Reinforcement Learning is bad, or rather, does not work at all with high dimensions. And also faces the problem that physics simulators are quite slow. Therefore, recently, a way to get around these limitations has become popular by training a separate neural network that simulates a physics engine. It turns out something like an analogue of imagination, in which further basic learning takes place.
Let's see how much progress has been made in this area and look at the main architectures.
The idea of using a neural network instead of a physical simulator is not new, since simple simulators like MuJoCo or Bullet on modern CPUs are capable of delivering at least 100-200 FPS (and more often at 60), and running a neural network simulator in parallel batches easily produces 2000-10000 FPS at comparable quality. True, on small horizons of 10-100 steps, but for reinforcement learning this is often enough.
But more importantly, the process of training a neural network to mimic a physics engine usually involves dimensionality reduction. Since the easiest way to train such a neural network is to use an autoencoder, where it happens automatically.
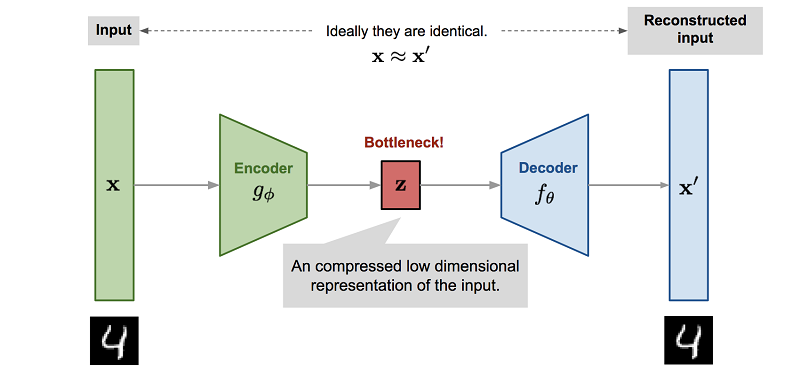
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
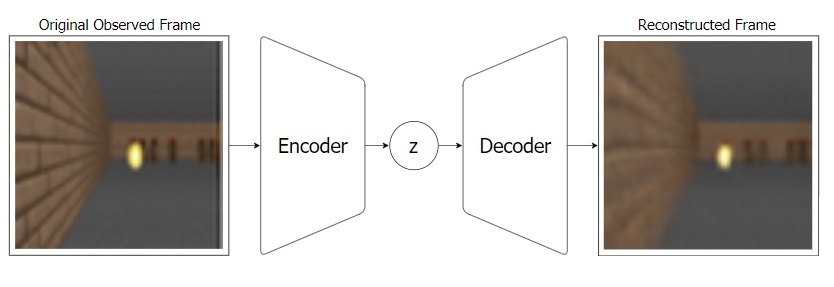
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
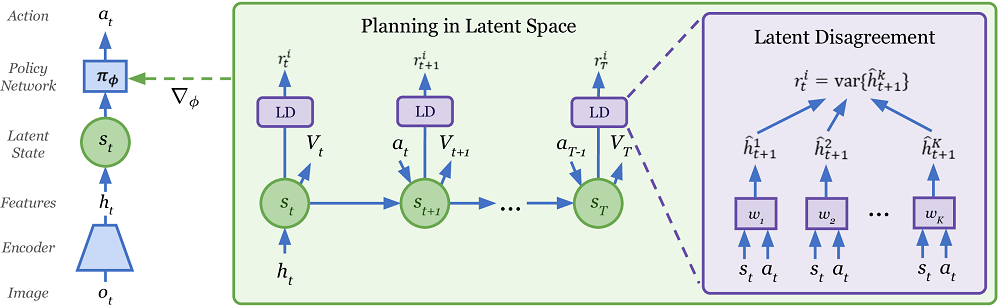
Plan2Explore , Dreamer Model-Free , , . , .
Interestingly, Plan2Explore uses an unusual way of assessing the novelty of new places while exploring the world. For this, an ensemble of models trained only on a model of the world and predicting only one step forward is trained. It is argued that their predictions differ for states of high novelty, but as data sets (frequent visits to the site), their predictions begin to agree even in random stochastic environments. Since one-step predictions eventually converge to some mean values in this stochastic environment. If you have not understood anything, then you are not alone. There, in the article, this is not very clear. But somehow it seems to work.