
We're back on the air and continuing the Data Scientist series of notes, and today I present my completely subjective checklist for choosing a machine learning model.
These are the top 10 properties of the problem and just points (without order in them), from the point of view of which I start choosing a model and, in general, modeling a data analysis task.
It is not at all necessary that you will have it the same - everything is subjective here, but I share my experience from life.
What is our goal in general? Interpretability and accuracy - spectrum

Source
Perhaps the most important question a data scientist faces before starting modeling is:
What, exactly, is a business task?
Or research, if we are talking about the academy, etc.
For example, we need analytics based on a data model, or vice versa, we are only interested in qualitative predictions of the likelihood that an email is spam.
The classic balance I've seen is the spectrum between the interpretability of the method and its accuracy (as in the graph above).
But in fact, you need not just to drive Catboost / Xgboost / Random Forest and choose a model, but to understand what the business wants, what data we have and how it will be applied.
In my practice, this will immediately set a point on the spectrum of interpretability and accuracy (whatever that means here). And based on this, one can already think about methods for modeling the problem.
The type of the task itself
Further, after we understood what the business wants - we need to understand what mathematical type of machine learning problems ours belongs to, for example
- Exploratory analysis - pure analytics of available data and sticking a stick
- Clustering - collect data into groups based on some common attribute (s)
- Regression - you need to return an integer result or there is a probability of an event
- Classification - you need to return one class label
- Multi-label - you need to return one or more class labels for each entry
Examples
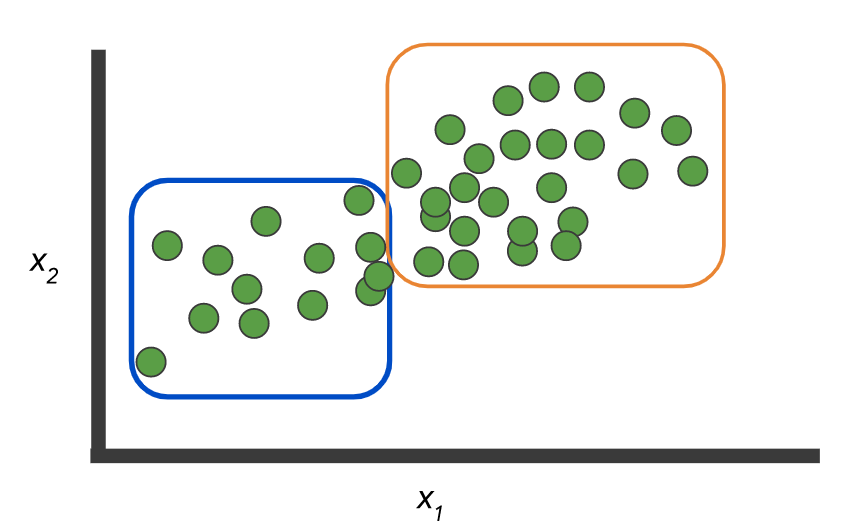
Data: there are two classes and an unlabeled recordset:

And you need to build a model that will mark up this very data:

Or, as an option, there are no labels and you need to select the groups:

Like here:
Pictures from here .
But the example itself illustrates the difference between the two concepts: classification, when N> 2 classes - multi class vs. multi label
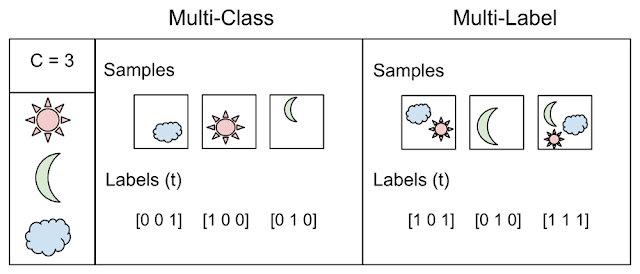
Taken from here
You will be surprised, but very often this point is also worth talking directly to the business - this can really save you a lot of time and effort. Feel free to draw pictures and give simple examples (but not overly simplistic).
Accuracy and how it is determined
I'll start with a simple example, if you are a bank and issue a loan, then on an unsuccessful loan we lose five times more than we get on a successful one.
Therefore, the question of measuring the quality of work is primary! Or imagine that you have a significant imbalance in the data, class A = 10%, and class B = 90%, then a classifier that simply returns B is always 90% accurate! This is most likely not what you wanted to see when training the model.
Therefore, it is critical to define a model scoring metric including:
- weight class - as in the example above, bad credit is 5 and good credit is 1
- cost matrix - it is possible to confuse low and medium risk - this does not matter, but low risk and high risk is already a problem
- Should the metric reflect balance? such as ROC AUC
- Do we generally count probabilities or are class labels straight?
- Or maybe the class is generally "one" and we have precision / recall and other rules of the game?
In general, the choice of a metric is determined by the task and its formulation - and it is for those who set this task (usually business people) that all these details need to be clarified and clarified, otherwise there will be seams at the output.
Model post analysis
It is often necessary to conduct analytics based on the model itself. For example, what is the contribution of different features to the original result: as a rule, most methods can produce something similar to this:
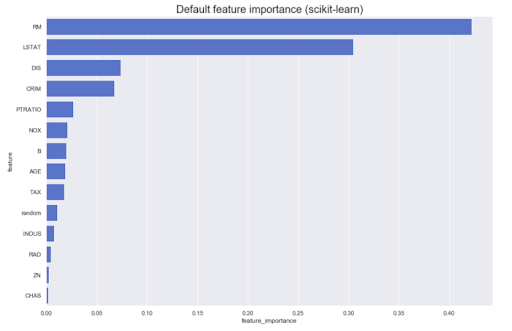
However, what if we need to know the direction - large values of the attribute A increase the belonging to the class Z, or vice versa? Let's call them directed feature importance - they can be obtained from some models, for example, linear ones (through coefficients on normalized data).
For a number of models based on trees and boosting, for example, the SHapley Additive exPlanations method is suitable.
SHAP
It is one of the model analysis methods that allows you to look under the hood of the model.
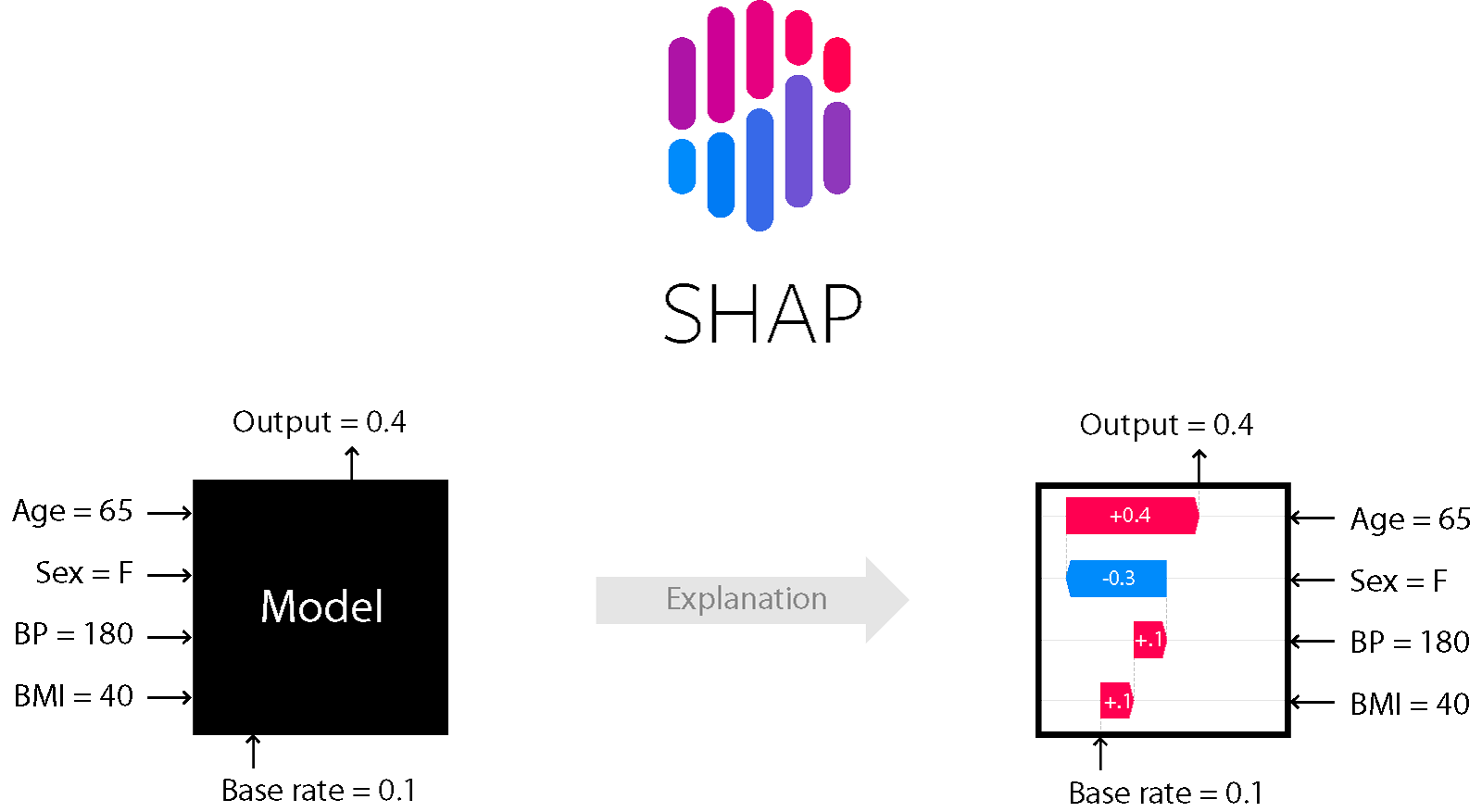
It allows you to assess the direction of the effect:

Moreover, for trees (and methods based on them) it is accurate. Read more about it here .
Noise level - stability, linear dependence, outlier detection, etc.
Resistance to noise and all these joys of life is a separate topic and you need to carefully analyze the noise level, as well as select the appropriate methods. If you are sure that there will be outliers in the data, you need to clean them with high quality and apply noise-resistant methods (high bias, regularization, etc.).
Also, signs can be collinear and meaningless signs can be present - different models react differently to this. Here's an example on the classic German Credit Data (UCI) dataset and three simple (relatively) learning models:
- Ridge regression classifier: classical regression with Tikhonov's regularizer
- Decition trees
- CatBoost from Yandex
Ridge regression
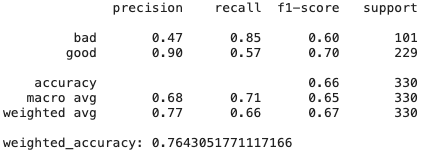
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Decision Trees
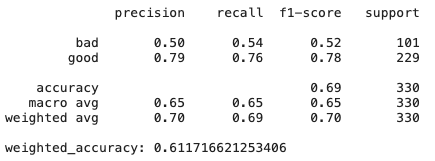
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
As we can see, simply the ridge regression model, which has high bias and regularization, shows results even better than CatBoost - there are many features that are not very useful and collinear, therefore methods that are resistant to them show good results.
More about DT - what if you change the dataset a little? Feature importance can vary as decision trees are generally sensitive methods, even to data shuffling.
Conclusion: sometimes easier is better and more effective.
Scalability
Do you really need Spark or neural networks with billions of parameters?
Firstly, you need to sensibly evaluate the amount of data, we have already seen the massive use of spark on tasks that easily fit into the memory of one machine.
Spark complicates debugging, adds overhead and complicates development - you shouldn't use it where you don't need it. Classics .
Second, of course, you need to assess the complexity of the model and relate it to the task. If your competitors show excellent results and they have RandomForest running, it may be worth thinking twice if you need a neural network with billions of parameters.
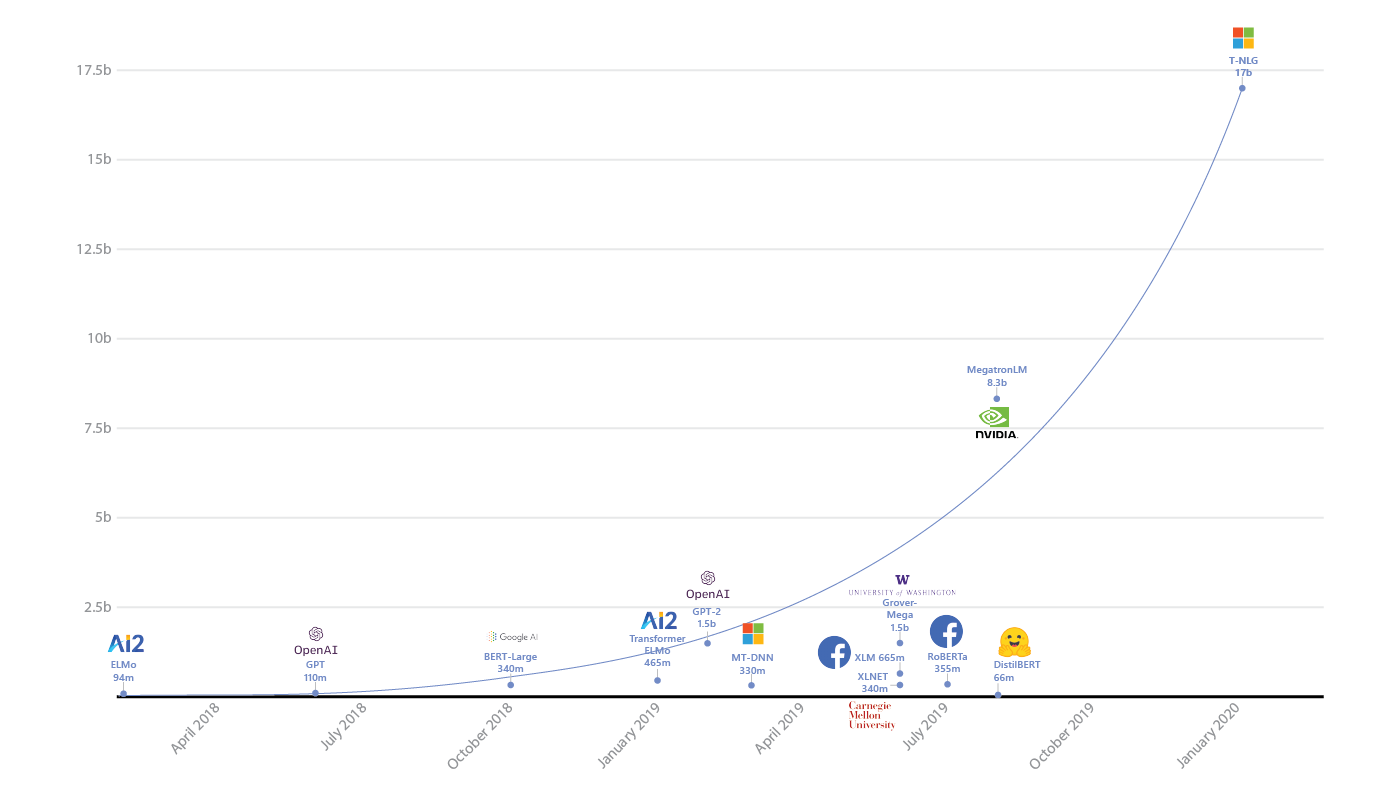
And of course, you need to take into account that if you really have large data, then the model must be able to work on them - how to learn from batches, or have some kind of distributed learning mechanisms (and so on). And in the same place, do not lose too much in speed with an increase in the amount of data. For example, we know that kernel methods require a square of memory for calculations in dual space - if you expect a 10-fold increase in data size, then you should think twice about whether you fit into the available resources.
Availability of ready-made models
Another important detail is the search for already trained models that can be pre-trained, ideal if:
- There is not a lot of data, but they are very specific to our task - for example, medical texts.
- Topic in general is relatively popular - for example, highlighting text topics - many works in NLP.
- Your approach allows, in principle, pre-learning - as for example with some type of neural networks.
Pre-trained models like GPT-2 and BERT can significantly simplify the solution of your problem, and if already trained models exist, I highly recommend that you do not pass by and use this chance.
Feature interactions and linear models
Some models perform better when there are no complex interactions between features - for example, the entire class of linear models - Generalized Additive Models. There is an extension of these models for the case of interaction of two features called GA2M - Generalized Additive Models with Pairwise Interactions.
As a rule, such models show good results on such data, are excellently regularized, interpretable and robust to noise. Therefore, it is definitely worth paying attention to them.
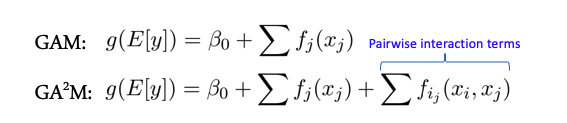
However, if the signs actively interact in groups of more than 2, then these methods no longer show such good results.
Package and model support
Many cool algorithms and models from articles are designed as a module or package for python, R, etc. It is worth really thinking twice before using and relying on such a solution in the long term (I say this, as a person who has written many articles on ML with such code). The probability that in a year there will be zero support is very high, because the author most likely now needs to engage in other projects, there is no time, and no incentives to invest in the development of the module or repository.
In this regard, libraries a la scikit learn are good precisely because they actually have a guaranteed group of enthusiasts around and if something is seriously broken, sooner or later they will be fixed.
Biases and Fairness
Along with automatic decision-making, people who are dissatisfied with such decisions come to life - imagine that we have some kind of ranking system for applications for a scholarship or a research grant at a university. Our university will be unusual - there are only two groups of students: historians and mathematicians. If suddenly the system, on the basis of its data and logic, suddenly handed out all the grants to historians and did not award them to any mathematician, this may not weakly offend mathematicians. They will call such a system biased. Now only the lazy does not talk about this, and companies and people are suing each other.
Conventionally, imagine a simplified model that simply counts the citations of articles and let historians cite each other actively - the average is 100 citations, but there is no mathematics, they have an average of 20 - and they write very little at all, then the system recognizes all historians as "good" because the citation rate is high 100> 60 (average), and mathematicians, as "bad" because they all have a citation rate much lower than the average 20 <60. Such a system can hardly seem adequate to someone.
The classics are now presenting the logic of decision making and training models that fight such a biased approach. Thus, for each decision, you have an explanation (conditionally) why it was made and how you actually made an effort to ensure that the model did not do bullshit (ELI5 GDPR).

Read more from Google here, or in the article here .
In general, many companies have begun such activities, especially in light of the release of the GDPR - such measures and checks can help avoid problems in the future.
If some topic interested more than others - write in the comments, we will go deeper. (DFS)!
