My team and I represent the direction of business development with partners of Rosbank. Today we would like to talk about the successful experience of automating a banking business process using direct integrations between systems, artificial intelligence in terms of image and text recognition based on GreenOCR, RF legislation, and preparing samples for training.

So, let's begin. Rosbank has a business process for opening an account for a borrower represented by a partner bank. The existing process, following all the regulatory requirements and the requirements of the Societe Generale Group, before automation took up to 20 minutes of operational time per client. The process includes receiving scans of documents by the back office, checking the correctness of filling out each document and posting the document fields across the bank's information systems, a number of other checks, and only at the very end - opening an account. This is exactly the process behind the "Open an Account" button.
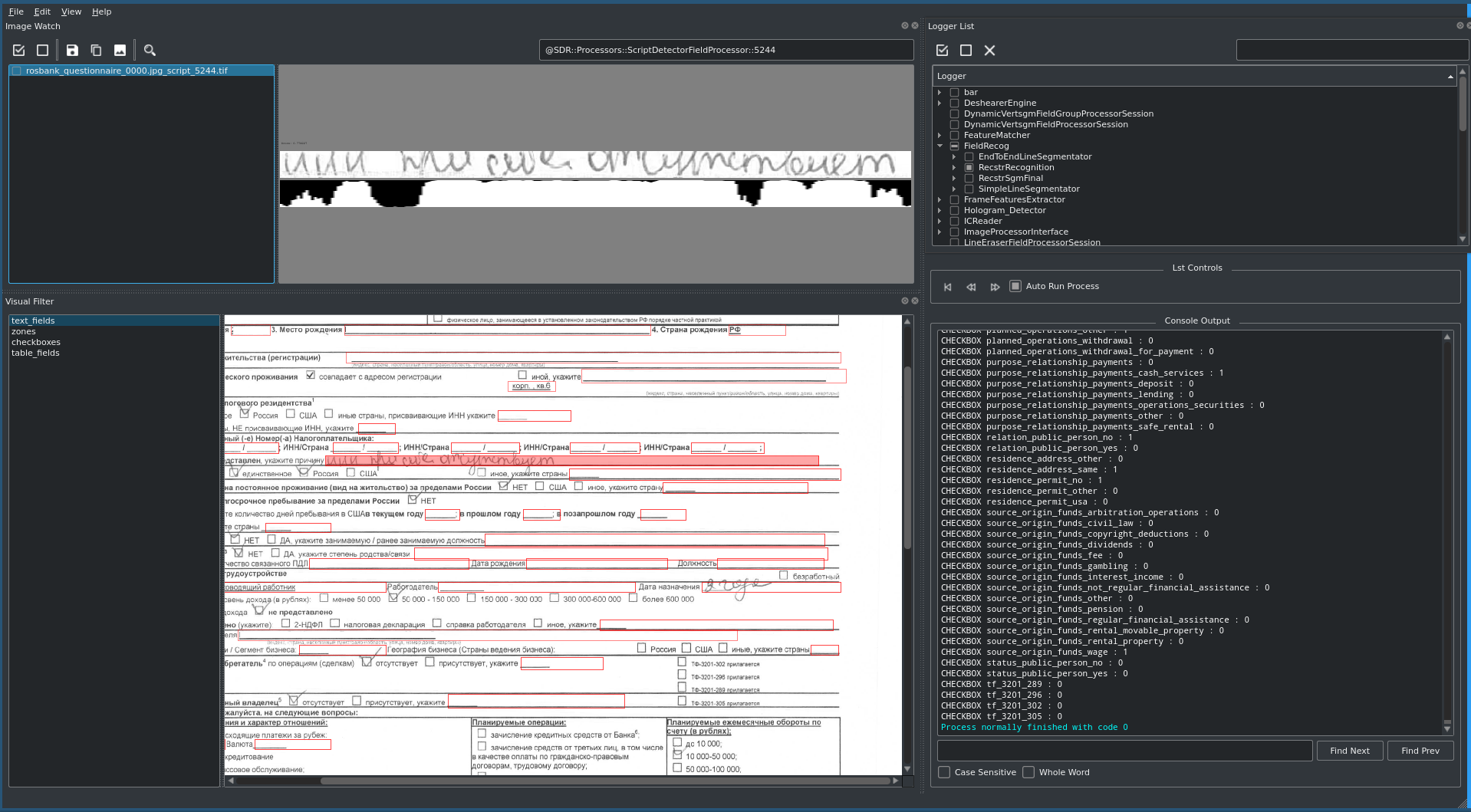
The main fields of the document - last name, first name, patronymic, date of birth of the client, etc. - are contained in practically all types of documents received and are duplicated when entered into different systems of the Bank. The most complex document - the KYC questionnaire (from Know Your Customer - know your customer) - is a printable A4 format filled with 8-point font and contains about 170 text fields and check-boxes, as well as tabular views.
What were we to do?
Our main goal was to reduce the time for opening an account to a minimum.
The analysis of the process showed that it is necessary:
- Reduce the number of manual verifications of each document;
- Automate the filling of the same fields in different bank systems;
- Reduce the movement of scans of documents between systems;
To solve problems (1) and (2), it was decided to use the GreenOCR-based image and text recognition solution already implemented in the bank (the working name is "recognizer"). The formats of documents used in the business process are not standard, so the team was faced with the task of developing requirements for the "recognizer" and preparing examples for training the neural network (samples).
To solve problems (2) and (3), it was necessary to refine the systems and intersystem integration.
Our team led by Julia Aleksashina
- Alexander Bashkov - internal systems development (.Net)
- Valentina Sayfullina - business analysis, testing
- Grigory Proskurin - integration between systems (.Net)
- Ekaterina Panteleeva - business analysis, testing
- Sergey Frolov - Project Management, model quality analysis
- Participants from an external vendor ( Smart Engines in conjunction with Philosophy.it )
Recognizer training
The set of client documents used in the business process included:
- Passport;
- Consent - printed form A4, 1 liter;
- Power of attorney - printed form A4, 2 l;
- KYC questionnaire - printed form A4, 1 liter;
To begin with, the documents were thoroughly studied and requirements were developed, which included not only the work of the recognizer with dynamic fields, but also work with static text, fields with handwritten data, in general, document recognition along the perimeter and other improvements.
Passport recognition was included in the box functionality of the GreenOCR system and did not require modifications.
For the rest of the types of documents, as a result of the analysis, the necessary attributes and signs were determined that the "recognizer" should return. At the same time, the following points had to be taken into account, which complicated the recognition process and required a noticeable complication of the algorithms used:
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
Initially, the task seemed to us not too difficult and looked pretty standard:
Requirements -> Vendor -> Model -> Testing the model -> Starting the process
In case of unsuccessful tests, the model is returned to the vendor for repeated training.
Every day we receive a huge number of scans of documents, and preparing a sample for training the model should not have been a problem. All processing of personal data must comply with the requirements of the Federal Law "On Personal Data" N152-FZ. Customers' consent to the processing of customer personal data is available only within Rosbank. We cannot transfer the client's documents to the vendor for training the model.
Three ways of solving the problem were considered:
- , , , , ;
- . , – () , ;
- () . , , , , , ;
Having analyzed the proposed options with the team, regarding the speed of their implementation and possible risks, we chose the third option - the path of imitating documents for training the model. The main advantage of this process is the ability to cover the widest possible range of scanning devices to reduce the number of iterations for calibration and model refinement.
Document templates were implemented in html format. An array of test data and a macro was quickly and efficiently prepared, filling templates with synthesized data and automating printing. Next, we generated printable forms in pdf-format and assigned a unique identifier to each file to verify the responses received from the "decoder".
The training of the neural network, the marking of areas and the customization of the forms took place on the vendor's side.
Due to the limited time frame, the training of the model was divided into 2 stages.
At the first stage, the model was trained to recognize types of documents and "rough" recognition of the contents of the documents themselves:
Requirements -> Vendor -> Preparing test data -> Data collection -> Training the model in form recognition -> Testing forms -> Setting up the model
At the second stage there was a detailed training of the model to recognize the content of each type of documents. Training and implementation of the model at the second stage can be described by the following scheme, which is the same for all types of documents:
Preparing test data in different resolutions -> Collecting and transmitting data to the vendor -> Training the model -> Testing the model -> Calibrating the model -> Implementing the model -> Checking the results in battle -> Identifying problem cases -> Simulating problem cases and transferring to the vendor -> Repeating steps from testing
It should be noted that, despite the very wide coverage of the range of scanners used, a number of devices were still not presented in the examples for training the model. Therefore, the introduction of the model into battle took place in pilot mode, and the results were not used for automation. The data obtained during the work in the pilot mode was only recorded in the database for further analysis and analysis.
Testing
Since the model training loop was on the vendor's side and was not connected with the bank's systems, after each training cycle the model was transferred by the vendor to the bank, where it was tested on a test environment. In case of successful verification, the model was transferred to the certification environment, where it was regression tested, and then to the industrial environment, in order to identify special cases that were not taken into account when training the model.
At the perimeter of the bank, data was submitted to the model, the results were recorded in the database. Data quality analysis was carried out using the almighty Excel - using pivot tables, logic with formulas and their combinations vlookup, hlookup, index, len, match and character-by-character string comparison through the if function.
Testing using simulated documents allowed us to run the maximum number of test scenarios and automate the process as much as possible.
First, in manual mode, we checked the return of all fields for compliance with the original requirements for each type of document. Next, we checked the model's responses when dynamically filling text blocks of different lengths. The goal was to test the quality of the responses when the text moves from line to line and from page to page. At the end, we checked the quality of the answers in the fields depending on the quality of the scanned document. For the highest quality calibration of the model, low resolution scans of documents were used.
Particular attention should have been paid to the most complex document containing the largest number of fields and checkboxes - the KYC questionnaire. For him, special scripts for filling out the document were prepared in advance and automated macros were written, which made it possible to speed up the testing process, check all possible data combinations and promptly give feedback to the vendor to calibrate the model.
Integration and internal development
The necessary revision of the bank's systems and intersystem integration were performed in advance and displayed on the test environments of the bank.
The realized scenario consists of the following stages:
- Acceptance of incoming scans of documents;
- Sending received scans to the "recognizer". Sending is possible in synchronous and asynchronous mode with up to 10 threads;
- Receiving a response from the "recognizer", checking and validating the received data;
- Saving the original scan of the document in the electronic library of the bank;
- Initiation in the bank's systems of processing the data received from the "recognizer" and subsequent verification by the employee;
Outcome
At the moment, the training of the model has been completed, successful testing and implementation of the business process in the production environment of the bank has been carried out. The performed automation allowed to reduce the average time for opening an account from 20 minutes to 5 minutes. The laborious stage of the business process for the recognition and input of document data, which was previously performed manually, has been automated. At the same time, the probability of errors caused by the human factor is sharply reduced. In addition, the identity of the data taken from the same document in different systems of the bank is guaranteed.