
Many people think that it is enough to port the application to Kubernetes (either using Helm or manually) and there will be happiness. But it's not that simple.
The Mail.ru Cloud Solutions team hastranslated an article by DevOps engineer Julian Guindi. He talks about the pitfalls his company faced in the migration process so that you don't step on the same rake.
Step one: set up pod requests and limits
Let's start by setting up a clean environment in which our pods will run. Kubernetes is great at scheduling pods and handling failure states. But it turned out that the planner sometimes cannot place a pod if it is difficult to estimate how much resources it needs to work successfully. This is where resource requests and limits come in. There has been a lot of debate about the best approach to setting requests and limits. Sometimes it seems that it really is more art than science. Here's our approach.
Pod requests are the primary value used by the scheduler for optimal pod placement.
Kubernetes: , . , PodFitsResources , .
We use application requests so that we can use them to estimate how many resources the application actually needs to work properly. This will allow the planner to realistically place the nodes. Initially, we wanted to set up requests with a margin to ensure that there is enough resources for each pod, but we noticed that the scheduling time increased significantly, and some pods were never fully scheduled, as if there were no resource requests for them.
In this case, the scheduler would often "squeeze" pods and would not be able to reschedule them because the control plane had no idea how much resources the application would need, which is a key component of the scheduling algorithm.
Pod limitsIs a clearer limitation for the pod. It represents the maximum amount of resources the cluster will allocate to the container.
Again, from the official documentation : if a 4 GiB memory limit is set for a container, then kubelet (and the container runtime) will force it. The runtime prevents the container from using more than the specified resource limit. For example, when a process in a container tries to use more than the allowed amount of memory, the kernel exits the process with an "out of memory" (OOM) error.
A container can always use more resources than specified in a resource request, but can never use more than specified in a limit. This value is difficult to set correctly, but it is very important.
Ideally, we want the resource requirements of the pod to change throughout the process life cycle without interfering with other processes in the system — this is the goal of setting limits.
Unfortunately, I cannot give specific instructions on what values to set, but we ourselves adhere to the following rules:
- Using a load testing tool, we simulate the baseline traffic and monitor the pod resource usage (memory and processor).
- ( 5 ) . , , Go.
Note that higher resource constraints make scheduling more difficult because the pod needs a target node with enough resources available.
Imagine a situation where you have a lightweight web server with a very high resource constraint like 4 GB of memory. This process will likely need to be scaled horizontally and each new module will have to be scheduled on a node with at least 4 GB of available memory. If no such node exists, the cluster must introduce a new node to process this pod, which may take some time. It is important to keep the difference between resource requests and limits as small as possible to ensure fast and smooth scaling.
Step two: set up the Liveness and Readiness tests
This is another subtle topic that is frequently discussed in the Kubernetes community. It is important to have a good understanding of the Liveness and Readiness tests as they provide a mechanism for the software to run smoothly and minimize downtime. However, they can seriously impact your application's performance if not configured correctly. Below is a summary of what both samples are.
Liveness shows if the container is running. If it fails, the kubelet kills the container, and a restart policy is enabled for it. If the container is not equipped with a Liveness probe, then the default state is success, as the Kubernetes documentation says .
Liveness probes should be cheap, i.e. not consume a lot of resources, because they run frequently and should inform Kubernetes that the application is running.
Setting it to run every second will add 1 request per second, so be aware that additional resources will be needed to handle this traffic.
At our company, Liveness tests validate the main components of an application, even if the data (for example, from a remote database or cache) is not fully available.
We have configured a "health" endpoint in applications that simply returns a response code of 200. This is an indication that the process is up and running and is able to handle requests (but not traffic yet). Readiness
testindicates whether the container is ready to serve requests. If the readiness probe fails, the endpoint controller removes the pod IP address from the endpoints of all services matching the pod. This is also stated in the Kubernetes documentation.
Readiness probes consume more resources, as they must go to the backend in such a way as to indicate that the application is ready to accept requests.
There is a lot of controversy in the community as to whether to go directly to the database. Considering the overhead (checks are performed frequently, but can be adjusted), we decided that for some applications, the availability to serve traffic is counted only after checking that records are returned from the database. Well-designed availability probes ensured higher availability and eliminated downtime during deployment.
If you decide to query the database to check that your application is ready, make sure it is as cheap as possible. Let's take a query like this:
SELECT small_item FROM table LIMIT 1Here's an example of how we configure these two values in Kubernetes:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Some additional configuration options can be added:
initialDelaySeconds- how many seconds will elapse between starting the container and starting the samples.periodSeconds— .timeoutSeconds— , . -.failureThreshold— , .successThreshold— , ( , ).
:
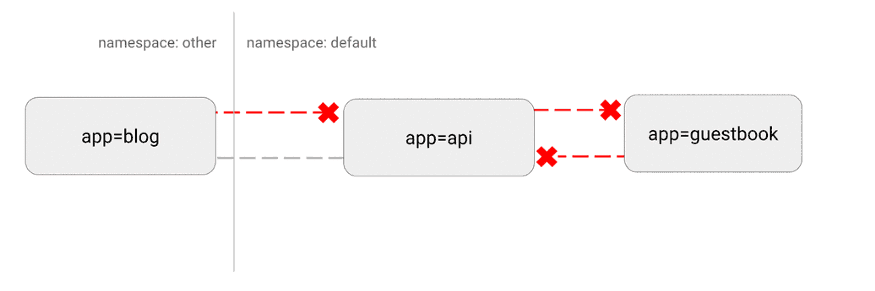
Kubernetes has a "flat" network topography, by default all pods interact directly with each other. In some cases, this is undesirable.
A potential security issue is that an attacker could use a single vulnerable application to send traffic to all pods on the network. As with many areas of security, the principle of least privilege applies. Ideally, network policies should explicitly state which connections between pods are allowed and which are not.
For example, the following is a simple policy that denies all inbound traffic for a specific namespace:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualization of this configuration:
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
More details here .
Step four: custom behavior with hooks and init containers
One of our main goals was to provide deployments to Kubernetes without downtime for developers. This is difficult because there are many options for shutting down applications and freeing up used resources.
Particular difficulties arose with Nginx . We noticed that when these pods were sequentially deployed, active connections were dropped before successful completion.
After extensive research on the Internet, it turned out that Kubernetes does not wait for Nginx connections to exhaust itself before shutting down the pod. With the help of a pre-stop hook, we implemented the following functionality and completely got rid of downtime:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
And here
nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Another extremely useful paradigm is the use of init containers to handle the launch of specific applications. This is especially useful if you have a resource-intensive database migration process that needs to be started before running the application. You can also specify a higher resource limit for this process without setting such a limit for the main application.
Another common scheme is to access secrets in the init container, which provides these credentials to the main module, which prevents unauthorized access to secrets from the main application module itself.
, : init- , . , .
:
Finally, let's talk about a more advanced technique.
Kubernetes is an extremely flexible platform that lets you run workloads the way you see fit. We have a number of highly efficient, resource-intensive applications. Through extensive load testing, we found that one of the applications struggles to handle the expected traffic load when Kubernetes defaults are in effect.
However, Kubernetes allows you to run a privileged container that changes kernel parameters only for a specific pod. Here's what we used to change the maximum number of open connections:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
This is a more advanced technique and is often unnecessary. But if your application is struggling to cope with a heavy load, you can try adjusting some of these parameters. More details about this process and setting various values - as always in the official documentation .
Finally
While Kubernetes may seem like an out-of-the-box solution, there are several key steps to take to keep your applications running smoothly.
Throughout your migration to Kubernetes, it is important to follow a "load testing cycle": run the application, test it under load, observe metrics and scaling behavior, tune the configuration based on that data, then repeat the cycle again.
Realistically estimate the expected traffic and try to go beyond it to see which components break first. With this iterative approach, only a few of these recommendations may be sufficient to achieve success. Or, more in-depth customization may be required.
Always ask yourself these questions:
- ?
- ? ? ?
- ? , ?
- ? ? ?
- ? - , ?
Kubernetes provides an incredible platform that enables best practices to deploy thousands of services across a cluster. However, all applications are different. Sometimes implementation takes a little more work.
Fortunately, Kubernetes provides the necessary settings to meet all of the technical goals. Using a combination of resource requests and limits, Liveness and Readiness probes, init containers, network policies, and custom kernel tuning, you can achieve high performance along with fault tolerance and fast scalability.
What else to read: