
In this article I will explain:
- what kind of beast is this Airflow, what components it consists of and how they interact with each other
- about the main entities of Airflow: pipelines called DAG, Operator and a few more things
- how to succeed in development on Airflow
- how we implemented the generation of pipelines and the so-called "declarative writing of pipelines"
- about the pros and cons of using Airflow
What is Airflow
Airflow is a platform for creating, monitoring and orchestrating pipelines. This open source project, written in Python, was created in 2014 at Airbnb. In 2016, Airflow went under the wing of the Apache Software Foundation, went through an incubator, and at the beginning of 2019 became a top-level Apache project.
In the world of data processing, some call it an ETL tool, but this is not exactly ETL in the classical sense, such as Pentaho, Informatica PowerCenter, Talend and others like them. Airflow is an orchestrator, “cron on batteries”: it does not do the heavy work of data transfer and processing itself, but tells other systems and frameworks what to do and monitors the execution status. We mainly use it to run queries in Hive or Spark jobs.
Spoiler
Airflow, worker ( ), . , , .
The range of tasks solved with Airflow is not limited to running something in a Hadoop cluster. It can run Python code, execute Bash commands, host Docker containers and pods in Kubernetes, query your favorite database, and much more.
Airflow architecture
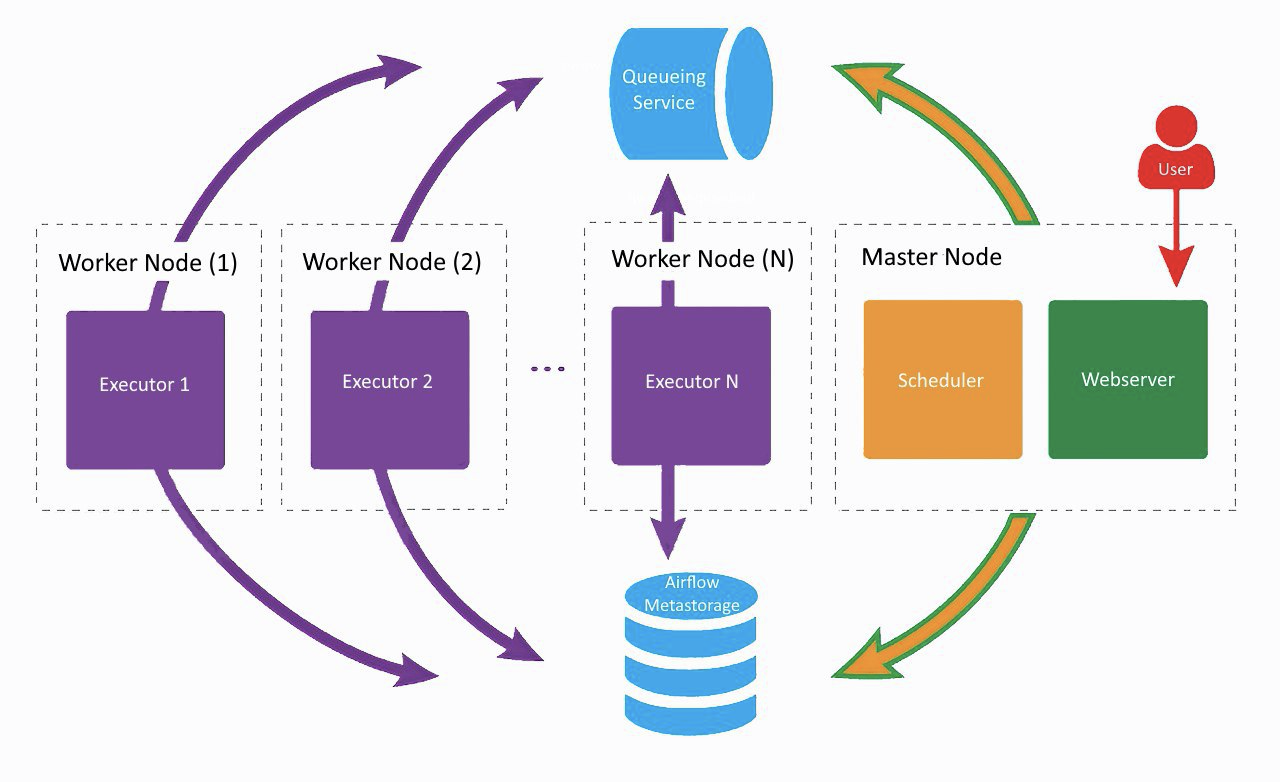
This is what our current Airflow setup looks like, only Lamoda uses two workers. On a separate machine, the web server and scheduler are spinning, workers are puffing on the neighboring ones. One was created for regular tasks, the second we adapted to start training ML models using Vowpal Wabbit. All components communicate with each other through a task queue and a metadata base.
At the dawn of Airflow development in the company, all components (except for the database) worked on the same machine, but at some point this led to a lack of resources on the server and delays in the work of the scheduler. Therefore, we decided to distribute the services to different servers and came to the architecture shown in the picture above.
Airflow components
Webserver
Webserver is a web interface showing what is happening with the pipeline. This page is
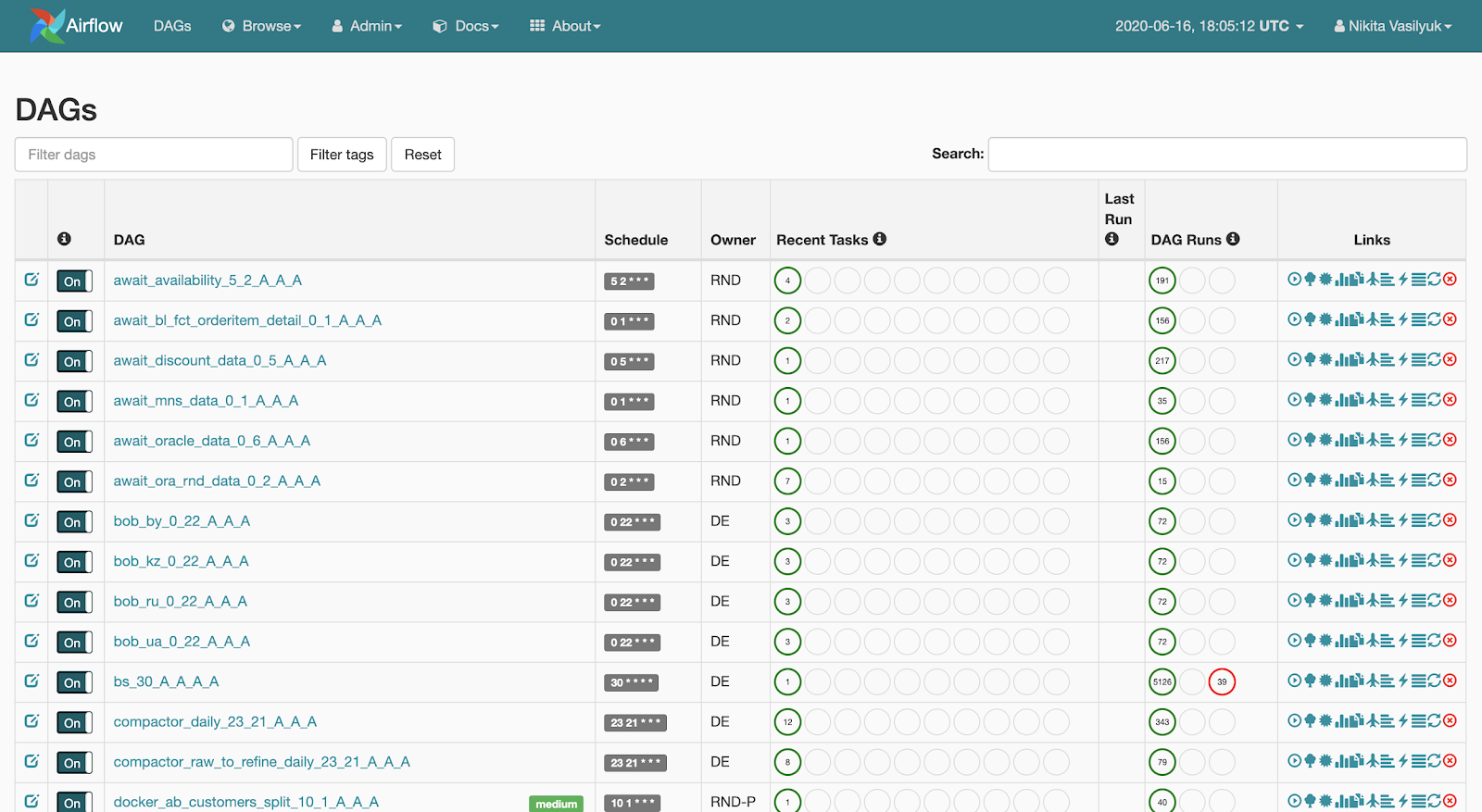
visible to the user: The web server makes it possible to view the list of available pipelines. Brief statistics of launches are displayed next to each pipeline. There are also several buttons that forcefully launch the pipeline or show detailed information: launch statistics, the source code of the pipeline, its visualization in the form of a graph or table, a list of tasks and the history of their launches.
If we click on the pipeline, we will fall through the Graph View menu. Tasks and links between them are displayed here.
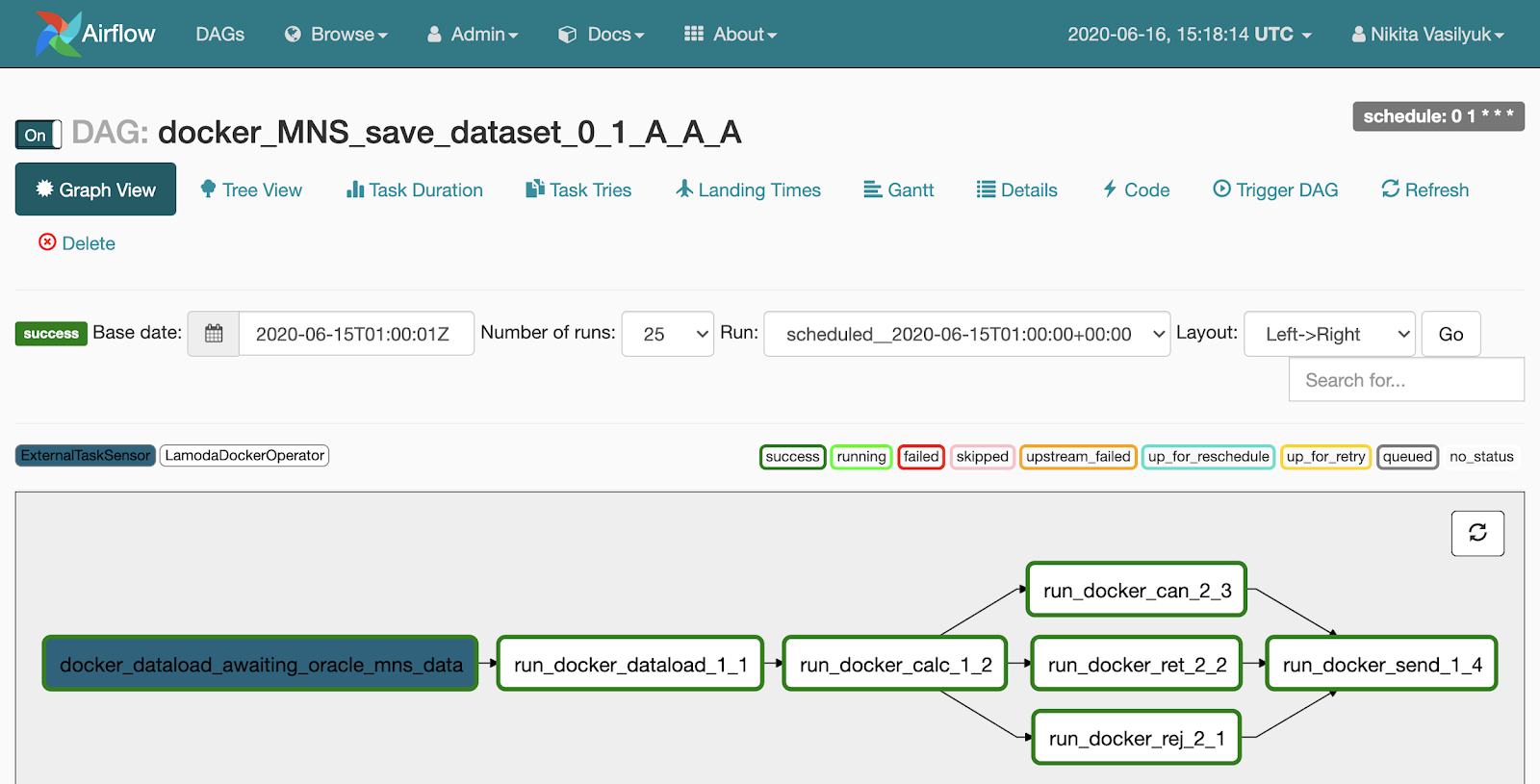
There is a Tree View menu next to the Graph View. It was created to restart tasks, view statistics and logs. The tree-like view of the graph is displayed on the left side, opposite it is a table with the history of task launch.
Each line of this scary table is one task, each column is one start of the pipeline. At their intersection there is a square with the launch of a specific task for a specific date. If you click on it, a menu appears where you can view detailed information and logs of this task, start or restart it, and also mark it as successful or unsuccessful.

Scheduler - as the name implies, launches pipelines when their time comes. It is a Python process that periodically goes to the directory with pipelines, pulls in their current state from there, checks the status, and starts it. In general, the Scheduler is the most interesting and at the same time the bottleneck in the Airflow architecture.
- The first caveat is that only one Scheduler instance can be running at a time. This means that the High Availability mode is currently not possible (the developers plan to add Scheduler HA to Airflow version 2.0).
- : , - . , - , .
Until some time, the delay is tuned by the parameters of the Airflow config file, but the launch lag still remains. It follows from this that Airflow is not about real-time data processing. If you act inadvertently and specify too frequent a launch interval (once every couple of minutes), you can achieve a delay in your pipeline. Experience shows that once every 5 minutes is already quite often, and some do not recommend running the pipeline every 10 minutes. We have a couple of pipelines that start every 10 minutes, they are quite simple and have not had any problems with them so far.
Worker
Worker is where our code runs and tasks get done. Airflow supports several executors:
- The first, the simplest, is the SequentialExecutor. It sequentially launches incoming tasks, and pauses the scheduler for the duration of their execution.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Apache Airflow entities
Pipeline, or DAG
The most important essence of Airflow is the DAG, aka a pipeline, aka a directed acyclic graph. To make it clearer how to cook it and why you need it, I will analyze a small example.
Let's say an analyst came to us and asked us to fill in data into a certain table once a day. He prepared all the information: what to get from where, when to start, with what SLA. Here's an example of how we could describe our pipeline.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
The dag_id contains the unique name of the pipeline. Next, we use schedule_interval to specify how often it should run.
Very important point: since Airflow was developed by an international company, it only works in UTC. At the moment, there is no sane way to make Airflow work in a different time zone, so you need to constantly remember about the difference between our time zone and UTC. In version 1.10.10, it became possible to change the time zone in the UI, but this only applies to the web interface, pipelines will still run in UTC.
The default_args parameter is a dictionary that describes the default arguments for all tasks within this pipeline. The names of most of the parameters describe themselves well, I will not dwell on them.
Operator
An operator is a Python class that describes what actions need to be performed within our daily task in order to delight the analyst.
We can use the HiveOperator, which, oddly enough, is designed to send execution requests to Hive. To start the operator, you need to specify the name of the task, the pipeline, the ID of the connection to Hive and the request being executed.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
There is a piece of Jinja template in the request that we pass to the operator's constructor. Jinja is a Python templating library.
Each pipeline launch stores information about the launch date. It lies in a variable called execution_date. {{ds}} is a macro that will take in execution_date only the date in the format% Y-% m-% d. At a certain moment before starting the operator, Airflow will render a query string, substitute the required date there, and send a request for execution.
ds is not the only macro, there are about 20 of them (a list of all available macros) . They include different date formats and a couple of functions for working with dates - add or subtract days.
When I got acquainted with Airflow, I did not understand why all sorts of macros are needed, when you can just insert a datetime.now () call there and enjoy life. But in some cases, this can greatly ruin the life of both us and the analyst. For example, if we want to recalculate something for some date in the past, Airflow will substitute there not the start date of the pipeline, but the actual execution time. And in some cases, we may not get what we expect.
For example, if we want to restart the pipeline for last Tuesday, then when using datetime.now (), we will actually recalculate the pipeline for today, and not for the required date. Plus, today's data may not even be ready at this point.
After successfully completing the request, we can send a notification to slack about loading data. Next, we command Airflow, in which order to start tasks. Thanks to operator overloading in Airflow, I can easily use the >> operator to specify the order of steps in the pipeline. In my example, we say that we will first start executing the request, then sending a notification to slack.
Idempotency
It is impossible to talk about Airflow without mentioning idempotency. Just in case, let me remind you: idempotency is a property of an object, when you reapply an operation to an object, always return the same result.
In the context of Airflow, this means that if today is Friday, and we restart the task last Tuesday, then the task will start as if it were last Tuesday, and nothing else. That is, the launch or restart of a task for some date in the past should not depend in any way on when this task is actually launched. Idempotency is implemented using the aforementioned execution_date variable.
Airflow was developed as a tool for solving data processing tasks. In this world, we usually process a large chunk of data only when it is ready, that is, the next day. And the creators of Airflow originally laid out such a concept in their products.
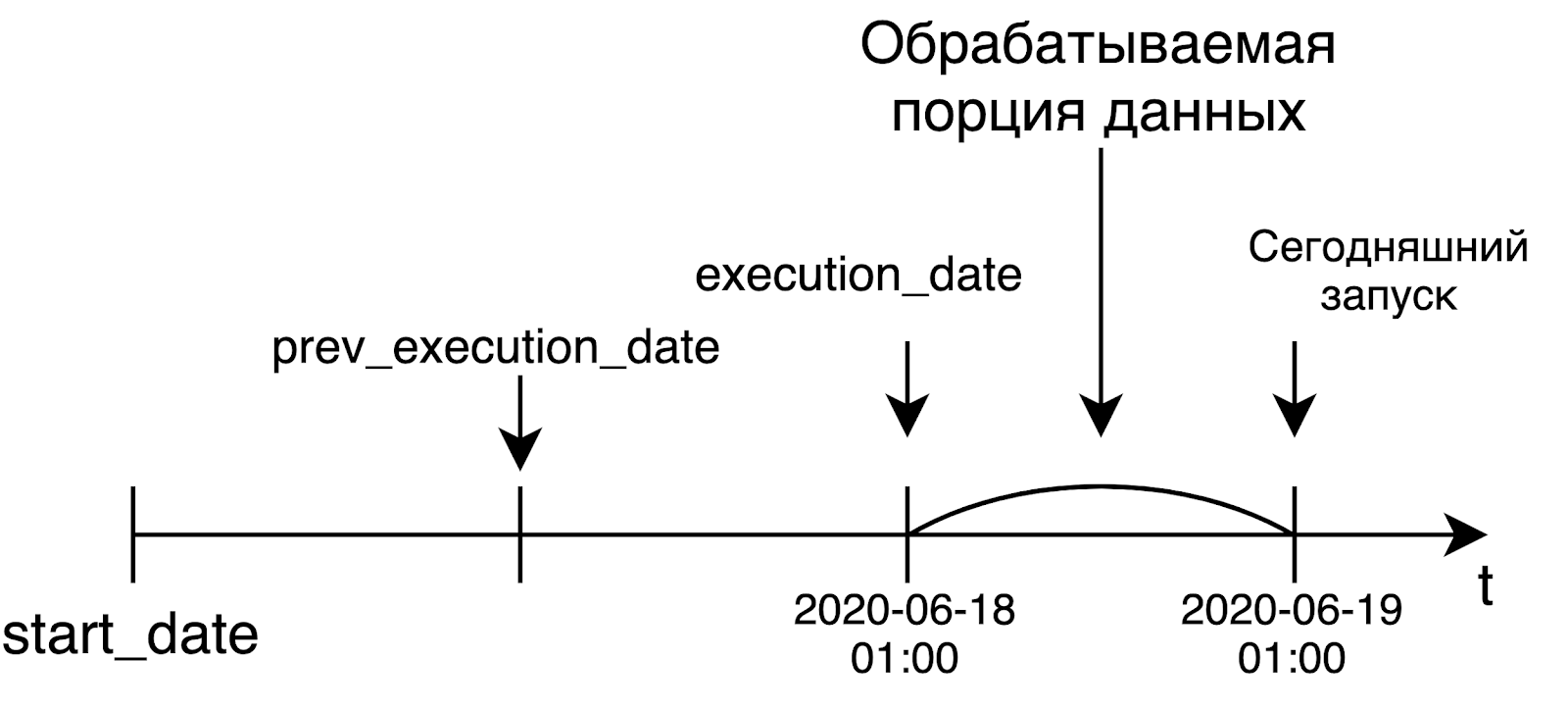
When we launch a daily pipeline, we will most likely want to process data from yesterday. That is why execution_date will be equal to the left border of the interval for which we process the data. For example, today's launch, which started at 1 am UTC, will receive yesterday's date as execution_date. In the case of an hourly pipeline, the situation is the same: to start the pipeline at 6 am, the time in execution_date will be equal to 5 am. This idea is not very obvious at first, but nevertheless, it is very meaningful and important.
Most common Airflow operators
In Airflow, there are not only operators who go to Hive and send something to slack. In fact, there are tons of operators out there. In the article, I brought out the most popular and useful ones.
- BashOpetator and PythonOperator. Everything is clear with them: they send a bash command and a python function for execution, respectively.
- There are a huge variety of operators for submitting queries to various databases. Standard Postgres, MySQL, Oracle, Hive, Presto are supported. If for some reason there is no operator for your favorite database, you can use a more general JdbcOperator or write your own, Airflow allows it.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

Further, you can see how the duration of tasks changed during the day. In our case, this is the process of transferring data from Kafka to Hive with data quality verification. Plus, you can trace when the task for some reason took longer than usual.

How to Succeed in Airflow Development
Below are some tips to help you avoid getting shot in the foot when using Airflow:
- It is useful to keep each pipeline (or pipeline generator, more on that below) in a separate file. I immediately know which file I need to go to in order to look at the required pipeline or generator.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Since the beginning of using Airflow, we have kept the pipeline configs separate from the code. Initially, this was due to the peculiarities of the deployment scheme, but gradually this approach took root. And now we use configs wherever there is a hint of boilerplate. This especially concerns Spark jobs that we run from Docker. From this came the story with the declarative writing of pipelines.
The approach is that we have a directory with configs. Each config file contains one or several pipelines with their description: how they should work, when to start, what tasks are in it and in what order they should be performed.
I will show what the code for calling our pipeline generator looks like. At the entrance, he receives a directory with configs, a prefix and a class that will be responsible for filling the pipeline with tasks. Under the hood, the generator goes to the specified directory, finds the config files there, and creates tasks in these files for each pipeline and links them.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
This is what a typical config file looks like. To describe the configs, we use the HOCON format , which is a superset of JSON. It supports imports of other HOCON files and can refer to the values of other variables.
In the config at the pipeline level (attribution block), you can specify many parameters, but the most important are name, start_date and schedule_interval.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Here you can specify concurrency - how many tasks will run simultaneously in one run. Recently, we have added a block with a short markdown description of the pipeline here. Then it, along with the rest of the information about the pipeline, will go to Confluence (we implemented the sending using Foliant ). It turned out super-convenient: this way we save time for dug developers to create pages in Confluence.
Next comes the part that is responsible for the formation of tasks. First, in the connections block, we indicate from which connection in Airflow we need to take parameters for connecting to an external source - in the example, this is our DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
All necessary information such as user, password, URL and so on will be forwarded to the docker container as environment variables. In the Containers block, we indicate which tasks we will launch. Inside there is the name of the image, a list of connections used and a list of environment variables.
You may notice that Jinja templates appear in the values of some environment variables. To specify a queue in YARN, we use standard Airflow syntax to retrieve variable values. To indicate the launch date, we use the {{ds_nodash}} macro, which represents the date of their execution_date without hyphens. The config contains 3 more similar tasks, they are hidden for clarity.
Next, using tasks, we indicate how these tasks will be launched. You will notice that they are listed as a list in a list. This means that all 4 of these tasks will run in parallel with each other.
And one last thing: we specify on which base pipelines our current DAG depends. Strange numbers and letters at the end of the names of the basic dags are the schedule that we embed in the name of the pipeline. Thus, our pipeline will begin to fill only after the basic dags and the tasks specified in them are completed.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Full text of the config file
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
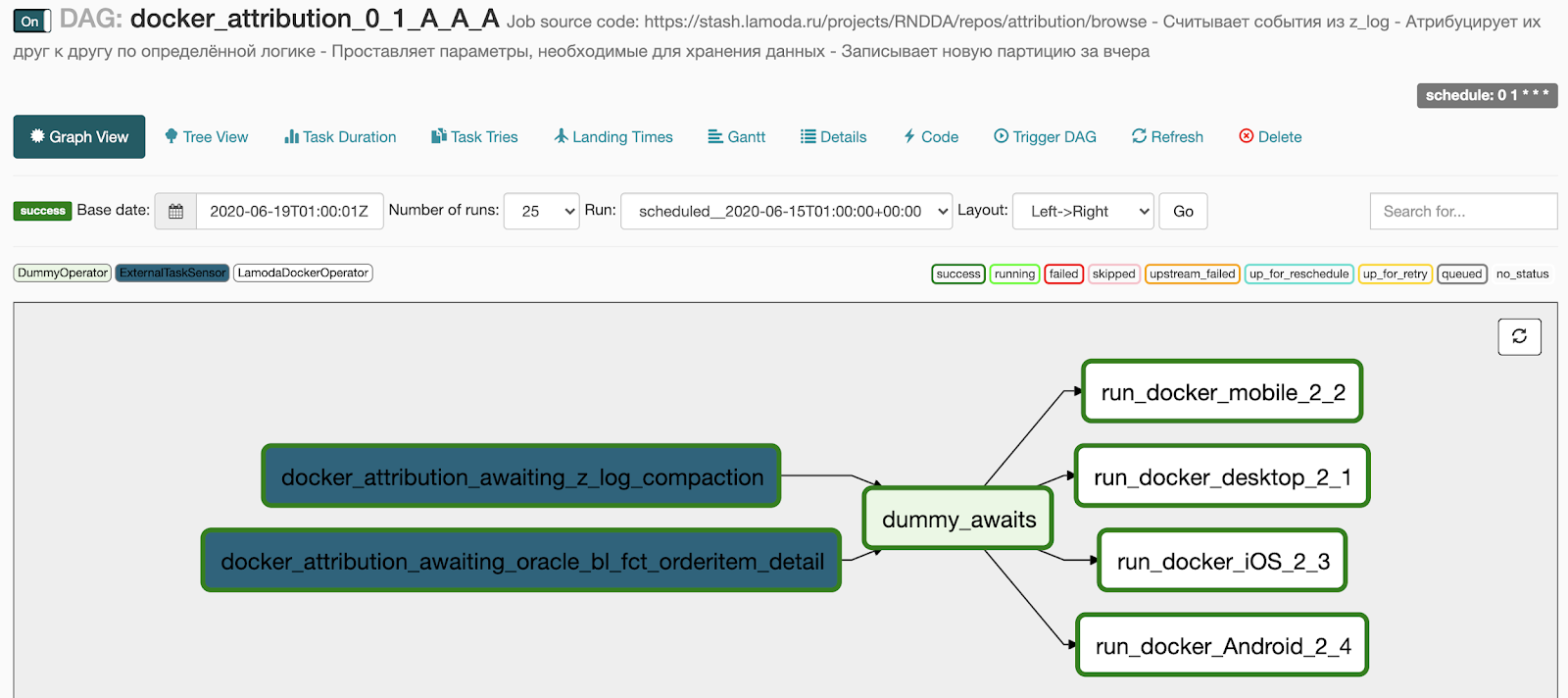
This is what we get after generation:
- 2 points in the awaits block turned into two sensors that are waiting for the execution of the basic pipeline,
- The 4 tasks that we specified in the docker block turned into 4 running tasks in parallel,
- we added a DummyOperator between the two blocks of operators so that there is no web of connections between tasks.
What do we want to do next
First, build a complete Feature environment. We now have one development stand for testing all of our pipelines. And before testing, you need to make sure the dev landscape is free now.
Recently, our team has expanded, and the number of applicants has increased. We have found a temporary solution to the problem and now let us know in Slack when we take dev. It works, but it's still a bottleneck in development and testing.
One option is to move to Kubernetes. For example, when creating a pull-request in master, you can raise a separate namespace in Kubernetes, where to deploy Airflow, deploy the code, then scatter variables, connections. After deployment, the developer will come to the newly created Airflow instance and test his pipelines. We have groundwork on this topic, but our hands did not get to the combat Kubernetes cluster, where we could run it all.
The second option for implementing the Feature environment is to organize a repository with a common develop branch, where developers' code is merged and automatically rolled out to the dev landscape. Now we are actively looking towards this scheme.
We also want to try to implement plugins - things to expand the functionality of the web interface. The main goal of plugins implementation is to build a Gantt chart at the level of the entire Airflow, that is, at the level of all pipelines, as well as build a dependency graph between different pipelines.
Why we chose Airflow
- Firstly, this is Python, where with the help of two loops and a couple of conditions, you can make an elegant, correctly working pipeline. And it won't need to be described in a huge chunk of XML. Plus, almost the entire Python ecosystem and its entire zoo of libraries are available out of the box, which can be used as you like.
- The absence of XML greatly simplifies code review. We wrote the pipeline code and configs for it, and everything is great, everything works. In fact, you can drag in XML or any other config format, but this is already a matter of taste.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.