
With the transition to self-isolation in March this year, we, like many companies, have moved all our grocery events online. Well, you remember this wonderful picture about webinars with monkeys. Over the past six months, only on the topic of data centers, for which my team is responsible, we have accumulated about 25 2-hour recorded webinars, 50 hours of video in total. The problem that has risen in full growth is how to understand in which video to look for answers to certain questions. The catalog, tags, a short description are good, well, we finally found that there are 4 two-hour videos on the topic, and then what? Watch on rewind? Is it possible somehow differently? And if you act in a fashionable way and try to screw the AI?
Spoiler for the impatient : I couldn't find a complete miracle system or assemble it on my knee, and then there would be no point in this article. But as a result of several days (or rather evenings), research, I got a working MVP, which I want to tell you about. The purpose of the article is to look at the level of interest in the issue, get advice from knowledgeable people, and perhaps find someone else who has the same problem.
What i want to do
At first glance, everything looked simple - you take a video, run it through the neural network, get a text, then look for a fragment in the text that describes the topic of interest. It would be even more convenient to search all videos in the catalog at once. In fact, it has been invented to upload transcripts of the text along with the videos for a long time, Youtube and most educational platforms know how to do this, although it is clear that people there edit these texts. You can quickly scan the text with your eyes and understand if there is an answer to the desired question. Probably, from a convenient functionality, it would not hurt to be able to poke at the place of interest in the text and listen to what the lecturer says and shows there, this is also not difficult if there is a markup of words in time, where they are in the text. Well, I was dreaming about possible directions of development, let's talk at the end,and now let's try to simply implement the chain as efficiently as possible
video file -> text fragment -> fuzzy text search .
At first I thought, since everything is so simple, and this case has been talked about for 4 years at all conferences on AI, such systems should exist ready-made. A couple of hours of searching and reading articles showed that this was not the case. Video is mainly used to look for faces, cars and other visual objects (masks / helmets), and audio - songs, tracks, as well as the tone / intonation of the speaker, as part of solutions for call centers. We managed to find only this mention of the Deepgram system . But she, unfortunately, does not have support for the Russian language. Also, Microsoft has very similar functionality in Streams , but nowhere did I find a mention of support for the Russian language, apparently, it is not there either.
Ok, let's reinvent. I am not a professional programmer (and, by the way, I will gladly accept constructive criticism on the code), but from time to time I write something “for myself”. Neural networks that can convert speech to text are called (surprise surprise), speech-to-text . If you can find a public speech-to-text service, you can use it to “digitize” speech in all webinars, and then make a fuzzy search in the text - an easier task. I confess that at first I did not think to "climb into the cloud", I wanted to collect everything locally, but after reading this article on Habré, I decided that speech recognition is really better done in the cloud.
Looking for cloud services for speech-to-text
The search for services capable of doing speech-to-text showed that there are a lot of such systems, including those developed in Russia, there are also global cloud providers like Google , Amazon , MS Azure among them . Descriptions of several services, including Russian-language ones , are here . In general, the first 20 lines in the search engine results will be unique. But there is another snag - I would like to launch this system into production in the future, this is a cost, and I work for Cisco, which globally has contracts with leading clouds. So from the whole list, I decided to consider only them for now.
So my list has been reduced to Google , Amazon , Azure ,IBM Watson (links to titles are the same as in the table below). All services have APIs through which they can be used. After analyzing the rest of the possibilities, I compiled a small table:

IBM Watson left the race at this stage, since all the recordings I have in Russian, it was decided to test the rest of the providers in a short excerpt from the webinar. I set up accounts in AWS and Azure. Looking ahead, I will say that Microsoft turned out to be a tough nut to crack in terms of setting up an account. I worked from a corporate network that "lands" on the Internet somewhere in Amsterdam, during the registration process I was asked twice if I was sure that my address was Russia, after which the system displayed a message that the account was administratively blocked "pending clarification" ... After 5 days, while I was writing this article, the situation has not changed, so I haven't been able to test Azure yet, which is a pity! I understand - security, but this has not yet allowed me to try the service. I will try to do this later, when the situation is resolved.
Separately, I would like to test this function in Yandex.Cloud, their recognition of Russian speech, in theory, should be the best. But, unfortunately, on the test access page of the service there is only the ability to "say" the text, file download is not provided. So, we will postpone together with Azure in the second place.
So, there are Google and Amazon, let's test it soon! Before writing any code, you can check and compare everything by hand, both providers, in addition to the API, have an administrative interface. For the test, I first prepared a 10-minute fragment of a general nature, if possible, with a minimum of specialized terminology. But then it turned out that Google supports a fragment of up to 1 minute in test mode, so I used this fragment of 57 seconds long to compare services .
- Google , .
- AWS Transcribe AWS, . AWS Transcribe 1 . , , AWS S3. ,
Based on the results of the work, both services issue the recognized text, you can compare the results of their work on a one-minute interval.
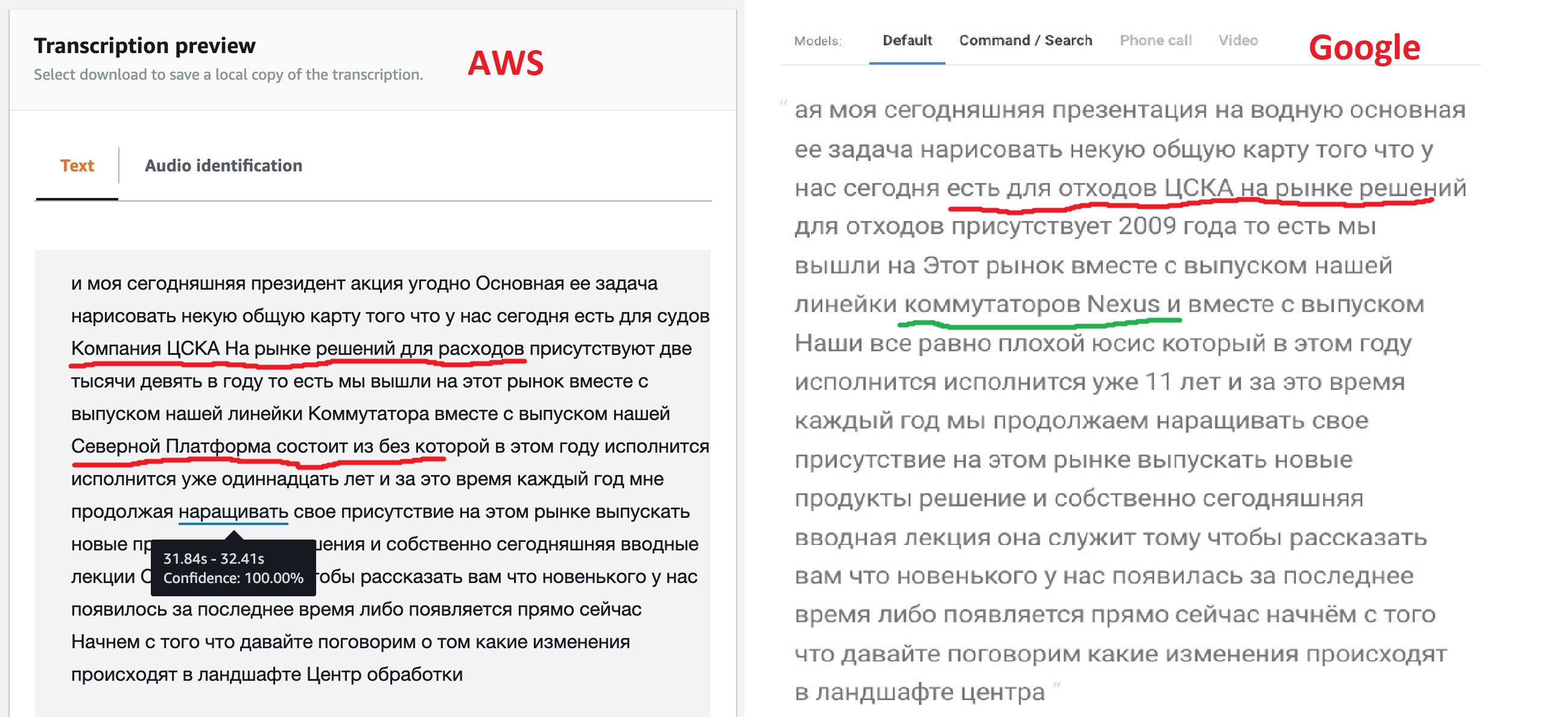
The result, frankly speaking, is not as expected, but it's not for nothing that the models provide different options for their customization. As we can see, the Google engine "out of the box" recognized most of the text more clearly, it also managed to see the names of some products, although not all. This suggests that their model allows for multilingual text. Amazon (later this was confirmed) does not have such an opportunity - they said Russian, which means we will sing: "Kin babe lom" and period!
But the ability to get tagged JSON that Amazon provides seemed very interesting to me. After all, this will allow in the future to implement a direct transition to the part of the file where the desired fragment was found. Perhaps Google also has such a function, because all speech recognition neural networks work this way, but a cursory search in the documentation did not manage to find this feature.

If you look at this JSON, you can see that it consists of three sections: the translated text (transcript), an array of words (items), and a set of segments (segments). For an array of words and segments for each element, its start and end times are indicated, as well as the neural network's confidence (confidence) that it correctly recognized it.
Teaching a neural network to understand data centers
So, at the end of this stage, I decided to choose Amazon Transcribe for further experiments and try to set up a learning model. And if you can't achieve stable recognition - deal with Google. Further tests were carried out on a 10 minute fragment.
AWS Transcribe has two options to tune what the neural network recognizes, and a couple more features for post-processing text:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
So, I decided to make my own word for the text. Obviously, it will include words such as "network, servers, profiles, data center, device, controller, infrastructure." After 2-3 tests, my vocabulary grew to 60 words. This dictionary must be created in a regular text file, one word per line, all in capital letters. There is also a more complex option ( described here ) with the ability to specify how the word is pronounced, but at the initial stage I decided to do with a simple list.
Before using a dictionary, you need to create it. On the Custom vocabulary tab in Amazon Transcribe, click Create Vocabulary , load the text of our file, specify the Russian language, answer the rest of the questions, and the process of creating a dictionary begins. Once he's outProcessing becomes Ready - the dictionary can be used.
The question remains - how to recognize "English" terms? Let me remind you that the dictionary only supports one language. At first I thought to create a separate dictionary with English terms, and run the same text through it. When terms like Cisco , VLAN , UCS are detectedetc. c probability rate 100% - take them for the given time fragment. But I’ll say right away that it didn’t work, the English language analyzer did not recognize more than half of the terms in the text. After thinking, I decided that this is logical, since we pronounce all these terms with a "Russian accent", even the Anglo-Americans do not understand us the first time. This prompted the idea to simply add these terms to the Russian dictionary according to the principle "as it is heard, so it is written." Cisco , usies , eisiai , vilan , viikslan - after all, we, in all honesty, say so when we communicate with each other. This increased the dictionary by a couple of dozen words, but looking ahead, it improved the recognition quality by an order of magnitude!
As the saying goes, “a good thought comes after,” the first dictionary has already been created, so I decided to create another one, adding all the abbreviations to it, and compare what happens.
Starting recognition with a dictionary is just as simple, in the Transcribe service on the Transcription job tab, select Create job , specify the Russian language, and do not forget to specify the dictionary we need. Another useful action - you can ask the neural network to give us several alternative search results, the Alternative results - Yes item , I set 3 alternative options. Later, when I do fuzzy text searches, this will come in handy.
The broadcast of a 10-minute piece of text takes 4-5 minutes, so as not to waste time, I decided to write a small tool that will facilitate the process of comparing the results. I will display the final text from the JSON file in the browser, simultaneously highlighting the “reliability” of the detection of individual words by the neural network (the same confidence parameter ). I have three options for the resulting text - the default translation, a dictionary without terms, and a dictionary with terms. Let all three texts be displayed simultaneously in three columns. I highlight words with reliability above 95% in green, from 95% to 70% in yellow, below 70% in red. The hastily compiled code of the resulting HTML page is below, the JSON files should be in the same directory as the file. File names are specified in the FILENAME1 variables, etc.
HTML page code to view results
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
I download the asrOutput.json files for all three tasks, rename them as written in the HTML script, and this is what happens.

It is clearly seen that the addition of Russian-language terms allowed the neural network to more accurately recognize specific terms - " service profile ", etc. And the addition of Russian transcription in the second step turned CSKA into cisco . The text is still rather "dirty", but for my context search task it should already be suitable. As new webinars are added and read, the vocabulary will gradually expand, this is a process of maintaining such a system that should not be forgotten.
Fuzzy search in recognized text
There are probably a dozen approaches to solving the problem of fuzzy search, for the most part they are based on a small set of mathematical algorithms, such as, for example, Levenshtein distance. good article about this , one more and one more . But I wanted to find something ready, like launched and works.
From ready-made solutions for local document search, after a little research, I found a relatively old project SPHINX, also the possibility of full-text search, it seems, is in PostgreSQL, it is written about this HERE . But most of the materials, including in Russian, were found about Elasticsearch . After reading good start-up and setup guides likeThis post or this lesson , here's another , as well as the documentation and API manual for Python , I decided to use it.
For all local experiments, I have been using Docker for a long time , and I highly recommend everyone who for some reason has not figured it out yet to do this. In fact, I try not to run anything other than development environments, browsers and "viewers" in the local operating system. Apart from the absence of compatibility issues, etc. this allows you to quickly try out a new product and see if it works well.
We download the container with Elasticsearch and run it with two commands:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
After starting the container,
http://localhost:9200the elastic interface appears at the address , it can be accessed using a browser or the REST API of a POSTMAN tool. But I found a handy Chrome plugin .
This is what the plugin window looks like with the example about funny kittens described in one of the guides above .
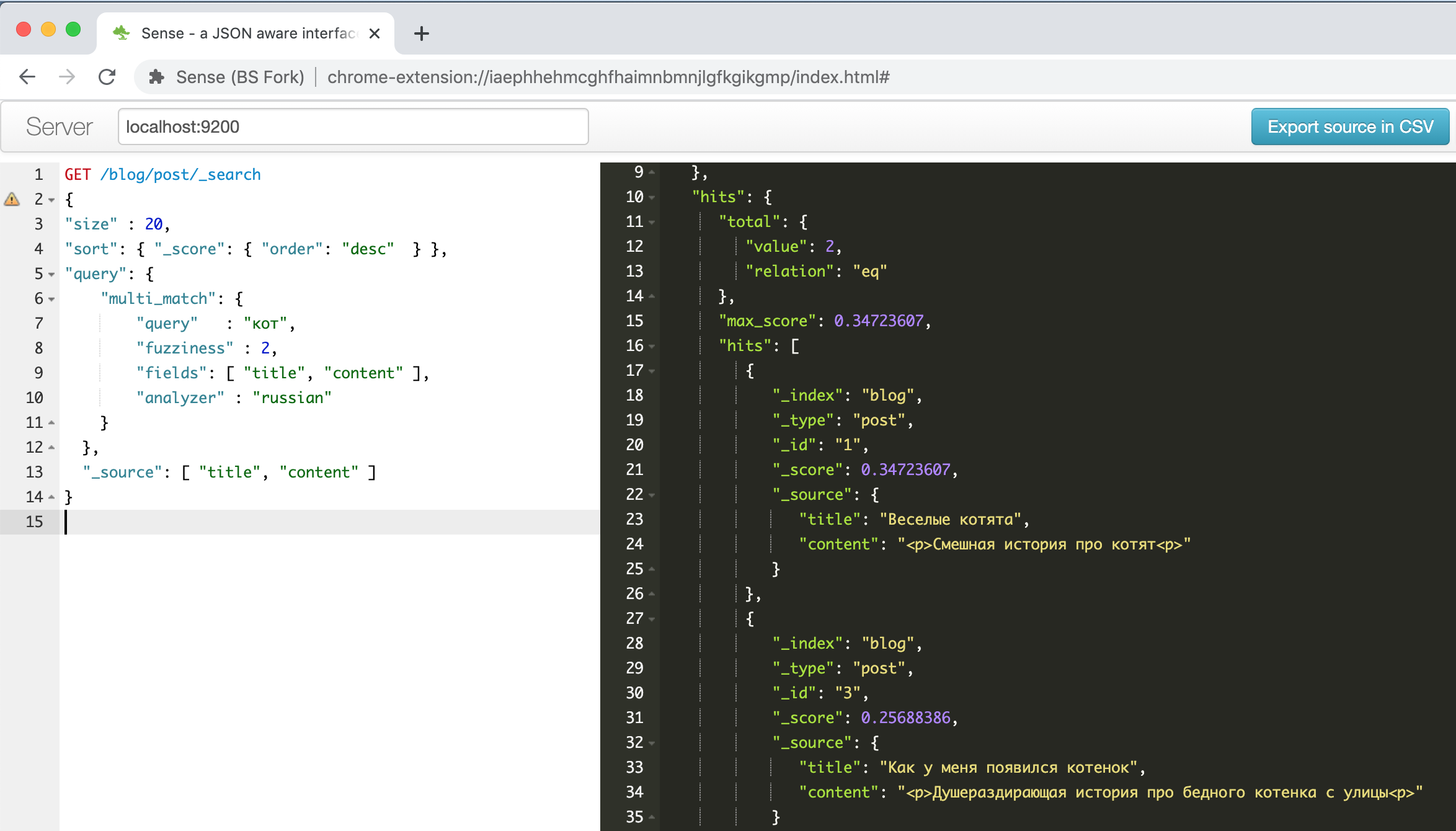
On the left is a request - on the right is an answer, autocomplete, syntax highlighting, autoformatting - what else is needed to be productive! In addition, this plugin can recognize the CURL command line format in the text pasted from the clipboard and format it correctly, for example, try pasting the line
" curl -X GET $ ES_URL " and see what happens. A handy thing, in general.
What and how will I store and search?Elasticsearch takes all JSON documents and stores them in structures called indexes. There can be as many different indexes as you like, but one index can contain homogeneous data and documents, with a similar structure of fields and the same approach to search.
To investigate the possibilities of fuzzy search, I decided to download and search the phrase (segments) section of the transcription file obtained in the previous step. In the segments section of the JSON file, data is stored in the following format:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
I want to increase the likelihood of a successful search, so I will upload all alternative options to the database for search, and then from the found fragments choose the one with the higher total confidence.
To reformat and load a JSON document into Elasticsearch, I use a small Python script, the script logic is as follows:
- First, we go through all the elements of the segments section and all alternative transcription options
- For each transcription option, we consider its total recognition confidence, I just take the arithmetic mean for individual words, although, probably, in the future this needs to be approached more carefully
- For each alternative transcription option, load a record of the form into Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Python script that loads records from a JSON file into Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
If you don't have Python, don't worry, Docker will help us again. I usually use a container with a Jupyter notebook - you can connect to it with a regular browser and do whatever you need to do, the only thing you need to think about saving the results, since all information is lost when the container is destroyed. If you haven’t worked with this tool before, then here is a good article for beginners , by the way, you can safely skip the section about installation.We
start a container with a Python notebook with the command:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
And we connect to it with any browser at the address that we see on the screen after the successful launch of the script, this is
http://127.0.0.1:8888with the specified security key.
We create a new notebook, in the first cell we write:
!pip install elasticsearch
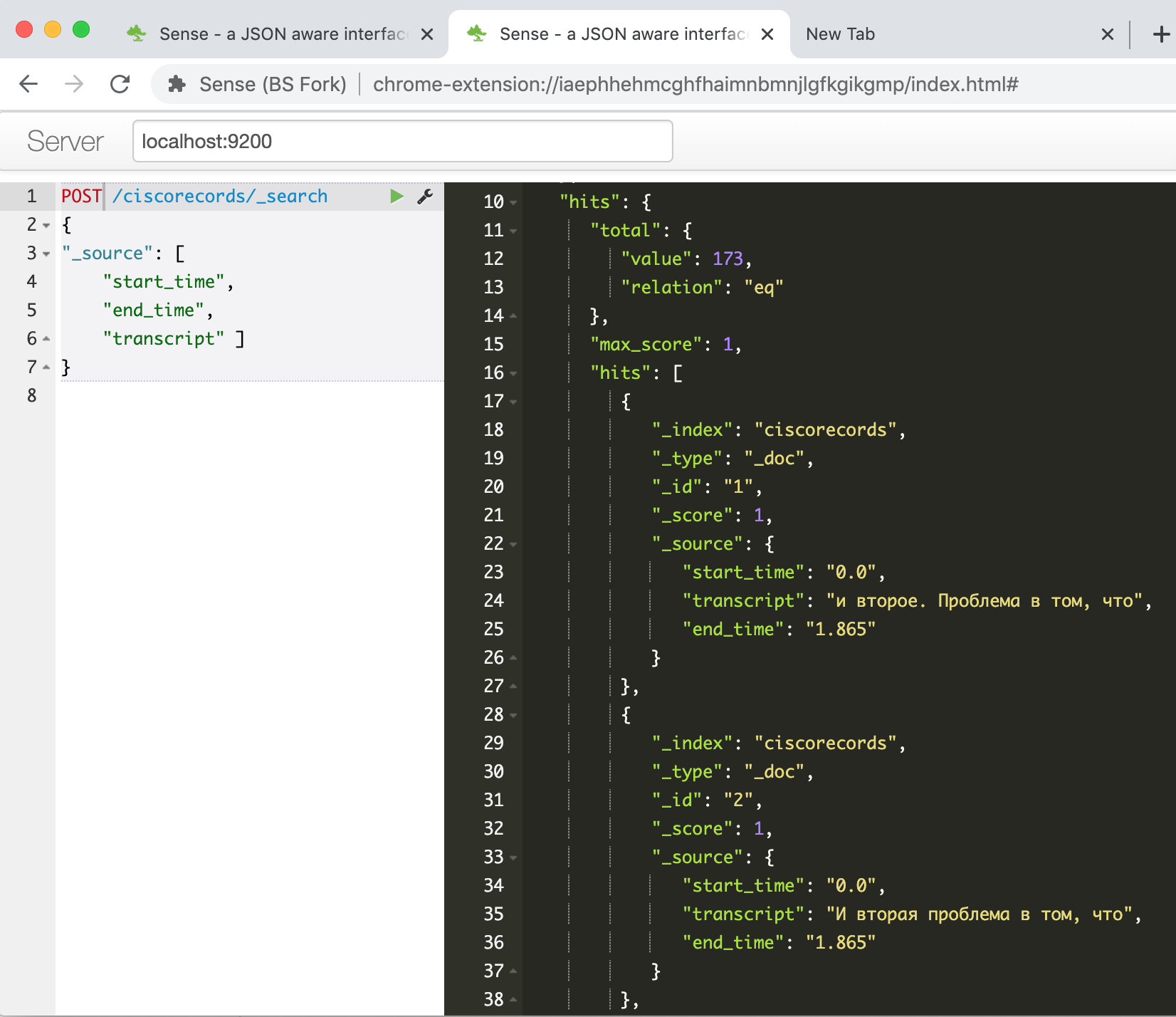
Run, wait until the package for working with ES through the API is installed, copy our script into the second cell and run it. After its work, if everything is successful, we can check in the Elasticsearch console that our data has been loaded successfully. We enter the command
GET /ciscorecords/_searchand see our loaded records in the response window, a total of 173 pieces, as the hits.total.value field tells us .
Now is the time to try fuzzy search - that's what it was all about. For example, to search for the phrase "core of the data center network", you need to give the following command:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
We get as many as 47 results!

No wonder, since most of them are different variations of the same fragment. Let's write another script to select from each segment one record with the highest confidence value.
Python script to query the Elasticsearch database
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Output example:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
We see that the results have become much smaller, and now we can view them and select the one that interests us the most.
Also, since we have the start and end time of the video fragment, we can make a page with a video player and programmatically "rewind" it to the fragment of interest.
But I will put this task in a separate article if there is interest in further publications on this topic.
Instead of a conclusion
So, within the framework of this article, I showed how I solved the problem of building a text search system using a video tool with recordings of webinars on technical topics. The result is what is usually called MVP, i.e. the minimum working algorithm that allows you to get a result and proves that the result is, in principle, achievable with existing technologies.
There is still a long way to go to the final product, from ideas that can be implemented in the near future:
- Screw on the video player so that you can listen to, view the found fragment
- Think about the possibility of text editing, while you can leave an anchor to the text of words recognized by 100%, edit only fragments where the quality of recognition "sags"
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
If you have any questions / comments, I will be glad to answer them, and I will also be glad to hear any suggestions to improve or simplify the process as a whole. This is my first technical article for Habr, I really hope that it turned out useful and interesting.
Good luck to everyone in your creative search, and may the Force be with you!