
Graph databases are an important technology for database professionals. I try to keep up with innovations and new technologies in this area and, after working with relational and NoSQL databases, I see that the role of graph databases is growing. When working with complex hierarchical data, not only traditional databases, but also NoSQL are ineffective. Often, with an increase in the number of levels of links and the size of the base, there is a decrease in performance. And as the relationships become more complex, the number of JOINs also increases.
Of course, there are solutions in the relational model for working with hierarchies (for example, using recursive CTEs), but these are still workarounds. At the same time, the functionality of SQL Server graph databases allows you to easily process several levels of the hierarchy. Both the data model and the queries are simplified and therefore more efficient. The amount of code is significantly reduced.
Graph databases are an expressive language for representing complex systems. This technology is already quite widely used in the IT industry in areas such as social media, anti-fraud systems, IT network analysis, social recommendations, product and content recommendations.
The graph database functionality in SQL Server is suitable for scenarios in which the data is tightly coupled and has well-defined relationships.
Graph data model
A graph is a set of vertices (nodes) and edges (relationships). Vertices represent entities, and edges represent links, whose attributes can contain information.
A graph database models entities in the form of a graph, as defined in graph theory. Data structures are vertices and edges. Attributes are properties of vertices and edges. A link is a connection of vertices.
Unlike other data models, in graph databases, relationships between entities take precedence. Therefore, there is no need to calculate relationships using foreign keys or in some other way. You can create complex data models using only vertex and edge abstractions.
In the modern world, modeling relationships requires more and more sophisticated techniques. For modeling relationships, SQL Server 2017 offers graph database capabilities. Vertices and edges of the graph are represented as new types of tables: NODE and EDGE. A new T-SQL function called MATCH () is used to query the graph. Since this functionality is built into SQL Server 2017, it can be used in your existing databases without the need for any conversion.
Benefits of the graph model
Today, businesses and users alike are demanding applications that handle more and more data while expecting high performance and reliability. The presentation of data in the form of a graph offers a convenient means for handling complex relationships. This approach solves many problems and helps you get results within a given context.
It appears that in the future, many applications will benefit from the use of graph databases.
Data Modeling: From Relational to Graph Model
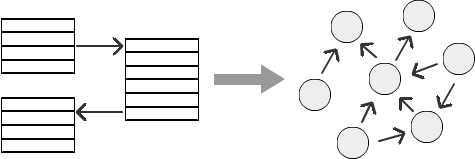
Example
Let's look at an example of an organizational structure with a hierarchy of employees: an employee reports to a manager, a manager reports to a senior manager, and so on. This hierarchy can have any number of levels, depending on a particular company. But as the number of levels increases, computing relationships in a relational database becomes more and more difficult. It is rather difficult to represent the hierarchy of employees, the hierarchy in marketing or social media connections. Let's see how SQL Graph can solve the problem of handling different levels of the hierarchy.
For this example, let's make a simple data model. Let's create an EMP employee table with an EMPNO identifier and a MGR column, indicating the identifier of the manager (manager) of the employee. All information about the hierarchy is stored in this table and can be queried using the columns EMPNO and MGR .
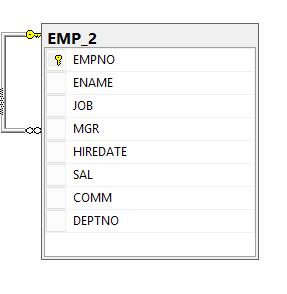
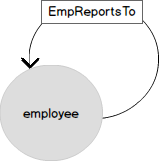
The following diagram shows the same org chart model with four levels of nesting in a more familiar form. Employees are the vertices of the graph from the EMP table . The entity "employee" is linked to itself by the link "submits" (ReportsTo). In graph terms, a link is an edge (EDGE) that connects the nodes (NODE) of employees.
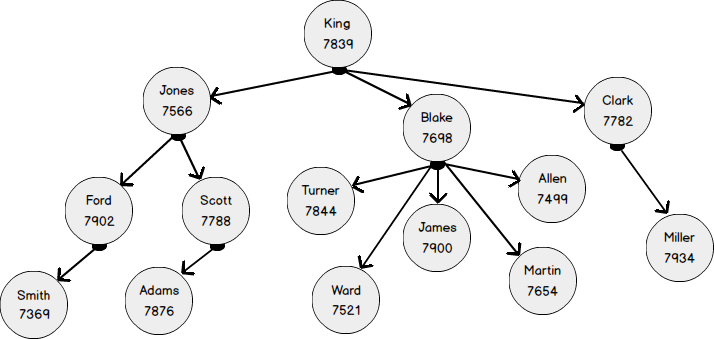
Let's create a regular EMP table and add the values there according to the above diagram.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)The figure below shows the employees:
- employee with EMPNO 7369 reports to 7902;
- employee with EMPNO 7902 obeys 7566
- employee with EMPNO 7566 obeys 7839
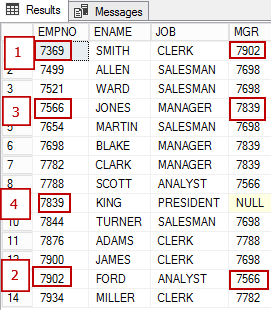
Now let's look at a graph representation of the same data. The node EMPLOYEE has several attributes and is associated with itself by the "obey" relationship (EmplReportsTo). EmplReportsTo is the name of the relationship.
The edge table (EDGE) can also contain attributes.
Create the EmpNode Node Table
The syntax for creating a node is pretty simple: the CREATE TABLE statement is appended with "AS NODE" at the end .
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Now let's transform the data from a regular table into a graph one. The next INSERT inserts data from the EMP relational table .
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp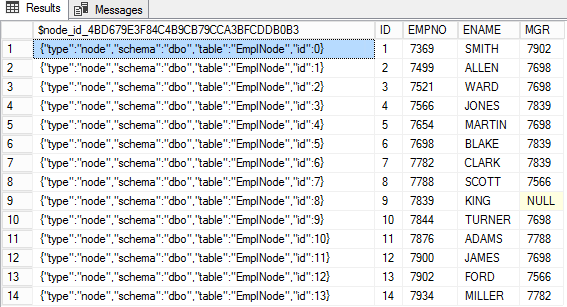
The node
$node_id_*ID is stored in a special column in the node table in the form of JSON. The remaining columns of this table contain the node attributes.
Create Edges (EDGE)
Creating an edge table is very similar to creating a node table, except that the keyword "AS EDGE" is used .
CREATE TABLE empReportsTo(Deptno int) AS EDGE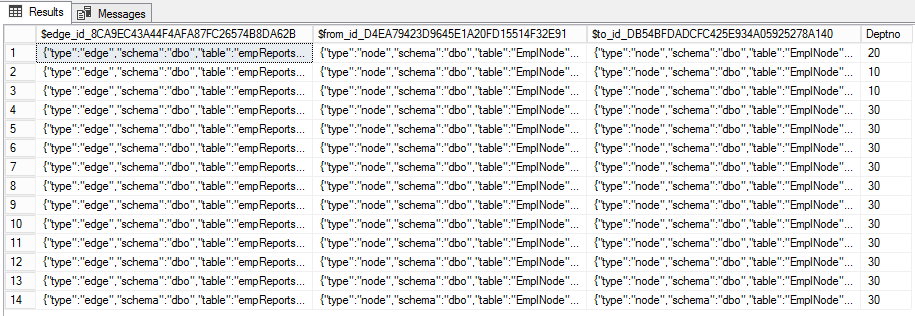
Now let's define the relationships between employees using the columns EMPNO and MGR . The org chart shows how to write INSERT .
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30);The default edge table has three columns. The first
$edge_idis the JSON ID of the edge. The other two ( $from_idand $to_id) represent communications between the nodes. In addition, ribs can have additional properties. In our case, this is Deptno .
System views
There are
sys.tablestwo new columns in the system view :
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%'
SSMS
Graph related objects are located in the Graph Tables folder. The node table icon is marked with a dot, and the edge table icon is marked with two connected circles (which looks a bit like glasses).

MATCH expression
The MATCH expression is taken from CQL (Cypher Query Language). It is an efficient way to query the properties of a graph. CQL starts with a MATCH expression .
Syntax
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasExamples
Let's take a look at a few examples.
The query below displays the employees to whom Smith and his manager report.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH'
The next query is for finding second-level employees and managers for Smith. If you remove the WHERE clause , then the result will display all employees.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH'
And finally, a request for third-level employees and managers.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH'
Now let's change direction to get Smith's bosses.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3)
Conclusion
SQL Server 2017 has established itself as a complete enterprise solution for various IT business challenges. The first version of SQL Graph is very promising. Even despite some limitations, there is already enough functionality to explore the capabilities of graphs.
The SQL Graph functionality is fully integrated into the SQL Engine. However, as mentioned, SQL Server 2017 has the following limitations:
No polymorphism support.
- .
- $from_id $to_id UPDATE.
- (transitive closure), CTE.
- In-Memory OLTP.
- (System-Versioned Temporal Table), .
- NODE EDGE.
- (cross-database queries).
- - (wizard) .
- GUI, Power BI.

:
- SQL Server bitmap-