- Good evening, my name is Masha, I work in the Eddila data analysis department, and today we have a lecture about testing with you.

First, we will discuss with you what types of testing there are in general, and I will try to convince you why you need to write tests. Then we will talk about what we have in Python to work directly with tests, with their writing and auxiliary modules. At the end, I will tell you a little about CI - an inevitable part of life in a large company.
I would like to start with an example. I will try to explain with very scary examples why it is worth writing tests.
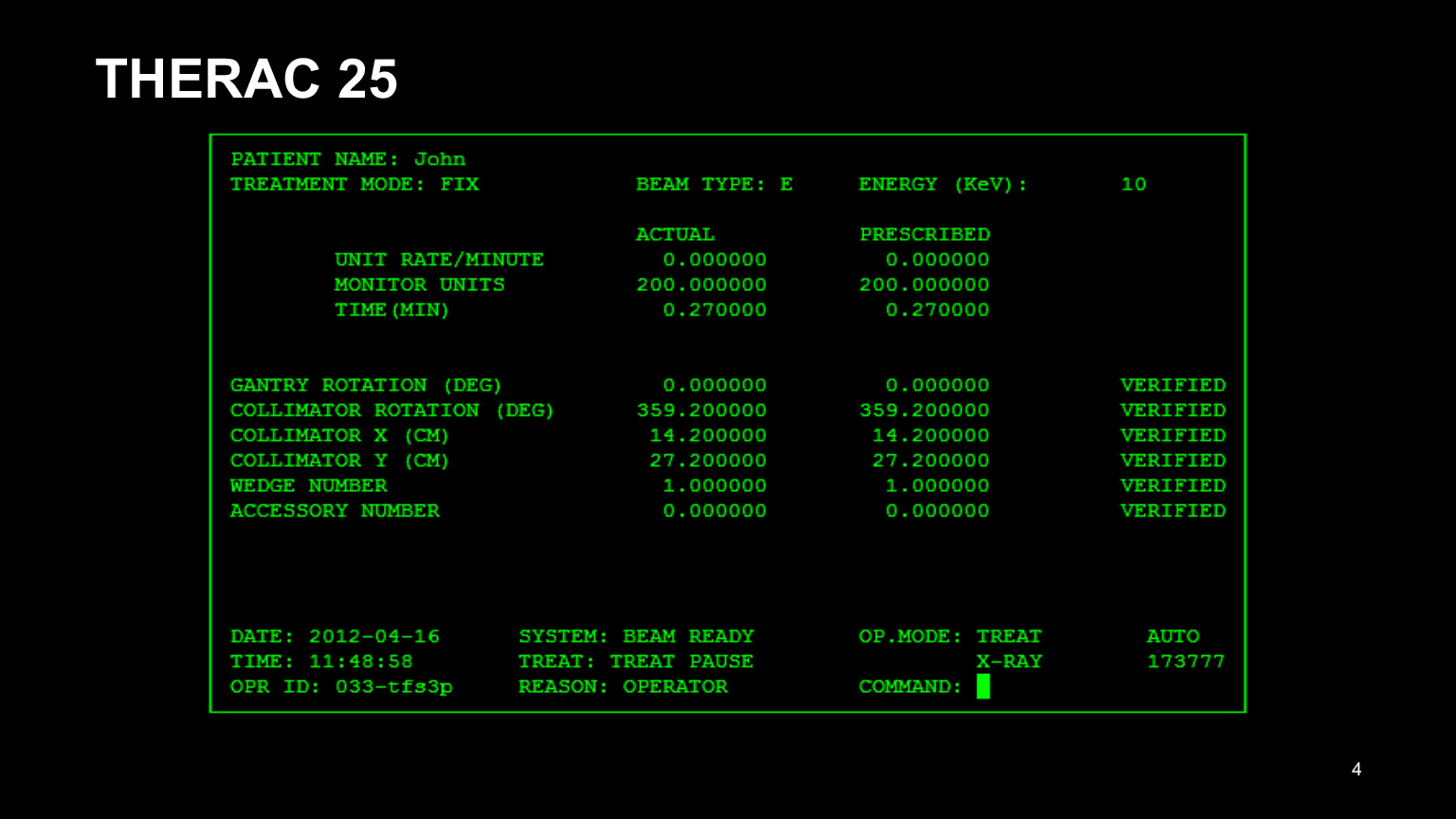
Here is the interface of the THERAC 25 program. That was the name of the device for radiation therapy of cancer patients, and everything went extremely badly with it. First of all, it had a bad interface. Looking at him, one can already understand that he is not very good: it was inconvenient for the doctors to drive in all these numbers. As a result, they copied the data from the previous patient's record and tried to edit only what needed to be edited.
It is clear that they forgot to correct half and were mistaken. As a result, patients were treated incorrectly. UI is also worth testing, there are never too many tests.
But besides the bad interface, there were many more problems in the backend. I have identified two that seemed to me the most egregious:
- . , . , . , .
- C . THERAC , — , . . , , , - , - — .
It would be worth writing tests. Because it ended up with five recorded deaths, and it's unclear how many more people have suffered from being given too much drugs.

There is another example that in some situations writing tests can save you a lot of money. This is the Mars Climate Orbiter - a device that was supposed to measure the atmosphere in the atmosphere of Mars, see what the climate was like.
But the module, which was on the ground, gave commands in the SI system, in the metric system. And the module in the orbit of Mars thought it was a British system of measures, interpreted it incorrectly.
As a result, the module entered the atmosphere at the wrong angle and collapsed. 125 million dollars just went into the trash, although it would seem that it is possible to simulate the situation on tests and avoid this. But it didn't work out.
Now I'll talk about more prosaic reasons why you should write tests. Let's talk about each item separately:
- Tests make sure that the code works and they calm you down a bit. In those cases for which you wrote tests, you can be sure that the code works - if, of course, you wrote it well. Sleep better. It is very important.
- . . , , , . , . , .
, - , — , - . , . , , . , , , git blame, , , , . - . , . , . , , . - - , - - . , , , . - .
- , . ? , , , , : , . 500 -, . . .
- : — . , , . , , .
, , , . , , . - . — , . , , . , .
: - . , , . , , , - , .
Now I would like to talk a little about what are the classifications of types of testing. There are a lot of them. I will only mention a few.
The testing process is divided into black box testing, white and gray testing.
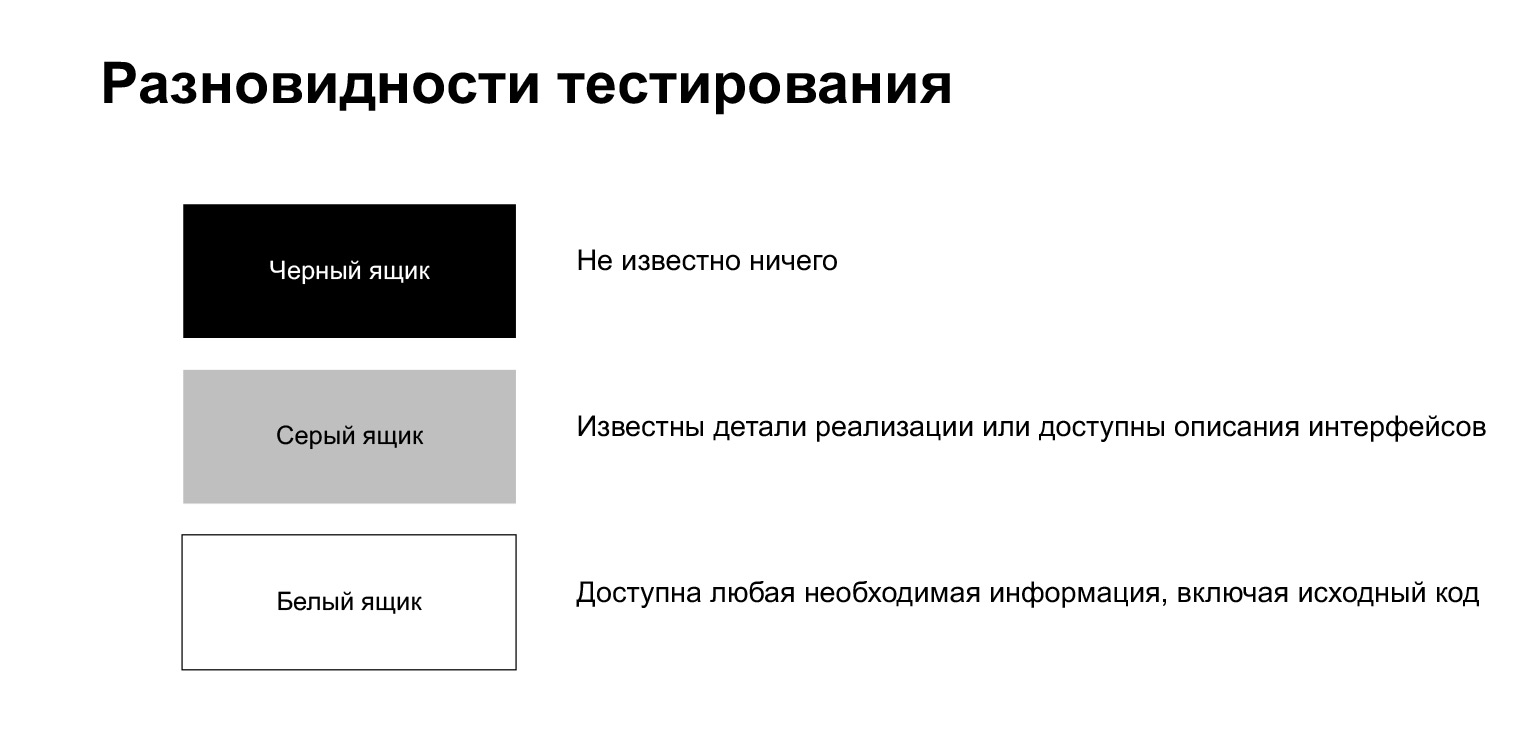
Black box testing is a process when the tester knows nothing about what's inside. He, like an ordinary user, does something without knowing any implementation specifics.
White-box testing means that the tester has access to any information he needs, including the source code. We are in such a situation when we write a test on our own code.
Gray box testing is something in between. This is when you know some implementation details, but not the whole thing.
Also, the testing process can be divided into manual, semi-automatic and automatic. Manual testing is done by a person. Let's say he clicks buttons in the browser, clicks somewhere, looks to see what is broken or not broken. Semi-automated testing is when a tester runs test scripts. We can say that we are in such a situation when we run and run our tests locally. Automated testing does not involve human participation: tests should be run automatically, not by hand.
Also, tests can be divided by level of detail. Here they are usually divided into unit and integration tests. There may be discrepancies. There are people who call any autotests unit tests. But a more classical division is something like this.
Unit tests check the operation of individual components of the system, and integration tests check the bundle of some modules. Sometimes there are also system tests that check the operation of the entire system as a whole. But it seems that this is more of a big variant of integration tests.
Tests for our code are unit and integration tests. There are people who believe that only integration tests should be written. I am not one of those, I think that everything should be in moderation, and both unit tests, when you are testing one component, and integration tests, when you are testing something big, are useful.
Why do I think so? Because unit tests are usually faster. When you need to tweak something, you will be very annoyed that you clicked the "run test" button, and then wait three minutes for the database to start, migrations are done, something else happens. For such cases, unit tests are useful. They can be run quickly and conveniently, run one at a time. But when you've fixed the unit tests, great, let's fix the integration tests.
Integration tests are also a very necessary thing, a big plus is that they are more about the system. Another big plus: they are more resistant to code refactoring. If you are more likely to rewrite some small function, then you are unlikely to change the overall pipeline with the same frequency.

There are many more different classifications. I will quickly go over what I have written here, but I will not dwell in detail, these are words that you can hear somewhere else.
Smoke tests are tests for critical functionality, the very first and simplest tests. If they break, then you no longer need to test, but you need to go to fix them. Let's say the application started, did not crash - great, the smoke test passed.
There are regression tests - tests for old functionality. Let's say you roll a new release and need to check that nothing was broken in the old one. This is the task of regression tests.
There are compatibility tests, installation tests. They check that everything works correctly for you in different OS and different OS versions, in different browser and different browser versions.
Acceptance tests are acceptance tests. I already talked about them, they talk about whether your change can be rolled into production or not.
There is also alpha and beta testing. Both of these concepts are more related to the product. Usually, when you have a more or less ready version of a release, but not everything is fixed there, you can give it either to conditionally external people, or to external people, volunteers, so that they find bugs for you, report them and you can release a very good version. The less finished is the alpha version, the more finished is the beta. In beta testing, almost everything should be fine by now.
Then there are performance and stress tests, load testing. They check, for example, how your application is handling the load. There is some code. You have calculated how many users, requests it will have, what RPS, how many requests will come per second. We simulated this situation, launched it, looked - it holds, does not hold. If it doesn't, think about what to do next. Perhaps to optimize the code or increase the amount of hardware, there are different solutions.
Stress tests are about the same, only the load is higher than expected. If the performance tests give the level of load that you expect, then in stress tests you can increase the load until it breaks.
Linters are a bit separate here. I'll tell you about linters a little later, these are code formatting tests, a style guide. In Python, we're lucky to have PEP8, a straightforward style guide that everyone should follow. And when you write something, you usually find it difficult to follow the code. Suppose you forgot to put an empty line, or made an extra line, or left a line that was too long. It gets in the way, because you get used to the fact that your code is written in the same style. Linters allow you to automatically catch such things.
With the theory, everything, then I will talk about what is in Python.

Here is a list of some of the libraries. I will not go into detail about all of them, but I will be about most of them. Of course, we'll talk about unittest and pytest. These are libraries that are used directly for writing tests. Mock is a helper library for creating mock objects. We will also talk about her. doctest is a module for testing documentation, flake8 is a linter, we'll also look at them. I won't talk about pylama and tox. If you are interested, you can see for yourself. Pylama is also a linter, even a metalinter, it combines several packages, very convenient and good. And the tox library is needed if you need to test your code in different environments - for example, with different versions of Python or with different versions of libraries. Tox helps a lot in this sense.
But before talking about different libraries, I will start with the banality. Feel free to use assert in your code. It's not a shame. It often helps to understand what's going on.

Suppose there is a function that calculates ordinal statistics, two asserts are written to it. Assert should be written in a function in cases where it is completely extreme nonsense that should not be in the code. These are very extreme cases, most likely, you will not even meet them in production. That is, if you mess up in the code, it will most likely fail in your tests.
Assert helps when you are prototyping, you do not have production code yet, you can stick assert everywhere - in the called function, anywhere. This is not good for serious projects, but quite good at the prototyping stage.
Let's say you want to disable assert for some reason - for example, you want it to never fire in production. Python has a special option for this.

I'll tell you what doctest is. This is a module, a Python standard library for testing documentation. Why is it good? Documentation that is written in code tends to break very often. There is a very small toy function here, you can see everything. But when you have a large code, a lot of parameters, and you have added something at the end, then with a very high probability you will forget to correct the docstrings. Doctest avoids these things. You fix something, don't update here, run doctest, and it will crash for you. So you will remember what exactly you did not correct, go and correct.
What does it look like? Doctest looks for these Christmas trees in docstrings, then executes them and compares what is obtained.

Here's an example of running doctest. We started it, we see that we have two tests and one of them fell - completely on the case. Great, we saw some good clear information about the error.

Link from the slide
The doctest has some helpful directives that might come in handy. I will not talk about all of them, but some that seemed to me the most common, I put on the slide. The SKIP directive allows you not to run a test on a marked example. The IGNORE_EXCEPTION_DETAIL directive ignores the EXCEPTION test. ELLIPSIS allows you to write ellipsis instead of anywhere in the output. FAIL_FAST stops after the first failed test. Everything else can be read in the documentation, there is a lot. I'd better show you with an example.

This example has an ELLIPSIS directive and an IGNORE_EXCEPTION_DETAIL directive. You see the K-th ordinal statistics in the ELLIPSIS directive, and we expect something to come that starts with a nine and ends with a nine. There could be anything in the middle. Such a test will not fail.
Below is the IGNORE_EXCEPTION_DETAIL directive, it will only check what came in the AssertionError. See, we wrote blah blah blah there. The test will pass, it will not compare blah blah blah with expected iterable as first argument. It will only compare AssertionError to AssertionError. These are useful things that you can use.

Then the plan is this: I will tell you about unittest, then about pytest. I'll say right away that I probably don't know the pros of unittest, other than that it's part of the standard library. I don't see a situation that would force me to use unittest now. But there are projects that use it, in any case it is useful to know what the syntax looks like and what it is.
Another point: tests written in unittest know how to run pytest right out of the box. He does not care. (…)
Unittest looks like this. There is a class starting with the word test. Inside, a function starting with the word test. The test class inherits from unittest.TestCase. I must say right away that one test here is written correctly, and the other test is incorrect.
The top test, where the normal assert is written, will fail, but it will look strange. Let's get a look.

Start command. You can write unittest main in the code itself, you can call it from Python.

We ran this test and we see that it wrote an AssertionError, but it did not write where it fell - unlike the next test, which used self.assertEqual. It is clearly written here: three does not equal two.

It must be repaired, of course. But then this magic output was not visible on the screen.
Let's take another look. In the first case, we wrote assert, in the second, self.assertEqual. Unfortunately, this is the only way in unittest. There are special functions - self.assertEqual, self.assertnotEqual and 100,500 more functions that you need to use if you want to see an adequate error message.
Why it happens? Because assert is a statement that receives a bool and possibly a string, but in this case bool. And he sees that he has true or false, and he has nowhere to take the left and right sides. Therefore, unittest has special functions that will correctly display error messages.
This is not very convenient in my opinion. More precisely, it is not convenient at all, because these are some special methods that are only in this library. They are different from what we are used to in ordinary language.

You don't have to remember this - we'll talk about pytest later, and I hope you will mostly write in it. Unittest has a zoo of functions to use if you want to test something and get good error messages.
Next, let's talk about how to write fixtures in unittest. But to do that, I first need to tell you what fixtures are. These are functions that are called before or after the test is run. They are needed if the test needs to perform a special setting - create a temporary file after the test, delete the temporary file; create a database, delete a database; create a database, write something to it. In general, whatever. Let's see how it looks in unittest.

Unittest has special methods setUp and tearDown for writing a fixture. Why they are still not written according to PEP8 is a big mystery to me. (...)
SetUp is what is done before the test, tearDown is what is done after the test. It seems to me that this is an extremely inconvenient design. Why? Because, firstly, my hand does not rise to write these names: I already live in a world where there is still PEP8. Secondly, you have a temp file, about which you have nothing in the arguments of the test itself. Where did he come from? It is not very clear why it exists and what it is all about.
When we have a small class that clings to the screen, it's cool, you can see it. And when you have this huge sheet, you are tortured to search for what it was and why he is like that, why he behaves like that.
There is another not-so-convenient feature with fixtures in unittest. Suppose we have one test class that needs a temporary file and another test class that needs a database. Excellent. You wrote one class, did setUp, tearDown, did create / delete a temporary file. We wrote another class, in it we also wrote setUp, tearDown, created / deleted a database in it.
Question. There is a third group of tests that need both. What to do with all this? I see two options. Or take and copy-paste the code, but it's not very convenient. Or create a new class, inherit from the previous two, call super. In general this will work too, but looks like a wild overkill for tests.

Therefore, I want your familiarity with unittest to remain like this, on a theoretical level. Next we will talk about a more convenient way to write tests, a more convenient library, this is pytest.
First, I'll try to tell you why pytest is convenient.

Link from the slide
First point: in pytest, asserts usually work, the ones you are used to, and they give normal information about the error. Second: there is good documentation for pytest, where a bunch of examples are disassembled, and anything you want, everything that you do not understand can be viewed.
Third, tests are just functions that start with test_. That is, you do not need an extra class, you just write a regular function, call it test_ and it will be run through pytest. This is convenient because the easier it is to write tests, the more likely you are to write the test rather than score it.
Pytest has a bunch of handy features. You can write parameterized tests, it is convenient to write fixtures of different levels, there are also some niceties that you can use: xfail, raises, skip, and some others. There are many plugins in pytest, plus you can write your own.

Let's see an example. This is how tests written in pytest look like. The meaning is the same as on unittest, only it looks much more concise. The first test is generally two lines.

Run the command python -m pytest. Excellent. Two tests passed, everything is fine, we can see what they passed and in what time.

Now let's break one test and make it so that we have information about the error. Print assert 3 == 2 and error. That is, we see: despite the fact that we wrote a regular assert, we correctly displayed information about the error, although before that in unittest we said that assert accepts a bool in a string or bool, so it is problematic to display information about the error.
One might wonder why this all works? Because in pytest they tried and tidied up the ugly part for the interface. Pytest first parses your code, and it appears as a kind of tree structure, an abstract syntax tree. In this structure, you have operators at the vertices, and operands at the leaves. Assert is an operator. It stands at the top of the tree, and at this moment, before giving everything to the interpreter, you can replace this assert with an internal function that does introspection and understands what is in your left and right sides. In fact, this is already fed to the interpreter, with assert replaced.
I will not go into details, there is a link, on it you can read how they did it. But I love that it all works under the hood. the user does not see this. He writes assert, as he is used to, the library itself does the rest. You don't even have to think about it.
Further in pytest for standard types, you will have good error information anyway. Because pytest knows how to display this error information. But you can compare custom data types in your test, for example trees or something complex, and pytest may not know how to display error information for them. For such cases, you can add a special hook - here is a section in the documentation - and in this hook write how the error information should look. Everything is very flexible and convenient.

Let's see how fixtures look like in pytest. If in unittest it is necessary to write setUp and tearDown, then here call the usual function whatever you like. We wrote the pytest.fixture decorator on top - great, it's a fixture.
And here is not the simplest example. The fixture can just do a return, return something, it will be analogous to setUp. In this case, it will make a kind of tearDown, that is, exactly here, after the end of the test, it will call close, and the temporary file will be deleted.
It seems to be convenient. You have an arbitrary function that you can name whatever you want. You explicitly pass it to the test. Passed filled_file, you know what it is. Nothing special is required from you. In general, use it. This is much more convenient than unittest.

A little more about fixtures. In pytest it is very easy to create fixtures of different scopes. By default, the fixture is created with the function level. This means that it will be called for every test you passed it to. That is, if there is a yield or something else a la tearDown, this will also happen after each test.
You can declare scope = 'module' and then the fixture will be executed once per module. Let's say you want to create a database once and don't want to delete and roll all migrations after each test.
Also in fixtures it is possible to specify the autouse = True argument, and then the fixture will be called regardless of whether you asked for it or not. It seems that this option should never be used, or should be, but very carefully, because it is an implicit thing. The implicit is best avoided.

We ran this code - let's see what happened. There is a test one that depends on the fixture call me once use when needed, call me every time. At the same time, call me once use when needed is a module-level fixture. We see that the first time we called fixtures call me once use when needed, call me every time, which output this, but the fixture with autouse was also called, because it doesn't care, it is always called.
The second test depends on the same fixtures. We see that the second time we call me once use when needed was not printed, because it is at the module level, it has already been called once and it will not be called again.
In addition, from this example, you can see that pytest does not have such problems that we talked about in unittest, when in one test you may need a database, in another - a temporary file. How to aggregate them normally is not clear. Here is the answer to this question in pytest. If two fixtures were passed, then there will be two fixtures inside.
Excellent, very comfortable, no problem. Fixtures are very flexible and can depend on other fixtures. There is no contradiction in this, and pytest itself will call them in the correct order.

In fact, inside you can inherit fixtures from other fixtures, make them different in scope, and autouse without autouse. He himself will arrange them in the correct order and call them.
Here we have the first test, test one, which depends on rare_dependency_for_test_one, where this fixture depends on another fixture - and one more. Let's see what happens in the exhaust.
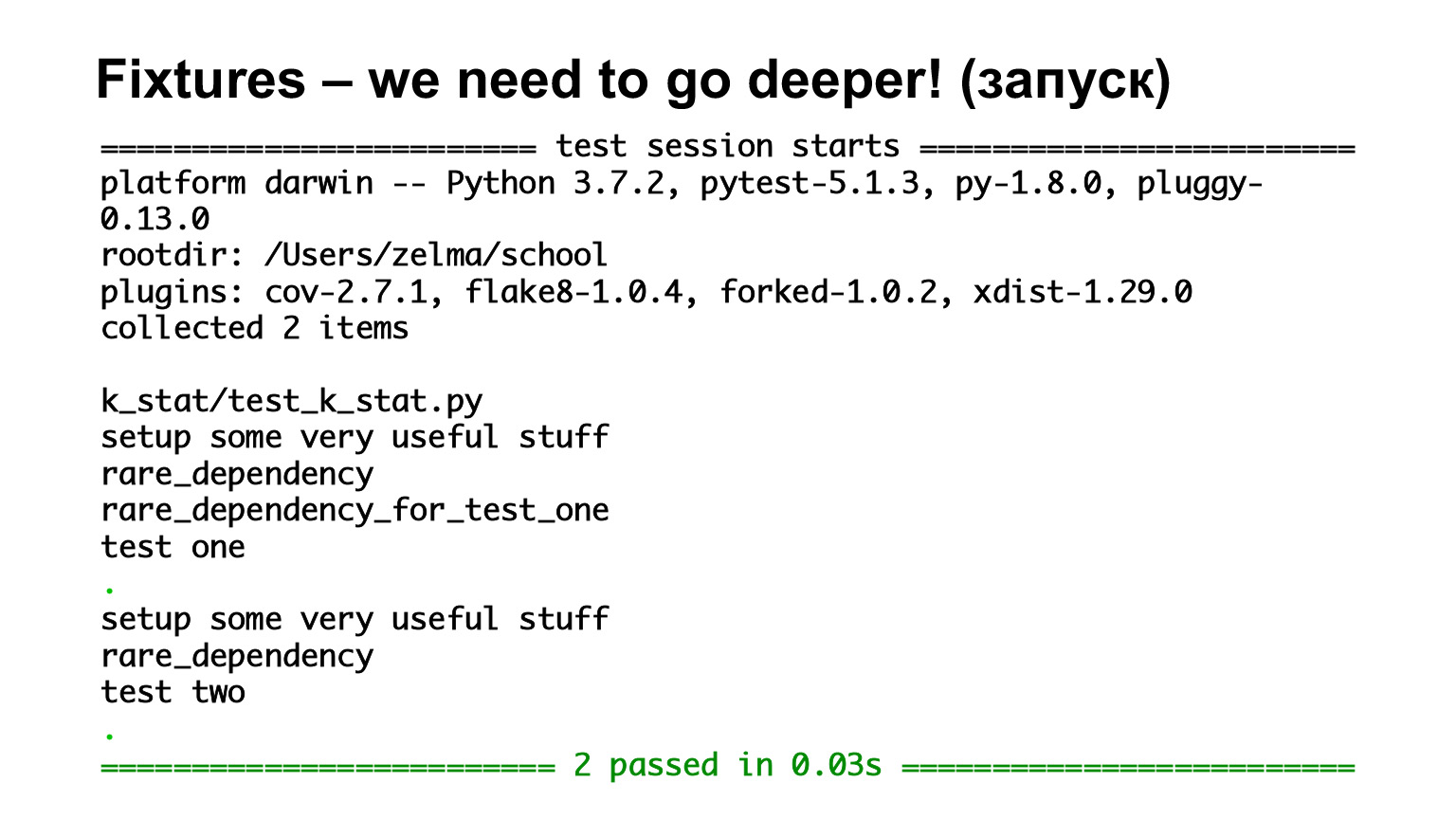
We have seen that they are called in order of inheritance. There are all function-level fixtures, so they are all called for each test. The second test depends on rare_dependency and rare_dependency depends on some_common_dependency. We look at the exhaust and see that two fixtures were called before the test.
Pytest has a special configuration file conftest.py where you can put all the fixtures, and it's good if you put it: usually, when a person looks at someone else's code, he usually goes to look at fixtures in conftest.
It's not obligatory. If there is a fixture that you only need in this file, and you know for sure that it is specific, narrowly applicable, and you will not need it in another file, then you can declare it in the file. Or create a lot of conftest and they will all work at different levels.

Let's talk about the features that are in pytest. As I said, it is very easy to parameterize tests. Here we see a test that has three sets of parameters: two input and one that is expected. We pass them to the function arguments and see if what we passed to the input matches what is expected.

Let's see how it looks. We see that there are three tests. That is, pytest thinks these are three tests. Two passed, one fell. What's good here? For the test that fell, we see the arguments, we see on which set of parameters it fell.
Again, when you have a small function and parametrize says three, you may see with your eyes what exactly fell. But when there are many sets of parameters, you will not see it with your eyes. Rather, you will see, but it will be very difficult for you. And it's very convenient that pytest displays everything in this way - you can immediately see in which case the test failed.

Parametrize is a good thing. And when you have written a test once, and then do many, many sets of parameters, this is a good practice. Do not make many code variants for similar tests, but write a test once, then make a large set of parameters, and it will work.
There are a lot more useful things in pytest. If you talk about them, the lecture is clearly not enough, so I will show, again, only a few. The first test uses pytest.raises () to show that you are expecting an exception. That is, in this case, if an AssertionError is raised, the test will pass. You should have an exception thrown.
The second handy thing is xfail. It is a decorator that allows the test to fail. Let's say you have a lot of tests, a lot of code. You refactored something, the test started to fail. At the same time, you understand that either it is not critical, or it will be very expensive to repair it. And you are like this: okay, I'll hang a decorator on it, it will turn green, I'll fix it later. Or suppose the test started to flood. It is clear that this is an agreement with one's own conscience, but sometimes it is necessary. Moreover, xfail in this form will be green regardless of whether the test has fallen or not. You can still pass it to the Strict = True parameter, then it will be a slightly different situation, pytest will wait for the test to fail. If the test passes, an error message will be returned, and vice versa.
Another useful thing is skipif. There's just a skip that won't run tests. And there is skipif. If you hover this decorator, the test will not run under certain conditions.
In this case, it is written that if I have a Mac platform, then do not start, because the test for some reason falls. It happens. But in general, there are platform-specific tests that will always fail on a specific platform. Then it's useful.

Let's get it started. We saw the letter X, we saw S. X we have refers to xfail, S - to skipif. That is, pytest shows which test we completely missed and which we ran, but we do not look at the result.

There are many different useful options in pytest itself. I, of course, will not be able to display them here, you can see it in the documentation. But I'll tell you about a few.
Here is a useful --collect-only option. It displays a list of found tests. There is an option -k - filtering by test name. This is one of my favorite options: if one test fails, especially if it is complex and you don’t know how to fix it yet, filter it and run it.
You want to save time and probably not fun running 15 other tests - you know they pass or fail, but you haven't gotten to them yet. Run the test that crashes, fix it and move on.
There is also a very nice option -s, it enables output from stdout and stderr in tests. By default, pytest will only output stdout and stderr for failed tests. But there are times, usually at the stage of debugging, when you want to output something in the test and do not know if the test will fail. It may not fall, but you want to see in the test itself what comes there and output. Then run with -s and you should see what you want.
-v is the standard verbose option, increase verbosity.
--lf, --last-failed is an option that allows you to restart only those tests that failed in the last run. --sw, --stepwise are also useful functions like -k. If you repair tests sequentially, then run with --stepwise, it goes through the green ones, and as soon as it sees the failed test, it stops. And when you run --sw again, it starts with this test that crashed. If it falls again, it will stop again; if it doesn’t fall, it will move on until the next fall.

Link from the slide
In pytest there is a main configuration file pytest.ini. In it, you can change the default behavior of pytest. I have given here the options that are very often found in the configuration file.
Testpaths are the paths pytest will search for tests. addopts is what is added to the command line at startup. Here I have added flake8 and coverage plugins to addopts. We will look at them a little later.

Link from the slide
There are a lot of different plugins in pytest. I wrote the ones that, again, are used everywhere. flake8 is a linter, coverage is code coverage by tests. Then there is a whole set of plugins that make it easier to work with certain frameworks: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. There is probably something else.
The xdist plugin is used if you want to run tests in parallel. The timeout plugin allows you to limit the test run time: this comes in handy. You hang a timeout decorator on the test, and if the test takes longer, it fails.

Let's get a look. I added coverage and flake8 to pytest.ini. Coverage gave me a report, I have a file with tests there, something from it didn't call, but that's okay :)
Here is the k_stat.py file, it contains as many as five statements. This is roughly the same as five lines of code. And the coverage is 100%, but that's because my file is very small.
In fact, coverage is usually not one hundred percent, and moreover, it should not be achieved by all means. Subjectively, it seems that 60-70% test coverage is quite enough and normal for work.
overage is such a metric that, even being one hundred percent, does not say that you are great. The fact that you have called this code does not mean that you have checked something. You can also write assert True at the end. You need to approach coverage reasonably, for 100% test coverage there are fading and robots, but people don't need to do that.
In pytest.ini I have connected one more plugin. Here you can see --flake8, this is a linter that shows my style errors, and some others, not from PEP8, but from pyflakes.

Here in the exhaust is written the error number in PEP8 or in pyflakes. In general, everything is clear. The line is too long, for redefinition you need two blank lines, you need a blank line at the end of the file. At the end it says that CitizenImport is not used for me. In general, linters allow you to catch gross errors and errors in code design.

We have already talked about the timeout plugin, it allows you to limit the test run time. For some perftests, run time is important. And you can limit it inside tests with time.time and timeit. Or using the timeout plugin, which is also very convenient. If the test works too much, it can be profiled in different ways, for example cProfile, but Yura will talk about this in his lecture .
If you use an IDE, and it's worth using auxiliary tools, I have here, in particular, PyCharm, then tests are very easy to run directly from it.

It remains to talk about mock. Let's say we have module A, we want to test it and there are other modules that we don't want to test. One of them goes to the network, the other to the database, and the third is a simple module that does not bother us in any way. In such cases, mock will help us. Again, if we are writing an integration test, we will most likely bring up a test database, write a test client, and that is fine too. It's just an integration test.
There are times when we want to do a unittest when we only want to test one piece. Then we need a mock.

Mock is a collection of objects that can be used to replace the real object. On any call to methods, to attributes, it also returns mock.

In this example, we have a simple module. We will leave it, and replace some more complex ones with mock. We will now see how it works.

It is shown here clearly. We imported it, we say that m is a mock. Called back mock. They said that m has a method f. Called back mock. They said that m is the is_alive attribute. Great, another mock is back. And we see that m and f are called once. That is, it is such a tricky object, inside which the getattr method is rewritten.

Let's take a look at a clearer example. Let's say there is an AliveChecker. He uses some kind of http_session, he needs a target, and he has a do_check function that returns True or false, depending on what he received: 200 or not 200. This is a slightly artificial example. But suppose that inside do_check you can wind up complex logic.
Let's say we don't want to test anything about the session, we don't want to know anything about the get method. We only want to test do_check. Great, let's test it.

You can do it like this. Mock http_session, here it is called pseudo_client. We mock her get method, we say that get is a mock that returns 200. We launch, create an AliveChecker from this, launch it. This test will work.
In addition, let's check that get was called once and with exactly the same arguments as written. That is, we called do_check without knowing anything about what session it was or what its methods were. We just froze them. The only thing we know is that it returned 200.

Another example. It is very similar to the previous one. The only thing here is side_effect instead of return_value. But that's something the mock does. In this case, it throws an exception. The assert line has been changed to assert not AliveChecker.do_check (). That is, we see that the check will not pass.
These are two examples of how to test the do_check function without knowing anything about what came into it from above, what came into this class.
The example, of course, looks artificial: it is not entirely clear why check, 200 or not 200, there is just a minimum of logic. But let's imagine doing something tricky depending on the return code. And then such a test starts to seem much more meaningful. We saw that 200 comes, and then we check the processing logic. If not 200 - the same.

You can also patch libraries with mock. Let's say you already have a library and need to change something in it. Here is an example, we have patched the sine. Now he always returns a deuce. Excellent.
We also see that m has been called twice. Mock, of course, does not know anything about the internal APIs of the methods that you mock and, in general, is not obliged to match them. But mock allows you to check what you called, how many times, and with what arguments. In this sense, it helps to test the code.

I want to warn you against a case where there is only one module and a huge mock. Please approach everything reasonably. If you have simple things, don't wet them. The more mock you have in your test, the more you drift away from reality: your API may not match, and in general, this is not exactly what you are testing. You don't need to soak everything without need. Approach the process intelligently.

We have the last little part about Continuous Integration left. When you are developing a pet project alone, you can run tests locally, and no big deal, they will work.
As soon as the project grows and there are more than one developers in it, it stops working. First, half will not run tests locally. Secondly, they will run them on their versions. There will be conflicts somewhere, everything will constantly break down.
For that, there is Continuous Integration, a development practice that involves quickly injecting candidates into the mainstream. But at the same time, they must go through some kind of auto assembly or autotests in a special system. You have the code in the repository, the commits that you want to merge into your main project branch. On these commits, tests are passed in a special system. If the tests are green, then either the commit is poured in itself, or you have the opportunity to pour it in.
Such a scheme, of course, has its drawbacks, as well as everything. At the very least, you need additional hardware - not the fact that CI will be free. But in any more or less large company, and not a large one either, you can't go anywhere without CI.
As an example - a screenshot from TeamCity, one of the CIs. There is an assembly, it was completed successfully. There were many changes in it, it was launched on such and such an agent at such and such a time. This is an example of when everything is good and can be infused.
There are many different CI systems. I wrote a list, if interested, have a look: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Thanks.
Other lectures of the video course on Python are in a post on Habré .