Almost any business is faced with a floating load: now silence, then a squall. You don't have to go far for examples:
- online store traffic can fluctuate significantly depending on the time of day or season;
- internal services of companies can be "empty" for weeks, and on the eve of the submission of the quarterly report, their attendance will jump sharply.
Under the cut, we'll talk about how we helped our customers solve this problem by introducing a new storage tier with custom IOPS.
A few words about disks
All our clients want plus or minus one thing - to get a reliable infrastructure that meets the requirements of business processes at a good price. Accordingly, we, as a cloud provider, are faced with the task of building services and services in such a way that we can easily find the optimal solution for each client.
Previously, we had two storage tiers: st2 and gp2. The number "2" in our internal terminology means a newer, improved version.
st2: Standard (HDD) - Leisurely and inexpensive SAS HDD media. Great for services where IOPS is not critical, but bandwidth is important.
Their parameters are as follows: response time - no more than 10 ms, performance of disks up to 2000 GB - 500 IOPS, from 2000 GB - 1000 IOPS, and the throughput grows with each gigabyte and reaches 500 MB / s for the same 2000 GB.
gp2: Universal (SSD) - More expensive and faster SAS SSD drives. Suitable for customers whose applications are more demanding in terms of IOPS. For example - databases of online stores.
Gp2 parameters are specified in the SLA. Performance in IOPS is calculated by volume - there are 10 IOPS per GB. The top bar is 10,000 IOPS. And the response time of such disks is no more than 2 ms. This is a fairly high performance, capable of completing 97% of business tasks.
Over the years of work, we have accumulated a lot of statistics and expertise in relation to customers and noticed that some of them are not entirely comfortable choosing between two drive options. For example, someone might want better performance than 10 IOPS per gigabyte. Or a floating load does not make it possible to stop at one of the types, and paying for ready for rush hour, but periodically idle capacity is also not an option.
You can simulate a simple topical case. During the pandemic, one company needed to issue passes for employees. So that they can safely drive around Moscow. The staff is large, two thousand people. An order was issued to urgently update personal data in the corporate CRM system. No sooner said than done. More than a thousand people simultaneously rushed to update the information. But thrifty people were engaged in CRM. Little capacity has been allocated. Nobody expected that more than ten people would climb into it at the same time! Everything fell and could not rise for another day. Business processes have been disrupted, people are sitting at home and are afraid of fines. And if there was an opportunity to flexibly "tweak" the performance of disks in the cloud, they would raise IOPS for a short time, and then return it as it was, eliminating or significantly reducing the CRM downtime.
On the one hand, the situation is grotesque; the percentage of customers with such needs is not very large. A small provider would even take their existence as a statistical anomaly and would not take any action. On the other hand, the organization of a new level of storage will allow us to increase the flexibility of services for all clients. That means we have to do it.
If you have been following our blog for a long time, then you probably remember the article in which we talked about a series of experiments with Dell EMC ScaleIO (now PowerFlex OS) and its implementation in the CROC Cloud. Be that as it may, we recommend that you familiarize yourself with it for a general understanding.
In general terms, let's say: ScaleIO (DellEMC renamed ScaleIO first to VxFlex OS, and from June 25, 2020 to PowerFlex OS) is a super versatile and reliable Software-Defined Storage, SDS. Reliability is our requirement # 0. Therefore, each node that forms part of the Storage Pool is installed in a separate rack, which excludes the possibility of data loss in the event of a partial loss of power in the data center or locally in the rack.
If a disk, server or entire rack fails, we will have enough time to replicate the data to other hosts and subsequently replace the failed element. If two racks die at once, nothing will be lost anyway. In this situation, the cluster will go into emergency mode, writing and reading data from disks will be limited, but after the restoration of connectivity with the "fallen" rack, PowerFlex OS will itself take over the process of data rebuild and cluster recovery. This process, by the way, most often takes no more than a couple of minutes.
This is, of course, an emergency situation - applications that cannot read and write will immediately "fall off", but the loss of even such a large part of the infrastructure will not destroy the data. While the probability of failure of two racks in different parts of the turbine hall is extremely small, this does not mean that it should not be taken into account.
In terms of versatility, PowerFlex OS (formerly ScaleIO) is also ideal for our requirements. In fact, this is a constructor, ready to accept any workload and capable of "accepting" slow SATA / SAS HDDs, fast SSDs, and ultra-fast NVME drives. And this is really true - it has been tested on numerous stage- and testing-stands of development and maintenance teams, you can assemble a cluster practically from
Music from five to six
Let's take a look at one of the scenarios in which a customer might need flexible performance with a real-world example. Among our clients there is a network of musical instruments stores. The company's technicians track how many visitors visit their site every day and hour. This is reflected even in our SLA: from 17:00 to 18:00 the store receives the maximum number of customers, so there should be no technical work or downtime.
Standard calculation practice is when 100% of the load is divided 24 hours. It turns out about 4% for every hour. For a chain of music stores, this particular hour "weighs" not 4, but 10% - this is tens of thousands of visitors and customers.
Accordingly, it would be very convenient for the customer if in this "golden" hour their disks became faster as if by magic,
Now we have the opportunity to give clients at least 30, at least 50 thousand IOPS during the busiest hours, and the rest of the time to keep the performance at the usual level. We called this type of storage io2: Ultimate (SSD). The response time of disks based on this type of storage is no more than 1 ms!
And again about reliability: st2, gp2 and the new io2 are independent, independent from each other Storage Pools in a PowerFlex cluster.
If earlier the client selected a disk and received a fixed performance, now he can select and configure it, performance. Regardless of the volume. The philosophy is as follows: you can get a huge and fast disk from a large number of providers, but are you ready to pay for it 100% of the time?
How to manage
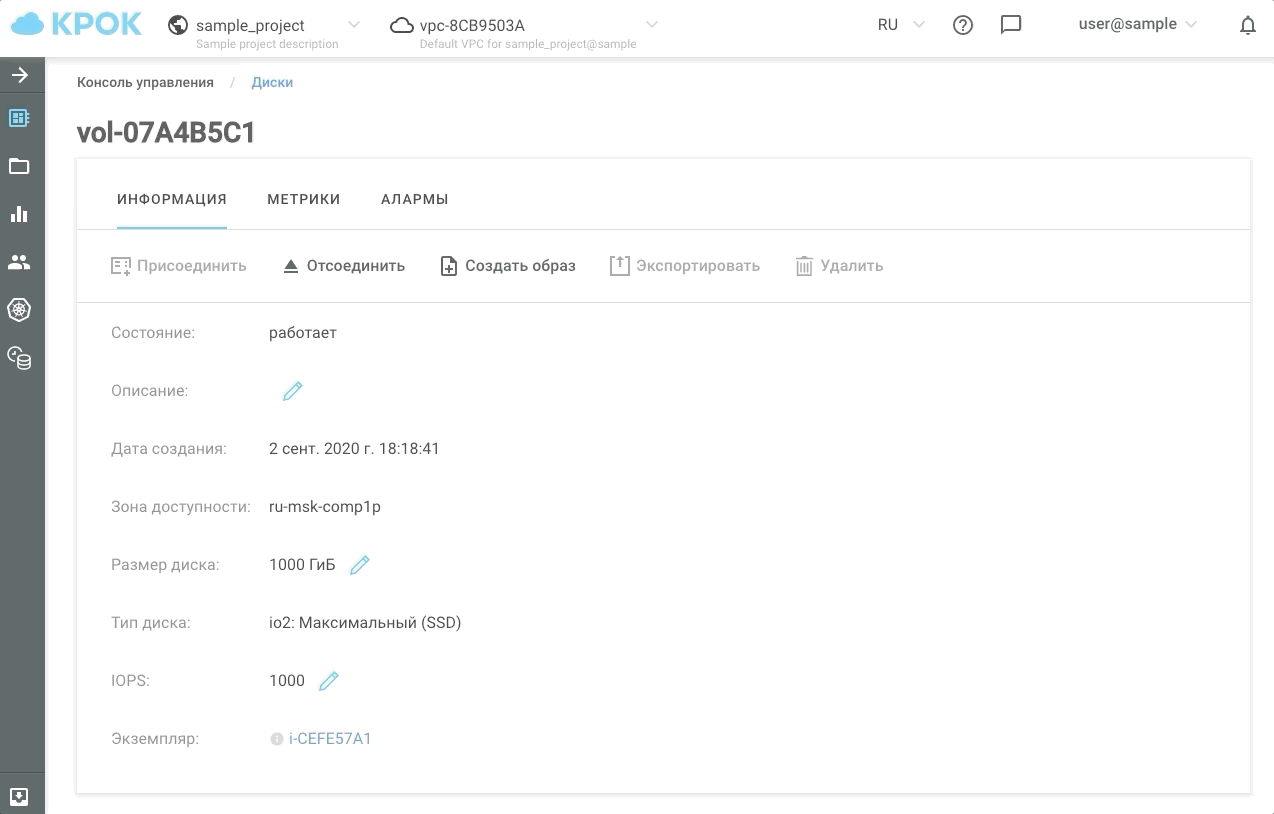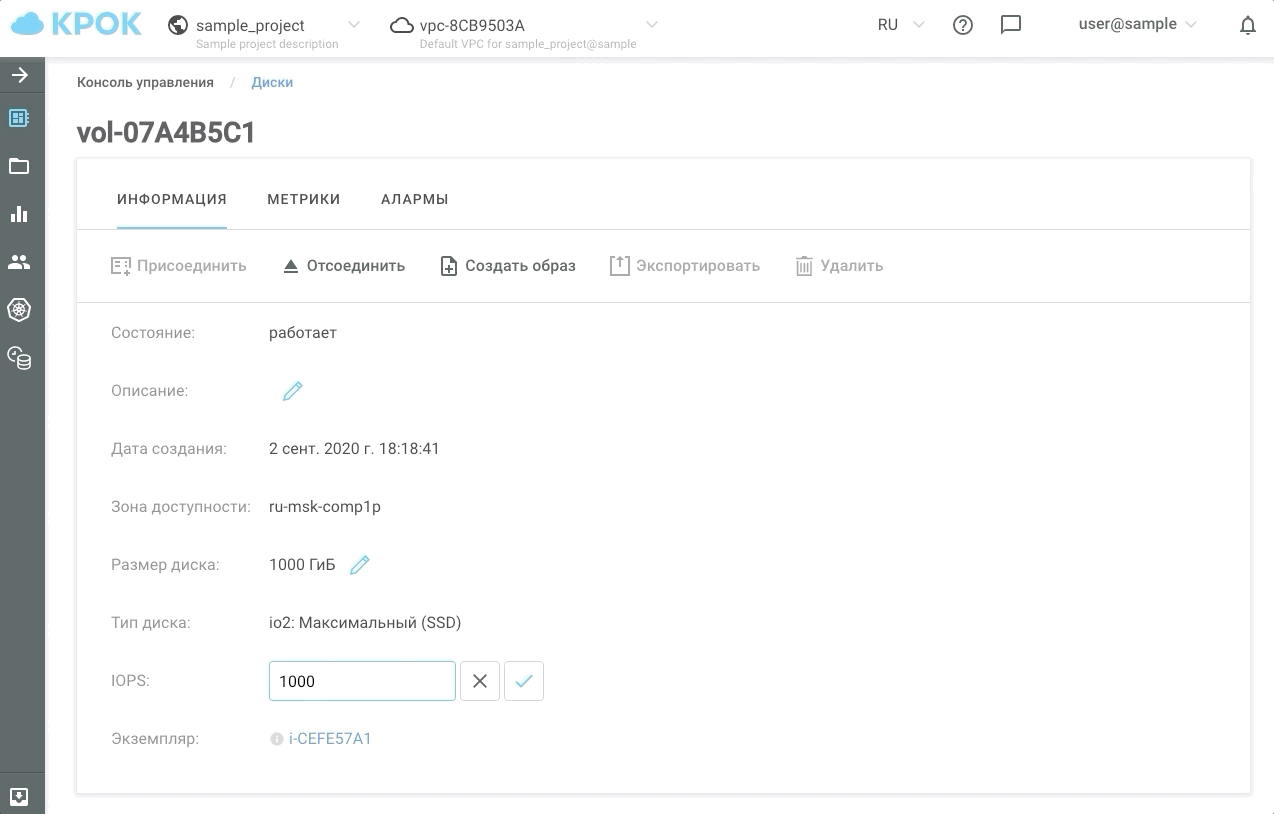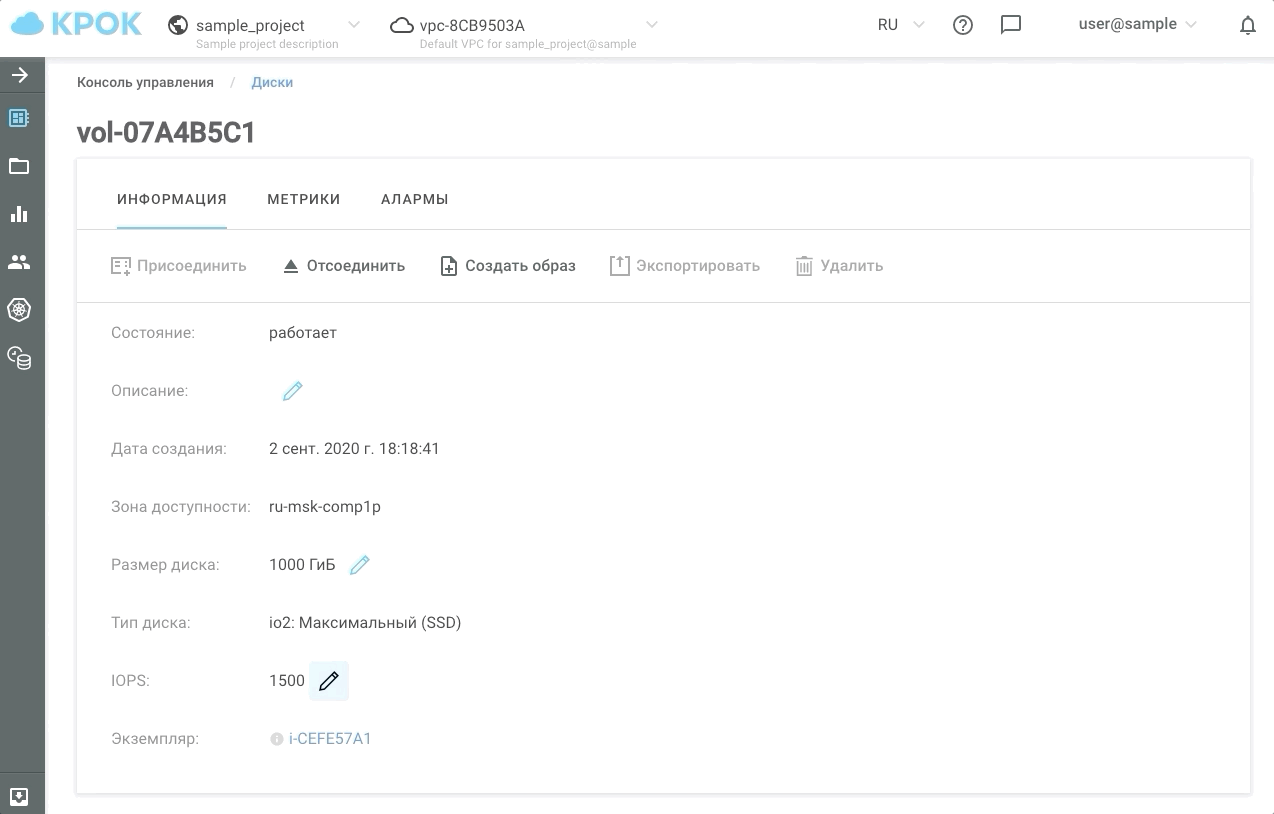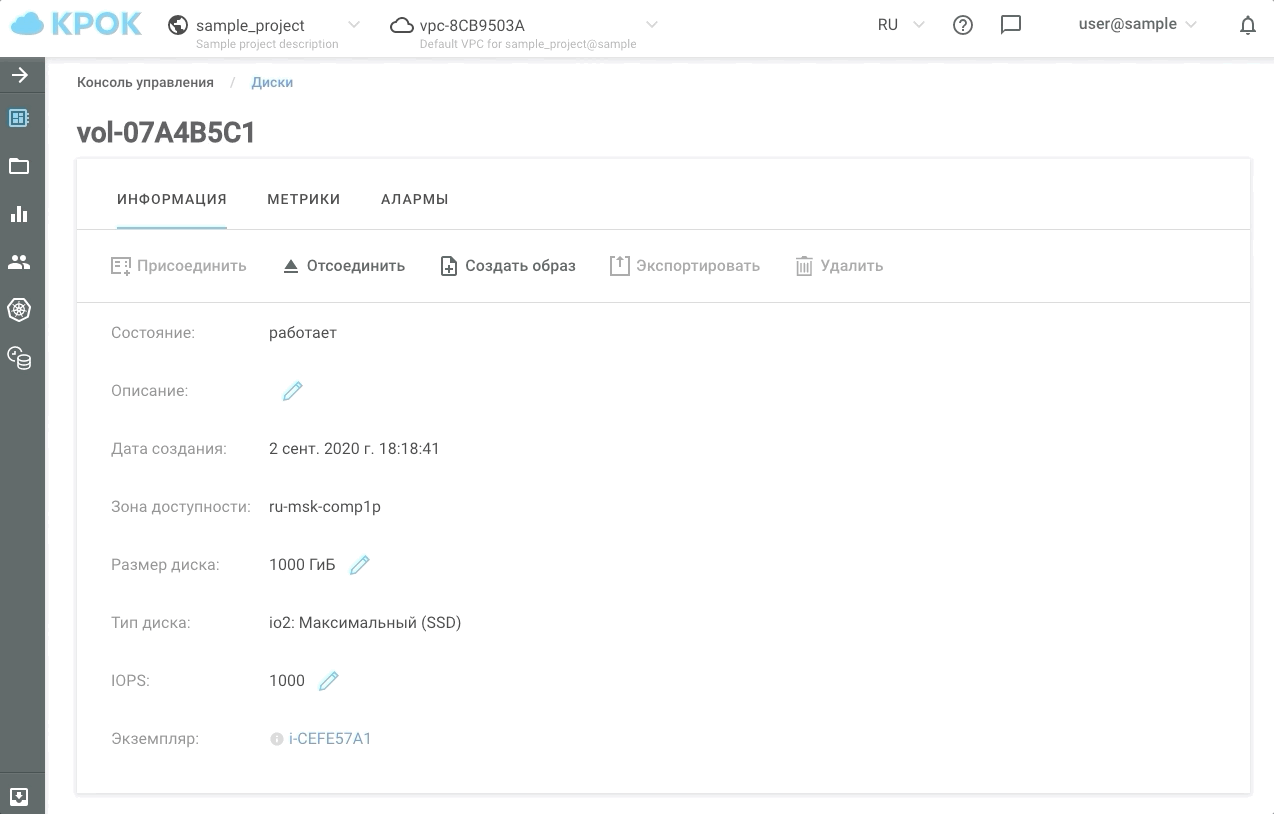
There are two ways to manage performance: the old-fashioned way, through the web interface, and using the API. This makes it possible to write simple scripts that will "speed up" or "slow down" disks on a schedule and, accordingly, save you money.
Whereas earlier we could take any load required by the client, now we can do it at the best price.
This is how it looks in practice.
Increasing the agility of the cloud infrastructure is a relevant and very correct trend. You cannot tell the customer: "Take what they give, or even this will not happen!" He must be able to decide what resources, when and how much he needs. The future lies in such flexible and reliable solutions.
We vouch for our services: all parameters are spelled out in the SLA, and you can count on the fact that the "paper" figures will not diverge from the real ones.
And how to check your cloud provider, we already wrote in the previous article .