Suppose we have a register of documents that operators or accountants in VLSI work with , like this: Traditionally, in such a display, either direct (new from below) or reverse (new from above) sorting by date and ordinal identifier assigned when creating a document is used - or ... I have already discussed the typical problems that arise in this case in the article PostgreSQL Antipatterns: Navigating the Registry . But what if the user for some reason wants to be "atypical" - for example, sort one field "like this", and another "that way" -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? But we do not want to create the second index, because it slows down the insertion and extra volume in the database.
Is it possible to solve this problem effectively using only the index
(dt, id)?
Let's first sketch out how our index is ordered:
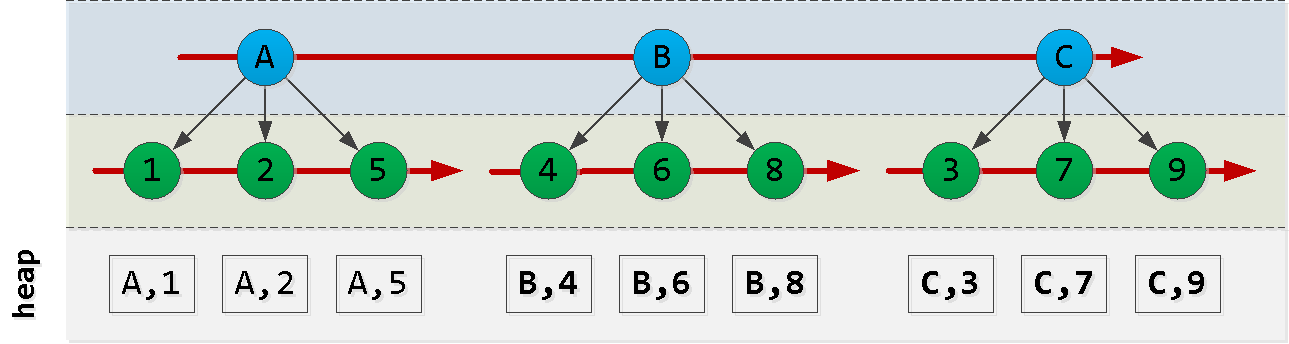
Note that the order in which the id entries are created does not necessarily match the order of dt, so we cannot rely on it, and we will have to invent something.
Now suppose we are at point (A, 2) and want to read the "next" 6 entries in the sort : Aha! We have selected some "piece" from the first node , another "piece" from the last node and all records from the nodes between them ( ). Each such block is quite successfully read by index , despite the not quite suitable order. Let's try to construct a query like this:
ORDER BY dt, id DESC
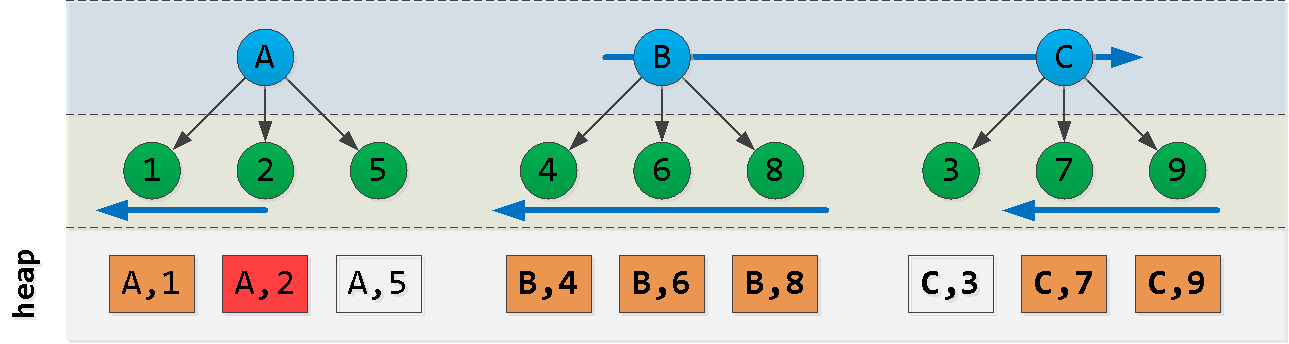
ACB(dt, id)
- first we read from block A "to the left" of the starting record - we get
Nrecords - further we read
L - N"to the right" of the value A - find in the last block the maximum key C
- filter out all records from the previous selection with this key and subtract it "on the right"
Now let's try to depict in the code and check on the model:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);In order not to calculate the number of already read records and the difference between it and the target number, we will force PostgreSQL to do this using a "hack"
UNION ALLand LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Now let's collect the following 100 records with target sorting from the last known value:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Let's see what happened in terms of:

[look at explain.tensor.ru]
- So,
A = '2019-09-07'we read 3 records using the first key . - They finished reading another 97 by
BandCdue to the exact hit inIndex Scan. - Among all records, 18 were filtered by the maximum key
C. - We read 23 records (instead of 18 searched for
Bitmap Scan) using the maximum key. - All re-sorted and trimmed the target 100 records.
- ... and it all took less than a millisecond!
The method, of course, is not universal and with indexes on a larger number of fields it will turn into something really terrible, but if you really want to give the user a “non-standard” sorting without “collapsing” the base into
Seq Scana large table, you can use it carefully.