Today we are going to write our own FTS engine. By the end of this article, he will be able to search millions of documents in less than a millisecond. We'll start with simple search queries such as "Return all documents with cat" and then extend the engine to support more complex logical queries.
Note: The most famous full-text search engine is Lucene (and also Elasticsearch and Solr built on top of it).
Why do you need FTS
Before you write any code, you might ask: "Couldn't you just use grep or a loop that checks each document for the search word?" Yes, you can. But that's not always the best idea.
Housing
We will search for fragments of annotations from the English-language Wikipedia. The latest dump is available at dumps.wikimedia.org . As of today, the file size after unpacking is 913 MB. The XML file contains more than 600 thousand documents.
Sample document:
<title>Wikipedia: Kit-Cat Klock</title>
<url>https://en.wikipedia.org/wiki/Kit-Cat_Klock</url>
<abstract>The Kit-Cat Klock is an art deco novelty wall clock shaped like a grinning cat with cartoon eyes that swivel in time with its pendulum tail.</abstract>Uploading documents
First, you need to load all documents from the dump using a very handy built-in package
encoding/xml:
import (
"encoding/xml"
"os"
)
type document struct {
Title string `xml:"title"`
URL string `xml:"url"`
Text string `xml:"abstract"`
ID int
}
func loadDocuments(path string) ([]document, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
defer f.Close()
dec := xml.NewDecoder(f)
dump := struct {
Documents []document `xml:"doc"`
}{}
if err := dec.Decode(&dump); err != nil {
return nil, err
}
docs := dump.Documents
for i := range docs {
docs[i].ID = i
}
return docs, nil
}Each document is assigned a unique ID. For simplicity, the first loaded document is assigned ID = 0, the second ID = 1, and so on.
First try
Content search
Now we have all the documents loaded into memory, let's try to find those that mention cats. First, let's go through all the documents and check them for a substring
cat:
func search(docs []document, term string) []document {
var r []document
for _, doc := range docs {
if strings.Contains(doc.Text, term) {
r = append(r, doc)
}
}
return r
}On my laptop, the search takes 103ms - not too bad. If a spot check several documents from the issue, we can see that the function gives satisfaction on the word caterpillar and category , but not at Cat with a capital letter the C . This is not exactly what we are looking for.
There are two things to fix before proceeding:
- Make the search case insensitive (so that the output includes Cat as well ).
- Consider word boundaries, not substrings (so that there are no words like caterpillar and communication in the output ).
Search with regular expressions
One obvious solution that solves both problems is regular expressions .
In this case, we need
(?i)\bcat\b:
(?i)means the regex is case insensitive
\bindicates correspondence with word boundaries (a place where there is a character on one side and not on the other)
But now the search took more than two seconds. As you can see, the system began to slow down even on a modest body of 600 thousand documents. While this approach is easy to implement, it doesn't scale very well. As the dataset grows, more and more documents need to be scanned. The time complexity of this algorithm is linear, that is, the number of documents to scan is equal to the total number of documents. If we had 6 million documents instead of 600 thousand, the search would take 20 seconds. We'll have to come up with something better.
Inverted index
To speed up search queries, we'll preprocess the text and build an index.
The core of FTS is a data structure called an inverted index . It links each word to documents containing that word.
Example:
documents = {
1: "a donut on a glass plate",
2: "only the donut",
3: "listen to the drum machine",
}
index = {
"a": [1],
"donut": [1, 2],
"on": [1],
"glass": [1],
"plate": [1],
"only": [2],
"the": [2, 3],
"listen": [3],
"to": [3],
"drum": [3],
"machine": [3],
}Below is a real example of an inverted index. This is an index in a book where the term is followed by page numbers:

Text analysis
Before starting to build the index, you need to split the source text into a list of words (tokens) suitable for indexing and searching.
The text analyzer consists of a tokenizer and several filters.
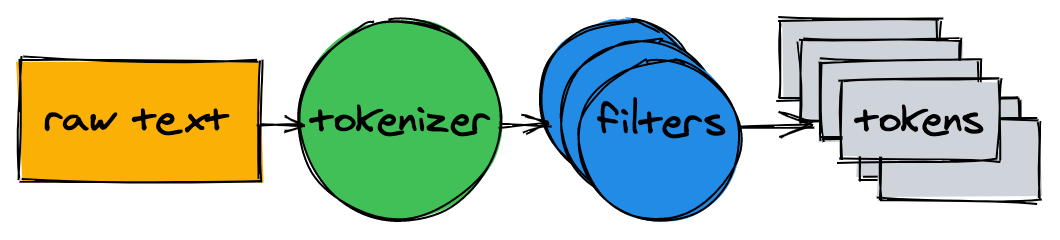
Tokenizer
The tokenizer is the first step in text parsing. Its task is to convert the text into a list of tokens. Our implementation splits the text at word boundaries and removes punctuation marks:
func tokenize(text string) []string {
return strings.FieldsFunc(text, func(r rune) bool {
// Split on any character that is not a letter or a number.
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
})
}> tokenize("A donut on a glass plate. Only the donuts.")
["A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"]Filters
In most cases, simply converting text to a list of tokens is not enough. Additional normalization will be required to facilitate indexing and searching.
Lower case
To make the search case insensitive, the lowercase filter converts tokens to lowercase. The words cAt , Cat, and caT are normalized to the form cat . Later, when referring to the index, we also normalize the search queries to lowercase, so that the search query cAt finds the word Cat .
Removing common words
Almost every English text contains common words such as a , I , The, or be . They are called stop words and are present in almost all documents, so they should be removed.
There is no "official" stopword list. Let's eliminate the top 10 on the OEC list . Feel free to supplement it:
var stopwords = map[string]struct{}{ // I wish Go had built-in sets.
"a": {}, "and": {}, "be": {}, "have": {}, "i": {},
"in": {}, "of": {}, "that": {}, "the": {}, "to": {},
}
func stopwordFilter(tokens []string) []string {
r := make([]string, 0, len(tokens))
for _, token := range tokens {
if _, ok := stopwords[token]; !ok {
r = append(r, token)
}
}
return r
}> stopwordFilter([]string{"a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"})
["donut", "on", "glass", "plate", "only", "donuts"]Stemming
Due to grammar rules, there are different forms of words in documents. Stemming reduces them to basic form. For example, fishing , fished, and fisher all boil down to the main fish form .
Implementing stemming is not a trivial task and is not covered in this article. Let's take one of the existing modules:
import snowballeng "github.com/kljensen/snowball/english"
func stemmerFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = snowballeng.Stem(token, false)
}
return r
}> stemmerFilter([]string{"donut", "on", "glass", "plate", "only", "donuts"})
["donut", "on", "glass", "plate", "only", "donut"]Note: Stemmers don't always work correctly. For example, some may shorten airline to airlin .
Assembling the analyzer
func analyze(text string) []string {
tokens := tokenize(text)
tokens = lowercaseFilter(tokens)
tokens = stopwordFilter(tokens)
tokens = stemmerFilter(tokens)
return tokens
}The tokenizer and filters convert the sentences into a list of tokens:
> analyze("A donut on a glass plate. Only the donuts.")
["donut", "on", "glass", "plate", "only", "donut"]Tokens are ready for indexing.
Building an index
Let's go back to the inverted index. It matches each word with document IDs. The built-in data type works well for storing a map (displaying)
map. The key will be a token (string), and the value will be a list of document IDs:
type index map[string][]intIn the process of building the index, documents are analyzed and their identifiers are added to the map:
func (idx index) add(docs []document) {
for _, doc := range docs {
for _, token := range analyze(doc.Text) {
ids := idx[token]
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(ids, doc.ID)
}
}
}
func main() {
idx := make(index)
idx.add([]document{{ID: 1, Text: "A donut on a glass plate. Only the donuts."}})
idx.add([]document{{ID: 2, Text: "donut is a donut"}})
fmt.Println(idx)
}Everything is working! Each token in the display refers to the IDs of the documents containing that token:
map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]]Inquiries
For queries to the index, we will apply the same tokenizer and filters that we used for indexing:
func (idx index) search(text string) [][]int {
var r [][]int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
r = append(r, ids)
}
}
return r
}> idx.search("Small wild cat")
[[24, 173, 303, ...], [98, 173, 765, ...], [[24, 51, 173, ...]]And now, finally, we can find all the documents that mention cats. Searching 600 thousand documents took less than a millisecond (18 μs)!
With an inverted index, the time complexity of a search query is linear with the number of search tokens. In the above query example, in addition to analyzing the input text, only three map searches are performed.
Logical queries
The previous request returned an unlinked list of documents for each token. But we usually expect a search for small wild cat to return a list of results that contain both small , wild and cat . The next step is to compute the intersection between the lists. Thus, we will get a list of documents corresponding to all tokens.

Fortunately, the IDs in our inverted index are inserted in ascending order. Since the IDs are sorted, you can calculate the intersection between the lists in linear time. The function
intersectioniterates through two lists at the same time and collects the identifiers that are present in both:
func intersection(a []int, b []int) []int {
maxLen := len(a)
if len(b) > maxLen {
maxLen = len(b)
}
r := make([]int, 0, maxLen)
var i, j int
for i < len(a) && j < len(b) {
if a[i] < b[j] {
i++
} else if a[i] > b[j] {
j++
} else {
r = append(r, a[i])
i++
j++
}
}
return r
}The updated one
searchparses the given request text, looks for tokens and calculates the given intersection between the ID lists:
func (idx index) search(text string) []int {
var r []int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
if r == nil {
r = ids
} else {
r = intersection(r, ids)
}
} else {
// Token doesn't exist.
return nil
}
}
return r
}The Wikipedia dump contains only two documents that simultaneously contain the words small , wild and cat :
> idx.search("Small wild cat")
130764 The wildcat is a species complex comprising two small wild cat species, the European wildcat (Felis silvestris) and the African wildcat (F. lybica).
131692 Catopuma is a genus containing two Asian small wild cat species, the Asian golden cat (C. temminckii) and the bay cat.Search works as expected!
By the way, I first learned about catopums , here is one of them:

conclusions
So, we made a full-text search engine. Despite its simplicity, it can provide a solid foundation for more advanced projects.
I have not mentioned many aspects that can significantly improve performance and make searching more convenient. Here are some ideas for further improvements:
- Add logical operators OR and NOT .
- Store index on disk:
- It takes some time to restore the index each time the application is restarted.
- Large indexes may not fit in memory.
- It takes some time to restore the index each time the application is restarted.
- Experiment with memory and CPU-optimized data formats for storing ID sets. Take a look at Roaring Bitmaps .
- Indexing multiple fields of the document.
- Sort results by relevance.
All source code is published on GitHub .