We at Lyft decided to move our server infrastructure to Kubernetes, a distributed container orchestration system, to take advantage of the benefits that automation has to offer. They wanted a solid and reliable platform that could become the foundation for further development, as well as reduce overall costs while increasing efficiency.
Distributed systems can be difficult to understand and analyze, and Kubernetes is no exception in this regard. Despite its many benefits, we identified several bottlenecks when moving to CronJob , a system built into Kubernetes for performing repetitive tasks on a schedule. In this two-part series, we'll discuss the technical and operational drawbacks of Kubernetes CronJob when used in a large project and share with you our experience of overcoming them.
First, we will describe the shortcomings of Kubernetes CronJobs that we encountered when using them in Lyft. Then (in the second part) - we will tell you how we eliminated these shortcomings in the Kubernetes stack, increased usability and improved reliability.
Part 1. Introduction
Who will benefit from these articles?
- Kubernetes CronJob users.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
Today, our multi-tenant production environment has nearly 500 cron jobs that are called over 1500 times per hour.
Recurring, scheduled tasks are used extensively by Lyft for a variety of purposes. Before moving to Kubernetes, they ran directly on Linux machines using regular Unix cron. The development teams were responsible for writing the
crontabdefinitions and provisioning the instances that executed them using the Infrastructure As Code (IaC) pipelines, and the infrastructure team was responsible for maintaining them.
As part of a larger effort to containerize and migrate workloads to our own Kubernetes platform, we decided to move to CronJob *, replacing the classic Unix cron with its Kubernetes counterpart. Like many others, Kubernetes was chosen because of its vast advantages (at least in theory), including its efficient use of resources.
Imagine a cron task that runs once a week for 15 minutes. In our old environment, the machine dedicated to this task would be idle 99.85% of the time. In the case of Kubernetes, computational resources (CPU, memory) are used only during the call. The rest of the time, unused capacities can be used to launch other CronJob's, or simply scale-downcluster. Given the past way of running cron jobs, we would benefit a lot from moving to a model in which jobs are ephemeral.

Responsibility Boundaries for Developers and Platform Engineers in the Lyft Stack
After moving to the Kubernetes platform, development teams stopped allocating and operating their own compute instances. The platform team is now responsible for maintaining and operating compute resources and runtime dependencies in the Kubernetes stack. In addition, she is responsible for creating the CronJob objects themselves. Developers only need to configure the task schedule and application code.
However, it all looks good on paper. In practice, we have identified several bottlenecks when migrating from a well-studied traditional Unix cron environment to a distributed, ephemeral CronJob environment in Kubernetes.
* Although CronJob was and still has (as of Kubernetes v1.18) beta status, we found it to be quite satisfying to our needs at the time and also fit perfectly with the rest of the Kubernetes infrastructure toolkit we had ...
What is the difference between Kubernetes CronJob and Unix cron?
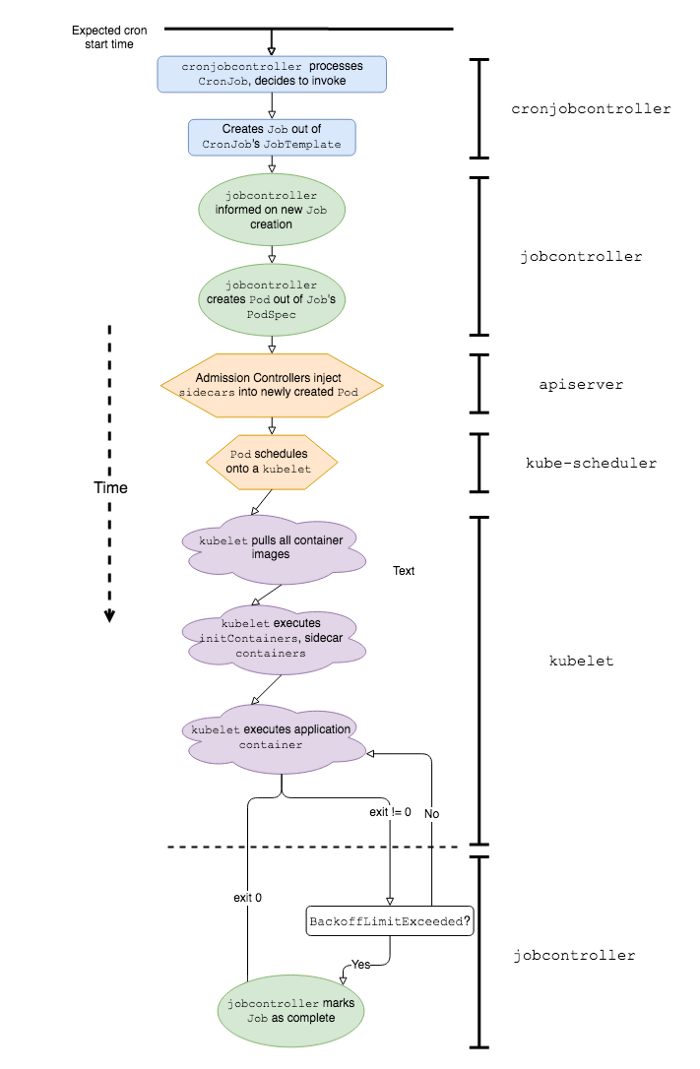
Simplified sequence of events and K8s software components involved in the work of Kubernetes CronJob
To better explain why working with Kubernetes CronJob in a production environment is associated with certain difficulties, let's first define how they differ from the classic. CronJob is supposed to work the same way as Linux or Unix cron jobs; however, there are actually at least a couple of major differences in their behavior: startup speed and crash handling .
Launch speed
Delay start (start delay) is defined as the time elapsed from the scheduled start cron until the actual beginning of the application code. In other words, if the cron is scheduled to start at 00:00:00 and the application starts running at 00:00:22, then the delay in starting that particular cron will be 22 seconds.
In the case of classic Unix crons, the startup delay is minimal. When the time is right, these commands are simply executed. Let's confirm this with the following example:
# date
0 0 * * * date >> date-cron.log
With a cron configuration like this, we will most likely get the following output in
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
On the other hand, Kubernetes CronJob can experience significant startup delays because the application is preceded by a number of events. Here are some of them:
-
cronjobcontrollerprocesses and decides to call the CronJob; -
cronjobcontrollercreates a Job based on the CronJob job specification; -
jobcontrollernotices a new Job and creates a Pod; - Admission Controller inserts sidecar container data into Pod specification *;
-
kube-schedulerplanning a Pod on kubelet; -
kubeletlaunches Pod (fetching all container images); -
kubeletstarts all sidecar containers *; -
kubeletstarts the application container *.
* These stages are unique to the Lyft Kubernetes stack.
We found that items 1, 5, and 7 make the most significant contribution to latency once we reach a certain scale of CronJob in the Kubernetes environment.
Delay caused by work cronjobcontroller'
To better understand where latency comes from, let's examine the inline source code
cronjobcontroller'. In Kubernetes 1.18, it cronjobcontrollerjust checks all CronJob's every 10 seconds and runs some logic on each one.
The implementation
cronjobcontroller'does this synchronously by making at least one additional API call for each CronJob. When the number of CronJob exceeds a certain number, these API calls begin to suffer from client-side constraints .
The 10-second polling cycle and client-side API calls significantly increase the delay in CronJob launch.
Scheduling pods with crons
Due to the nature of the cron schedule, most of them run at the beginning of the minute (XX: YY: 00). For example, the
@hourly(hourly) cron runs at 01:00:00, 02:00:00, etc. In the case of a multi-tenant cron platform with many crons running every hour, every quarter of an hour, every 5 minutes, etc., this leads to bottlenecks (hotspots) when multiple crons are started at the same time. We at Lyft noticed that one such place is the start of the hour (XX: 00: 00). These hotspots create a load and lead to additional limiting the frequency of requests in the components of the control layer involved in the execution of the CronJob, such as kube-schedulerand kube-apiserver, which leads to a noticeable increase in startup delay.
In addition, if you do not provision compute power for peak loads (and / or use compute instances of the cloud service), and instead use the cluster autoscaling mechanism to dynamically scale nodes, then the time taken to start nodes adds an additional contribution to startup latency. pods CronJob.
Pod launch: helper containers
Once the CronJob pod has been successfully scheduled for
kubelet, the latter should fetch and run the container images of all the sidecars and the application itself. Due to the specifics of launching containers in Lyft (sidecar containers start before application containers), the delay in starting any sidecar will inevitably affect the result, leading to an additional delay in starting the task.
Thus, delays at startup, prior to the execution of the required application code, coupled with a large number of CronJob's in a multi-tenant environment, lead to noticeable and unpredictable startup delays. As we will see a little later, in real life, such a delay can negatively affect the behavior of the CronJob, threatening to miss launches.
Container crash handling
In general, it is recommended to keep an eye on the work of crons. For Unix systems, this is fairly easy to do. Unix crones interpret the given command using the specified shell
$SHELL, and after the command exits (successful or not) that particular call is considered complete. You can track the execution of a cron on Unix using a simple script like this:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
In the case of Unix, cron
stat-and-logwill run exactly once for each cron call - regardless of $exitcode. Therefore, these metrics can be used to organize the simplest notifications about unsuccessful calls.
In the case of CronJob Kubernetes, where retry attempts on failures are defined by default, and the failure itself can be caused by various reasons (Job failure or container failure), monitoring is not so simple and straightforward.
Using a similar script in the application container and with Jobs configured to restart on failure, the CronJob will try to execute the task on failure, generating metrics and logs in the process, until it reaches BackoffLimit(max. number of retries). Thus, a developer trying to determine the cause of a problem will have to sort out a lot of unnecessary "garbage". In addition, the alert from the shell script in response to the first failure can also be a normal noise on which further actions cannot be based, since the application container can recover and successfully complete the task on its own.
You can implement alerts at the Job level, rather than at the application container level. For this, API level metrics for Job failures are available, such as
kube_job_status_failedfrom kube-state-metrics. The disadvantage of this approach is that the engineer on duty only becomes aware of the problem after the Job reaches the “final failure stage” and hits the limit BackoffLimit, which can happen much later than the first failure of the application container.
CronJob'
Substantial start-up delays and restart cycles introduce additional latency that can prevent Kubernetes CronJob from being re-executed. In the case of CronJob's that are called frequently, or those with runtimes significantly longer than the idle time, this additional delay can cause problems on the next scheduled call. If the CronJob has a policy
ConcurrencyPolicy: Forbidthat prohibits concurrency , the delay results in future calls not being completed on time and delayed.

An example of a timeline (from a cronjobcontroller's point of view) in which startingDeadlineSeconds is exceeded for a specific hourly CronJob: it skips its scheduled start and will not be called until the next scheduled time
There is also a more unpleasant scenario (we ran into it in Lyft), due to which CronJob's can completely skip calls, this is when CronJob is installed
startingDeadlineSeconds. In this scenario, if the startup delay exceeds startingDeadlineSeconds, the CronJob will skip starting entirely.
In addition, if
ConcurrencyPolicyCronJob is set to Forbid, the restart-on-failure-cycle of the previous call can also interfere with the next CronJob call.
Problems with operating Kubernetes CronJob in real-world conditions
Ever since we started migrating repetitive, calendar tasks to Kubernetes, it has been found that using the CronJob mechanism unchanged leads to unpleasant moments, both from the developer's point of view and from the platform team's point of view. Unfortunately, they began to negate the benefits and benefits for which we originally chose Kubernetes CronJob. We soon realized that neither the developers nor the platform team had the necessary tools at their disposal to exploit CronJob's and understand their intricate life cycles.
The developers tried to exploit their CronJob and configure them, but as a result they came to us with a lot of complaints and questions like these:
- Why is my cron not working?
- It looks like my cron has stopped working. How can you confirm that it is actually running?
- I didn't know that cron wasn't working and I thought everything was fine.
- How do I "fix" a missing cron? I can't just SSH login and run the command myself.
- Can you tell me why this cron seems to have missed multiple runs between X through Y?
- We have X (large number) crons, each with its own notifications, and it becomes rather tedious / difficult to maintain all of them.
- Pod, Job, sidecar - what kind of nonsense is this?
As a platform team , we were unable to answer questions like:
- How to quantify the performance of the Kubernetes cron platform?
- How will enabling additional CronJob's affect our Kubernetes environment?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
Debugging CronJob crashes is not an easy task. It often takes intuition to understand where failures occur and where to look for evidence. Sometimes these clues are quite difficult to obtain - like, for example, logs
cronjobcontroller', which are recorded only if the high level of detail is enabled. In addition, the tracks can simply disappear after a certain period of time, which makes debugging similar to the game "profit mole" (talking about it - approx pens..), - for example, Kubernetes Events for CronJob'ov, Job'ov and Pod'ov which by default are only kept for an hour. None of these methods are easy to use, and none of them scale well in terms of support as the number of CronJob's on the platform grows.
Also, sometimes Kubernetes juststops trying to execute the CronJob if it missed too many runs. In this case, it must be restarted manually. In real life, this happens much more often than you might imagine, and the need to manually fix the problem each time becomes quite painful.
This concludes my dive into the technical and operational problems that we encountered when using Kubernetes CronJob in a busy project. In the second part, we will talk about how we eliminated Kubernetes in our stack, improved usability and improved the reliability of CronJob.
Part 2. Introduction
It became clear that Kubernetes CronJob, unchanged, cannot become a simple and convenient replacement for their Unix counterparts. To confidently transfer all our crones to Kubernetes, we needed not only to eliminate the technical shortcomings of CronJob's, but also to improve the usability of working with them . Namely:
1. Listen to the developers in order to understand the answers to what questions about crones they are most worried about. For example: Has my cron started? Was the application code executed? Was the launch successful? How long did the cron run? (How long did the application code take?)
2. Simplify platform maintenance by making CronJob's more understandable, their life cycle more transparent, and the platform / application boundaries clearer.
3. Supplement our platform with standard metrics and alerts to reduce the amount of custom alert configuration and reduce the number of duplicate cron bindings that developers have to write and maintain.
4. Develop tools for easy crash recovery and testing new CronJob configurations.
5. Fix long-standing technical problems in Kubernetes , such as a TooManyMissedStarts bug that requires manual intervention to fix and causes a crash in one critical failure scenario ( when startingDeadlineSeconds is not set ) going unnoticed.
Decision
We solved all these problems as follows:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

An example of a dashboard generated by the platform for monitoring a specific CronJob
We have added the following metrics to the Kubernetes stack (they are defined for all CronJob in Lyft):
1.
started.count- this counter is incremented when the application container is first launched when the CronJob is called. It helps answer the question, “ Did the application code run? ".
2.
{success, failure}.count- these counters are incremented when a particular CronJob call reaches the terminal state (that is, the Job has finished its job and jobcontrollerno longer tries to execute it). They answer the question: “ Was the launch successful? ".
3.
scheduling-decision.{invoke, skip}.count- these countersallow you to find out about the decisions that are made cronjobcontrollerwhen calling the CronJob. In particular, it skip.counthelps to answer the question: “ Why isn't my cron working? ". The following labels act as its parameters reason:
-
reason = concurrencyPolicy-cronjobcontrollermissed the call to CronJob, because otherwise it would break itConcurrencyPolicy; -
reason = missedDeadline-cronjobcontrollerrefused to call CronJob, because it missed the call window specified.spec.startingDeadlineSeconds; -
reason = errorIs a common parameter for all other errors that occur when trying to call a CronJob.
4.
app-container-duration.seconds- This timer measures the lifetime of the application container. It helps answer the question: “ How long did the application code run? ". In this timer, we deliberately did not include the time required for pod scheduling, launching sidecar containers, etc., since they are the responsibility of the platform team and are included in the launch delay.
5.
start-delay.seconds- This timer measures the start delay. This metric, when aggregated across the entire platform, allows engineers who maintain it not only to evaluate, monitor and tune platform performance, but also serves as a basis for determining SLOs for parameters such as startup delay and maximum cron schedule frequency.
Based on these metrics, we've created default alerts. They notify developers when:
- Their CronJob did not start on schedule (
rate(scheduling-decision.skip.count) > 0); - Their CronJob failed (
rate(failure.count) > 0).
Developers no longer need to define their own alerts and metrics for crons in Kubernetes - the platform provides their ready-made counterparts.
Running crons when needed
We adapted it
kubectl create job test-job --from=cronjob/<your-cronjob>to our internal CLI tool. Lyft engineers use it to interact with their services on Kubernetes to call CronJob when needed to:
- recovery from intermittent CronJob crashes;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
We have fixed a bug with TooManyMissedStarts so that now CronJob's do not "hang" after 100 consecutive missed starts. This patch not only removes the need for manual intervention, but allows you to actually track when the time is
startingDeadlineSeconds exceeded . Thanks to Vallery Lancey for designing and building this patch, Tom Wanielista for helping design the algorithm. We opened a PR to bring this patch to the main Kubernetes branch (however, it was never adopted, and closed due to inactivity - approx. Transl.) .
Implementing cron monitoring

At what stages of the life cycle of Kubernetes CronJob we added metrics export mechanisms
Alerts that don't depend on cron schedules
The trickiest part of implementing missed cron call notifications is handling their schedules ( crontab.guru came in handy for decrypting them ). For example, consider the following schedule:
# 5
*/5 * * * *
You can make the counter for this cron increment every time it exits (or use a cron binding ). Then, in the notification system, you can write a conditional expression of the form: "Look at the previous 60 minutes and let me know if the counter increases by less than 12". Problem solved, right?
But what if your schedule looks like this:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
In this case, you will have to tinker with the condition (although, maybe your system has a notification function only for business hours?). Be that as it may, these examples illustrate that binding notifications to cron schedules has several disadvantages:
- When you change the schedule, you have to make changes to the notification logic.
- Some cron schedules require quite complex queries to replicate using time series.
- There needs to be some kind of "waiting period" for crones that do not start their work exactly in time to minimize false positives.
Step 2 alone makes generating notifications by default for all crones on the platform a very difficult task, and step 3 is especially relevant for distributed platforms like Kubernetes CronJob, in which launch delay is a significant factor. In addition, there are solutions that use " dead man 's switches ", which again brings us back to the need to tie the alert to the cron schedule, and / or anomaly detection algorithms that require some training and do not work immediately for new CronJob or changes in their timetable.
Another way to look at the problem is to ask yourself: what does it mean that cron should have started but it didn't?
In Kubernetes, if you forget about bugs in
cronjobcontroller'or the possibility of a fall in the control plane itself (although you should immediately see this if you track the state of the cluster correctly) - this means that cronjobcontrollerthe CronJob evaluated and decided (according to the cron's schedule) that it should be called, but for some reason for the reason I deliberately decided not to .
Sounds familiar? This is exactly what our metric does
scheduling-decision.skip.count! Now we just need to track the change rate(scheduling-decision.skip.count)to notify the user that his CronJob should have been triggered, but it did not.
This solution decouples the cron schedule from the notification itself, providing several benefits:
- Now you do not need to reconfigure alerts when changing schedules.
- There is no need for complex time requests and conditions.
- You can easily generate default alerts for all CronJob's on the platform.
This, combined with the other time series and alerts mentioned earlier, helps to create a more complete and understandable picture of the state of the CronJob.
Implementing a Start Delay Timer
Due to the complex nature of the CronJob life cycle, we needed to carefully consider the specific points of the toolkit placement on the stack in order to measure this metric reliably and accurately. As a result, it all came down to fixing two points in time:
- T1: when cron should be started (according to its schedule).
- T2: When the application code actually starts executing.
In this case
start delay(start delay) = 2 — 1. To fix the moment T1, we included the code in the cron call logic in the cronjobcontroller'. It records the expected start time like .metadata.Annotationthe Job objects it cronjobcontrollercreates when the CronJob is called. It can now be retrieved using any API client using a normal request GET Job.
With T2, everything turned out to be more complicated. Since we need to get the value as close to real as possible , T2 must coincide with the moment when the container with the application is launched for the first time . If you shoot T2 at anywhen the container is started (including restarts), then delaying the launch in this case will include the running time of the application itself. Therefore, we decided to assign another
.metadata.AnnotationJob object whenever we discovered that the application container for a given Job first received a status Running. Thus, in essence, a distributed lock was created, and future starts of the application container for this Job were ignored (only the moment of the first start was saved ).
results
After rolling out new functionality and fixing bugs, we received a lot of positive feedback from the developers. Now developers using our Kubernetes CronJob platform:
- no longer have to puzzle over their own monitoring tools and alerts;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
In addition, platform maintenance engineers now have a new parameter ( start delay ) to measure user experience and platform performance.
Finally (and perhaps our biggest win), by making CronJob's (and their states) more transparent and traceable, we've greatly simplified the debugging process for developers and platform engineers. They can now debug together using the same data, so it often happens that developers find the problem on their own and solve it using the tools provided by the platform.
Conclusion
Orchestrating distributed, scheduled tasks is not easy. CronJob Kubernetes is just one way to organize it. Although they are far from ideal, CronJob's are quite capable of working in global projects, if, of course, you are ready to invest time and effort in improving them: increasing observability, understanding the causes and specifics of failures, and supplementing with tools that make it easier to use.
Note: there is an open Kubernetes Enhancement Proposal (KEP) to fix the shortcomings of CronJob and translate their updated version to GA.
Thanks to Rithu John , Scott Lau, Scarlett Perry , Julien Silland, and Tom Wanielista for their help in reviewing this series of articles.
PS from translator
Read also on our blog:
- " A visual guide to troubleshooting in Kubernetes »;
- " 6 entertaining system bugs in the operation of Kubernetes [and their solution] ";
- “ Success stories of Kubernetes in production. Part 6: BlaBlaCar ".