
Back in April 2020, Citizenlab reported on Zoom's rather weak encryption and stated that Zoom was using the SILK audio codec. Unfortunately, the article did not contain the initial data to confirm this and give me the opportunity to refer to it in the future. However, thanks to Natalie Silvanovich from Google Project Zeroand to the Frida tracing tool, I was able to get a dump of some raw SILK frames. Their analysis inspired me to take a look at how WebRTC handles audio. When it comes to perceived call quality in general, it is the audio quality that affects the most, as we tend to notice even small glitches. Just ten seconds of analysis was enough to set off on a real adventure - looking for options for improving the sound quality provided by WebRTC.
I dealt with the native Zoom client back in 2017 (before the DataChannel post ) and noticed that its audio packs were sometimes very large compared to the WebRTC-based solution packs:

The graph above shows the number of packets with a specific UDP payload length. Packets between 150 and 300 bytes are unusual when compared to a typical WebRTC call. They are much longer than the packets we usually get from Opus. We suspected that there was forward error control (FEC) or redundancy, but without access to unencrypted frames, it was difficult to draw further conclusions or do something.
Unencrypted SILK frames in the new dump showed a very similar distribution. After converting the frames to a file and then playing a short message (thanks to Giacomo Vacca for a very helpful blog postdescribing the necessary steps) I went back to Wireshark and looked at the packages. Here's an example of three packages that I found particularly interesting:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaefPackage 9 contains two previous packages, package 8 - 1 previous package. This redundancy is caused by the use of the LBRR - Low Bit-Rate Redundancy format, which was shown by a deep study of the SILK decoder (it can be found in the Internet project provided by the Skype team , or in the repository on GitHub ):

Zoom uses SKP_SILK_LBRR_VER1 but with two fallback packages. If each UDP packet contains not only the current audio frame, but also the two previous ones, it will be robust even if you lose two of the three packets. So maybe the key to Zoom sound quality is Grandma's Skype secret recipe?
Opus FEC
How can I achieve the same with WebRTC? The next obvious step was to consider Opus FEC.
SILK's LBRR (Low Rate Reservation) is also found in Opus (remember that Opus is a hybrid codec that uses SILK for the lower end of the bitrate range). However, Opus SILK is very different from the original SILK, the source code of which was once discovered by Skype, as is the part of LBRR that is used in error control mode.
Opus doesn't just add error control after the original audio frame, it precedes it and is encoded in the bitstream. We tried experimenting with adding our own error control using the Insertable Streams API , but this required a complete transcoding to insert the information into the bitstream before the actual packet.
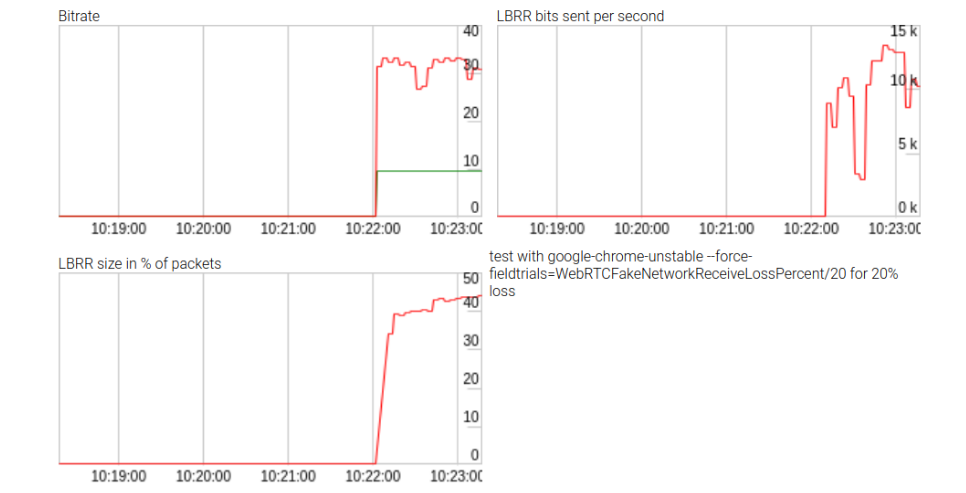
Although the efforts were unsuccessful, they did generate some statistics on the impact of LBRR, which are shown in the figure above. LBRR uses up to 10 kbps (or two-thirds of the data rate) bitrate for high packet loss. The repository is available here . These statistics are not displayed when calling the WebRTC
getStats() API , so the results were quite entertaining.
The need for transcoding is not the only problem with Opus FEC. As it turned out, its settings in WebRTC are somewhat useless:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
Subtracting the FEC bitrate from the target maximum bitrate does not make sense at all - FEC is actively reducing the bitrate of the main stream. A lower bitrate stream usually results in lower quality. If there is no packet loss that can be corrected with FEC, then FEC will only degrade the quality, not improve it. Why it happens? The basic theory is that congestion is one of the reasons for packet loss. If you are experiencing congestion, you will not want to send more data because that will only make the problem worse. However, as Emil Ivov describes in his excellent 2017 KrankyGeek talkcongestion is not always the cause of packet loss. In addition, this approach also ignores any accompanying video streams. The congestion-based FEC strategy for Opus audio doesn't make much sense when you are sending hundreds of kilobits of video alongside a relatively small 50kbps Opus stream. Perhaps in the future we will see some changes in libopus, but for now I would like to try to disable it, because it is currently enabled in WebRTC by default .
We conclude that this does not suit us ...
RED
If we want real redundancy, RTP has a solution called RTP Payload for Redundant Audio Data, or RED. It's quite old, RFC 2198 was written in 1997 . The solution allows multiple RTP payloads with different timestamps to be put into the same RTP packet at a relatively low cost.
Using RED to put one or two redundant audio frames in each packet would be much more robust against packet loss than Opus FEC. But this is only possible by doubling or tripling the audio bitrate from 30 kbps to 60 or 90 kbps (with an additional 10 kbps for the header). Compared to more than 1 megabit of video data per second, though, that's not too bad.
The WebRTC library included a second encoder and decoder for RED, which is now redundant! Despite attempts to remove unused audio-RED-code , I was able to apply this encoder with relatively little effort. The complete history of the solution is available in the WebRTC bug tracking system.
And it is available as a trial that is included when Chrome starts with the following flags:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/Then RED can be enabled via SDP negotiation; it will display like this:
a=rtpmap:someid red/48000/2It is not enabled by default as there are environments where using extra bandwidth is not a good idea. To use RED, change the order of the codecs so that it comes before the Opus codec. This can be done using the API
RTCRtpTransceiver.setCodecPreferencesas shown here . Obviously another alternative is to manually change the SDP. The SDP format could also provide a way to configure the maximum level of redundancy, but the RFC 2198 offer-response semantics were not completely clear, so I decided to postpone this for a while.
You can demonstrate how this all works by running it in an audio example . This is what the early version looks like with one backup package:
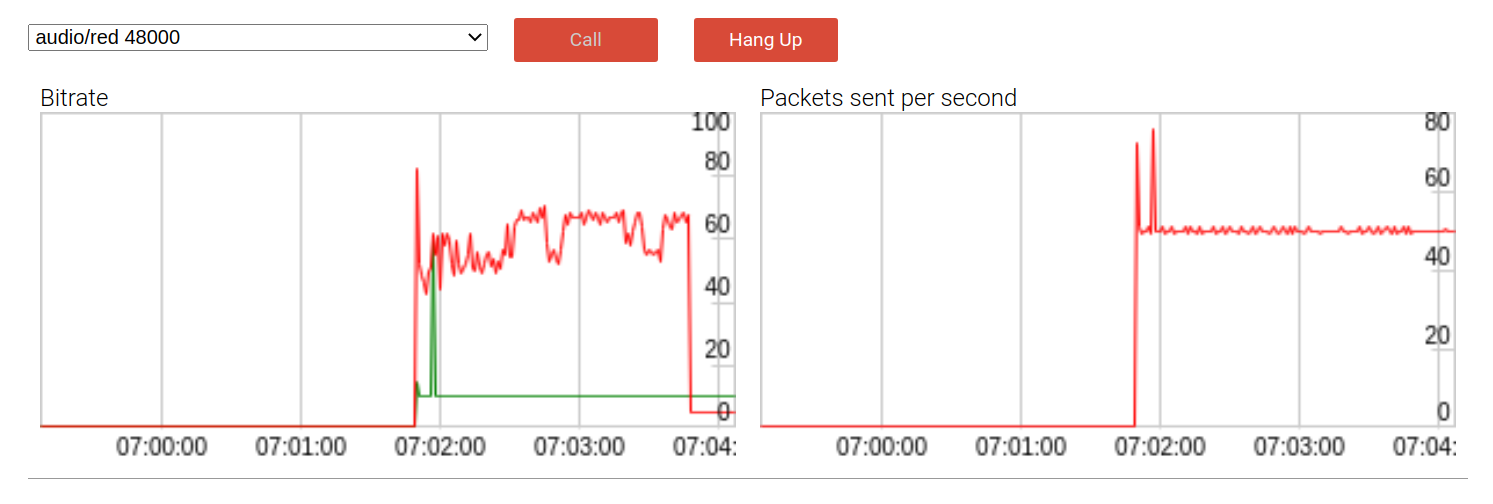
By default, the payload bitrate (red line) is almost twice as high as without redundancy, at almost 60 kbps. DTX (Discontinuous Transfer) is a bandwidth conserving mechanism that only sends packets when voice is detected. As expected, when using DTX, the effect of the bitrate softens somewhat, as we can see at the end of the call.
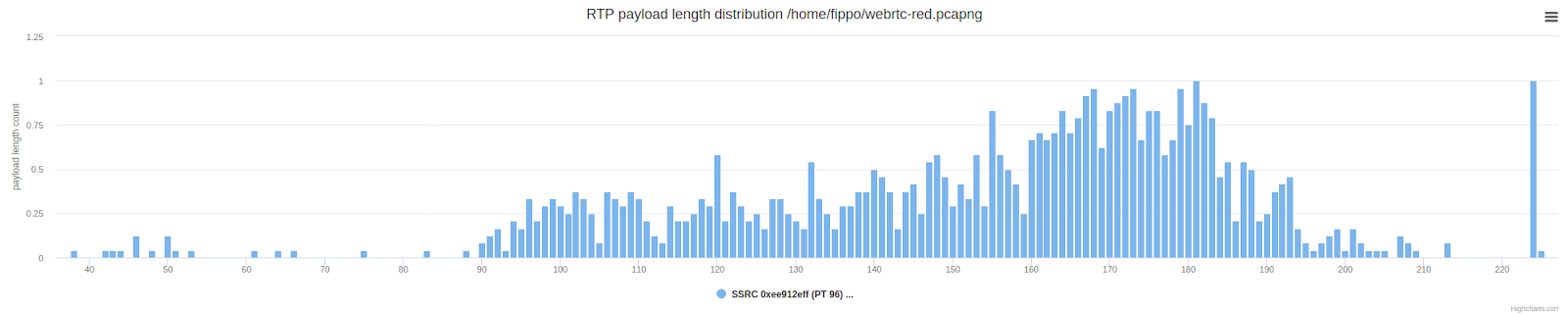
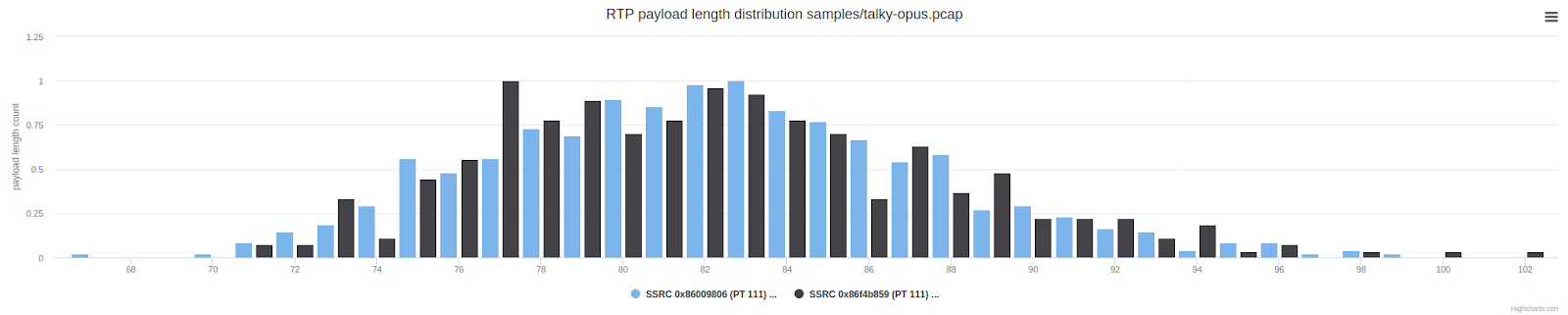
Checking the packet length shows the expected result: the packets are, on average, twice as long (taller) compared to the normal distribution of payload length shown below.
This is still slightly different from what Zoom does, where we saw fractional reservations. Let's revisit the Zoom packet length graph shown earlier to see a comparison:
Adding Voice Activity Detection (VAD) Support
Opus FEC sends backup data only if there is voice activity in the packet. The same should be applied to the RED implementation. For this, the Opus encoder must be changed to display the correct VAD information , which is defined at the SILK level. With this setting, the bitrate reaches 60 kbps only in the presence of speech (compared to constant 60+ kbps):

and the "spectrum" becomes more like what we saw with Zoom:

The change to achieve this has not yet appeared.
Finding the right distance
Distance is the number of backup packets, that is, the number of previous packets in the current one. In the process of working to find the right distance, we found that if RED at distance 1 is cool, then RED at distance 2 is even cooler. Our laboratory estimate simulated a random packet loss of 60%. In this environment, Opus + RED performed excellent sound, while Opus without RED performed much worse. The WebRTC getStats () API provides a very useful ability to measure this by comparing the percentage of hidden samples obtained by dividing concealedSamples by totalSamplesReceived .
On the audio samples page, this data is easily retrieved using this JavaScript snippet pasted into the console:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})I ran a couple of packet loss tests using a not-so-famous but very useful flag
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/At 20% packet loss and FEC enabled by default, there was not much difference in audio quality, but there was a slight difference in metric:
| scenario | loss percentage |
|---|---|
| without red | eighteen% |
| no red, FEC disabled | 20% |
| red with distance 1 | 4% |
| red with distance 2 | 0.7% |
Without RED or FEC, the metric almost matches the requested packet loss. There is an effect of FEC, but it is small.
Without RED, at 60% loss, the sound quality became rather poor, a little metallic, and the words difficult to understand:
| scenario | loss percentage |
|---|---|
| without red | 60% |
| red with distance 1 | 32% |
| red with distance 2 | eighteen% |
There were some audible artifacts at RED with distance = 1, but almost perfect sound with distance 2 (which is the amount of redundancy currently in use).
There is a feeling that the human brain can withstand a certain level of silence that occurs irregularly. (And Google Duo seems to be using a machine learning algorithm to fill the silence.)
Measuring performance in the real world
We hope that the inclusion of RED in Opus will improve the sound quality, although in some cases it can make it worse. Emil Ivov volunteered to conduct a couple of listening tests using the POLQA-MOS method. This has already been done for Opus, so we have a baseline for comparison.
If the initial tests show promising results, then we will conduct a large-scale experiment on the main scan of Jitsi Meet, applying the percentage loss metrics we used above.
Note that for media servers and SFUs, enabling RED is a little more difficult because the server may need to manage RED relaying to select clients, as if not all clients support RED conferences. Also, some clients may be on a limited bandwidth channel where RED is not required. If the endpoint does not support RED, the SFU can remove unnecessary encoding and send Opus without a wrapper. Likewise, it can implement RED itself and use it when resubmitting packets from an endpoint transmitting Opus to an endpoint supporting RED.
Many thanks to Jitsi / 8 × 8 Inc for sponsoring this exciting adventure and the folks at Google who analyzed and provided feedback on the changes needed.
And without Natalie Silvanovich, I would have sat looking at the encrypted bytes!