Research path
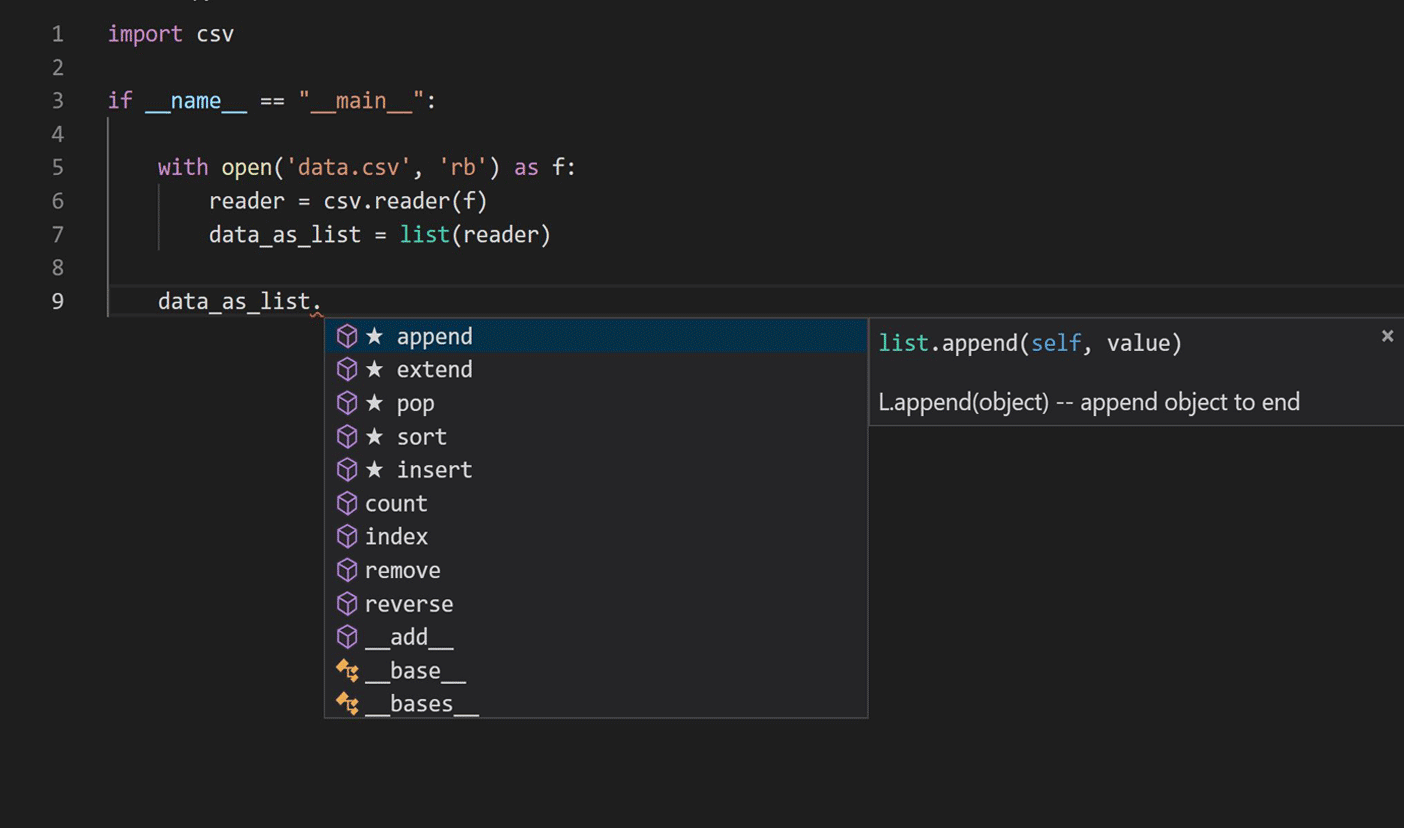
The journey began by researching the application of language modeling techniques in natural language processing to learn Python code. We focused on the current IntelliCode completion script, as shown in the image below.

The main task is to find the most probable fragment (member) of the type, taking into account the fragment of code preceding the call of the fragment (member). In other words, given the original C code snippet, the vocabulary V, and the set of all possible methods M ⊂ V, we would like to define:
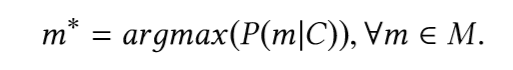
To find this fragment, we need to build a model that can predict the probability of available fragments.
Previous modern approaches based on recurrent neural networks ( RNN ) used only the sequential nature of the source code, trying to convey natural language techniques without taking advantage of the unique characteristics of the programming language syntax and code semantics. The nature of the code completion problem has made it a promising candidate for long-term short-term memory ( LSTM). When preparing the data for training the model, we used a partial abstract syntax tree (AST) corresponding to code snippets containing member access expressions (member) and module function calls to capture the semantics carried by the remote code.
Training deep neural networks is a resource-intensive task that requires high performance computing clusters. We used Horovod's distributed parallel training framework with the Adam optimizer , keeping a copy of the entire neural model on each worker, processing different mini-batches of the training dataset in parallel. We used Azure Machine Learningfor model training and hyperparameter tuning, as its GPU on-demand cluster service made it easy to scale our training as needed, and also helped provision and manage VM clusters, schedule jobs, collect results, and handle failures. The table shows the architecture models that we tested, as well as their respective accuracy and model size.

We chose Predictive Implementation manufacturing because of the smaller model size and a 20% improvement in model accuracy over the previous production model during offline model evaluation; model size is critical for production deployments.
The architecture of the model is shown in the figure below:

To deploy the LSTM in production, we had to improve the model inference speed and memory footprint to meet the code completion requirements during edit. Our memory budget was around 50MB and we needed to keep the average output speed under 50 milliseconds. The IntelliCode LSTM was trained with TensorFlow and we chose ONNX Runtime for inference to get the best performance. ONNX Runtime works with popular deep learning frameworks and makes it easy to integrate into a variety of serving environments by providing APIs that span multiple languages including Python, C, C ++, C #, Java, and JavaScript - we used C # APIs that are compatible with .NET Core to integrate into Microsoft Python Language Server .
Quantization is an effective approach to reduce model size and improve performance when the drop in precision caused by approximating low-digit numbers is acceptable. With the post-training INT8 quantization provided by ONNX Runtime, the resulting improvement was significant: the memory footprint and inference time were reduced to about a quarter of the prequantized values compared to the original model, with an acceptable 3% reduction in model accuracy. You can find detailed information on model architecture design, hyperparameter tuning, accuracy, and performance in a research paper that we published at the KDD 2019 conference.
The final stage of release to production was conducting online A / B experiments comparing the new LSTM model to the previous working model. The online A / B experiment results in the table below showed an approximately 25% improvement in the accuracy of the first level recommendations (accuracy of the first recommended completion item in the completion list) and a 17% improvement in the mean inverse rank (MRR), which convinced us that the new LSTM model is significantly better. the previous model.

Python Developers: Try the IntelliCode add-ons and send us your feedback!
Thanks to a lot of team effort, we've completed the phased rollout of the first deep learning model to all IntelliCode Python users in Visual Studio Code . In the latest version of the IntelliCode extension for Visual Studio Code, we also integrated the ONNX runtime and LSTM to work with the new Pylance extension , which is written entirely in TypeScript. If you are a Python developer, install the IntelliCode extension and share your opinion with us.