
The last years of deep learning have been a continuous series of achievements: from defeating people in the game of Go to world leadership in image recognition, voice recognition, text translation and other tasks. But this progress has been accompanied by an insatiable increase in the appetite for computing power. A group of scientists from MIT, Yeonse University (Korea) and Brasilia University have published a meta-analysis of 1,058 scientific papers on machine learning . It clearly shows that progress in machine learning (ML) is a derivative of the computing power of the system . Computer performance has always limited the functionality of ML, but now the needs of new ML models are growing much faster than computer performance.
The study demonstrates that advances in machine learning are, in fact, little more than a consequence of Moore's Law. And for this reason, many ML problems will never be solved due to the physical limitations of the computer.
The researchers analyzed scientific papers on Image Classification (ImageNet), Object Recognition (MS COCO), Question Answering (SQuAD 1.1), Named Entity Recognition (COLLN 2003), and Machine Translation (WMT 2014 En-to-Fr).

Computing queries ML, log scale
Progress in all five areas has been shown to be highly dependent on increased computing power. Extrapolating this relationship makes it clear that progress in these areas is rapidly becoming economically, technically and environmentally unsustainable. Thus, further progress in these applications will require significantly more computationally efficient methods.
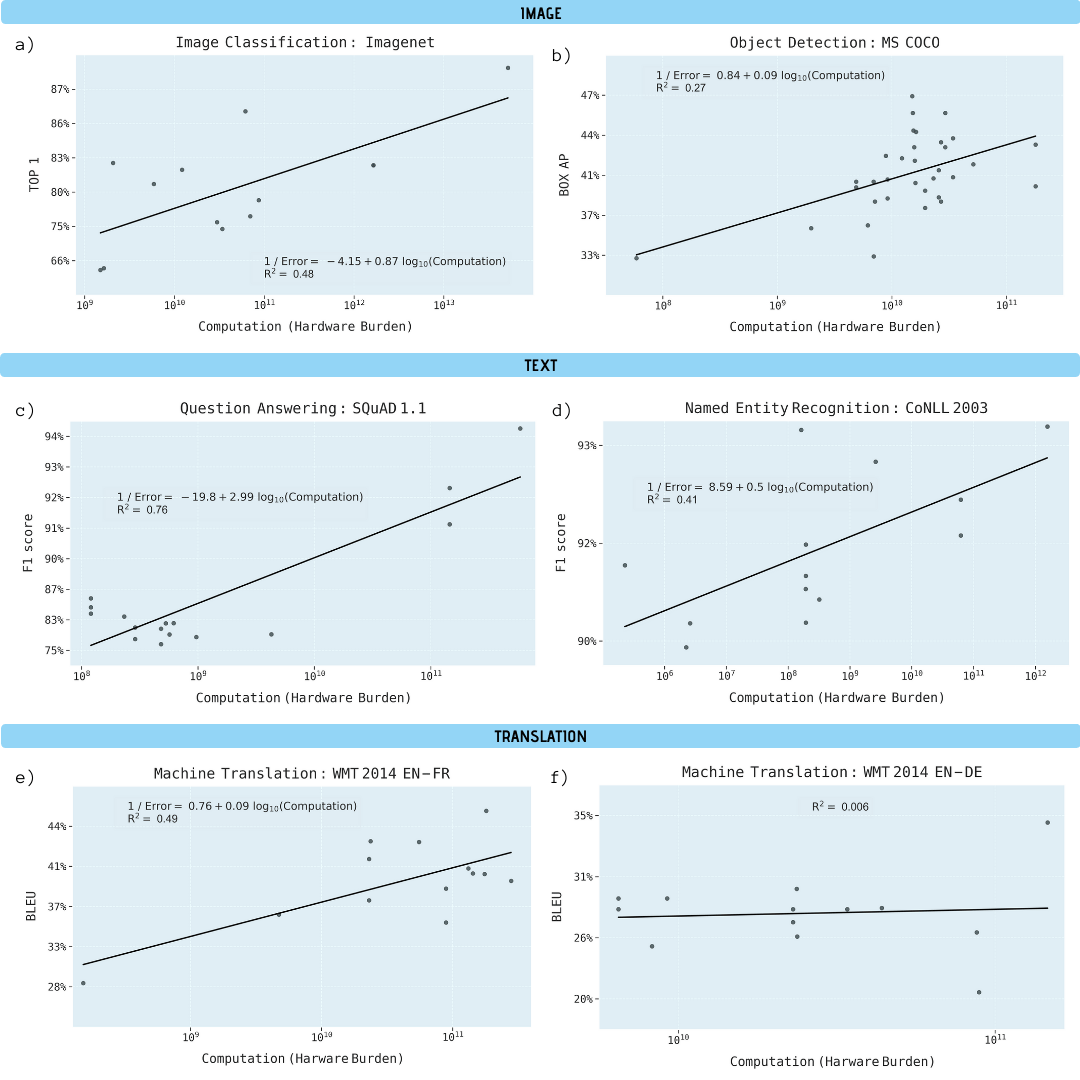
Performance improvement in various machine learning tasks as a function of the computational power of the learning model (in gigaflops)
Why is machine learning so dependent on computational power
There are important reasons to believe that deep learning is inherently more computationally dependent than other methods. In particular, due to the role of hyperparametrization and how the system is scaled up, when additional training data is used to improve the quality of the result (for example, to reduce the rate of classification errors, the root mean square error of regression, etc.).
It has been proven that significant advantages are provided by hyperparametrization, that is, the implementation of neural networks with the number of parameters more than the number of data points available for its training. Classically this would lead to overfitting. But stochastic gradient optimization techniques provide a regularizing effect at the expense of early stopping, putting neural networks into interpolation mode where the training data fits almost exactly, while still maintaining reasonable predictions at intermediate points. An example of large-scale networks with hyperparametrization is one of the best pattern recognition systems NoisyStudent , which has 480 million parameters for 1.2 million ImageNet data points.
The problem with hyperparametrization is that the number of deep learning parameters must grow as the number of data points grows. Since the cost of training a deep learning model scales with the product of the number of parameters and the number of data points, this means that the computational requirement grows by at least the square of the number of data points in a hyperparametrized system. Quadratic scaling does not yet sufficiently estimate how fast deep learning networks must grow, since the amount of training data must scale much faster than linearly to obtain linear performance improvements.
Consider a generative model that has 10 non-zero values out of a possible 1000, and consider four models to try to discover these parameters:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
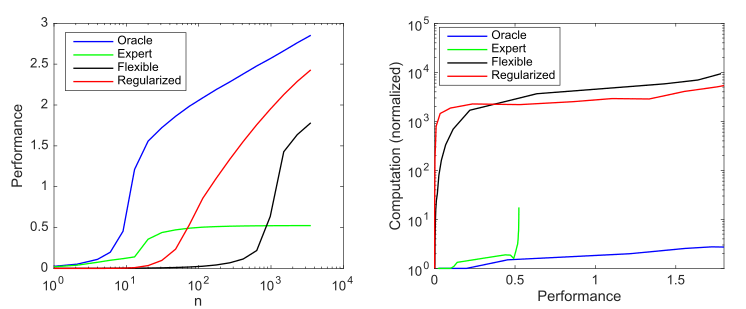
Impact of model complexity and regularization on model performance (measured as negative log 10 normalized root mean square error versus the optimal predictor) and on computational requirements averaged over 1000 simulations per case; a) average productivity as sample sizes increase; b) Average computation needed to improve performance
This graph summarizes the principle outlined by Andrew Ng: traditional machine learning methods work better on small data, but flexible ML models work better on big data. A common phenomenon of agile models is that they have higher potential, but also significantly more data and computational needs.
We can see that deep learning works well because it uses hyperparametrization to create a very flexible model and (implicit) regularization to reduce sample complexity to acceptable levels. At the same time, however, deep learning is significantly more computationally intensive than more efficient models. Thus, increasing ML flexibility implies dependence on large amounts of data and computation.
Computational limits
Computer performance has always limited the power of ML systems.
For example, Frank Rosenblatt described the first three-layer neural network in 1960. It was hoped that she would "demonstrate the possibilities of using the perceptron as a pattern recognition device." But Rosenblatt found that "as the number of connections on the network increases, the load on a typical digital computer soon becomes excessive." Later in 1969, Minsky and Papert explained the limitations of 3-layer networks, including the inability to learn a simple XOR function. But they noted a potential solution: “The experimenters have found an interesting way to get around this difficulty by introducing longer chains of intermediate units” (that is, by building deeper neural networks). Despite this potential workaround, much of the academic work in this area has been abandoned.because at that time there was simply not enough computing power.
Over the ensuing decades, improvements in hardware resulted in performance gains of about 50,000 times, and neural networks proportionally increased their computational needs, as shown in KDPV. Since the increase in computing power by one dollar roughly matched the computing power per chip, the economic costs of running such models have remained largely stable over time.
Despite such significant CPU acceleration, deep learning models were still too slow for large-scale applications back in 2009. This forced researchers to focus on smaller scale models or use fewer training examples.
The turning point was the transfer of deep learning to the GPU, which immediately gave acceleration in5-15 times , which by 2012 had grown to 35 times and which led to an important victory for AlexNet in the 2012 Imagenet competition . But image recognition was only the first benchmark where deep learning systems won. They soon won out in object detection, named entity recognition, machine translation, question answering, and speech recognition.
The introduction of deep learning on GPUs (and then ASICs) led to widespread adoption of these systems. But the amount of computing power in modern ML systems grew even faster, about 10 times a year from 2012 to 2019. This speed is much higher than the overall improvement from the move to GPUs, the modest gain from the last gasp of Moore's Law, or the improved efficiency of neural network training.
Instead, the main gain in ML efficiency came from running models over longer periods of time on more machines. For example, in 2012 AlexNet trained on two GPUs for 5-6 days, in 2017 ResNeXt-101 trained on eight GPUs for more than 10 days, and in 2019 NoisyStudent trained on about a thousand TPU for 6 days. Another extreme example is the Evolved Transformer machine translation system , which used over 2 million GPU hours in training, which cost millions of dollars.
Scaling deep learning computations by increasing hardware clocks or the number of chips is problematic in the long run. Because it implies that costs scale at roughly the same rate as increases in computing power, and that quickly makes further growth impossible.
Future
Sad conclusion from the above.
The following table shows how much computational power and cost of the system will achieve certain goals in ML problems, if we extrapolate from the current models. Machine learning tasks will run on the most powerful supercomputers. The authors of the scientific work believe that the requirements for the goals set will not be met . Although they are considering theoretically possible options for achieving them: improving efficiency without increasing performance, hardware accelerators such as TPU and FPGA, neuromorphic computing, quantum computing and others, none of these technologies (yet) allows you to overcome the computational limits of ML.

. .
