... into a nicely designed query with contextual hints for the corresponding plan nodes:

In this transcript of the second part of my talk at PGConf.Russia 2020, I will tell you how we managed to do this.
The transcript of the first part, which deals with typical query performance problems and their solutions, can be found in the article "Recipes for ailing SQL queries" .
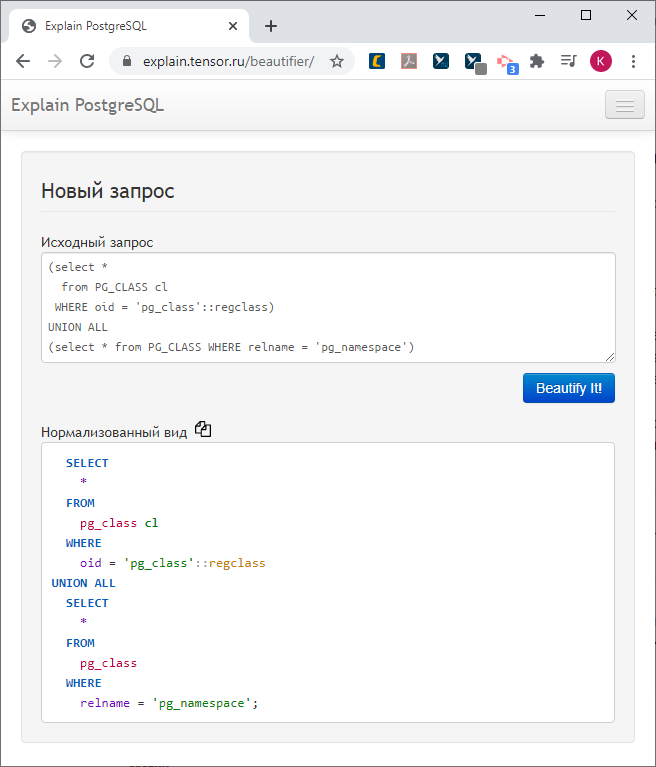
First, we will paint - and we will no longer paint the plan, we have already painted it, we have it already beautiful and understandable, but a request.
It seemed to us that the query pulled from the log with an unformatted "sheet" looks very ugly and therefore uncomfortable.

Especially when the developers in the code "glue" the request body (this is, of course, an anti-pattern, but it happens) in one line. Horror!
Let's draw it somehow more beautifully.
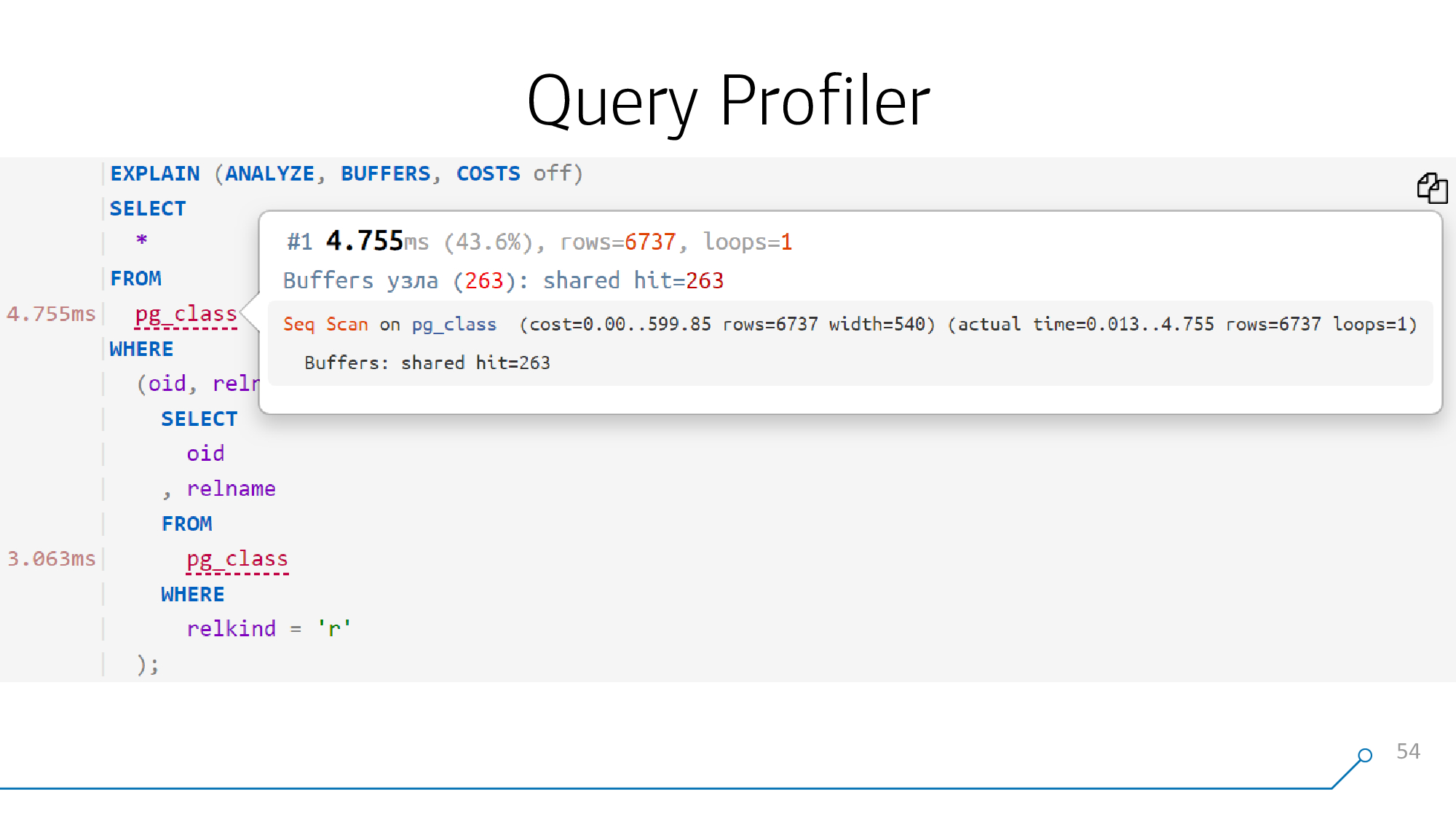
And if we can draw it beautifully, that is, disassemble and reassemble the request body, then we can then attach a hint to each object of this request - what happened at the corresponding point in the plan.
Syntax query tree
To do this, the request must first be parsed.
Since our system core is running on NodeJS , we made modules for it, you can find it on GitHub . In fact, these are extended "bindings" to the internals of the PostgreSQL parser itself. That is, the grammar is simply compiled in binary and bindings are made to it from the NodeJS side. We took other people's modules as a basis - there is no big secret here.
We feed the request body to the input of our function - at the output we get the parsed syntax tree in the form of a JSON object.

Now you can go through this tree in the opposite direction and collect the request with the indents, coloring, formatting that we want. No, it is not configurable, but it seemed to us that this would be convenient.

Mapping Query and Plan Nodes
Now let's see how we can combine the plan that we analyzed in the first step and the query that we analyzed in the second.
Let's take a simple example - we have a request that generates a CTE and reads it two times. He generates such a plan.

CTE
If you look at it carefully, before the 12th version (or starting from it with the keyword
MATERIALIZED), the formation of CTE is an absolute barrier for the planner .
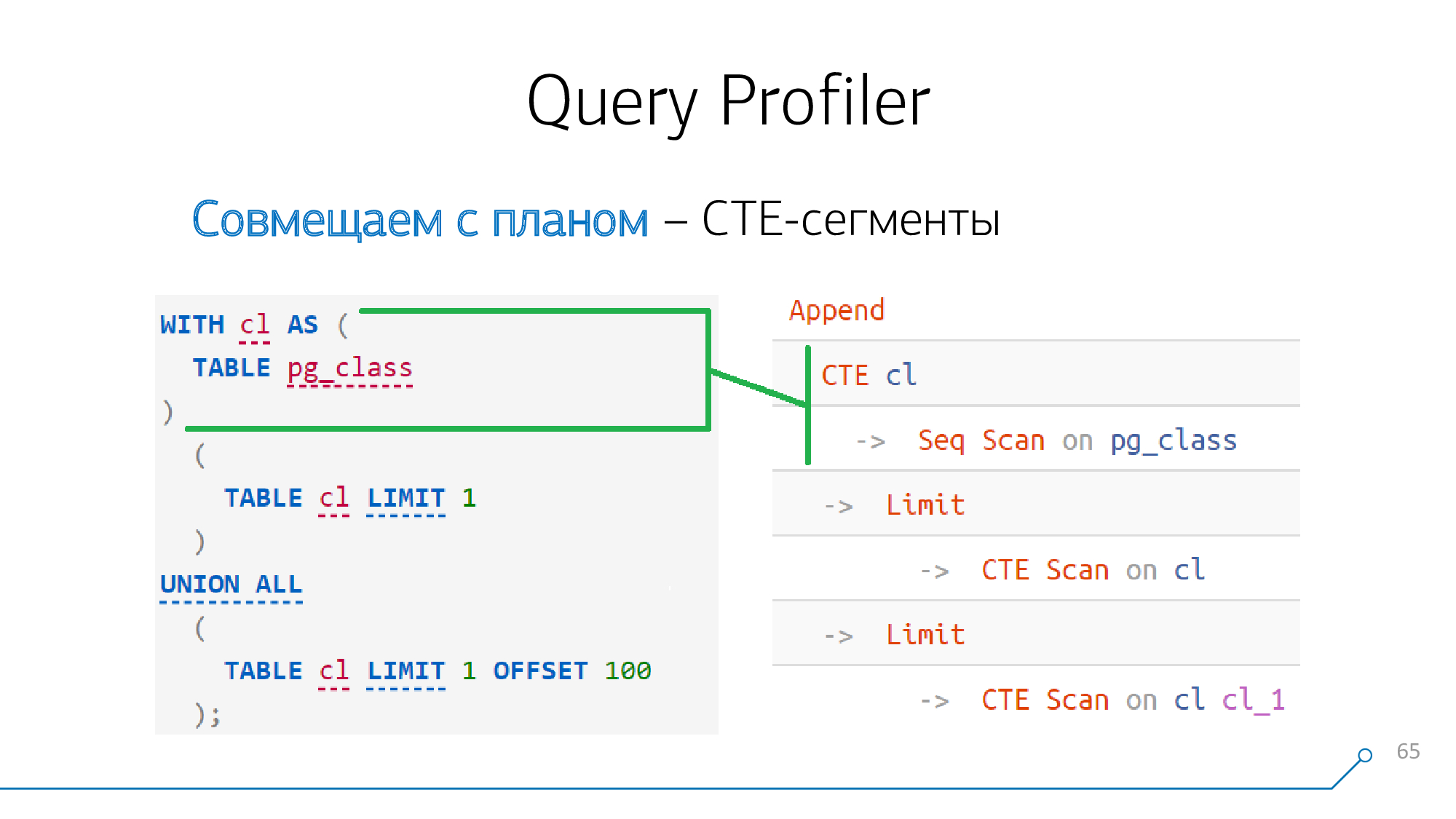
This means that if we see the generation of CTEs somewhere in the request and somewhere in the plan a node
CTE, then these nodes definitely "fight" with each other, we can immediately combine them.
Asterisk problem : CTEs can be nested.

There are very badly nested, and even the same names. For example, you can
CTE Ado it inside CTE X, and CTE Bdo it again at the same level inside CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...You must understand this when comparing. It is very difficult to understand this with “eyes” - even seeing the plan, even seeing the body of the request. If your CTE generation is complex, nested, requests are large - then it's completely unconscious.
UNION
If we have a keyword in our query
UNION [ALL](the operator of joining two selections), then either a node Appendor some one corresponds to it in the plan Recursive Union.

What "above" is above
UNIONis the first child of our node, what is "below" is the second. If UNIONseveral blocks are "glued" through us at once, then Appendthere will still be only one -node, but it will not have two children, but many - in order as they go, respectively:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Problem "with an asterisk" : inside the generation of a recursive selection (
WITH RECURSIVE) there can also be more than one UNION. But only the very last block after the last is always recursive UNION. Everything above is one but different UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...You also need to be able to “paste” such examples. In this example, we see that
UNIONthere were 3 segments in our request. Accordingly, one UNION corresponds to a Append-node, and the other corresponds to Recursive Union.

Read-write data
That's it, we spread it out, now we know which piece of the request corresponds to which piece of the plan. And in these pieces we can easily and naturally find those objects that are "readable".
From the point of view of the query, we do not know if this is a table or CTE, but they are denoted by the same node
RangeVar. And in terms of "readable" - this is also a fairly limited set of nodes:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
We know the structure of the plan and the query, we know the correspondence of the blocks, we know the names of the objects - we make an unambiguous comparison.

Again, an asterisk problem . We take the request, execute it, we don't have any aliases - we just read it twice from one CTE.

We look at the plan - what's the trouble? Why did our alias get out? We didn't order it. Why is he so "numbered"?
PostgreSQL adds it itself. You just need to understand that just such an alias does not make any sense for us for purposes of comparison with the plan, it is simply added here. Let's not pay attention to him.
The second task is "with an asterisk" : if we are reading from a partitioned table, then we will get a node
AppendorMerge Append, Which will consist of a large number of "children", and each of which is somehow Scan'th of the section of the table: Seq Scan, Bitmap Heap Scanor Index Scan. But, in any case, these "children" will not be complex queries - this is how these nodes can be distinguished from Appendwhen UNION.

We also understand such nodes, we collect them "in one pile" and say: " everything that you read from megatable is right here and down the tree ."
"Simple" nodes for receiving data

Values Scanin plan matches VALUESin request.
Result- this is a request without FROMlike SELECT 1. Or when you have a knowingly false expression in the WHERE-block (then the attribute occurs One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan"Map" to the SRF of the same name.
But with nested queries, everything is more complicated - unfortunately, they do not always turn into
InitPlan/ SubPlan. Sometimes they turn into ... Joinor ... Anti Join, especially when you write something like WHERE NOT EXISTS .... And it is not always possible to combine there - there are no operators corresponding to the plan nodes in the text of the plan.
Again, a task with an asterisk : several
VALUESin the request. In this case, and in the plan, you will receive several nodes Values Scan.

"Numbered" suffixes will help to distinguish them from one another - it is added exactly in the order of finding the corresponding
VALUES-blocks along the request from top to bottom.
Data processing
It seems that everything in our request has been sorted out - only remains
Limit.
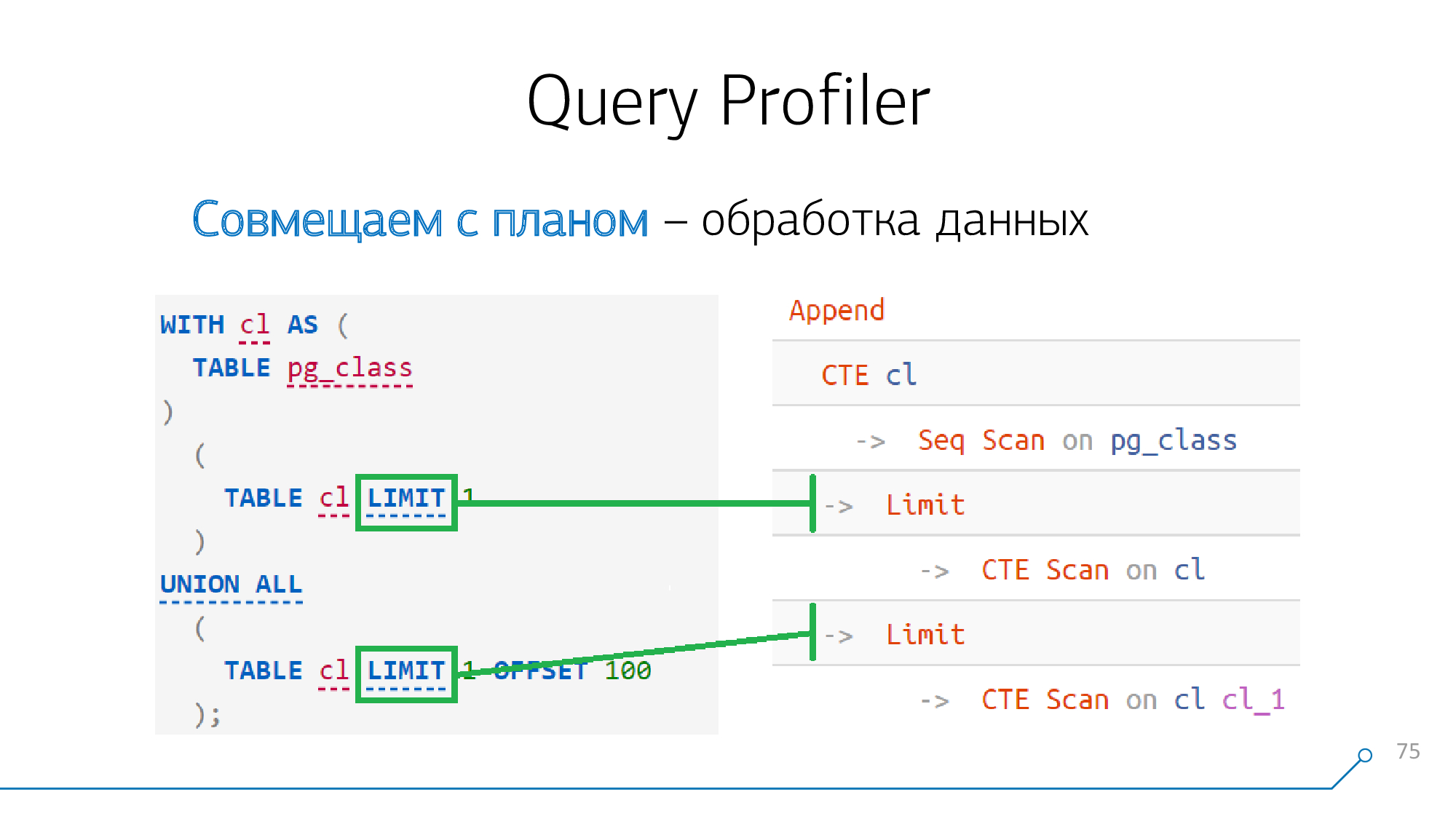
But everything is simple - such as the nodes
Limit, Sort, Aggregate, WindowAgg, Unique"mapyatsya" one-to-one to the corresponding statements in the request, if they are there. There are no "stars" and no difficulties.

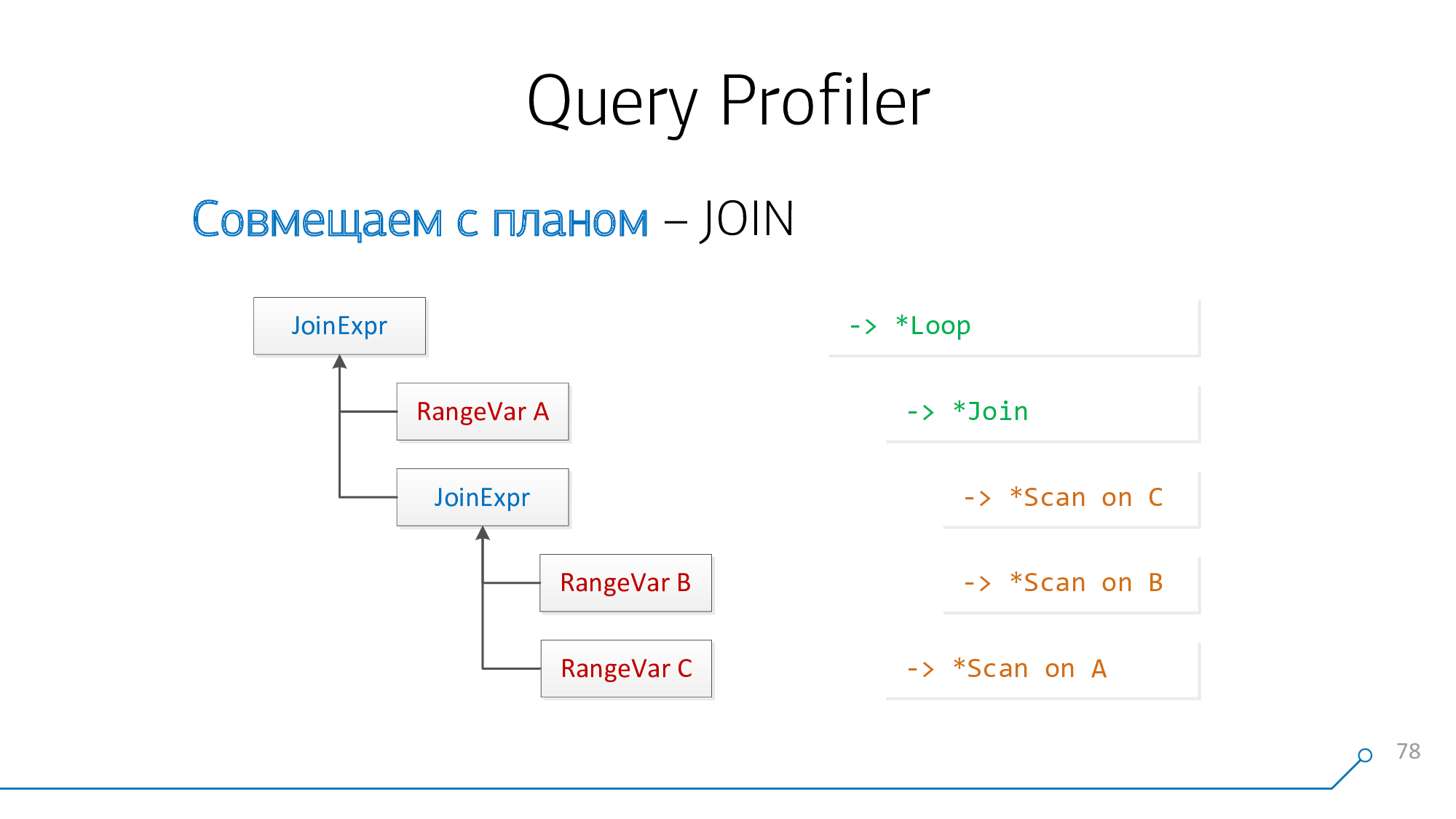
JOIN
Difficulties arise when we want to combine with
JOINeach other. This is not always done, but you can.

From the point of view of the query parser, we have a node
JoinExprthat has exactly two children - left and right. This, respectively, is what is "above" your JOIN and what is "under" it in the request is written.
And from the point of view of the plan, these are two descendants of some
* Loop/ * Join-node. Nested Loop, Hash Anti Join... - that's something.
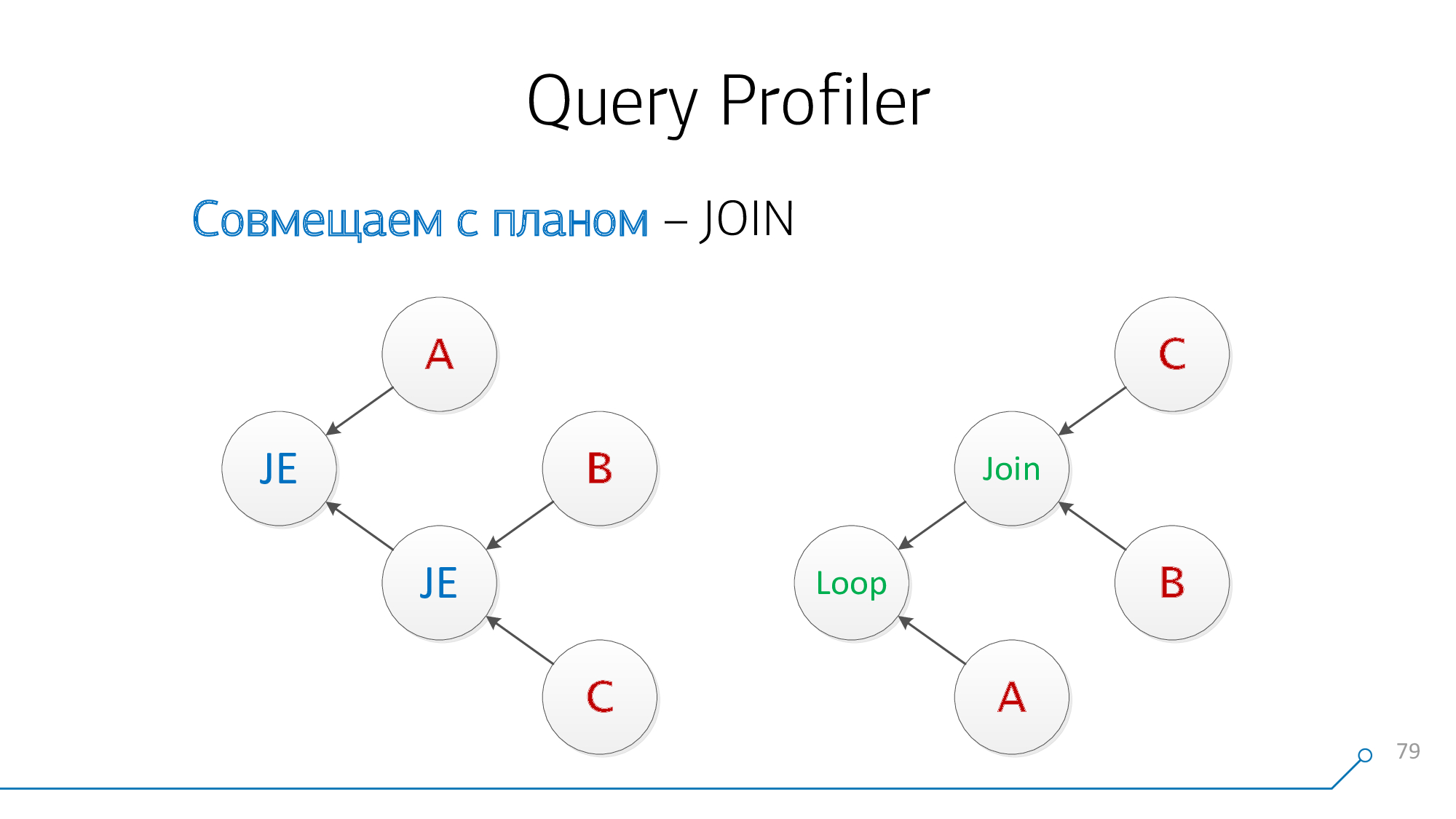
Let's use a simple logic: if we have plates A and B that "join" each other in the plan, then in the request they could be located either
A-JOIN-Bor B-JOIN-A. Let's try to combine this way, try to combine it the other way around, and so on until such pairs run out.
Take our syntax tree, take our outline, look at them ... not like that!
Let's redraw it in the form of graphs - oh, it has already become something like something!
Let's notice that we have nodes that have children B and C at the same time - we don't care in which order. Let's combine them and turn the knot picture.

Let's see again. Now we have nodes with children A and pairs (B + C) - compatible with them too.
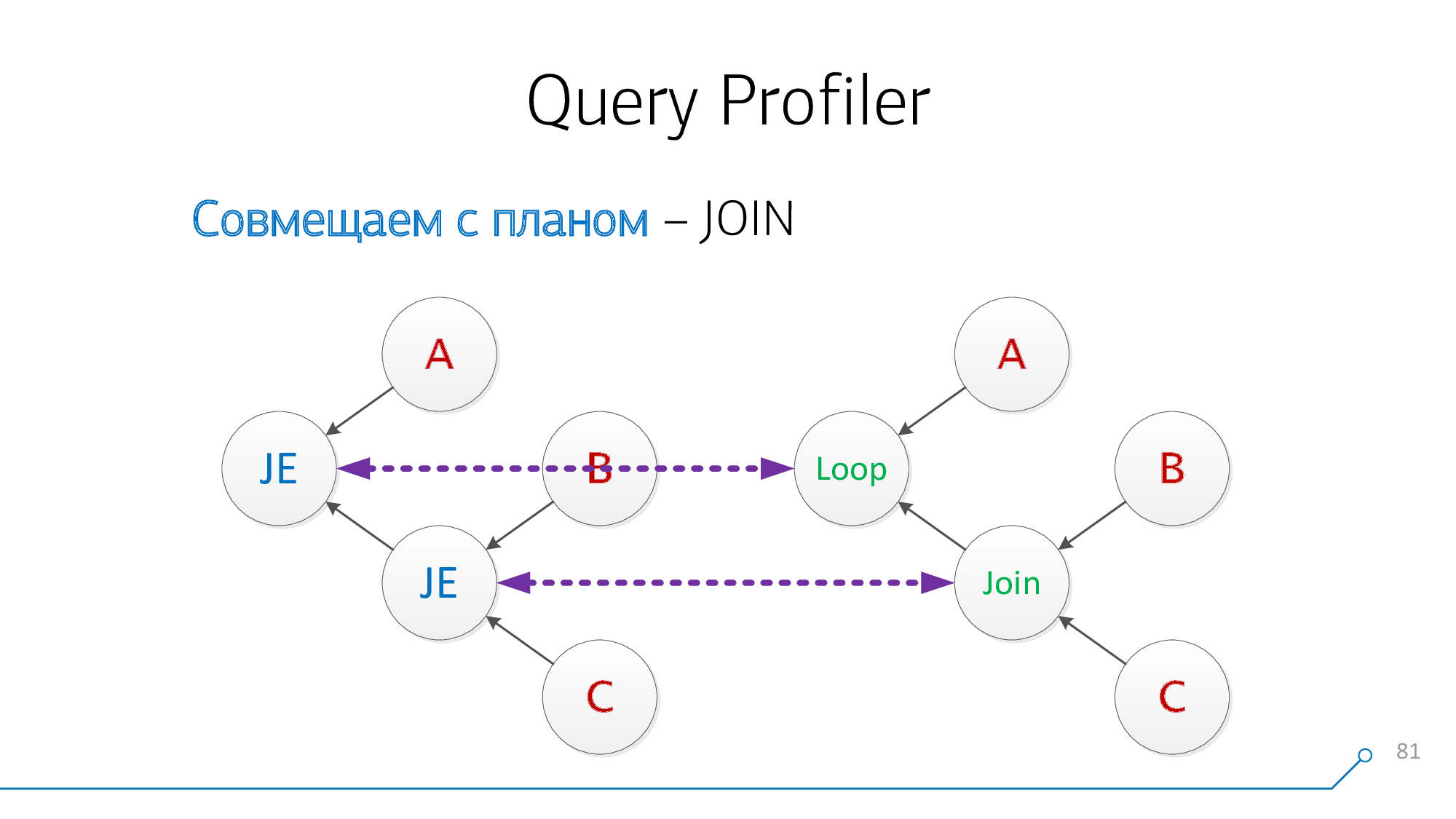
Excellent! It turns out that we have
JOINsuccessfully combined these two from the query with the plan nodes.
Alas, this task is not always solved.
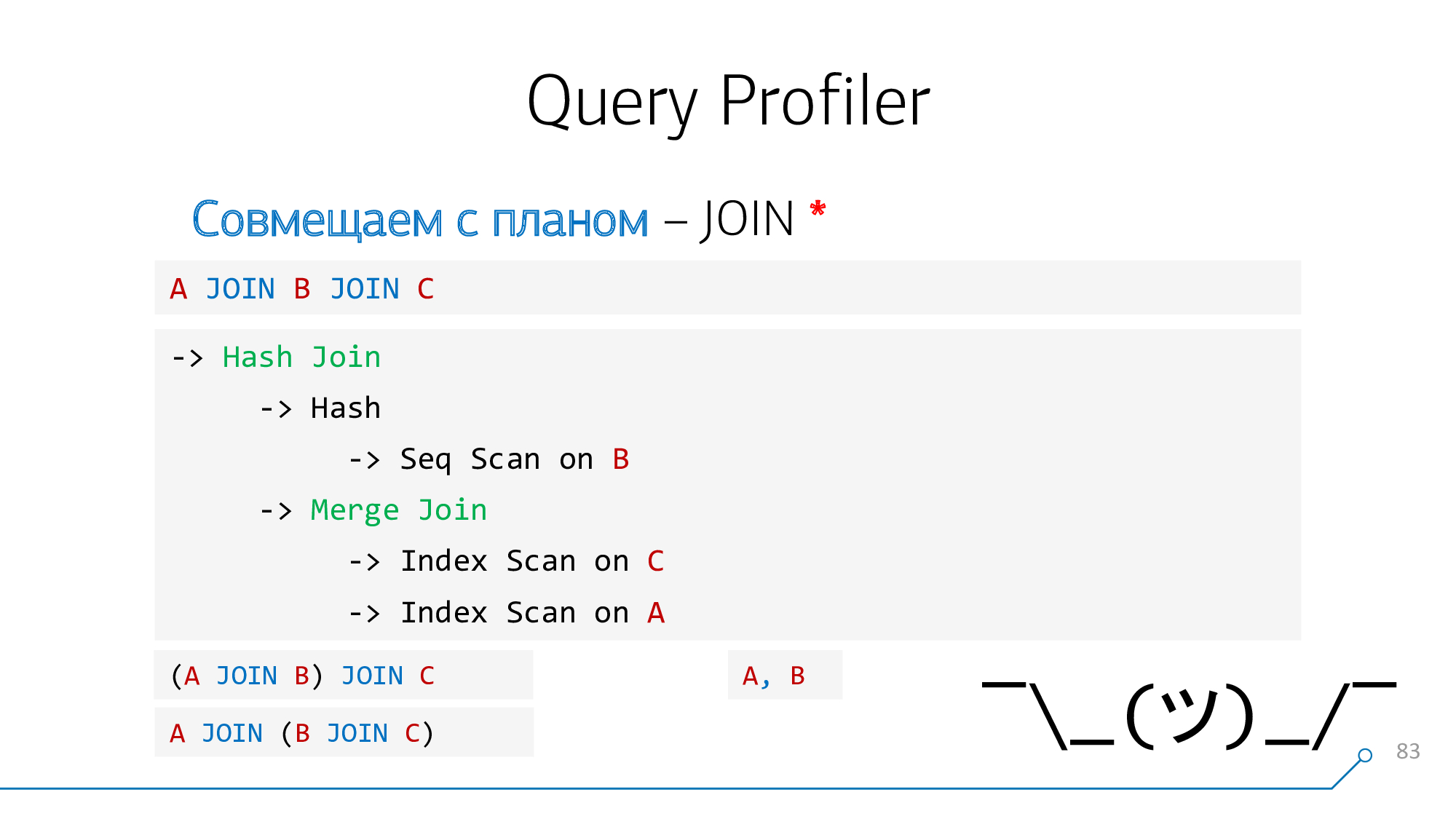
For example, if in the query
A JOIN B JOIN C, but in the plan, the "extreme" nodes A and C were connected first of all. And in the query there is no such operator, we have nothing to highlight, there is nothing to bind the hint to. It's the same with the "comma" when you write A, B.
But, in most cases, almost all the nodes can be “untied” and you get this kind of profiling on the left in time - literally, like in Google Chrome, when you analyze JavaScript code. You can see how long each line and each statement were "executed".

And to make it more convenient for you to use all this, we made an archive storage , where you can save and then find your plans along with associated requests or share a link with someone.
If you just need to bring an unreadable query into an adequate form, use our "normalizer" .