Sources on GitHub
 Video on click
Video on click
How I came to D
The main reason is that the original blogpost compared statically typed languages like Go and Rust, and made respectful references to Nim and Crystal, but did not mention D, which also falls into this category. So I think it will make the comparison interesting.
I also like D as a language and have mentioned it in various other blog posts.
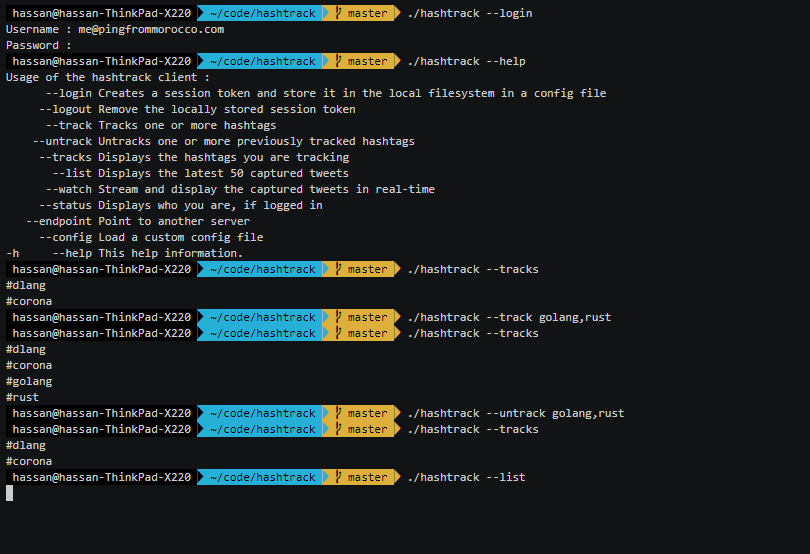
Local environment
The manual contains extensive information on how to download and install the reference compiler, DMD. Windows users can get an installer, while macOS users can use homebrew. On Ubuntu, I just added the apt repository and followed the normal installation. With this, you get not only the DMD, but also the dub, the package manager.
I installed Rust so I could get an idea of how easy it would be to get started. I was surprised how easy it is. I only needed to run the interactive installer , which took care of the rest. I needed to add ~ / .cargo / bin to path. You just had to restart the console for the changes to take effect.
Support by editors
I wrote the Hashtrack in Vim without much difficulty, but that's probably because I have some idea of what's going on in the standard library. I always had the documentation open, because at times I used a symbol that I didn't import from the correct package, or I called a function with the wrong arguments. Note that for the standard library, you can simply write "import std;" and have everything at your disposal. For third party libraries, however, you are on your own.
I was curious about the state of the toolkit, so I looked into plugins for my favorite IDE, Intellij IDEA. I found thisand installed it. I also installed DCD and DScanner by cloning their respective repos and building them, then configuring the IDEA plugin to point to the correct paths. Contact the author of this blog post for clarification.
I ran into a few issues at first, but they were fixed after updating the IDE and plugin. One problem I ran into was that she couldn't recognize my own packages and kept marking them as "possibly undefined." Later I found that in order for them to be recognized, I had to put "module package_module_name;" at the top of the file.
I think there is still a bug that .length is not recognized, at least on my machine. I have opened an issue on Github, you can follow it hereif you're curious.
If you are on Windows, I've heard good things about VisualD .
Package management
Dub is the de facto package manager in D. It downloads and installs dependencies from code.dlang.org . For this project, I needed an HTTP client because I didn't want to use cURL. I ended up with two dependencies, requests and its dependency, cachetools, which has no dependency of its own. However, for some reason, he picked twelve more dependencies:

I think Dub uses them internally, but I'm not sure about that.
Rust has loaded a lot of crates ( Approx: 228 ), but that's probably because the Rust version has more features than mine. For example, he downloaded rpassword , a tool that hides password characters as they type them into the terminal, similar to Python's getpass function.
Libraries
Having little understanding of graphql, I had no idea where to start. A search for "graphql" on code.dlang.org led me to the corresponding library, aptly named " graphqld ". However, after studying it, it seemed to me that it looks more like a vibe.d plugin than a real client, if any.
After examining network requests in Firefox, I realized that for this project I can simply simulate graphql requests and transformations that I will send using an HTTP client. The responses are just JSON objects that I can parse using the tools provided by the std.json package. With this in mind, I started looking for HTTP clients and settled on requests , which is an easy-to-use HTTP client, but more importantly, has reached a certain level of maturity.
I copied the outgoing requests from the sniffer and pasted them into separate .graphql files, which I then imported and sent with the appropriate variables. Most of the functionality was put into the GraphQLRequest structure because I wanted to insert the various endpoints and configurations into it as needed for the project:
Source
struct GraphQLRequest
{
string operationName;
string query;
JSONValue variables;
Config configuration;
JSONValue toJson()
{
return JSONValue([
"operationName": JSONValue(operationName),
"variables": variables,
"query": JSONValue(query),
]);
}
string toString()
{
return toJson().toPrettyString();
}
Response send()
{
auto request = Request();
request.addHeaders(["Authorization": configuration.get("token", "")]);
return request.post(
configuration.get("endpoint"),
toString(),
"application/json"
);
}
}
Here is a packet exchange snippet. The following code handles authentication:
struct Session
{
Config configuration;
void login(string username, string password)
{
auto request = createSession(username, password);
auto response = request.send();
response.throwOnFailure();
string token = response.jsonBody
["data"].object
["createSession"].object
["token"].str;
configuration.put("token", token);
}
GraphQLRequest createSession(string username, string password)
{
enum query = import("createSession.graphql").lineSplitter().join("\n");
auto variables = SessionPayload(username, password).toJson();
return GraphQLRequest("createSession", query, variables, configuration);
}
}
struct SessionPayload
{
string email;
string password;
//todo : make this a template mixin or something
JSONValue toJson()
{
return JSONValue([
"email": JSONValue(email),
"password": JSONValue(password)
]);
}
string toString()
{
return toJson().toPrettyString();
}
}Spoiler alert - I've never done this before.
Everything happens like this: the main () function creates a Config structure from the command line arguments and injects it into the Session structure, which implements the functionality of the login, logout and status commands. The createSession () method constructs a graphQL query by reading the actual query from the corresponding .graphql file and passing the variables along with it. I didn't want to pollute my source code with graphQL mutations and queries, so I moved them into .graphql files, which I then import at compile time using enum and import. The latter requires a compiler flag to point to stringImportPaths (which defaults to view /).
As for the login () method, its only responsibility is to send the HTTP request and process the response. In this case, it handles potential errors, although not very carefully. It then stores the token in a config file, which is really nothing more than a nice JSON object.
The throwOnFailure method is not part of the core functionality of the query library. It's actually a helper function that does some quick and dirty error handling:
void throwOnFailure(Response response)
{
if(!response.isSuccessful || "errors" in response.jsonBody)
{
string[] errors = response.errors;
throw new RequestException(errors.join("\n"));
}
}Since D supports UFCS , the throwOnFailure (response) syntax can be rewritten as response.throwOnFailure (). This makes it easy to embed in other method calls such as send (). I may have been overusing this functionality throughout the project.
Error processing
D prefers exceptions when it comes to error handling. The rationale is explained in detail here . One of the things I love is that unhandled errors will eventually pop up unless explicitly plugged up. This is why I was able to get away from simplified error handling. For example, in these lines:
string token = response.jsonBody
["data"].object
["createSession"].object
["token"].str;
configuration.put("token", token);If the response body does not contain a token or any of the objects leading to it, an exception will be thrown, which will bubble up in the main function and then explode in front of the user. If I were to use Go, I would have to be very careful with errors at every step. And, frankly, since it is annoying to write if err! = Null every time the function is called, I would be very tempted to simply ignore the error. However, my understanding of Go is primitive, and I wouldn't be surprised if the compiler barks at you for not doing anything with an error return, so feel free to correct me if I'm wrong.
Rust-style error handling as explained in the original blogpost was interesting. I don't think there is anything like this in the D standard library, but there have been discussions about implementing this as a third party library.
Websockets
I just want to briefly point out that I did not use websockets to implement the watch command. I tried to use the websocket client from Vibe.d but it couldn't work with the hashtrack backend because it kept closing the connection. In the end, I ditched it in favor of circular polling, even though it is frowned upon. The client has been working since I tested it with another webserver, so I might come back to this in the future.
Continuous integration
For CI, I set up two build jobs: a regular branch build and a master release to ensure that optimized builds of artifacts are downloaded.

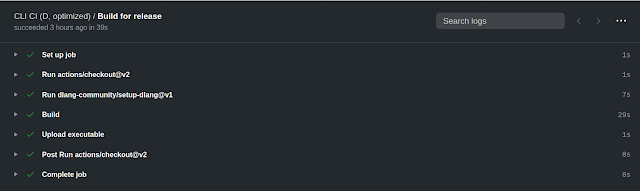
Approx. The pictures show the assembly time. Taking into account loading of dependencies. Rebuild without dependencies ~ 4s
Memory consumption
I used the / usr / bin / time -v ./hashtrack --list command to measure memory usage as explained in the original blog post. I don't know if the memory usage depends on the hashtags that the user is following, but here are the results of a D program compiled with dub build -b release:
Maximum resident set size (kbytes): 10036
Maximum resident set size (kbytes): 10164
Maximum resident set size (kbytes): 9940
Maximum resident set size (kbytes): 10060
Maximum resident set size (kbytes): 10008
Not bad. I ran the Go and Rust versions with my hashtrack user and got these results:
Go built with go build -ldflags "-s -w":
Maximum resident set size (kbytes): 13684Rust compiled with cargo build --release:
Maximum resident set size (kbytes): 13820
Maximum resident set size (kbytes): 13904
Maximum resident set size (kbytes): 13796
Maximum resident set size (kbytes): 13600
Maximum resident set size (kbytes): 9224Upd: Reddit user skocznymroczny recommended testing the LDC and GDC compilers as well. Here are the results:
Maximum resident set size (kbytes): 9192
Maximum resident set size (kbytes): 9384
Maximum resident set size (kbytes): 9132
Maximum resident set size (kbytes): 9168
LDC 1.22 compiled by dub build -b release --compiler = ldc2 (after adding color output and getpass)
Maximum resident set size (kbytes): 7816
Maximum resident set size (kbytes): 7912
Maximum resident set size (kbytes): 7804
Maximum resident set size (kbytes): 7832
Maximum resident set size (kbytes): 7804
D has garbage collection, but it also supports smart pointers and, more recently, an experimental memory management methodology inspired by Rust. I'm not entirely sure how well these functions integrate with the standard library, so I decided to let the GC handle the memory for me. I think the results are pretty good considering that I hadn't thought about memory consumption while writing the code.
Binaries size
Rust, cargo build --release: 7.0M
D, dub build -b release: 5.7M
D, dub build -b release --compiler=ldc2: 2.4M
Go, go build: 7.1M
Go, go build -ldflags "-s -w": 5.0M
.. — , , . Windows dub build -b release 2 x64 ( 1.5M x86-mscoff) , Rust Ubuntu18 - openssl, ,
I think D is a reliable language for writing command line tools like this. I didn't go to external dependencies very often because the standard library contained most of what I needed. Things like parsing command line arguments, handling JSON, unit testing, sending HTTP requests (with cURL ) are all available in the standard library. If the standard library lacks what you need, then third party packages exist, but I think there is still room for improvement in this area. On the other hand, if your NIH mentality is not invented here, or if you want to easily make an impact as an open source developer, then you will definitely love the D ecosystem.
Reasons why I would use D
- Yes