- I'll start with where online cinemas came from.

In the course of the development of the Internet, OTT media services appeared, which began to be used to transfer media content over the Internet, in contrast to traditional media services, which used cable, satellite and other communication channels.
Such media services are based on OVP - an online video platform, which includes a content management system, a web player and a CDN. A separate class of such systems is OTT-TV, an online cinema, which, in addition to OVP, implements control and management systems for access to content, a system for protecting digital content rights, management of subscriptions, purchases, and various product and technical metrics. And it imposes on these systems increased requirements for uptime and latency.
I will talk about the backend, which is responsible for the content management system, for the user functionality of the online cinema and for the part of the content management and control system.
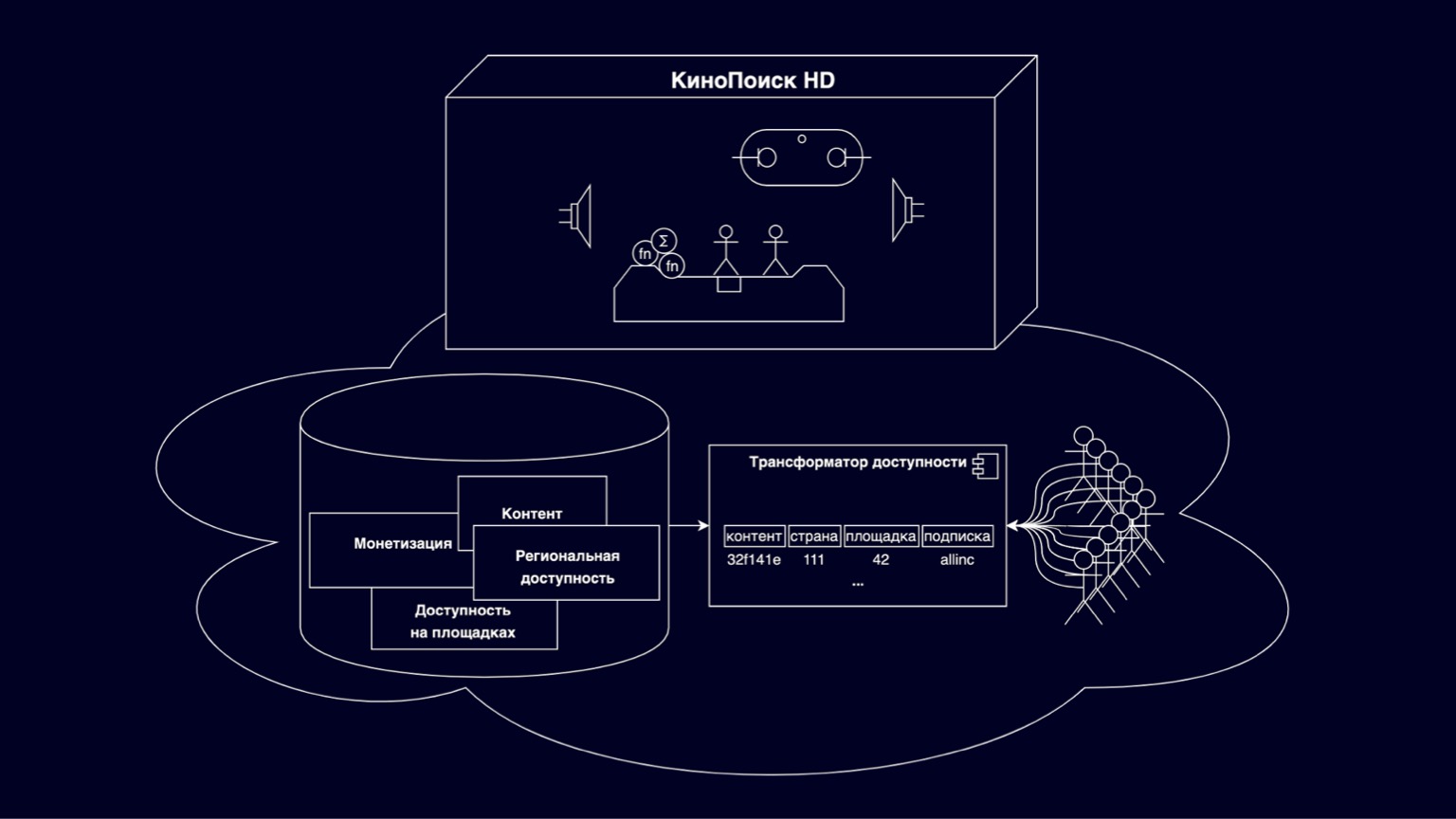
Let's see what online cinemas are made of. In the KinoPoisk HD box, all sorts of cool things and viewing modes are implemented. Thousands of RPS users select available content in storefronts, subscribe and purchase. Save browsing progress, user settings. Thousands of RPS generate various metrics. This is a rather large and interesting set of components, the details of which we will not go into today. But it's worth mentioning that, in general, these are good and understandably scalable services - due to the fact that they are sharded by users.
Today we will focus on the cloud under the box. This is a platform responsible for storing films, series, various restrictions from copyright holders. Supported by the efforts of several departments. Part of this platform is an accessibility transformer that answers questions that I can watch right now at this location. Without an accessibility transformer, no content will literally appear on KinoPoisk HD.
The challenge for the transformer is to translate a flexible and layered accessibility model into an efficient model that scales well to as many content consumers as possible.
Why is it flexible and scalable? Primarily because it includes various entities that describe content, monetization, relational availability, and availability on sites. All this is in revolutionary relations, has a complex hierarchy. And this flexibility is needed in order to meet the requirements of dozens of copyright holders and various flexible pricing options.
By sites, we mean, for example, an online cinema on the web, an online cinema on devices and other partner OTT services that also play our content.
It is clear that to efficiently calculate the availability of such a multi-level model, you need to build complex joins, and such queries do not scale for any load, they are quite complex in interpretation to build some functionality on them quickly and clearly. To solve these problems, an accessibility transformer emerged, denormalizing the model presented on the slide as a composite key, which includes content IDs, countries, sites, subscriptions, and some invisible non-key residue that makes up most of the memory. Today we will talk about the difficulties of scaling the accessibility transformer.
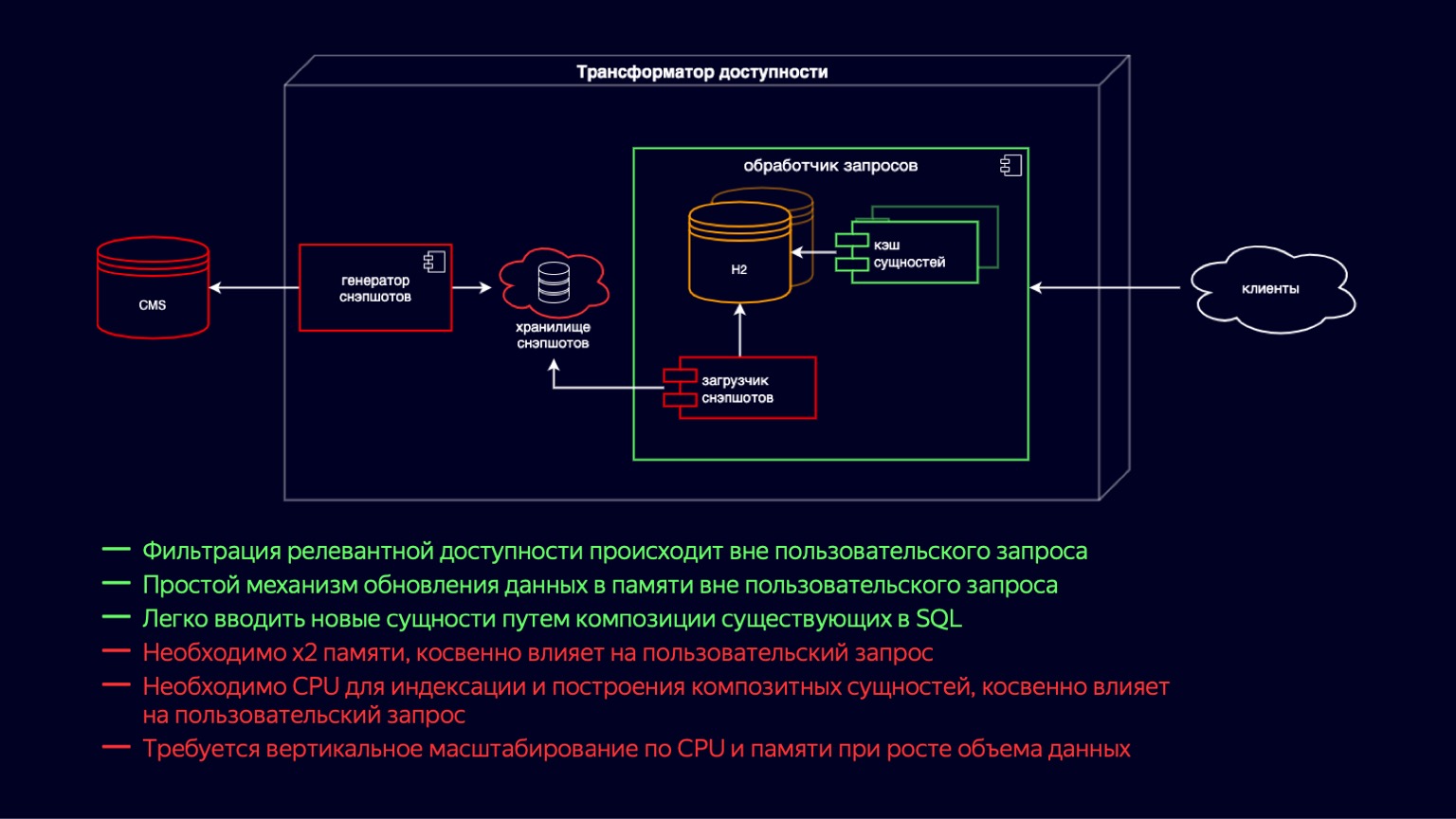
Let's dive deeper into this component and see what it consists of. Here we see the state of the system just before the start of the problem. All this time, the accessibility transformer has been moving along the path of lightning-fast development of the online cinema. It was important to quickly launch new functionality, first of all, to ensure the availability of tens of thousands of films and TV series.
If you go from left to right, then there is a CMS, a relational database in which in third normal form and in EAVour main entities are stored. Next is the snapshot loader. Further, the snapshot generator, which regularly receives relevant data, filters it, adds it to the snapshot storage. This is actually a SQL dump. Further inside the request processor instance, the Snapshot Loader regularly receives new data and imports it into H2. H2 is an in-memory database written in Java that implements the basic capabilities of a DBMS, that is, there is a query interpreter, a query optimizer, and indexes.
In fact, this is exactly the component that provides the flexibility to create new functionality for an online cinema due to the fact that you can simply write SQL queries and join denormalized entities quickly and easily.
H2 is updated on a copy-on-write model. The Snapshot Loader picks up a new database instance and populates it. And then, after filling, it disposes of the old one using the garbage collector.
Simultaneously with H2, the entity cache is raised, which includes composite entities and an index above them. Composite entities are essentially a continuation of the denormalization of what lies in H2 to accommodate more demanding latency requests from clients. The cache entities are updated in the same way according to the copy-on-write model, simultaneously with the raising of new H2 instances.
The main advantages of the system: you can easily and flexibly add new functionality using joins. A relatively simple scheme for updating data by copy-on-write. The downside is, of course, that x2 memory is required to store and update these entities. This indirectly affects the user request as it is disposed of by the garbage collector.
Also, while building the entity cache, a CPU resource is required for indexing. And this also indirectly affects the user request, but at the expense of competition for CPU resources. Both of these points together lead to the fact that with the growth of the data volume of our main entities, the query processor needs to scale vertically, both in terms of CPU and memory.
But the system relied on tens of thousands of films and TV series available online. Therefore, for a long time, these disadvantages were acceptable, they made it possible to exploit the main advantage in terms of flexibility and ease of introducing new functions of an online cinema.
It is clear that all this worked up to a certain point. Imagine this yellow bus is our accessibility transformer.

It hosts films and serials reproduced by denormalization, that is, there are tens of thousands of them. And at one of the stops, hundreds of thousands of music videos and trailers need to be lifted aboard and somehow placed. Once on board, they will also multiply due to denormalization. Those who are inside need to shrink, and those who are outside need to jump in, squeeze through. You can imagine how this happens. Technically, at that moment, our memory capacity on the instance grew to tens of gigabytes. Building the cache and disposing of old instances using the garbage collector took several virtual cores. And since the amount of data has grown dramatically, this whole procedure has led to the fact that it takes tens of minutes to publish new content.
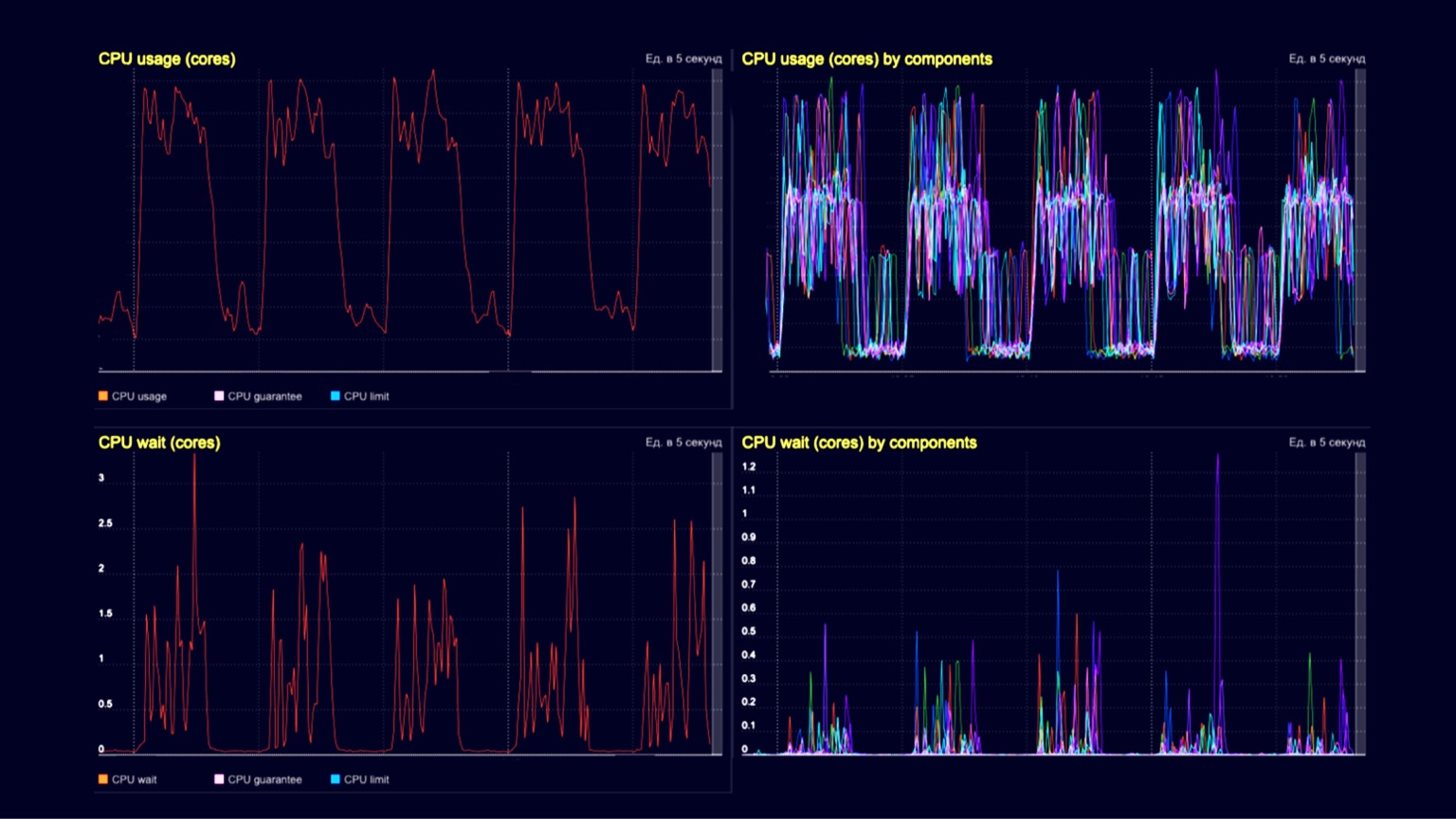
Technically, we are seeing CPU utilization here on a query processor cluster. In the trenches - the processing of client requests of the order of several thousand RPS, and in the hills - the same several thousand RPS, plus the same loading of snapshots and their disposal using a garbage collector. The bottom two graphs are CPU wait on the container. We see that they also begin to manifest themselves at the moment of downloading snapshots and their disposal.
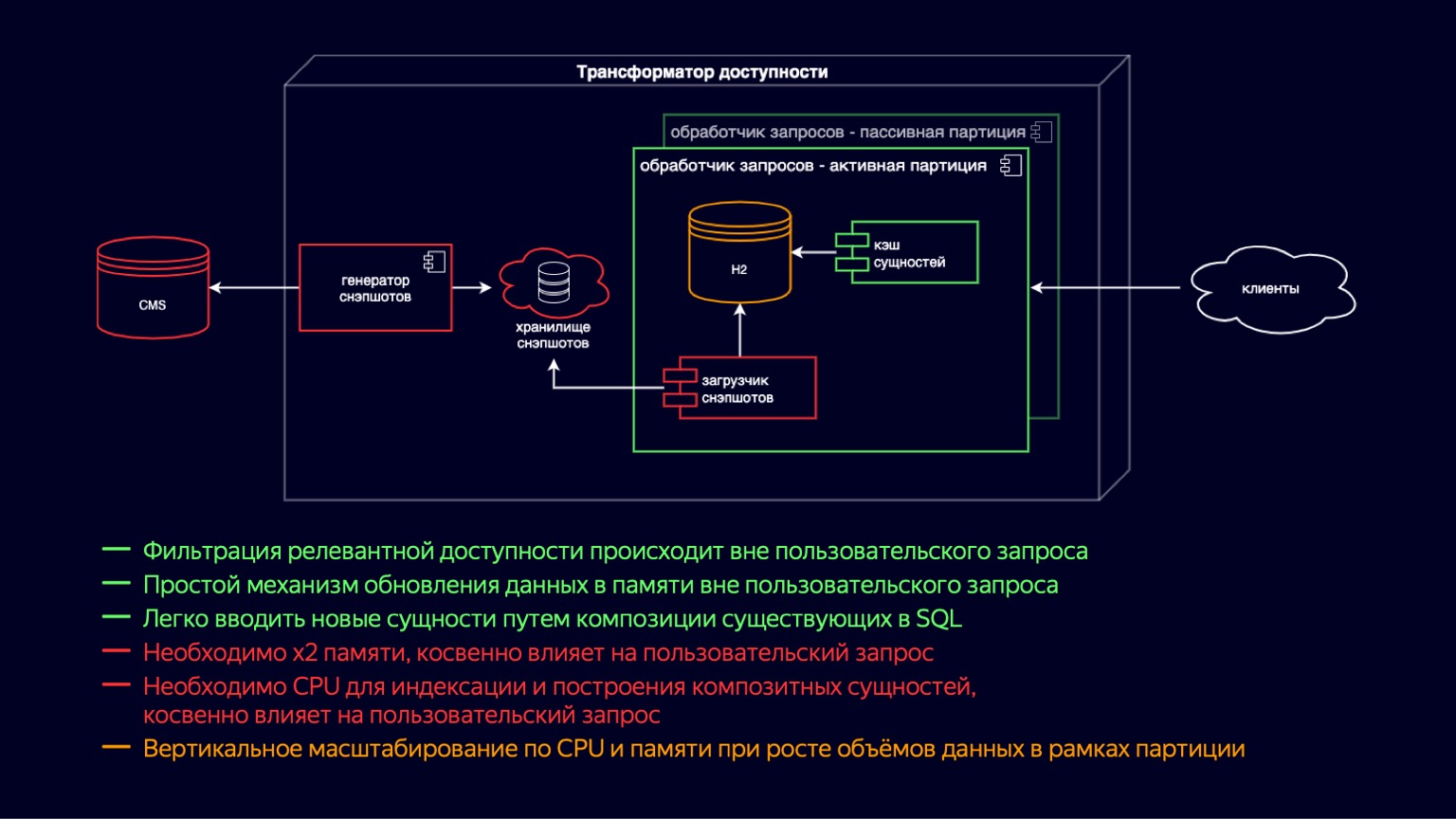
To accommodate these music videos and trailers and continue to scale, we introduced active and passive request processor instances. In fact, this is a transfer of copy-on-write up one level. Now we have both active and passive instances in the container. The passive prepares the new H2 and the entity cache, while the active one simply processes user requests. Thus, we have reduced the impact of garbage collection and its pauses on the processing of user requests. But at the same time, since they still live in the same container, loading snapshots and building cache still compete for CPU resources, and the impact on user requests is still there.
We have additionally introduced partitioning by site. This provided us with a reduction in memory on those sites where all these new types of content are not needed. For example, this allowed an online movie theater not to download music videos and trailers, and to reduce the impact. But at the same time, for sites that need to provide all content with accessibility, of course, nothing has changed.
Therefore, the pros and cons of the scheme remained about the same as before. But due to partitioning, vertical scaling in terms of CPU and memory moved to sites, and this allowed some sites to continue to scale. Compared to the previous content publishing scheme, this has not changed in any way. It generally took the same tens of minutes, so we kept looking for ways to optimize it.

What did we understand by that time? That online cinema queries use a small part of the DBMS capabilities. The query interpreter and optimizer has degenerated over time into an entity cache. We realized that the definition of accessibility is broadly universal. Queries differ in that you need to understand the availability of a content unit or list and add additional attributes to this availability. In general, this can be done without a full-fledged DBMS.
And second, a part of the composite key is the low cardinal parameters. There are dozens of countries, in the limit of a couple of hundred, dozens of sites, and only a few subscriptions. Most likely, full denormalization is not required. Both of these findings have led us to move towards a more compact and less denormalized in-memory representation, but which still responds quickly to user requests.

On the slide, we see the transition from the availability transformer v1 to v2. Here's a schematic of a new accessibility scheme, where the composite key actually boils down to just being a content ID key. And accessibility physically or logically boils down to determining the availability by lists of countries, sites and subscriptions.
Thus, we reduce the amount of invisible non-key remainder, which makes up most of the memory, and reduce the amount of memory at the same time.
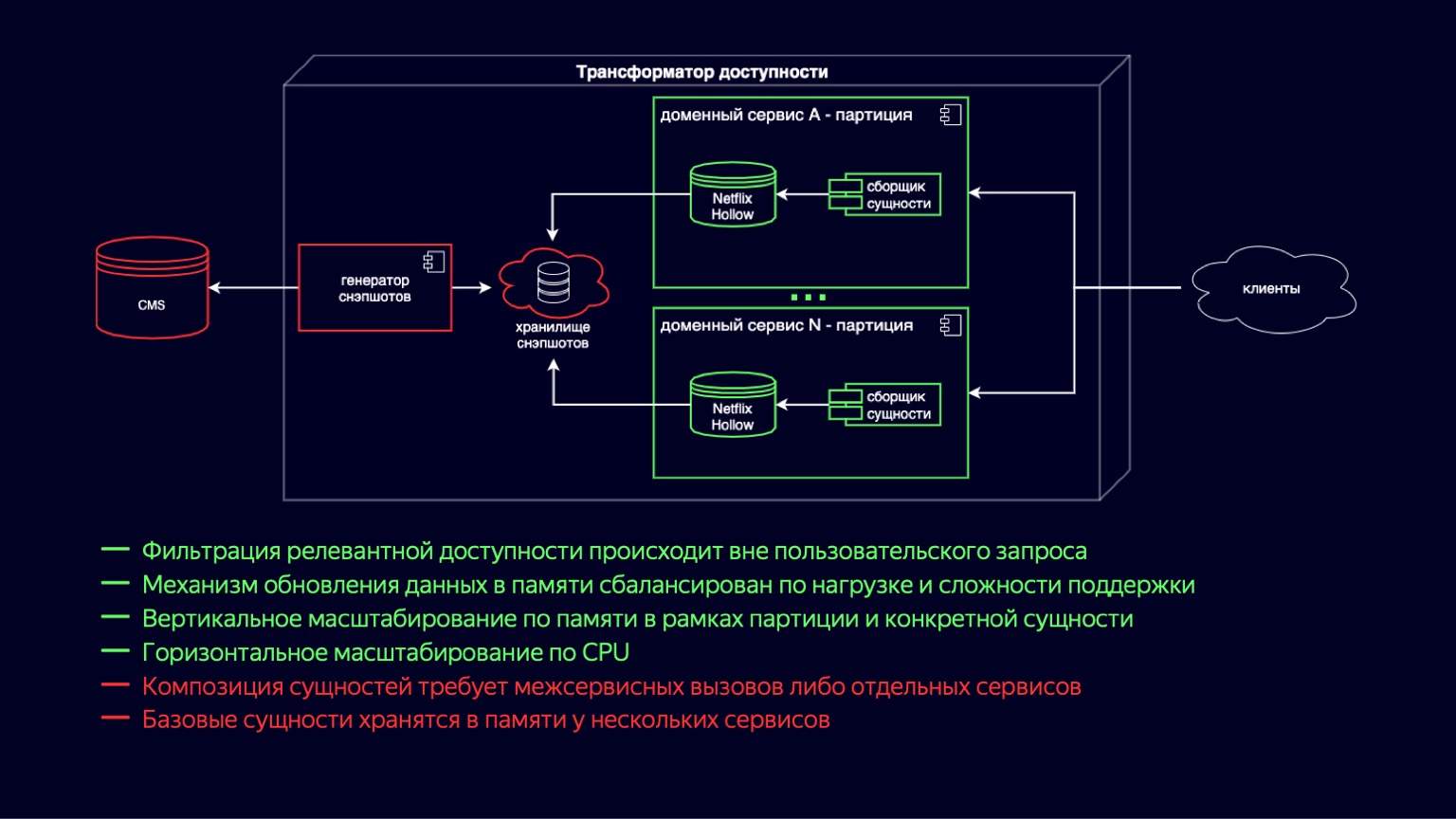
Here we see the process of transitioning to the new accessibility transformer circuit. Netflix Hollow plays the role of a provider and indexer of basic entities, over which domain services collect on the fly an assembly of composite entities of various sizes. This works because the underlying entities are still denormalized and the number of joins is minimal when building. On the other hand, determining availability comes down to simple and cheap cycles and shouldn't be difficult.
At the same time, Netflix Hollow stores and rather carefully treats the load on the CPU and garbage collection, both during the data update and during the access to them. This allows us to reduce the hills that we saw in the CPU utilization graphs and keep them to an acceptable minimum. Additionally, since it implements a hybrid delivery scheme in the form of snapshots and diffs to them, it can increase the speed of publishing new content up to a few minutes.
It is clear that most of the advantages of the previous scheme have been preserved. The mechanism for updating data in memory has become simpler and cheaper in terms of resource utilization. Vertical scaling by partitions, by sites has also been supplemented with scaling for a specific entity, it is now cheaper. And since we reduced the overhead of updating Snapshot copies, there was truly horizontal scaling across the CPU.
The downside to this scheme is that entity composition requires interservice calls or separate services. And there is still duplication of data at the base entity level, since it is now stored in every domain service where it is used. But Netflix Hollow stores data more compactly than H2, and H2 stores it much more compactly than HashMap with objects. So this minus is definitely also considered acceptable and allows you to look to the future with optimism.

This slide is able to charge even tap water with optimism. Because scaling to new countries is no longer a multiplier factor from memory - nor is scaling to new sites. Due to partitioning, it is converted to horizontal scaling.
Well, the scaling of new users and the expansion of the online cinema functionality comes down to an increase in the load. To provide it, we are ready to bring up as many lightweight CPU-bound services as needed. On the other hand, we have accumulated enough knowledge in the area of accessibility to look forward to new challenges with confidence. I hope I was able to share some of this knowledge with you. Thank you for attention.