I work in the department of computing systems of CROC, we support everything that can be thrown into the wall. That is, servers, data storage systems and other expensive hardware in data centers. Well, the fact that it has operating systems, basic infrastructure. The simplest basic service is spare parts, that is, replacement of components on time. More complex ones are to replace the customer's system administrators.
The scariest moment of the contract is the drafting of the terms of reference. I will tell you about the rake that we felt together with the clients and how to avoid them. Well, I will attach an example of the TK template that we use.
Raise statistics
The very first jamb of all technical specifications is a banal ignorance of your average monthly number of applications. It looks like this: you want to outsource the administration, then you need to understand how much it will cost. If you just attach a description of the equipment park, then we, as a participant in the competition, will estimate the plug for the amount of work, visits, if required, and deliver with some margin. But if you know exactly how many and what tickets there were last year, then the price may drop dramatically - after all, you can see in fact what and how breaks down and how often changes are made to the infrastructure. Someone, for example, adds virtual machines every day, and someone once a year - the price will be the same in the first approximation.
Often the customer's task looks like “Now administer everything for us now”. And what's that? The service provider (that is, to us) does not understand the volume, everything is re-mortgaged for labor costs. If we redeem, you will overpay. If suddenly the price tag rises in the course of the contract, there will be conflicts. If suddenly something happens, and we take a contract cheaper than it actually costs, then we will try to refuse, and in the end we will have to look for a contractor again.
Sometimes it happens that the customer does not know his infrastructure at all (for example, after a merger-takeover or the sudden departure of the past admin). And simply if it is a branch, and they did not look there for a long time. In this case, you need to do the audit at the very beginning. The audit, of course, costs money in itself, but it saves a lot of money on the subsequent contract. And the audit results can be shown in a competition if you want to compare suppliers at a price per service unit. After all, we think how: there is a price of work (repair, departure), there is an understanding of how many and what devices. Then we look: there will be so many failures per month for such and such a unit, we will spend so much time on it. Well, or take a backup system. Here it is enough for someone to configure once and only check that all backups go through. And someone endlessly changes policies, adds, removes,adds again. We have been administering since the 90s and have been collecting statistics throughout, so we predict quite accurately. And when "there are so many servers of incomprehensible stuffing, some virtual machines, incomprehensible OS and something else there, you need to administer, the guy quit" - inhumane price tags are guaranteed. Moreover, they often come to us with old equipment, for which there has been no manufacturer support for a long time.
The next step is to split the contract into regular jobs and rare ones. The point is this: if it is some kind of permanent work with a fixed duration, we select it in a separate block and prescribe regularity. For rare tasks, we form a list of solution systems for which competencies are needed (even if they are needed once a year). The contractor will prepare specialists. And it will not include it in the main price list. He will simply register the rates for such works.
My favorite example is when a customer decided that administration includes a complete migration of the services on which the site was running to another data center at a distance of 1000 km along with the servers. Like, take the servers and everything taken together with them (network, storage, data on them ...) and take it, we pay for their administration. But this is rather out of the ordinary. Usually we single out such things in separate projects and work out migration in detail.
Reaction time
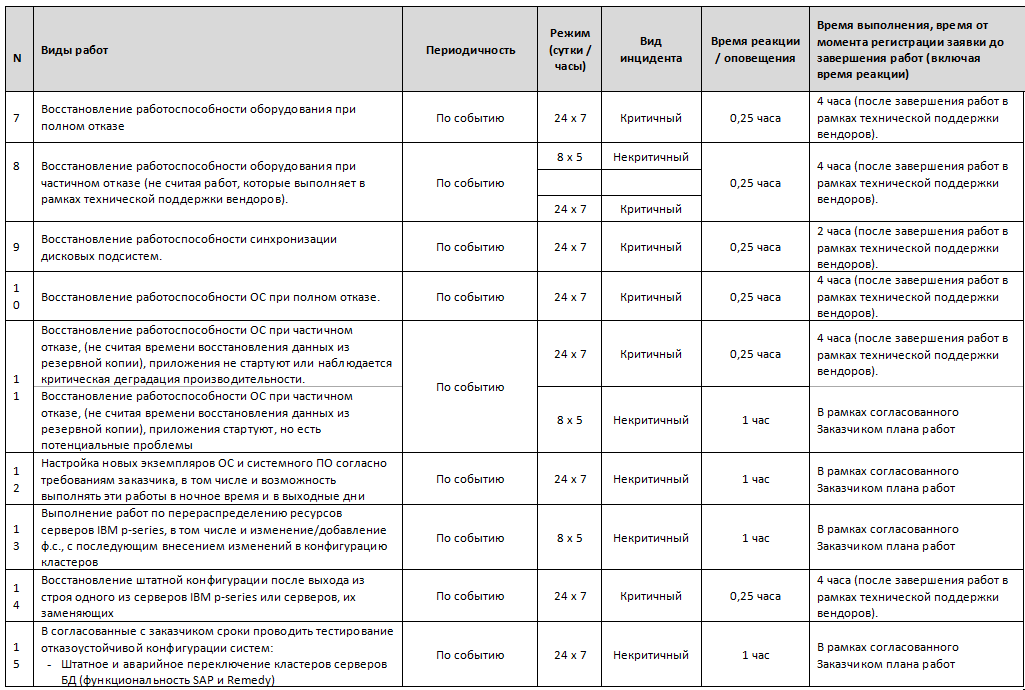
I regularly see customers who prescribe reaction times incorrectly or do not prescribe at all. It is better to fix everything here so that expectations coincide with reality. It is super important to write strict SLA for critical equipment: we usually have a response time of 15 minutes, replacement - four hours. But if you do this for all the hardware in the data center, the price tag will again turn out to be inhumane. There are also more complex contracts. We have production facilities where the average price tag is higher than usual, but at the same time we subscribe to the fact that we pay several million rubles per hour of downtime. Because the production cycle is tied to these nodes. Our duty officer did not notice that the memory was full on the server or was delayed on the road with a spare part - it is possible, at the end of the year, to remain indebted to the customer.
Usually production, when it wants one-time work (as failures), tries to prescribe an SLA for 15 minutes, not understanding what is behind it. To send an engineer with such a clearance, you need him to be on duty all year, and not drink on New Year's (or drink strictly according to chess with colleagues). And it costs money - and not at all as a one-time service.
There was a contract when it was necessary to keep 99% of the uptime, and they paid for it with penalties for going out of the indicator. We looked at the infrastructure, decided that, in principle, it would not be sufficient, and everything needed to be redone. The contract was not included, but we know those who decided that they would ride. It didn't work.
Reporting
The third favorite rake is that the customer does not set the reporting format. Design the reporting format you want to see. And indicate its frequency in the contract. If all tasks are performed at your rates, then it is better that the contractor informs about the preliminary estimate of the duration of the work before starting work.
This is to the question "Why do you have here two hours, and not one and a half?" Is an eternal dispute. We solve it as follows: before repairing, we give the customer an estimate with an error of plus or minus 10% to the sides. We put large tasks into projects with a work plan and stage deadlines.
It is clear that control is needed on both sides, which is a waste of time: we let the customer into our systems and fanatically cut the reports so that there are no surprises. Because we are interested in renewals for a year, two, three and five. And we know that if there is no feeling of complete control and predictability, there will be no contract renewal either.
It is also helpful to schedule regular meetings. The first month every week to build the process, then less often so that the supplier shares with you the recommendations of what he sees. Then once a month, at least once a quarter. We have a customer who leaves his outsourcer in a month, and he doesn't even know. Because there is no dialogue. They don't listen to the customer and do everything like five years ago. That is, without taking into account his new business requirements. The customer was trying to convey it, but then he spat, started looking for a new contractor.
Documentation
Rake number four is the virtual absence of documentation on site. Yes, I know nobody likes to make changes to infrastructure documentation. If you don't write it down in the contract, then you did something there, remade something here, but forgot to say - a common situation. The alternative is to take someone who will keep it up-to-date for you (changed something, reflected). It will be easy to change performers or transfer the accompaniment back to internal specialists.
We have come hundreds of times where from the documents - only DRP of about 2011. And you can't use it. In my memory, there are at least two cases when such customers got up in production. They helped to figure out what was the matter, it turned out that DRP did not work, because the IP had changed.
Don't forget to pick up the unloading at the end of the period
Advanced outsourcers maintain CMDB: installed new equipment, added it to the base. Everything is kept up to date. If there is no CMDB base of its own, then service organizations always have one. Well, if it's not about yours, ask for access to it. And be sure to add a clause to the contract - so that the accumulated data will then be transferred to you at the time of termination of the contract. We have a customer who was glad that he was being followed where what guarantee, where what license. But when the contract ended, I had to urgently inventory everything myself. This was our first service along with an audit - the previous counterparty didn’t want to share the data.
Don't be afraid to include high fines in your contract
A normal performer treats them well. Willingness to subscribe to them is an indicator that the supplier is confident in adhering to the SLA. The only point - if you transfer directly control over the decrease in productivity and fix the percentage of availability, make, for example, a month for a transition period when penalties do not apply. It takes a month to delve into the IT infrastructure, update the documentation, get all access and then guarantee the availability. If someone subscribes without it, your infrastructure is under threat for the first month.
By the way, you also need to measure what you think is the normal level of performance right on the living infrastructure. Then there will be something to compare with and show the performer that productivity has decreased. Otherwise you will not prove it.
Immediately involve an information security specialist in the development process
This is so important that it often defines the project in general. Let's once again: immediately involve an information security specialist in the development process. If you suddenly haven't done this, expect trouble. Most often, they are administered remotely, so the supplier needs to understand what the requirements will be. For example, there are clients for whom video surveillance of the dedicated workstation from which the connection is made is critical. The banks are even more serious - they have direct GOSTs and the requirements of the Central Bank. The best way to draw up a technical specification, which will dramatically increase the price tag, is to directly refer to the internal regulations in it and not provide it.
We had a case when they could not sign the contract for three months, the CIO hung up. The security officer wanted the implementation of GOST, we wanted him to show how it is now implemented (suspecting that it was not possible), and offered to send a variant. He did not send. As a result, they wrote that “if within three days you do not receive comments on the proposed text of the technical task, then we consider it agreed,” and put the head of the company in the copy. IB sent one phrase: "Installation of updates and patches that eliminate critical IS vulnerabilities must be done no later than 48 hours." And that's all. It can be said that it has passed.
In general, the topic of information security is greasy and slippery. Safe people live in their own world. Everything is cool and cool, the infrastructure specialists agreed among themselves, the contractors are implementing it. And then you come to the company, and you: go to the first department to negotiate. And there they sit on a stool and ask questions, because no one has informed them that something is happening.
Oh yes, and do not forget to note that admins must have access to the object. And it is difficult to change parts in the server remotely. We had on one of the projects waiting for five to six hours due to the fact that it was necessary for the global team of the company (IT head in India) to approve requests for the physical access of the engineer.
Service desk is important
If you want to see applications online, do not be too lazy to register the possibility of integrating your Service Desk system with the contractor or the need for a web-portal. This way you can transparently control the execution. Many customers who work via mail only receive the message "Your ticket is very important to us, and we will deal with it soon." And that's it, beyond the black box. And if the case is critical, everyone wants to see priority, they want to see who is working, microstats. Some asked to call every ten minutes. Now we have a dedicated person who stands next to the engineer, does not prevent him from solving the problem, but at the same time informs the customer about the status of critical cases, when everything is up, nothing works and everyone is nervous.
It was also very cool in one bank, where the rules for responding to incidents were described in an internal standard. Fortunately, they gave it to us. There were 300 pages written back in 2005 and updated in 2018 on top of a set of crutches. In general, among other things, logical, there was a procedure for responding to incidents with the collection of chat from important people exclusively in Skype. At night, you need to call all those interested and unsubscribe there. And Skype is not that very lively. I had to re-install it.
Certificates should not be in the company, but at the specialists of your project
Simple advice: make sure of the professionalism of the contractor, these are certificates and work experience in the company.
The harder tip is to make sure that these people will be on your project. There are companies that directly write to the TK who can be involved in work and who can not. Trainees are not suited to work with critical systems. You can write it like this: "Testing of specialists by our specialists." I've seen a man come to the piece of iron with a bundle of instructions. Says: "They found me on Yuda for 5 thousand rubles."
It happens that they gave a cool list, won, guys come to the kick-off meeting - and there are other people who did not participate, there are not a couple of necessary competencies. I know that there were cases on the market when teams were changed three times. In finance, the procedure is simple: there are lists of who can touch the infrastructure. They do not admit anyone just like that, only on the white list.
Finally
Write down all your requirements, types of work, types of applications and make a form in XLS with the inability to edit fields. Because very often suppliers try to write something of their own, and it is impossible to compare further. I know the advice is simple, but rarely does anyone use it. And then a mountain of time is wasted to figure out who promised what and who is more profitable in price.
Sample project
We support a retail company with stores in all regions of Russia (it increases by 13% in the number of stores over the year). The infrastructure consists of 1400 positions from different manufacturers, and functions that are critical for business operate on its basis. IT bears a huge number of development tasks. There, even the infrastructure support is already so great that the IT department alone cannot cope. There is a lot of equipment, it is necessary to somehow manage its life cycle. In general, they have been outsourcing routine tasks for five years. We have been with them for two years. In tasks:
- 24 x 7 monitoring of computing infrastructure and virtualization environment.
- Informing those responsible about the problems based on the monitoring results, for critical cases within 15 minutes.
- Entry of applications for replacement parts from manufacturers, replacement, informing about the restoration of work.
- , / .
- 1400 CMDB.
- , CMDB.
We have a team: the first line is responsible for monitoring and filing applications from vendors, the second for field work, the third for related areas (when the application software does not work, and it is not clear where the problem is). There is a dedicated technical manager, he supervises and coordinates all technical specialists; separately responsible for the CMDB; a separate service manager is responsible for overall project coordination.
About the contract. I must say right away that it contains an SLA for all work, as well as penalties for non-fulfillment. There is a possibility of a quarterly revision of the list of supported equipment with an easy recalculation of the cost, since there is a price list for each unit. We also hold regular meetings with the customer, where we discuss the results of the work and plans for the future.
The result is a saving of 5500 hours per year for the customer, which were spent by their own employees on development projects. 99.9% of SLA fulfillment (there were two violations in the first month in terms of notification terms, they were corrected due to regular feedback). The number of notifications from the monitoring system decreased by 30%, thanks to the optimal setting. CIO, when asked about how we work, replied: "We do not hear about you." He understands how important this is.
TK template here . There are 16 pages of hellish bureaucracy, which will save all parties nerves and many hundreds of hours of work, if you read and discuss once before signing.