - one process group. When scaling Celery, you have to increase the resources of one pod, because there is no synchronization between pods, which means stopping the processing of tasks, albeit temporarily. And if the tasks are also long-term, then you already guessed how difficult it is to manage. The second obvious drawback: out of the box there is no support for asynchrony, and for us this is important, because tasks mainly contain I / O operations, and Celery runs on threads.
At that time (2018), we did not find a suitable ready-made tool, and began to develop our own. Taking as a basis the functionality of deferred execution of tasks and the Dead Letter Exchange, we decided to create a system for processing periodic tasks. The concept looked something like this:
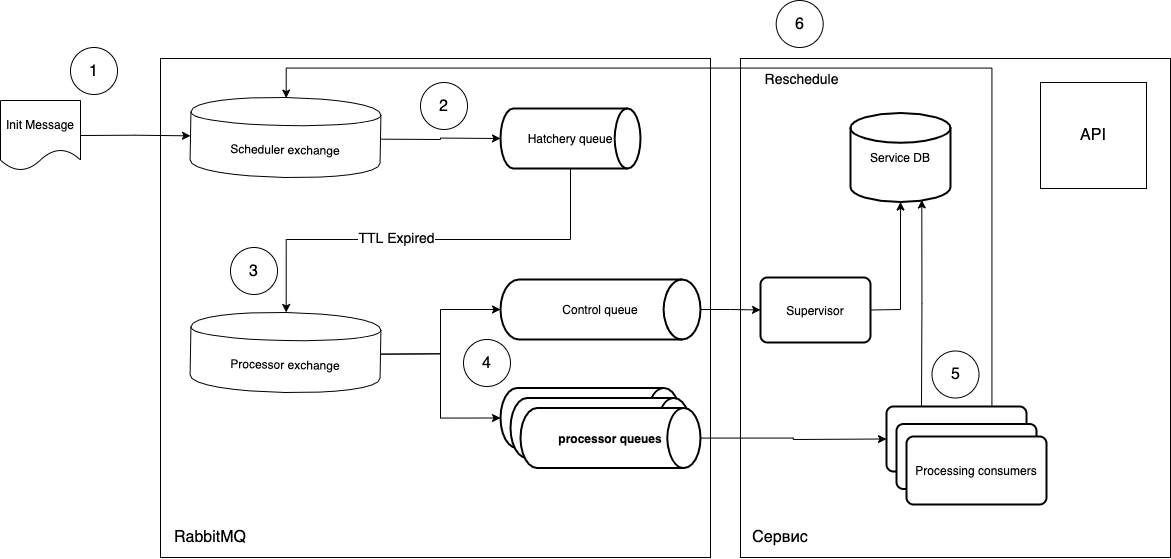
I'll try to explain what's what.
- Tasks are sent in the form of a message to the Scheduler exchange.
- The
routing_keysoftware gets into the required Hatchery queue, which has a parametermessage_ttl, as well as the connection with the Processor exchange as a deal letter exchange. The "maturing" queue is not associated with the type of tasks, it only plays the role of a "timer", that is, you can create as many queues as you need periods and manage throughrouting_key. - Since the queue has no listeners, the messages after "maturing" in the queue go to the Processor exchange.
- Then the free consumer (Processing consumer) picks up the message and executes. After execution, the cycle is repeated if necessary.
What is the advantage of such a scheme?
- Phased execution, that is, a new task will not be processed if the previous one has not completed.
- A single listener (consumer), that is, you can create both universal workers and specialized ones. Scaled by simply increasing the number of pods needed.
- Deploy new tasks without disrupting the work of the current ones. It is enough to softly update the listener pods and send the appropriate message to the queue. That is, you can raise pods with a new code, which will deal with new messages, and the current processes will live on in the old pods. This gives us a seamless update.
- You can use asynchronous code and any infrastructure, while being stack independent.
- You can control the execution of tasks at the native
ack/ levelreject, and also get an additional optional queue (control queue) that can track the life cycle of tasks.
The circuit turned out to be actually quite simple, we quickly created a working prototype. And the code is beautiful. It is enough to mark the callback function with a simple decorator that controls the message lifecycle.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Now we use this scheme to perform only periodic sequential tasks, but it can also be used when it is important to start executing a task at a specific time, without shifting the time to the execution itself. To do this, it is enough to reschedule the task after the message hits the supervisor.
True, this approach has additional overhead costs. You need to understand that in case of an error, the message will return to the queue, another worker will pick it up and immediately start executing it. Therefore, you need to separate error handling according to the degree of criticality and think in advance about what to do with the message in case of this or that error.
Possible options:
- The error will fix itself (for example, it is a system error): send
noackand repeat error handling. - Business logic error: you need to interrupt the cycle - send
ack. - The mistake from point 1 is repeated too often: we poison
rejectand signal the developers. There are options here. You can create a deal letter queue for the messages to be deposited in order to return the message after parsing, or you can use the retry technique (specifymessage_ttl).
Decorator example:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
This scheme has been working for us for half a year, it is quite reliable and practically does not require attention. The application crash does not break the scheduler and only slightly delays the execution of tasks.
There are no pluses without minuses. This scheme also has a critical vulnerability. If something happened to RabbitMQ and the messages disappeared, then you need to manually look at what was lost and start the loop again. But this is an extremely unlikely situation in which you will have to think about this service last :)
PS If the topic of scheduling periodic tasks seems interesting to you, then in the next article, I will tell you in more detail how we automate queue creation, as well as about Supervisor.
Links: