The principles of our system
When you hear terms like "automatic" and "fraud," you are most likely thinking of machine learning, Apache Spark, Hadoop, Python, Airflow, and other technologies from the Apache Foundation ecosystem and data science. I think there is one aspect of using these tools that is usually not mentioned: they require certain prerequisites in your corporate system before you can start using them. In short, you need an enterprise data platform that includes a data lake and storage. But what if you don't have such a platform and still need to develop this practice? The following principles, which I discuss below, have helped us reach the point where we can focus on improving our ideas, rather than finding one that works. However, this is not a "plateau" of the project.There are still many things in the plan from a technological and product point of view.
Principle 1: Business Value Comes First
We have placed business value at the center of all our efforts. In general, any automatic analysis system belongs to the group of complex systems with a high level of automation and technical complexity. It will take a long time to create a complete solution if you create it from scratch. We decided to prioritize business value and technological completeness second. In real life, this means that we do not accept advanced technology as a dogma. We choose the technology that works best for us at the moment. Over time, it may seem that we will have to reimplement some modules. This compromise that we have accepted.
Principle 2: augmented intelligence
I bet most people who are not deeply involved in developing machine learning solutions might think that replacing people is the goal. In fact, machine learning solutions are far from perfect and can only be replaced in certain areas. We ditched this idea from the beginning for several reasons: imbalanced data on fraudulent activity and the inability to provide an exhaustive list of features for machine learning models. In contrast, we chose the enhanced intelligence option. It is an alternative concept of artificial intelligence that focuses on the supporting role of AI, highlighting the fact that cognitive technologies are designed to improve human intelligence, not replace it. [1]
With this in mind, developing a complete machine learning solution from the start would have required a tremendous amount of effort that would delay the creation of value for our business. We decided to build a system with an iteratively growing aspect of machine learning under the guidance of our domain experts. The tricky part of developing such a system is that it must provide our analysts with cases not only in terms of whether it is a fraudulent activity or not. In general, any anomaly in customer behavior is a suspicious case that specialists need to investigate and respond somehow. Only a fraction of these recorded cases can really be classified as fraud.
Principle 3: rich intelligence platform
The hardest part of our system is the end-to-end check of the system workflow. Analysts and developers should be able to easily retrieve historical datasets with all the metrics used for their analysis. In addition, the data platform should provide an easy way to add new metrics to an existing set of metrics. The processes that we create, and these are not only software processes, should make it easy to recalculate previous periods, add new metrics and change the data forecast. We could achieve this by accumulating all the data that our production system generates. In this case, the data would gradually become a hindrance. We would need to store and protect the growing amount of data we don't use. In such a scenario, over time, the data will become more and more irrelevant,but still require our efforts to manage them. For us, data hoarding didn't make sense, and we decided to take a different approach. We decided to organize real-time data stores around the target entities that we want to classify, and only store data that allows us to check the most recent and current periods. The challenge with this effort is that our system is heterogeneous with multiple data stores and software modules that require careful planning to work consistently.which allow you to check the most recent and current periods. The challenge with this effort is that our system is heterogeneous with multiple data stores and software modules that require careful planning to work consistently.which allow you to check the most recent and current periods. The challenge with this effort is that our system is heterogeneous with multiple data stores and software modules that require careful planning to work consistently.
Constructive concepts of our system
We have four main components in our system: ingestion system, computational, BI analysis and tracking system. They serve specific isolated purposes, and we keep them isolated by following specific design approaches.
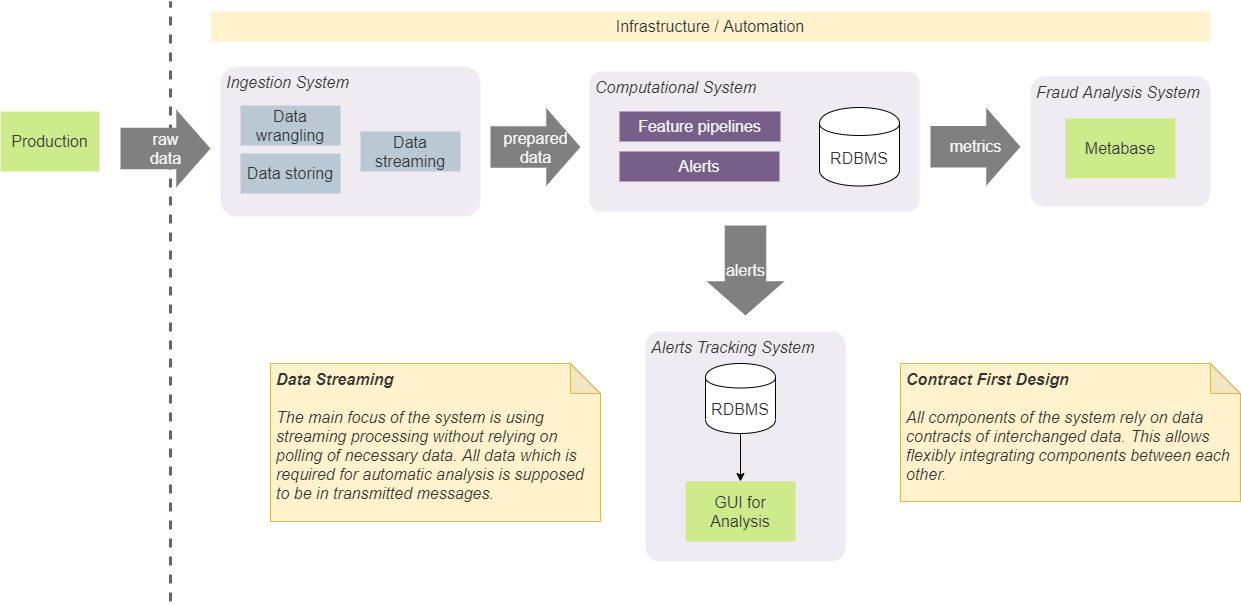
Contract based design
First of all, we agreed that components should only rely on certain data structures (contracts) that are passed between them. This makes it easy to integrate between them and not to impose a specific composition (and order) of components. For example, in some cases, this allows us to directly integrate the receiving system with the alert tracking system. If so, this will be done in accordance with the agreed notification contract. This means that both components will be integrated using a contract that any other component can use. We will not add an additional contract to add alerts to the tracking system from the input system. This approach requires the use of a predetermined minimum number of contracts and simplifies the system and communication. In fact,we use an approach called "Contract First Design" and apply it to streaming contracts. [2]
Maintaining and managing state in the system will inevitably lead to complications in its implementation. In general, state should be accessible from any component, it should be consistent and provide the most relevant value for all components, and it should be reliable with the correct values. In addition, having calls to persistent storage to get the latest state will increase the amount of I / O and the complexity of the algorithms used in our real-time pipelines. Because of this, we decided to remove state storage as completely as possible from our system. This approach requires the inclusion of all necessary data in the transmitted data block (message). For example, if we need to calculate the total number of some observations (the number of operations or cases with certain characteristics),we compute it in memory and generate a stream of such values. Dependent modules will use partition and batch to split the stream into entities and operate on the latest values. This approach eliminated the need to have persistent disk storage for such data. Our system uses Kafka as a message broker and it can be used as a database with KSQL. [3] But using it would strongly tie our solution to Kafka, and we decided not to use it. The approach we have taken allows us to replace Kafka with another message broker without major internal system changes.This approach eliminated the need to have persistent disk storage for such data. Our system uses Kafka as a message broker and it can be used as a database with KSQL. [3] But using it would strongly tie our solution to Kafka, and we decided not to use it. The approach we have taken allows us to replace Kafka with another message broker without major internal system changes.This approach eliminated the need to have persistent disk storage for such data. Our system uses Kafka as a message broker and it can be used as a database with KSQL. [3] But using it would strongly tie our solution to Kafka, and we decided not to use it. The approach we have taken allows us to replace Kafka with another message broker without major internal system changes.
This concept does not mean that we do not use disk storage and databases. To check and analyze the performance of the system, we need to store on disk a significant part of the data that represents various indicators and states. The important point here is that real-time algorithms are independent of such data. In most cases, we use the stored data for offline analysis, debugging and tracking of specific cases and results that the system produces.
The problems of our system
There are certain problems that we have solved to a certain level, but they require more thoughtful solutions. For now, I would just like to mention them here, because each point is worth a separate article.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Last but not least. We need to create an extensive performance validation platform on which we can analyze our models. [4]