
There is such a joke in IT circles that machine learning (ML) is like sex among teenagers: everyone talks about it, everyone pretends to do it, but, in fact, very few people succeed. FunCorp has succeeded in introducing ML into the main mechanics of its product and achieving a radical (almost 40%!) Improvement in key metrics. Interesting? Welcome to cat.
A bit of background
For those who read the FunCorp blog irregularly, let me remind you that our most successful product is the iFunny UGC application with elements of a social network for meme lovers. Users (and this is every fourth representative of the young generation in the US) upload or create new pictures or videos directly in the application, and a smart algorithm selects (or, as we say, “features”, from the word “featured”) the best of them and forms each day 7 issues of 30-60 content units in a separate feed, with which 99% of the audience interacts. As a result, when entering the application, each user sees top memes, videos and funny pictures. If you visit often, then the feed quickly scrolls and the user waits for the next issue in a few hours. However, if you visit less often, featured content accumulates, and the feed can grow to 1000 items in a few days.
Accordingly, the task arose: to show each user the most relevant content for him, grouping memes that are interesting to him personally at the beginning of the feed.
For over 9 years of iFunny's existence, there have been several approaches to this task.
First, we tried the obvious way to sort the feed by the number of smiles (our analogue of "likes") - Smile rate . It was better than sorting in chronological order, but at the same time led to the effect of the "average temperature in the hospital": there is little humor that everyone likes, and there will always be those who are not interested (and even frankly annoying) popular topics today ... But you also want to see all the new funny jokes from your favorite cartoon.
In the next experiment, we tried to take into account the interests of individual microcommunities: fans of anime, sports, memes with cats and dogs, etc. To do this, they began to form several thematic featured-feeds and offer users to choose topics of interest to them, using tags and text recognized in pictures. Something has improved, but the effect of the social network has been lost: there are fewer comments on featured content, which played a big role in user engagement. Moreover, on the way to segmented feeds, we lost a lot of really top popular memes. They watched "Favorite Cartoon", but did not see the jokes about "The Last Avengers".
Since we have already begun to implement machine learning algorithms into our product, which we presented at our own meetup, they wanted to make another approach using this technology.
It was decided to try to build a recommendation system based on the principle of collaborative filtering. This principle is good in cases where the application has very little data about users: few indicate their age or gender when registering, and only by the IP address one can assume their geographical location (although it is known without fortune-tellers that the vast majority of iFunny users are residents United States), and by phone model - income level. On this, in general, everything. Collaborative filtering works like this: the history of positive ratings of the user's content is taken, other users with similar ratings are found, then he is recommended what the same users have already liked (with similar ratings).
Features of the task
Memes are pretty specific content. First, it is highly susceptible to rapidly changing trends. The content and the form that went to the top and made 80% of the audience smile a week ago, today can cause irritation with their secondary nature and irrelevance.
Second, a very non-linear and situational interpretation of the meaning of the meme. In the news selection, you can catch on well-known names, topics that are fairly consistently used by a particular user. In a selection of movies, you can catch on to the cast, genre and much more. Yes, you can catch on to all this in a selection of personal memes. But how disappointing it would be to miss a real masterpiece of humor, which uses images or vocabulary that does not fit into the semantic content at all!

Finally, a very large amount of dynamically generated content. At iFunny, users create tens of thousands of posts every day. All this content must be "raked" as quickly as possible, and in the case of a personalized recommendation system, not only to find "diamonds", but also to be able to predict the assessment of content by various representatives of society.
What do these features mean for machine learning model development? First of all, the model must be constantly trained on the most recent data. At the very start of immersion in the development of a recommendation system, it is still not entirely clear whether we are talking about tens of minutes or a couple of hours. But both means the need for constant retraining of the model, or even better - online training on a continuous stream of data. All these are not the easiest tasks from the point of view of finding a suitable model architecture and selecting its hyperparameters: such that would guarantee that in a couple of weeks the metrics will not start to degrade confidently.
A separate difficulty is the need to follow the a / b-testing protocol adopted by us. We never implement anything without first checking on some of the users, comparing the results with a control group.
After long calculations, it was decided to start an MVP with the following characteristics: we only use information about the interaction of users with the content, we train the model in real time, right on a server equipped with a large amount of memory, which allows storing the entire history of interaction of the test group of users for a fairly long period. It was decided to limit the training time to 15-20 minutes in order to maintain the effect of novelty, as well as to have time to use the latest data from users who massively come to the application during releases.
Model
First, we started to spin the most classic collaborative filtering with matrix decomposition and training on ALS (alternating least square) or SGD (stochastic gradient descent). But they quickly figured out: why not start right away with the simplest neural network? From a simple single-layer mesh, in which there is only one linear embedding layer, and there is no wrapping of hidden layers, so as not to bury yourself in weeks of selecting its hyperparameters. A little beyond MVP? Maybe. But to train such a mesh is hardly more difficult than a more classical architecture, if you have hardware equipped with a good GPU (you had to fork out for it).
Initially, it was clear that there are only two options for the development of events: either the development will give a significant result in product metrics, then it will be necessary to dig further into the parameters of users and content, into additional training on new content and new users, into deep neural networks, or personalized content ranking will not bring tangible increase and "shop" can be covered. If the first option happens, then all of the above will have to be screwed up to the starting Embedding layer.
We decided to opt for the Neural Factorization Machine . The principle of its operation is as follows: each user and each content are encoded by vectors of fixed equal length - embeddings, which are further trained on a set of known interactions between the user and the content.
The training set includes all the facts of users viewing the content. In addition to smiles, it was decided to consider clicks on the "share" or "save" buttons, as well as writing a comment, for positive feedback about content. If present, the interaction is marked with 1 (one). If, after viewing, the user did not leave positive feedback, the interaction is marked with 0 (zero). Thus, even in the absence of an explicit rating scale, an explicit model is used (a model with an explicit rating from the user), and not an implicit one, which would take into account only positive actions.
We also tried the implicit model, but it didn't work right away, so we focused on the explicit model. Perhaps, for the implicit model, you need to use more cunning than simple binary cross-entropy ranking loss functions.
The difference between Neural Matrix Factorization and standard Neural Collaborative Filtering is in the presence of the so-called Bi-Interaction Pooling layer instead of the usual fully connected layer, which would simply connect the user and content embedding vectors. Bi-Interaction layer converts a set of embedding vectors (there are only 2 vectors in iFunny: user and content) into one vector by multiplying them element by element.
In the absence of additional hidden layers on top of Bi-Interaction, we get the dot product of these vectors and, adding user bias and content bias, wrap it in a sigmoid. This is an estimate of the likelihood of positive feedback from the user after viewing this content. It is according to this assessment that we rank the available content before demonstrating it on a specific device.
Thus, the task of training is to make sure that the user and content embeddings for which there is a positive interaction are close to each other (have the maximum dot product), and the user and content embeddings for which there is a negative interaction are far from each other. (minimum dot product).
As a result of this training, embeddings of users who smile the same thing become close to each other by themselves. And this is a convenient mathematical description of users that can be used in many other tasks. But that is another story.
So, the user enters the feed and starts watching the content. Every time you view, smile, share, etc. the client sends statistics to our analytical storage (which, if interested, we wrote about earlier in the article Moving from Redshift to Clickhouse ). On the way, we select events of interest to us and send them to the ML-server, where they are stored in memory.
Every 15 minutes, the model is retrained on the server, after which new user statistics are taken into account in recommendations.
The client requests the next page of the feed, it is formed in a standard way, but on the way the content list is sent to the ML service, which sorts it according to the weights given by the trained model for this particular user.

As a result, the user sees first those pictures and videos that, according to the model, will be most preferable to him.
Internal service architecture
The service works over HTTP. Flask is used as an HTTP server in conjunction with Gunicorn. It handles two requests: add_event and get_rates.
add_event request adds new interaction between user and content. It is added to an internal queue and then processed in a separate process (peaking up to 1600 rps).
get_rates request calculates weights for user_id and content_id list according to the model (at the peak of about a hundred rps).
The main internal process is the Dispatcher. It is written in asyncio and implements the basic logic:
- processes the queue of add_event requests and stores them in a huge hashmap (200M events per week);
- recalculates the model in a circle;
- saves new events to disk every half an hour, while deleting events older than a week from the hashmap.

The trained model is placed in shared memory, from where it is read by HTTP workers.
results
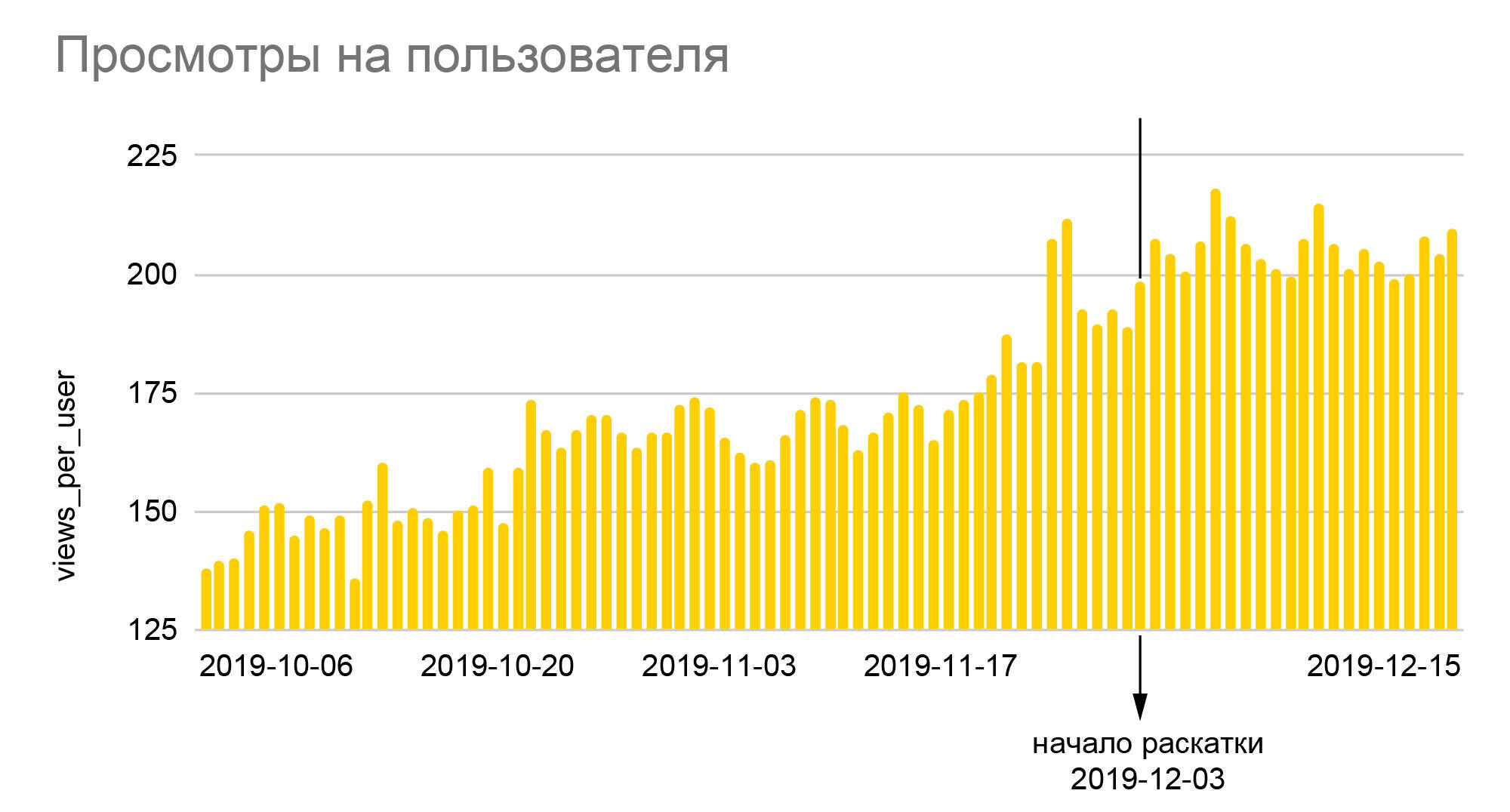

The charts speak for themselves. The 25% growth in the relative number of smilies and almost 40% in the depth of views that we see on them is the result of rolling out the new algorithm to the entire audience at the end of the A / B test 50/50, that is, a real increase relative to the base values was almost twice as large. Since iFunny makes money from advertising, the increase in depth means a proportional increase in revenue, which, in turn, allowed us to get through the crisis months of 2020 quite calmly. An increase in the number of smilies translates into greater loyalty, which means a lower probability of abandoning the application in the future; loyal users start to go to other sections of the application, leave comments, communicate with each other. And most importantly, we have not only created a reliable basis for improving the quality of recommendations,but also laid the foundation for creating new features based on the colossal amount of anonymous behavioral data that we have accumulated over the years of the application.
Conclusion
The ML Content Rate service is the result of a large number of minor improvements and improvements.
First, unregistered users were also taken into account in training. Initially, there were questions about them, since they a priori could not leave emoticons - the most frequent feedback after viewing content. But it soon became clear that these fears were in vain and closed a very large point of growth. A lot of experiments are done with the configuration of the training sample: to place a larger proportion of the audience in it or to expand the time interval of the interactions taken into account. In the course of these experiments, it turned out that not only the amount of data plays a significant role for product metrics, but also the time to update the model. Often, the increase in the quality of ranking drowned in the extra 10-20 minutes to recalculate the model, which made it necessary to abandon innovations.
Many, even the smallest, improvements have yielded results: they either improved the quality of learning, or accelerated the learning process, or saved memory. For example, there was a problem with the fact that interactions did not fit into memory - they had to be optimized. In addition, the code was modified and it became possible to shove into it, for example, more interactions for recalculation. It also led to improved service stability.
Now work is underway to effectively use the known user and content parameters, to make an incremental, quickly retraining model, and new hypotheses for future improvements are emerging.
If you are interested in learning about how we developed this service and what other improvements we managed to implement - write in the comments, after a while we will be ready to write the second part.
About the authors
Unfortunately, Habr does not allow to indicate several authors for the article. Although the article was published from my account, most of it was written by the lead developer of FunCorp ML services - Grisha Kuzovnikov (PhoenixMSTU), as well as an analyst and data scientist - Dima Zemtsov. Your recalcitrant servant is mainly responsible for the teen sex jokes, the introduction and the results section, plus the editorial work. And, of course, all these achievements would not have been possible without the help of the backend development teams, QA, analysts and the product team, who invented all this and spent several months conducting and adjusting A / B experiments.