CPU limits and throttling
Like many other Kubernetes users, Google highly recommends adjusting CPU limits . Without this configuration, the containers in the node can take up all the processor power, which, in turn, will cause important Kubernetes processes (for example
kubelet) to stop responding to requests. Thus, setting CPU limits is a good way to protect your nodes.
Processor limits set the container the maximum processor time that it can use for a specific period (100ms by default), and the container will never exceed this limit. Kubernetes uses a special tool CFS Quota to throttle the container and prevent it from exceeding the limit., however, in the end, such artificial processor limits lower performance and increase the response time of your containers.
What can happen if we don't set CPU limits?
Unfortunately, we ourselves had to deal with this problem. Each node has a process responsible for managing containers
kubelet, and it has stopped responding to requests. The node, when this happens, will go into the state NotReady, and the containers from it will be redirected somewhere else and will create the same problems already on new nodes. Not an ideal scenario, to put it mildly.
Manifesting throttling and responsiveness issues
The key metric for tracking containers is
trottlinghow many times your container has been throttled. We noticed with interest the presence of throttling in some containers, regardless of whether the load on the processor was maximum or not. For example, let's take a look at one of our main APIs:
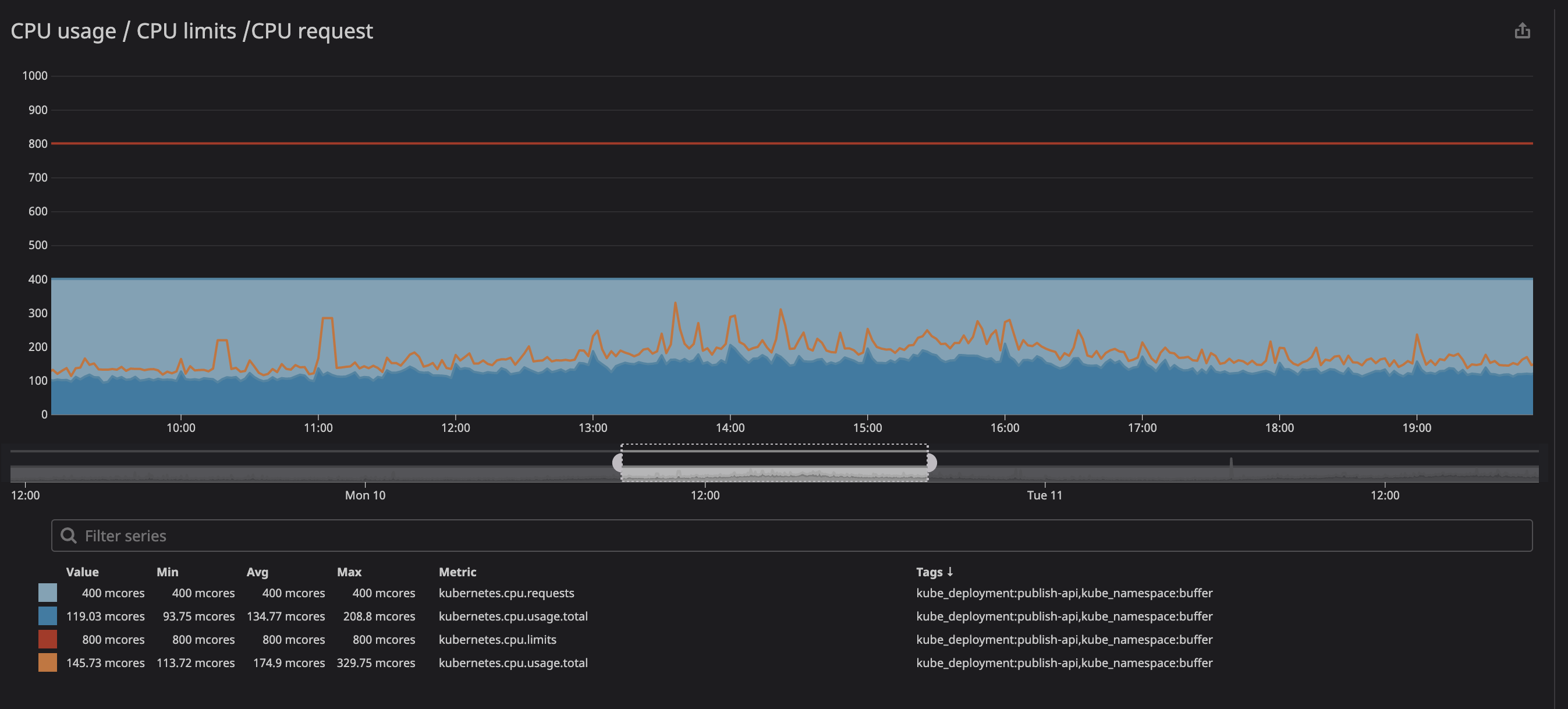
As you can see below, we set the limit at
800m(0.8 or 80% of the core), and the peak values are at best 200m(20% of the core). It would seem that we still have a lot of processing power before throttling the service, however ...
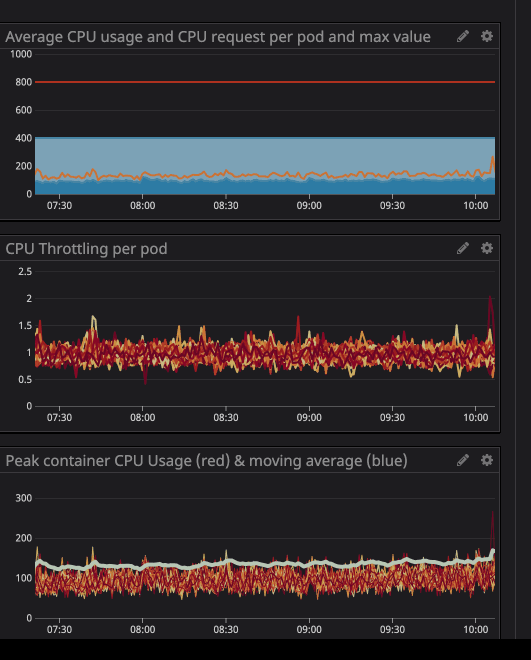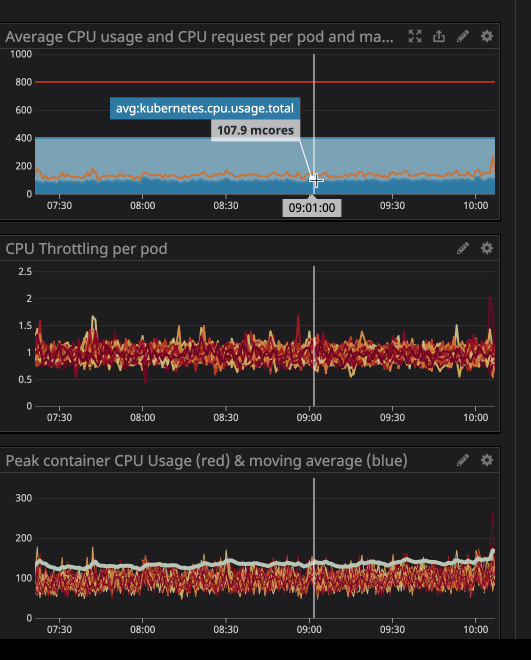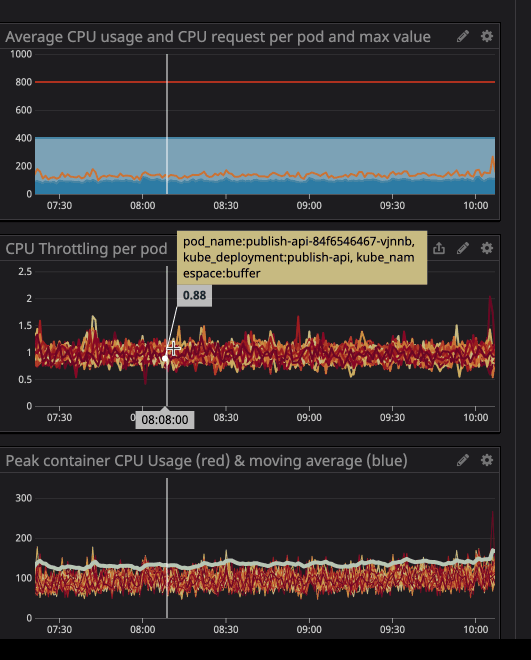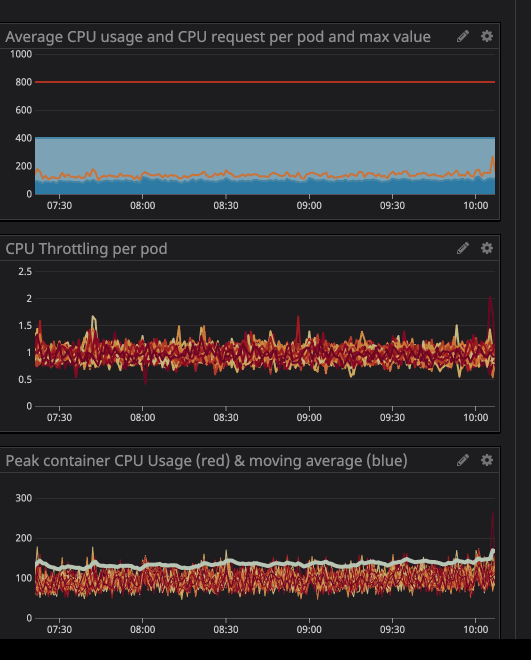
You may have noticed that even when the load on the processor is below the specified limits - much lower - throttling still works.
Faced with this, we soon discovered several resources (a problem on github , a presentation on zadano , a post on omio ) about the drop in performance and response time of services due to throttling.
Why do we see throttling under low CPU usage? The short version reads like this: "There is a bug in the Linux kernel that triggers unnecessary throttling of containers with specified processor limits." If you are interested in the nature of the problem, you can read the presentation ( video and text variants) by Dave Chiluk.
Removing processor limits (with extreme caution)
After lengthy discussions, we decided to remove processor restrictions from all services that directly or indirectly affect critical functionality for our users.
The decision turned out to be difficult, as we highly value the stability of our cluster. In the past, we have already experimented with the instability of our cluster, and then the services consumed too many resources and slowed down the work of our entire node. Now everything was a little different: we had a clear understanding of what we expect from our clusters, as well as a good strategy for implementing the planned changes.

Business correspondence on a pressing issue.
How to protect your nodes when removing restrictions?
Isolating "unlimited" services:
In the past, we have seen some nodes get into a state
notReady, primarily due to services that were consuming too many resources.
We decided to place such services in separate ("tagged") nodes so that they would not interfere with the "linked" services. As a result, by marking some nodes and adding a toleration parameter to the “unrelated” services, we gained more control over the cluster, and it became easier for us to identify problems with the nodes. To carry out similar processes yourself, you can familiarize yourself with the documentation .
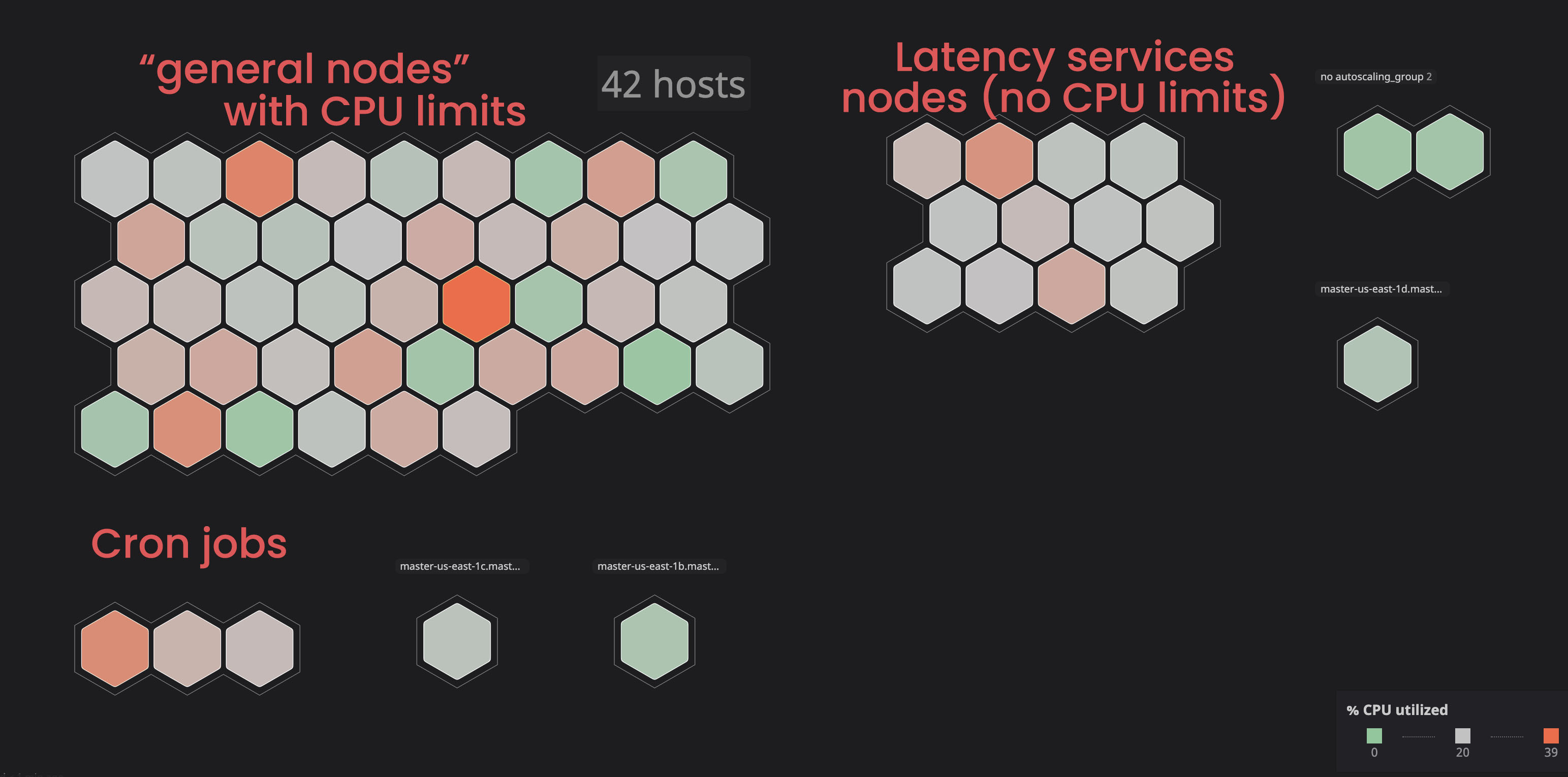
Assigning the correct processor and memory request:
Most of all, we feared that the process would consume too many resources and the node would stop responding to requests. Since now (thanks to Datadog) we could clearly observe all the services on our cluster, I analyzed several months of operation of those that we planned to designate as "unrelated". I simply set the maximum CPU utilization with a margin of 20%, and thus allocated space in the node in case k8s tries to assign other services to the node.
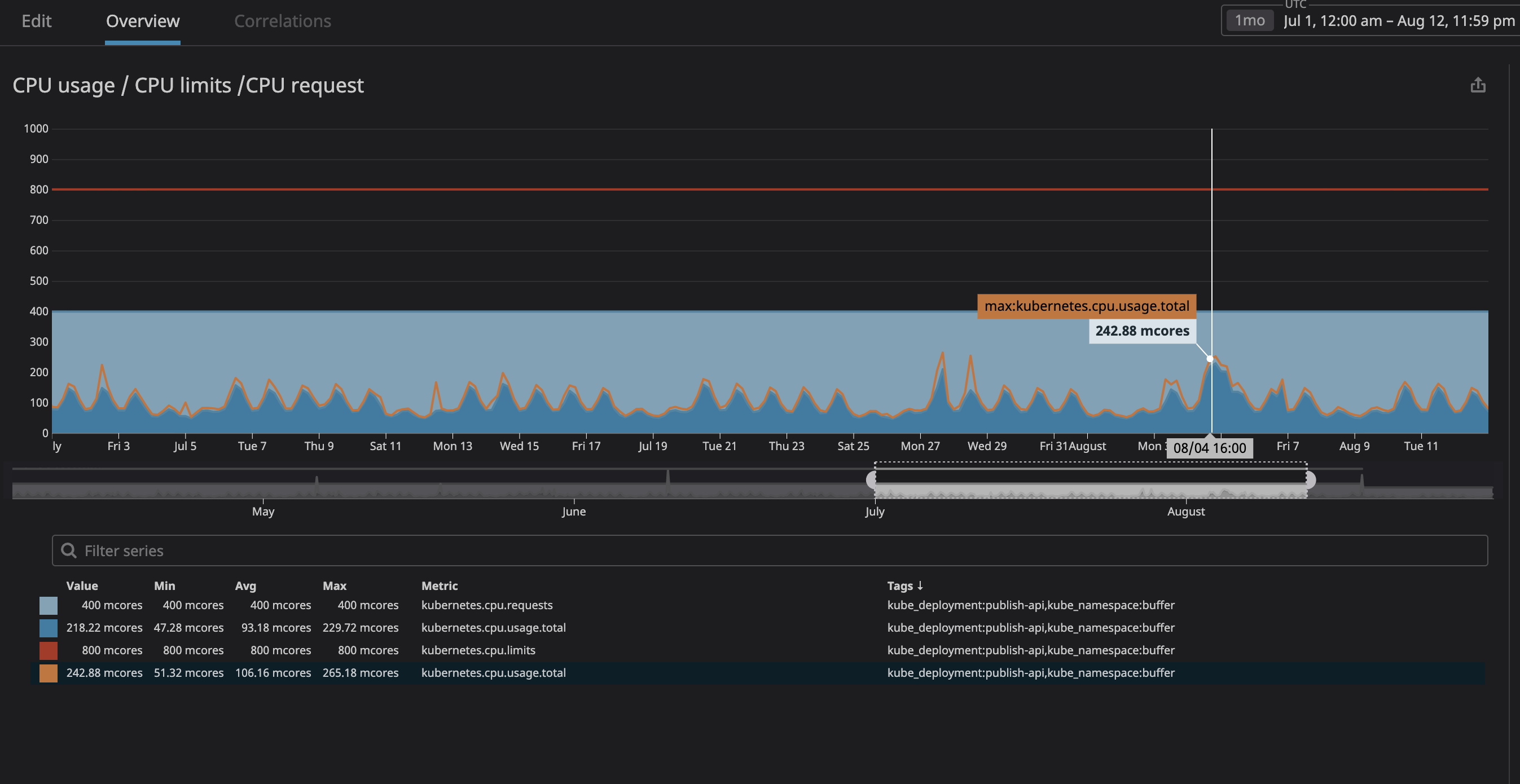
As you can see in the graph, the maximum processor load has reached
242mCPU cores (0.242 processor cores). For a processor request, it is enough to take a number slightly larger than this value. Note that since the services are user-centric, the load peaks coincide with the traffic.
Do the same with memory usage and queries, and voila - you're all set! For more safety, you can add horizontal autoscaling of pods. Thus, every time when the load on resources is high, autoscaling will create new pods, and kubernetes will distribute them to nodes with free space. In case there is no space left in the cluster itself, you can set yourself an alert or configure the addition of new nodes through their autoscaling.
Of the minuses, it is worth noting that we have lost in the " density of containers ", i.e. the number of containers working in one node. We may also have a lot of "indulgences" at low traffic density, and there is also a chance that you will reach a high processor load, but node autoscaling should help with the latter.
results
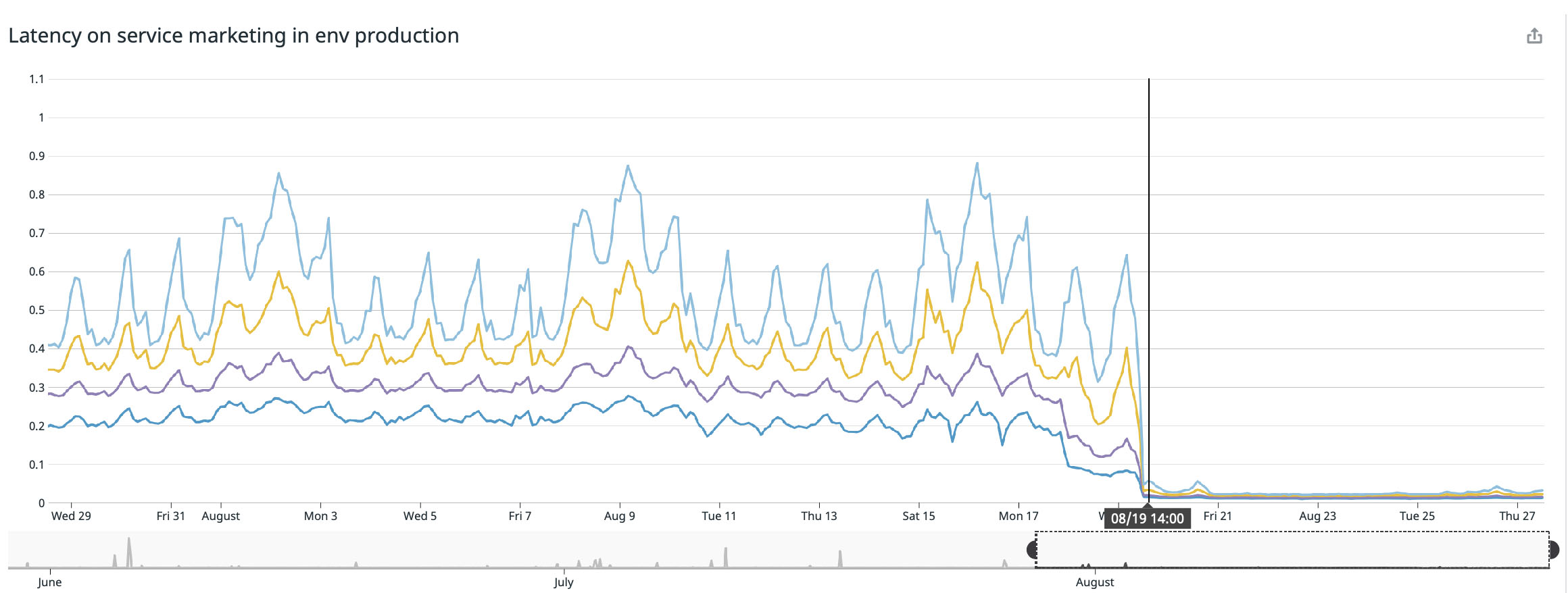
I am delighted to publish these excellent results of experiments over the past few weeks, we have already noticed significant improvement in response among all modified services:
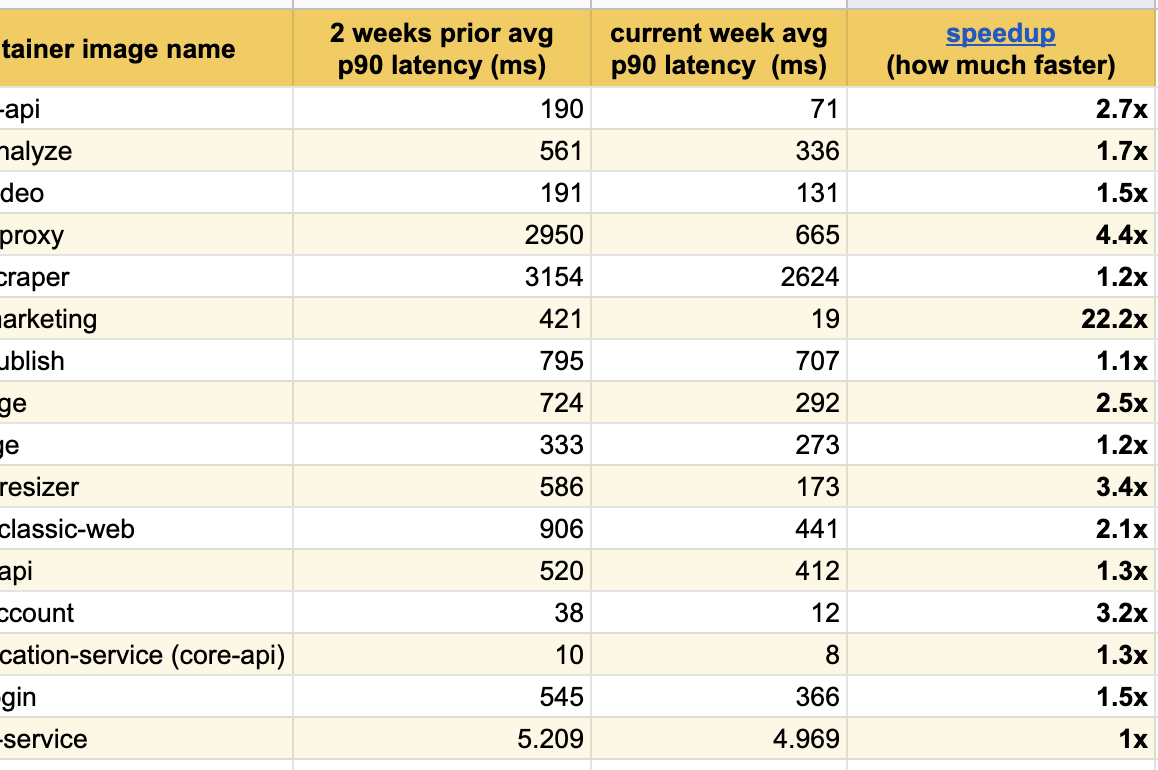
We achieved the best result on our main page ( buffer.com ), where the service was accelerated twenty-two times!
Is the Linux kernel bug fixed?
Yes, the bug has already been fixed, and the fix has been added to the kernel of distributions version 4.19 and higher.
However, while reading the kubernetes issue on github for September 2, 2020, we still come across references to some Linux projects with a similar bug. I believe that some Linux distributions still have this bug and are currently working on a fix.
If your version of the distribution is lower than 4.19, I would recommend updating to the latest, but you should try to remove the processor limits anyway and see if throttling persists. Below you can find an incomplete list of managing Kubernetes services and Linux distributions:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
What if the fix fixed the throttling problem?
I'm not sure if the problem has been completely resolved. When we get to the fixed kernel version, I'll test the cluster and update the post. If someone has already updated, I would like to review your results with interest.
Conclusion
- If you work with Docker containers under Linux (it doesn't matter Kubernetes, Mesos, Swarm, or whatever), your containers can lose performance due to throttling;
- Try updating to the latest version of your distribution in the hope that the bug has already been fixed;
- Removing processor limits will solve the problem, but this is a dangerous technique that should be used with extreme caution (it is better to update the kernel first and compare the results);
- If you removed the processor limits, carefully monitor your processor and memory usage, and make sure that your processor resources exceed the consumption;
- A safe option would be to autoscale pods to create new pods in case of high load on hardware, so that kubernetes assigns them to free nodes.
I hope this post helps you improve the performance of your container systems.
PS Here the author is in correspondence with readers and commentators (in English).