
The purpose of this article is to share our first experience with MLflow .
We will start our review of MLflow from its tracking server and continue through all iterations of the study. Then we will share our experience of connecting Spark to MLflow using UDF.
Context
At Alpha Health, we use machine learning and artificial intelligence to empower people to take care of their health and well-being. This is why machine learning models are at the heart of the data products we develop, which is why our attention was drawn to MLflow, an open source platform that covers all aspects of the machine learning lifecycle.
MLflow
The main goal of MLflow is to provide an additional layer on top of machine learning that would allow data scientists to work with almost any machine learning library ( h2o , keras , mleap , pytorch , sklearn and tensorflow ), taking its work to the next level.
MLflow provides three components:
- Tracking - recording and querying experiments: code, data, configuration and results. It is very important to follow the process of creating the model.
- Projects - Packaging format to run on any platform (e.g. SageMaker )
- Models is a common format for submitting models to various deployment tools.
MLflow (alpha at the time of this writing) is an open source platform that allows you to manage the machine learning lifecycle, including experimentation, reuse, and deployment.
Configuring MLflow
To use MLflow, you first need to set up the entire Python environment, for that we'll use PyEnv (to install Python on Mac, take a look here ). So we can create a virtual environment where we will install all the libraries necessary to run.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Install the required libraries.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Note: we are using PyArrow to run models like UDFs. The PyArrow and Numpy versions needed to be fixed as the latest versions were conflicting.
Launch Tracking UI
MLflow Tracking allows us to log and make requests to experiments using Python and REST API. In addition, you can define where to store model artifacts (localhost, Amazon S3 , Azure Blob Storage , Google Cloud Storage, or SFTP server ). Since we are using AWS at Alpha Health, S3 will be used as the storage for the artifacts.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow recommends using persistent file storage. File storage is where the server will store run and experiment metadata. When starting the server, make sure it points to persistent file storage. Here we'll just use it for experiment
/tmp.
Remember that if we want to use the mlflow server to run old experiments, they must be present in the file store. However, even without this, we would be able to use them in the UDF, since we only need the path to the model.
Note: Keep in mind that the Tracking UI and the model client must have access to the location of the artifact. That is, regardless of the fact that the Tracking UI is located in the EC2 instance, when MLflow is launched locally, the machine must have direct access to S3 to write artifact models.
Tracking UI stores artifacts in an S3 bucket
Running models
Once the Tracking Server is running, you can start training the models.
As an example, we will use the wine modification from the MLflow example in Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvAs we already said, MLflow allows you to log parameters, metrics and artifacts of models so that you can track how they develop as you iterate. This feature is extremely useful, because this way we can reproduce the best model by contacting the Tracking server or by understanding which code has performed the required iteration using the git hash commit logs.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")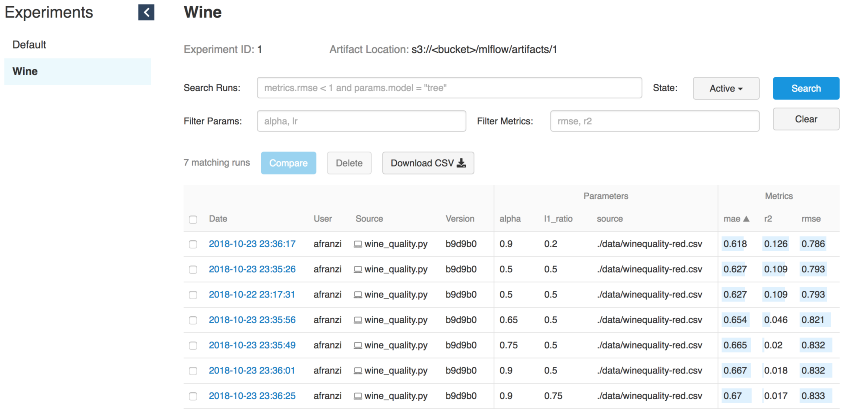
Wine iterations
Server part for the model
The MLflow tracking server, launched with the “mlflow server” command, has a REST API for tracking launches and writing data to the local file system. You can specify the tracking server address using the environment variable "MLFLOW_TRACKING_URI" and the MLflow tracking API will automatically contact the tracking server at this address to create / get launch information, log metrics, etc.To provide the model with a server, we need a running tracking server (see the launch interface) and a Run ID of the model.
Source: Docs // Running a tracking server

Run ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelTo serve models using the MLflow serve functionality, we need access to the Tracking UI to get information about the model simply by specifying
--run_id.
Once the model communicates with the Tracking Server, we can get the new model endpoint.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Running models from Spark
Despite the fact that the Tracking server is powerful enough to serve models in real time, train them and use the serve functionality (source: mlflow // docs // models # local ), using Spark (batch or streaming) is an even more powerful solution for distribution account.
Imagine you just did offline training and then applied the output model to all of your data. This is where Spark and MLflow will show their best.
Install PySpark + Jupyter + Spark
Source: Get started PySpark - Jupyter
To show how we apply MLflow models to Spark dataframes, we need to set up Jupyter notebooks to work together with PySpark.
Start by installing the latest stable version of Apache Spark :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Install PySpark and Jupyter in a virtual environment:
pip install pyspark jupyterSet up environment variables:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Once determined
notebook-dir, we can store our notebooks in the desired folder.
Launching Jupyter from PySpark
Since we were able to set up Jupiter as the PySpark driver, we can now run Jupyter notebooks in the PySpark context.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
As mentioned above, MLflow provides a function for logging model artifacts in S3. As soon as we have the selected model in our hands, we have the opportunity to import it as a UDF using the module
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark - Outputting Wine Quality Predictions
Up to this point, we've talked about how to use PySpark with MLflow by running wine quality predictions on the entire wine dataset. But what if you need to use Python MLflow modules from Scala Spark?
We tested this too by splitting the Spark context between Scala and Python. That is, we registered MLflow UDF in Python, and used it from Scala (yes, maybe not the best solution, but what we have).
Scala Spark + MLflow
For this example, we will add the Toree Kernel to the existing Jupiter.
Install Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```As you can see from the attached notebook, UDF is shared between Spark and PySpark. We hope this part will be helpful for those who love Scala and want to deploy machine learning models to production.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Next steps
Despite being in Alpha at the time of this writing, MLflow looks pretty promising. The mere ability to run multiple machine learning frameworks and use them from a single endpoint takes recommender systems to the next level.
In addition, MLflow brings Data Engineers and Data Scientists closer together by creating a common layer between them.
After doing this research on MLflow, we're confident we'll go ahead and use it for our Spark pipelines and recommender systems.
It would be nice to sync the file storage with the database instead of the file system. This way we need to get multiple endpoints that can use the same file storage. For example, use multiple instances of Prestoand Athena with the same Glue metastore.
To summarize, I'd like to thank the MLFlow community for making our work with data more interesting.
If you are playing with MLflow, feel free to write to us and tell us how you use it, and even more so if you use it in production.
Learn more about courses:
Machine Learning. Basic Machine Learning course
. Advanced course
Read more: