
When looking for parallel corpora for your needs, whether it be training a machine translation model or learning a foreign language, you may encounter the fact that there are not so many of them, especially if we are talking not about English, but some rare language. In this article we will try to create our own corpus for the popular Russian-German language pair based on Remarque's novel "Three Comrades". Dedicated to fans of parallel reading of books and developers of machine translation systems.
Task
This task is called text alignment and can be solved to some extent in the following ways:
- Use heuristics. You can count the number of sentences in the texts, the number of words in them and based on this, make a comparison. This method does not provide good quality, but it can also be useful.
- sentence embeddings. word2vec sent2vec — "" + "" — "" = "". , , (, ) . .
, , Universal Sentence Encoder, Sentence Transformers LaBSE (Language Agnostic BERT Sentence Embeddings).
, , , . . , — , , . .
, , , , , , , , — "I love cats" " ". , , 1. USE, - , xlm-r-100langs-bert-base LaBSE.
1. Multilingual sentence embedding models
| embedding' | |||
|---|---|---|---|
| sentence transformers/distiluse-base-multilingual-cased | 13 (, , , , , , , , , , , ) | 500Mb | 512 |
| Universal Sentence Encoder | 15 ( ) | 250Mb (300Mb large version) | 512 |
| sentence transfomers/xlm-r-100langs-bert-base | 100 *, | 1Gb | 768 |
| LaBSE | 109 , | 1.63Gb | 768 |
* sentence transformers , .
- , Colab', jupyter . .
. .
!pip3 install razdel
!pip3 install sentence-transformersimport re
import seaborn as sns
import numpy as np
from scipy import spatial
from matplotlib import pyplot as plt
import razdel
from sentence_transformers import SentenceTransformer, " " (1936 ) .
. (1959 ). . , . razdel' ( natasha), , ( — »«).
double_dash = re.compile(r'[--]+')
quotes_de = re.compile(r'[»«]+')
ru = re.sub('\n', ' ', text_ru)
ru = re.sub(double_dash, '—', ru)
de = re.sub('\n', ' ', text_de)
de = re.sub(quotes_de, ' ', de)
sent_ru = list(x.text for x in razdel.sentenize(ru))
sent_de = list(x.text for x in razdel.sentenize(de)):
[' , ; .',
' .',
'— .',
' — .',
' .',
' .',
' .',
' , — , .',
' .',
' .']:
['Der Himmel war gelb wie Messing und noch nicht verqualmt vom Rauch der Schornsteine.',
'Hinter den Dächern der Fabrik leuchtete er sehr stark.',
'Die Sonne mußte gleich aufgehen.',
'Ich sah nach der Uhr.',
'Es war noch vor acht.',
'Eine Viertelstunde zu früh.',
'Ich schloß das Tor auf und machte die Benzinpumpe fertig.',
'Um diese Zeit kamen immer schon ein paar Wagen vorbei, die tanken wollten.',
'Plötzlich hörte ich hinter mir ein heiseres Krächzen, das klang, als ob unter der Erde ein rostiges Gewinde hochgedreht würde.',
'Ich blieb stehen und lauschte.']570 561- . , .
, , . , .
def get_batch(iter1, iter2, batch_size):
l1 = len(iter1)
l2 = len(iter2)
k = int(round(batch_size * l2/l1))
kdx = 0 - k
for ndx in range(0, l1, batch_size):
kdx += k
yield iter1[ndx:min(ndx + n, l1)], iter2[kdx:min(kdx + k, l2)]sentence-transformers (distiluse-base-multilingual-cased), , (~500 Mb), .
model_st = SentenceTransformer('distiluse-base-multilingual-cased')vectors1, vectors2 = [], []
for lines_ru_batch, lines_de_batch in get_batch(sent_ru, sent_de, batch_size):
batch_number += 1
vectors1 = [*vectors1, *model_st.encode(lines_de_batch)]
vectors2 = [*vectors2, *model_st.encode(lines_ru_batch)]512.
[array([-0.03442561, 0.02094117, ... , 0.11265451])], dtype=float32)]. , , — - " ". .
def get_sim_matrix(vec1, vec2, window=10):
sim_matrix=np.zeros((len(vec1), len(vec2)))
k = len(vec1)/len(vec2)
for i in range(len(vec1)):
for j in range(len(vec2)):
if (j*k > i-window) & (j*k < i+window):
sim = 1 - spatial.distance.cosine(vec1[i], vec2[j])
sim_matrix[i,j] = sim
return sim_matrixsim_matrix = get_sim_matrix(vectors1, vectors2, window)50 . heatmap, seaborn.
plt.figure(figsize=(12,10))
sns.heatmap(sim_matrix, cmap="Greens", vmin=threshold)
plt.xlabel("russian", fontsize=18)
plt.ylabel("chinese", fontsize=18)
plt.show()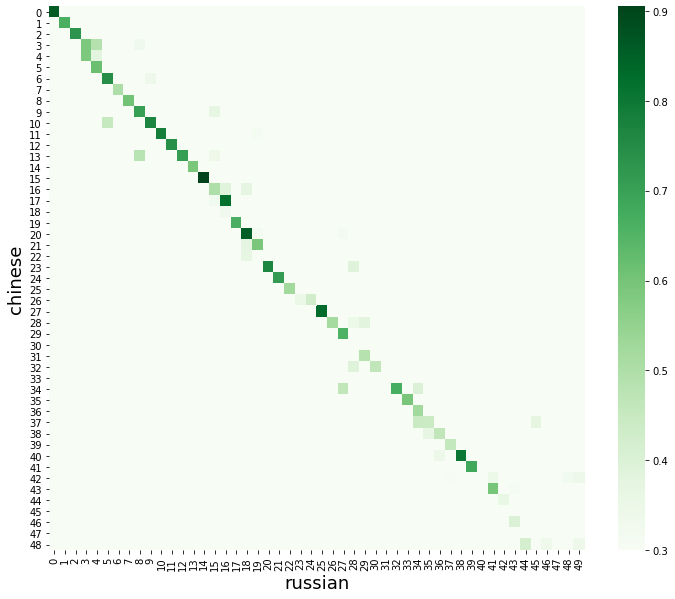
. .

.

, , :
- . , , , — , , common crawling' , .
- . , (, , , nich nicht).
- . , — . .
- . , , , , , . "" . , .
- . "". , - . , ( ) . ..
, , , . , — , , , , . , .
, ; .
Der Himmel war gelb wie Messing und noch nicht verqualmt vom Rauch der Schornsteine.
>> similarity 0.8614717125892639
.
Hinter den Dächern der Fabrik leuchtete er sehr stark.
>> similarity 0.6654264330863953
— .
Die Sonne mußte gleich aufgehen.
>> similarity 0.7304455041885376
— .
Ich sah nach der Uhr.
>> similarity 0.5894380807876587
— .
Es war noch vor acht.
>> similarity 0.5892142057418823
.
Eine Viertelstunde zu früh.
>> similarity 0.6182181239128113
.
Ich schloß das Tor auf und machte die Benzinpumpe fertig.
>> similarity 0.7467120289802551
.
Um diese Zeit kamen immer schon ein paar Wagen vorbei, die tanken wollten.
>> similarity 0.5018423199653625
, — , .
Plötzlich hörte ich hinter mir ein heiseres Krächzen, das klang, als ob unter der Erde ein rostiges Gewinde hochgedreht würde.
>> similarity 0.6064425110816956
.
Ich blieb stehen und lauschte.
>> similarity 0.7030230760574341
.
Dann ging ich über den Hof zurück zur Werkstatt und machte vorsichtig die Tür auf.
>> similarity 0.7700499296188354
, , .
In dem halbdunklen Raum taumelte ein Gespenst umher.
>> similarity 0.7868185639381409 , , . ? ? !
[1] Google Colab.
[2] Sentence Transformers.
[3] Universal Sentence Encoder.
[4] Language Agnostic BERT Sentence Encoder .