https://www.youtube.com/playlist?list=PLwr8DnSlIMg0KABru36pg4CvbfkhBofAi
Somehow on Habré I came across a rather curious article "Scientific and technical myths, part 1. Why do planes fly?" ... The article describes in some detail what problems arise when trying to explain the lift of the wings in terms of Bernoulli's law or Newtonian lift model . And although the article offers other explanations, I would still like to dwell on Newton's model in more detail. Yes, Newton's model is not complete and has assumptions, but it gives a more accurate and intuitive description of phenomena than Bernoulli's law.
— . - , , .
, . ? GitHub.
Computational Fluid Dynamics
, (Computational fluid dynamics, CFD), -.
, , 7- . 38 (“”), 40 (“ ‘’ ”) 41 (“ ‘’ ”). , - — . (, ) . , , .
: . . .
— . , SpaceX . , , , . . , . , (Smoothed-particle hydrodynamics, SPH). : , , , . . , . , , (screen-space meshes, dual contouring, marching tetrahedra, metaballs). , .
Discrete Element Method
, .
(Discrete Element Method, DEM) , . , , , .
, ( X Y), . , . . — NASA . , STS-1 . Mission Anomalies.
DEM — (Discrete Collision Detection). .
Continuous Collision Detection (CCD), , . , , . . CCD , « ». , Unity Unreal .
Continuous Collision Detection
CCD . — . . — , , , . , “ ”
, DEM.
, , , , . , . , . .
National Geographic. , . , , .

( National Geographic)
. — . — . . .
https://youtu.be/cx8XbaQNnxw?t=2206
, . , . (heatmap) ( ) ( ) . .
.
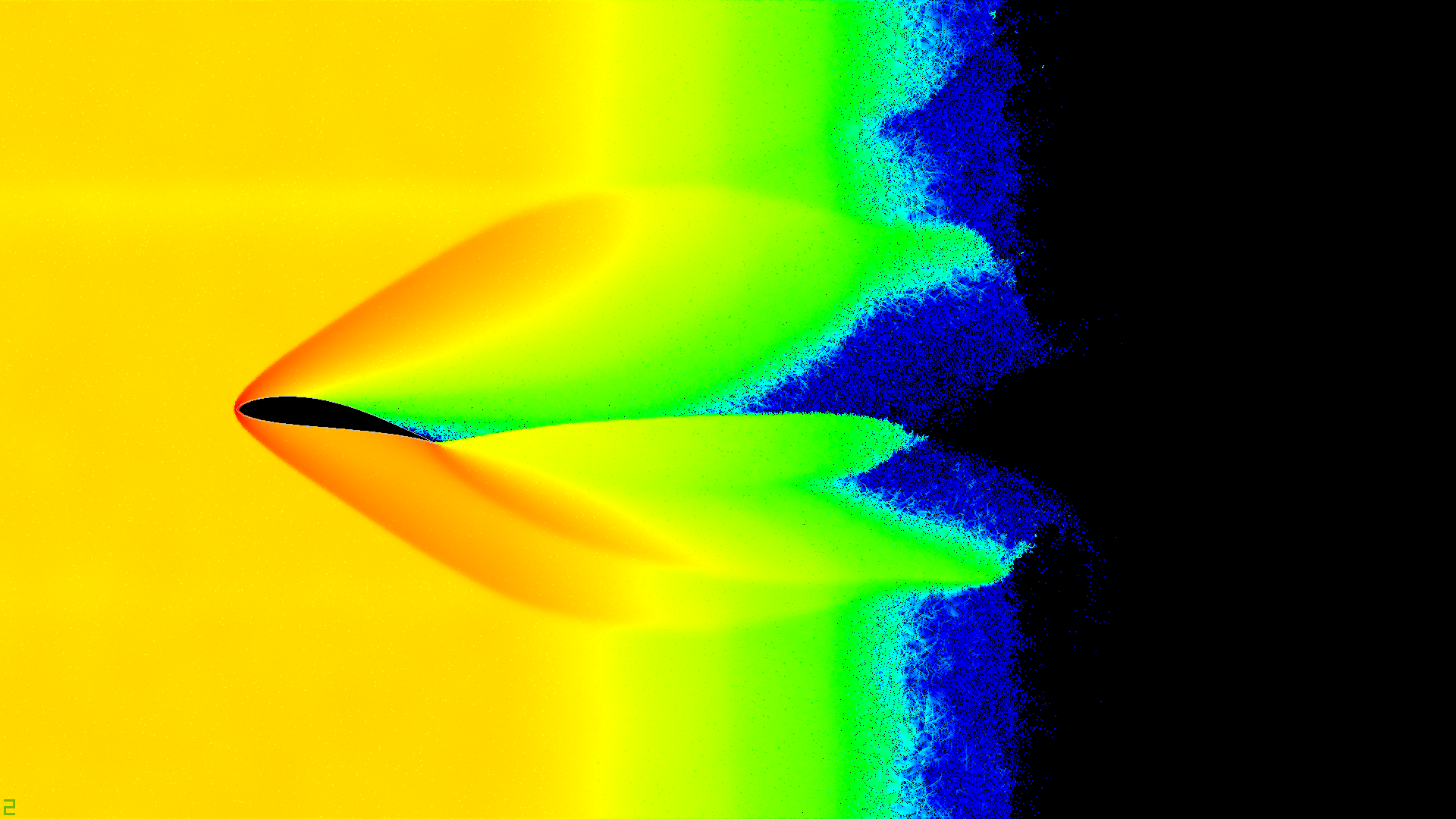
( )

,
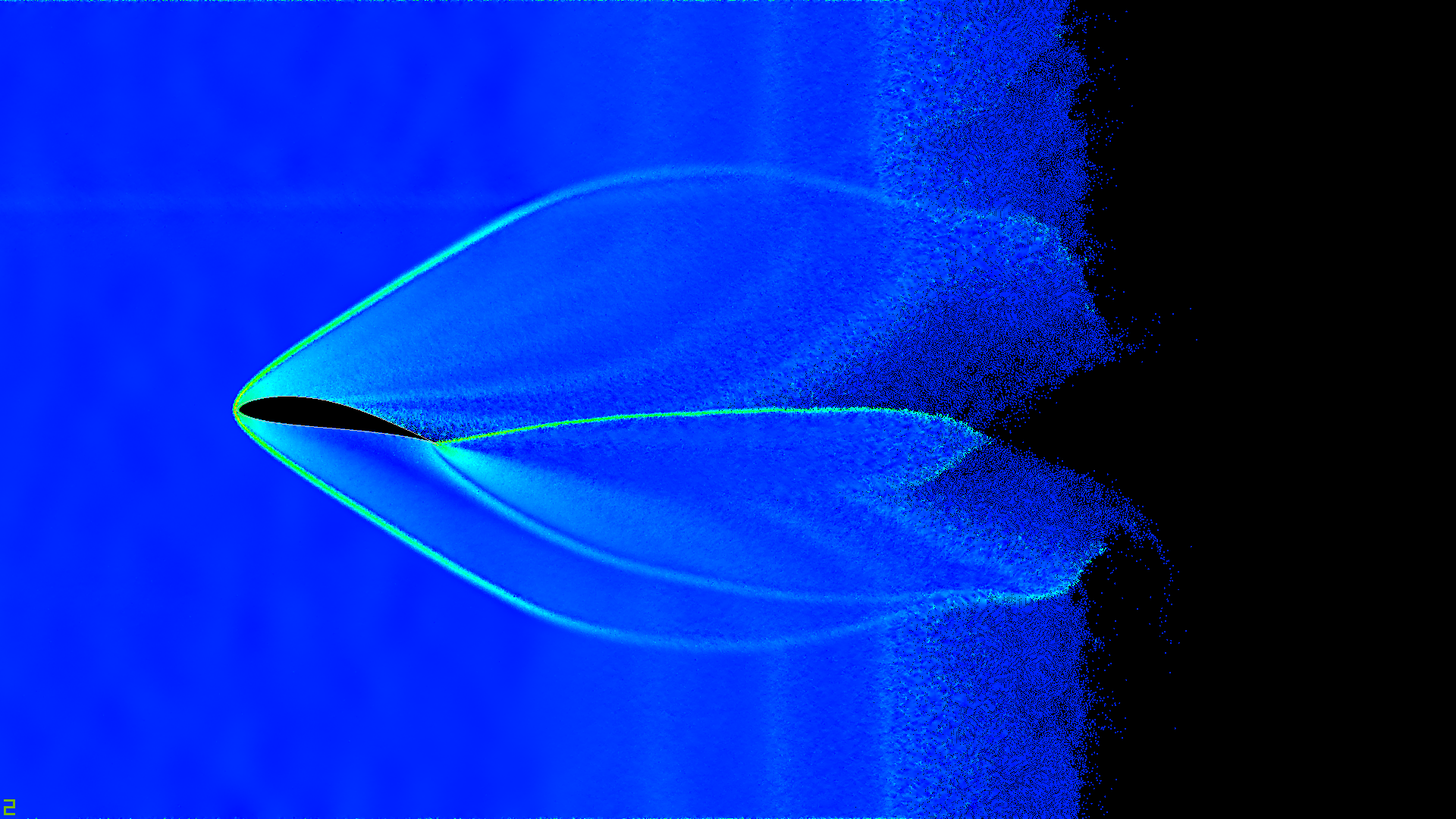
, . :
- .
- CPU CUDA.
. . CUDA- , , 16 .
. , , , , , .., . . .
, . (Ordinary Differential Equation, ODE). , — , — , . , .
, f, — .
'Differential Equation Basics' and 'Particle Dynamics' https://www.cs.cmu.edu/~baraff/sigcourse/
3Blue1Brown : 
https://www.youtube.com/playlist?list=PLZHQObOWTQDNPOjrT6KVlfJuKtYTftqH6
, — (Forward Euler). - 4- (RK4), , . RK4 , , . , , - . , , 'Differential Equation Basics' lecture notes, section 3, 'Adaptive Stepsizes'.
, , . , . .
float CSimulationCpu::ComputeMinDeltaTime(float requestedDt) const
{
auto rad = m_state.particleRad;
auto velBegin = m_curOdeState.cbegin() + m_state.particles;
auto velEnd = m_curOdeState.cend();
return std::transform_reduce(std::execution::par_unseq, velBegin, velEnd, requestedDt, [](const auto t1, const auto t2)
{
return std::min(t1, t2);
}, [&](const auto& v)
{
auto vel = glm::length(v);
auto radDt = rad / vel;
return radDt;
});
}
float CSimulationCpu::Update(float dt)
{
dt = ComputeMinDeltaTime(dt);
m_odeSolver->NextState(m_curOdeState, dt, m_nextOdeState);
ColorParticles(dt);
m_nextOdeState.swap(m_curOdeState);
return dt;
}— f, “ ”. CPU CUDA . , CPU , . CUDA , . . “ ”.
//CPU-
void CDerivativeSolver::Derive(const OdeState_t& curState, OdeState_t& outDerivative)
{
ResetForces();
BuildParticlesTree(curState);
ResolveParticleParticleCollisions(curState);
ResolveParticleWingCollisions(curState);
ParticleToWall(curState);
ApplyGravity();
BuildDerivative(curState, outDerivative);
}
//CUDA-
void CDerivativeSolver::Derive(const OdeState_t& curState, OdeState_t& outDerivative)
{
BuildParticlesTree(curState);
ReorderParticles(curState);
ResetParticlesState();
ResolveParticleParticleCollisions();
ResolveParticleWingCollisions();
ParticleToWall();
ApplyGravity();
BuildDerivative(curState, outDerivative);
}, , , — . 2’097’152 . - . , . — .
— Uniform Grid, . GPU “Chapter 32. Broad-Phase Collision Detection with CUDA”.

( Tero Karras, NVIDIA Corporation)
, . 9 (3x3) 27 (3x3x3) 2D 3D . — . , , RCU lock-free . Nvidia , malloc()/free() device , .
CppCon 2017: Fedor Pikus “Read, Copy, Update, then what? RCU for non-kernel programmers”
, :
- .
- RAM/VRAM, -, .
- , .
- .
- GPU, lock-free (https://youtu.be/86seb-iZCnI?t=2311, ).
, — BVH- Z-. , .
— Z-, .

Z- ( Wikipedia)

—
( Wikipedia)
, space-filling curve, , . 2D/3D , , , , , . . , , , , , .
, . , . , Tero Karras Nvidia, .
“Maximizing Parallelism in the Construction of BVHs, Octrees, and k-d Trees”.
:
- : https://developer.nvidia.com/blog/thinking-parallel-part-ii-tree-traversal-gpu/
- : https://developer.nvidia.com/blog/thinking-parallel-part-iii-tree-construction-gpu/
, . N , bounding box , , ( Z-). .
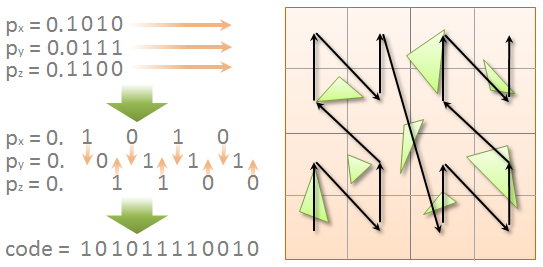
( Tero Karras, NVIDIA Corporation)
. , , , N N-1 . , . . , . , . .
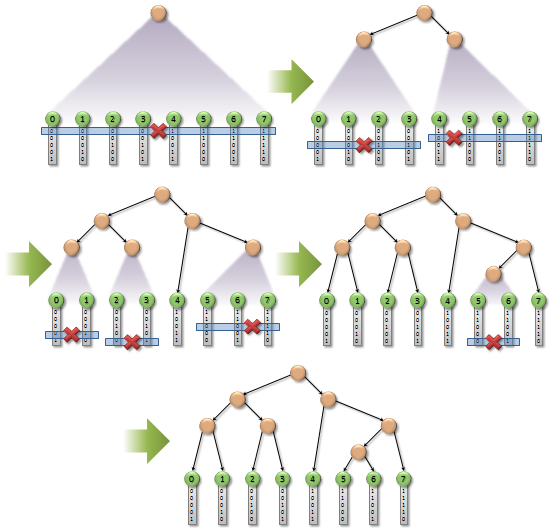
( Tero Karras, NVIDIA Corporation)
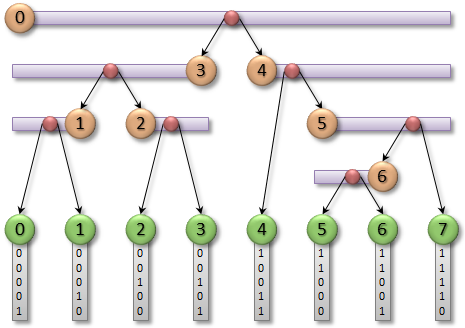
( Tero Karras, NVIDIA Corporation)
, , BVH-.

BVH- ( Tero Karras, NVIDIA Corporation)
N , , . , , , . atomicExch() 1. , . 0, . , , . . 1, , , .
.
“-” “- ”.
“-” , , “” , . Tero Karras. , A-B B-A , . . (rightmost leaf), . , rightmost(N2) = 4, rightmost(N3) = 8. , , , O6, , N2. rightmost, , O6 N2. O6 N2. , , N2, N3. , O6 , , N2.
:
template<typename TDeviceCollisionResponseSolver, size_t kTreeStackSize>
void CMortonTree::TraverseReflexive(const TDeviceCollisionResponseSolver& solver);“- ” :
template<typename TDeviceCollisionResponseSolver, size_t kTreeStackSize>
void CMortonTree::Traverse(const thrust::device_vector<SBoundingBox>& objects, const TDeviceCollisionResponseSolver& solver);TDeviceCollisionResponseSolver — , :
struct Solver
{
struct SDeviceSideSolver
{
...
__device__ SDeviceSideSolver(...);
__device__ void OnPreTraversal(TIndex curId);
__device__ void OnCollisionDetected(TIndex leafId);
__device__ void OnPostTraversal();
};
Solver(...);
__device__ SDeviceSideSolver Create();
}; , , . Create(). OnPreTraversal, . - , OnCollisionDetected . . OnPostTraversal.
. -. , Tero Karras. . NxO, N — , O — . , . . , (coalesced memory access). , . , .
struct SParticleParticleCollisionSolver
{
struct SDeviceSideSolver
{
CDerivativeSolver::SIntermediateSimState& simState;
TIndex curIdx;
float2 pos1;
float2 vel1;
float2 totalForce;
float totalPressure;
__device__ SDeviceSideSolver(CDerivativeSolver::SIntermediateSimState& state) : simState(state)
{
}
__device__ void OnPreTraversal(TIndex curLeafIdx)
{
curIdx = curLeafIdx;
pos1 = simState.pos[curLeafIdx];
vel1 = simState.vel[curLeafIdx];
totalForce = make_float2(0.0f);
totalPressure = 0.0f;
}
__device__ void OnCollisionDetected(TIndex anotherLeafIdx)
{
const auto pos2 = simState.pos[anotherLeafIdx];
const auto deltaPos = pos2 - pos1;
const auto distanceSq = dot(deltaPos, deltaPos);
if (distanceSq > simState.diameterSq || distanceSq < 1e-8f)
return;
const auto vel2 = simState.vel[anotherLeafIdx];
auto dist = sqrtf(distanceSq);
auto dir = deltaPos / dist;
auto springLen = simState.diameter - dist;
auto force = SpringDamper(dir, vel1, vel2, springLen);
auto pressure = length(force);
totalForce += force;
totalPressure += pressure;
atomicAdd(&simState.force[anotherLeafIdx].x, -force.x);
atomicAdd(&simState.force[anotherLeafIdx].y, -force.y);
atomicAdd(&simState.pressure[anotherLeafIdx], pressure);
}
__device__ void OnPostTraversal()
{
atomicAdd(&simState.force[curIdx].x, totalForce.x);
atomicAdd(&simState.force[curIdx].y, totalForce.y);
atomicAdd(&simState.pressure[curIdx], totalPressure);
}
};
CDerivativeSolver::SIntermediateSimState simState;
SParticleParticleCollisionSolver(const CDerivativeSolver::SIntermediateSimState& state) : simState(state)
{
}
__device__ SDeviceSideSolver Create()
{
return SDeviceSideSolver(simState);
}
};
void CDerivativeSolver::ResolveParticleParticleCollisions()
{
m_particlesTree.TraverseReflexive<SParticleParticleCollisionSolver, 24>(SParticleParticleCollisionSolver(m_particles.GetSimState()));
CudaCheckError();
}, , OnCollistionDetected . : - A, B, C D, Z , :
| lock-step # | Thread #1 | Thread #2 | Thread #3 |
|---|---|---|---|
| 1 | OnCollisionDetected
A <-> C |
OnCollisionDetected
B <-> C |
OnCollisionDetected
C <-> D |
| 2 | OnCollisionDetected
A <-> D |
OnCollisionDetected
B <-> D |
INACTIVE |
| 3 | OnPostTraversal(1) | OnPostTraversal(2) | OnPostTraversal(3) |
, 1 2 #1 #2 atomicAdd C D OnCollistionDetected. atomic .
Volta, Nvidia warp-vote . match_any warp, , .

match_any match_all
, warp shuffle .
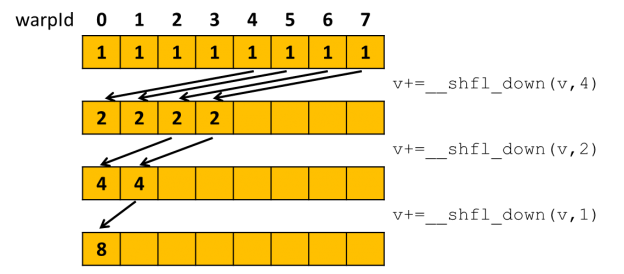
Warp-wide
, . SM . , Pascal (1080 Ti) , . , , . , atomic , Arithmetic Workload . Volta Turing . , RTX 2060 , atomic . “ ”.
, , .
SoA
Structure of Arrays — , .
. , , SoA:
typedef uint32_t TIndex;
struct STreeNodeSoA
{
const TIndex leafs;
int* __restrict__ atomicVisits;
TIndex* __restrict__ parents;
TIndex* __restrict__ lefts;
TIndex* __restrict__ rights;
TIndex* __restrict__ rightmosts;
SBoundingBox* __restrict__ boxes;
const uint32_t* __restrict__ sortedMortonCodes;
};:
struct SIntermediateSimState
{
const TIndex particles;
const float particleRad;
const float diameter;
const float diameterSq;
float2* __restrict__ pos;
float2* __restrict__ vel;
float2* __restrict__ force;
float* __restrict__ pressure;
}; , bounding box’ SoA , . Array of Structures (AoS):
struct SBoundingBox
{
float2 min;
float2 max;
};
struct SBoundingBoxesAoS
{
const size_t count;
SBoundingBox* __restrict__ boxes;
}; , , . , . . , uncoalesced memory access.
GPU. coalesced memory access, . , . SpaceX: https://youtu.be/vYA0f6R5KAI?t=1939 ( ).

( SpaceX)
50% : 8 FPS 12 FPS .
UPD: , 16 , 192 . , .
Shared Memory
, . , — . SM , uncoalesced. , Shared Memory Streaming Multiprocessor’.
__device__ void traverseIterative( CollisionList& list,
BVH& bvh,
AABB& queryAABB,
int queryObjectIdx)
{
// Allocate traversal stack from thread-local memory,
// and push NULL to indicate that there are no postponed nodes.
NodePtr stack[64]; //<----------------------------
NodePtr* stackPtr = stack;
*stackPtr++ = NULL; // push
// Traverse nodes starting from the root.
NodePtr node = bvh.getRoot();
do
{
// Check each child node for overlap.
NodePtr childL = bvh.getLeftChild(node);
NodePtr childR = bvh.getRightChild(node);
bool overlapL = ( checkOverlap(queryAABB,
bvh.getAABB(childL)) );
bool overlapR = ( checkOverlap(queryAABB,
bvh.getAABB(childR)) );
// Query overlaps a leaf node => report collision.
if (overlapL && bvh.isLeaf(childL))
list.add(queryObjectIdx, bvh.getObjectIdx(childL));
if (overlapR && bvh.isLeaf(childR))
list.add(queryObjectIdx, bvh.getObjectIdx(childR));
// Query overlaps an internal node => traverse.
bool traverseL = (overlapL && !bvh.isLeaf(childL));
bool traverseR = (overlapR && !bvh.isLeaf(childR));
if (!traverseL && !traverseR)
node = *--stackPtr; // pop
else
{
node = (traverseL) ? childL : childR;
if (traverseL && traverseR)
*stackPtr++ = childR; // push
}
}
while (node != NULL);
}template<typename TDeviceCollisionResponseSolver, size_t kTreeStackSize, size_t kWarpSize = 32>
__global__ void TraverseMortonTreeKernel(const CMortonTree::STreeNodeSoA treeInfo, const SBoundingBoxesAoS externalObjects, TDeviceCollisionResponseSolver solver)
{
const auto threadId = blockIdx.x * blockDim.x + threadIdx.x;
if (threadId >= externalObjects.count)
return;
const auto objectBox = externalObjects.boxes[threadId];
const auto internalCount = treeInfo.leafs - 1;
__shared__ TIndex stack[kTreeStackSize][kWarpSize]; //
unsigned top = 0;
stack[top][threadIdx.x] = 0;
auto deviceSideSolver = solver.Create();
deviceSideSolver.OnPreTraversal(threadId);
while (top < kTreeStackSize) //top == -1 also covered
{
auto cur = stack[top--][threadIdx.x];
if (!treeInfo.boxes[cur].Overlaps(objectBox))
continue;
if (cur < internalCount)
{
stack[++top][threadIdx.x] = treeInfo.lefts[cur];
if (top + 1 < kTreeStackSize)
stack[++top][threadIdx.x] = treeInfo.rights[cur];
else
printf("stack size exceeded\n");
continue;
}
deviceSideSolver.OnCollisionDetected(cur - internalCount);
}
deviceSideSolver.OnPostTraversal();
}Shared Memory 43%: 14 FPS 20 FPS. :
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#device-memory-accesses
, — 1080 Ti Pascal. , , . 20- . .

20- RTX . .
, , . . :
.
atomic- lock-free . , (Out-of-order execution), , . lock-free . , , , . -, , , C++ . std::memory_order.
__device__ void CMortonTree::STreeNodeSoA::BottomToTopInitialization(size_t leafId)
{
auto cur = leafs - 1 + leafId;
auto curBox = boxes[cur];
while (cur != 0)
{
auto parent = parents[cur];
//1. atomic
auto visited = atomicExch(&atomicVisits[parent], 1);
if (!visited)
return;
TIndex siblingIndex;
SBoundingBox siblingBox;
TIndex rightmostIndex;
TIndex rightmostChild;
auto leftParentChild = lefts[parent];
if (leftParentChild == cur)
{
auto rightParentChild = rights[parent];
siblingIndex = rightParentChild;
rightmostIndex = rightParentChild;
}
else
{
siblingIndex = leftParentChild;
rightmostIndex = cur;
}
siblingBox = boxes[siblingIndex];
rightmostChild = rightmosts[rightmostIndex];
SBoundingBox parentBox = SBoundingBox::ExpandBox(curBox, siblingBox);
boxes[parent] = parentBox;
rightmosts[parent] = rightmostChild;
cur = parent;
curBox = parentBox;
//2. .
//
__threadfence();
}
}, , BVH , . , . , SIMT ( Volta SIMT Model Starvation-Free Algorithms) Nvidia Volta Out-of-order execution. , , atomicExch(), .. , Turing . , , , , . data race.
thrust::device_vector
, thurst::device_vector . resize() GPU cudaDeviceSynchronize(). , . , . , , . — . — (reduce, sum, min, max) , . Cuda UnBound (CUB) . , thrust , .
, , .
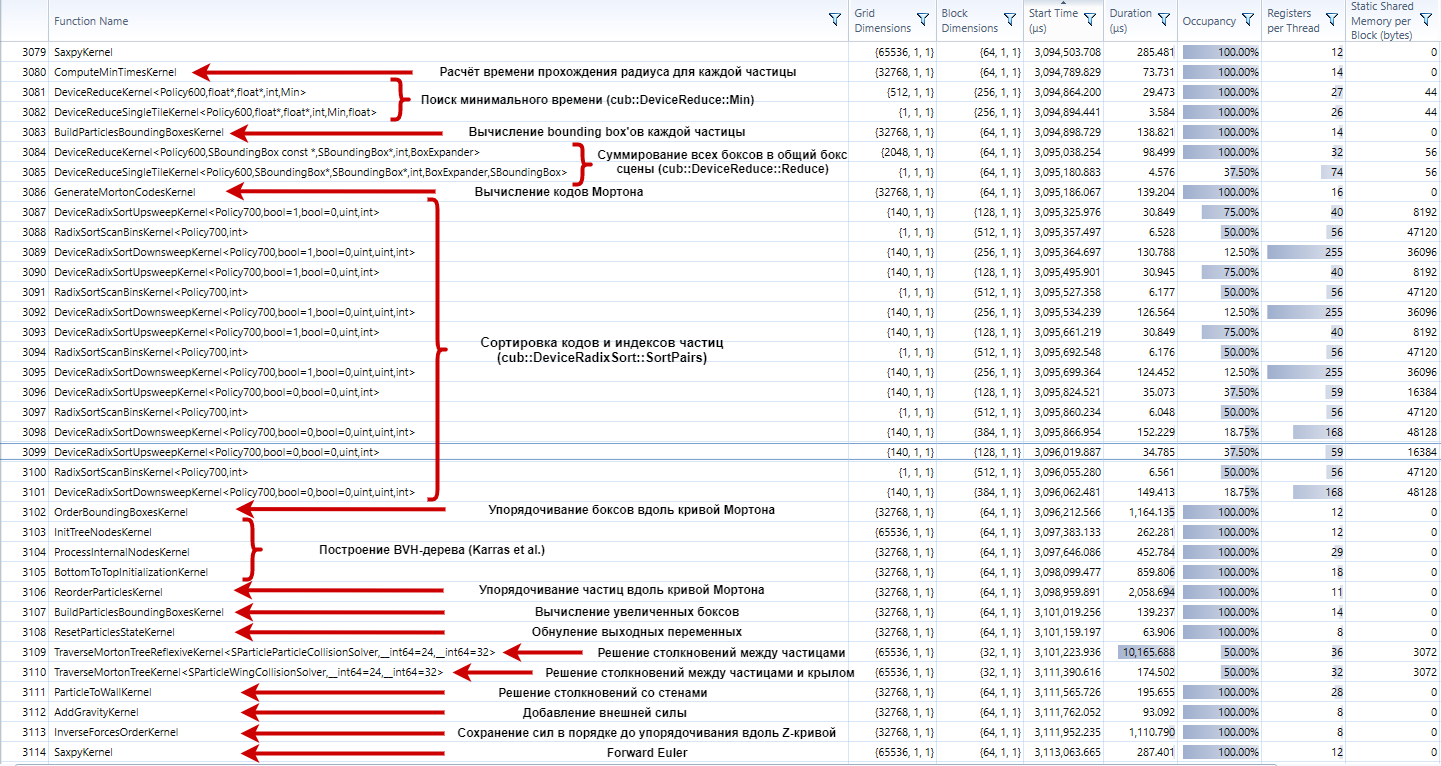
,
, GPU -, . , . “ ”, APOD .
, , , , GPU.
If you would like to start learning CUDA but don't know where to start, there is a great course on Youtube from Udacity “Intro to Parallel Programming”. I recommend to review.
https://www.youtube.com/playlist?list=PLAwxTw4SYaPnFKojVQrmyOGFCqHTxfdv2
Finally, a few more video simulations:
CPU version, 8 threads, 131'072 particles
CUDA version, 4.2M particles, 30 minutes simulation