But all of these solutions didn't have what I needed:
- Centralized installation
- Search results taking into account access rights
- Search by document content
- Morphology
And I decided to make my own.
I will disclose point by point what I have in the form to avoid differences in interpretation and misunderstandings.
Centralized installation - client-server execution. All of the above solutions have one fundamental problem - each user makes his own local search index, which, in the case of large storage volumes, delays indexing, the user's profile on the machine grows, and is generally inconvenient in the event of a new employee arriving or moving to a new machine.
Search results taking into account the rights - everything is simple here - the results must correspond to the employee's rights to the file resource. Otherwise, it turns out that even if the employee does not have rights to the resource, he can read everything from the search cache. It will turn out awkward, agree? Search by the content of the document - search by the text of the document, everything is obvious here, it seems to me, and there can be no discrepancies.
Morphology is even simpler. Specified in the request "knife" and received both "knife" and "knives", "knife" and "knife". It is desirable for this to work for Russian and English.
We have decided on the formulation of the problem, we can proceed to implementation.
As a search engine, I chose the Sphinx system, and the interface development language was C # and .net, and as a result the project was named Vidocq (Vidocq) after the name of the French detective. Well, like, it finds everything and that's it.
Architecturally, the application looks like this: The
search robot recursively crawls a file resource and processes files according to a given list of extensions. Processing consists in retrieving the contents of the file, compressing the text - quotes, commas, extra spaces, etc. are removed from the text, then the contents are placed in the database (MS SQL), the date of the placement is marked and the robot moves on.
The Sphins indexer works directly with the received base, forming its own index and returning a pointer to the found file and a snippet of the found text fragment as a response.
A form was developed in C # that communicated with the Sphinx through the MySQL connector. Sphinx gives an array of files in accordance with the request, then the array is filtered for the access right of the user who is searching, the output is formatted and shown to the user.
We need to store the following information about the file:
- File id
- File name
- The path to the file
- File contents
- Expansion
- Date added to the database
This is all done in one table and the search robot will add everything to it. The date of addition is necessary so that when the robot on the next round it compares the date of the file modification with the date it was placed in the database, and if the dates differ, then update the information about the file.
Then set up the search engine itself. I will not describe the entire config, it will be available in the project archive, but I will only cover the main points.
The main request that forms the
source documents base : documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Setting up morphology through a lemmatizer.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}After that, you can set the indexer on the base and check the work.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateHere the path to the indexer is followed by the name of the index into which to place the processed one, the path to the config and the –rotate flag means that indexing will be performed on a profit, i.e. with the search service running. After indexing is complete, the index will be replaced with the updated one.
We check the work in the console. As an interface, you can use a MySQL client, taken, for example, from the web server kit.
mysql -h 127.0.0.1 -P 9306after that request select id from documets; should return a list of indexed documents, if, of course, you started the Sphinx service itself and did everything right.
Okay, the console is great, but we're not going to force users to type in commands, right?
I sketched out a form like this
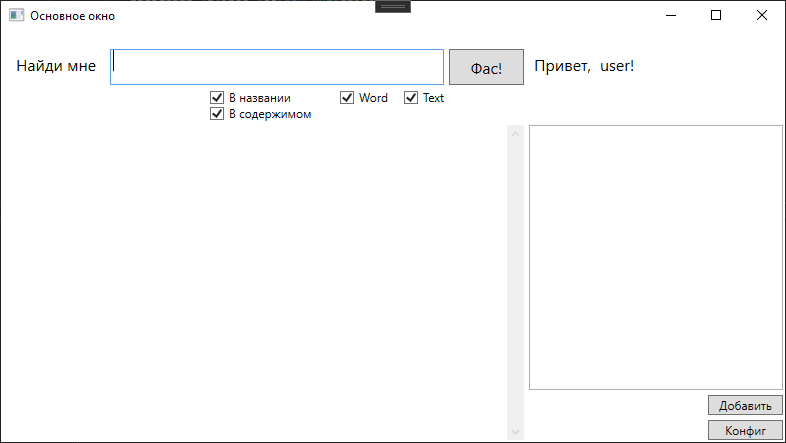
And here with the search results

When you click on a specific result, a document opens.
How is it implemented.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Yes, there is a bydloc code, but it's MVP.
Actually, a request to the Sphinx is formed here, depending on the set checkboxes. Checkboxes indicate the type of files in which to search and the search area.
Then the request goes to the Sphinx, and then the result is parsed.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}At the same stage, the issue is generated. Each element of the issue is a richtextbox with an event for opening a document on click. Items are placed on the StackPanel and before that the file is checked for the user. Thus, a file inaccessible to the user will not be included in the output.
The advantages of this solution:
- Indexing takes place centrally
- Accurate display based on access rights
- Customizable search by document type
Of course, for the full-fledged operation of such a solution, a file archive must be properly organized in the company. Ideally, roaming user profiles and so on should be configured. And yes, I know about SharePoint, Windows Search, and most likely a few more solutions. Then you can endlessly discuss the choice of a development platform, the search engine Sphinx, Manticore or Elastic, and so on. But I was interested in solving the problem with the tools in which I understand a little. It is currently running in MVP mode, but I am developing it.
But in any case, I am ready to listen to your suggestions about what points can be either improved or redone in the bud.