The Go language was first announced at the end of 2009, and officially released in 2012, but only in the past few years has it begun to gain serious recognition. Go was one of the fastest growing languages in 2018 and the third most popular programming language in 2019 .
Since the Go language itself is fairly new, the developer community is not very strict about how to write code. If we look at similar conventions in the communities of older languages, such as Java, it turns out that most projects have a similar structure. This can come in very handy when writing large codebases, however, many might argue that it would be counterproductive in modern practical contexts. As we move on to writing microsystems and maintaining relatively compact codebases, Go's flexibility in structuring projects becomes very attractive.
Everyone knows an example with hello world http on Golang , and it can be compared with similar examples in other languages, for example, in Java... There is no significant difference between the first and the second, neither in complexity nor in the amount of code that needs to be written to implement the example. But there is a fundamental difference in approach. Go encourages us to " write simple code whenever possible ." Aside from the object-oriented aspects of Java, I think the most important takeaway from these code snippets is this: Java requires a separate instance for each operation (instance
HttpServer), whereas Go encourages us to use the global singleton.
This way you have to maintain less code and pass fewer links in it. If you know that you only have to create one server (and this usually happens), then why bother with too much? This philosophy seems all the more compelling as your code base grows. Nevertheless, life sometimes throws up surprises :(. The fact is that you still have several levels of abstraction to choose from, and if you combine them incorrectly, you can make serious traps for yourself.
That is why I want to draw your attention to three approaches to organizing and structuring Go code. Each of these approaches implies a different level of abstraction. In conclusion, I will compare all three and tell you in which application cases each of these approaches is most appropriate.
We are going to implement an HTTP server that contains information about users (denoted as Main DB in the following figure), where each user is assigned a role (say, basic, moderator, administrator), and also implement an additional database (in the next figure, denoted as Configuration DB), which specifies the set of access rights reserved for each of the roles (e.g. read, write, edit). Our HTTP server must implement an endpoint that returns the set of access rights that the user with the given ID has.
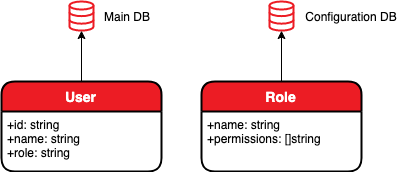
Next, let's assume that the configuration database changes infrequently and takes a long time to load, so we're going to keep it in RAM, load it when the server starts, and update it hourly.
All the code is in the repository for this article located on GitHub.
Approach I: Single package
The single-package approach uses a single-tier hierarchy where the entire server is implemented within a single package. All the code .
Warning: comments in the code are informative, important for understanding the principles of each approach.
/main.go
package main
import (
"net/http"
)
// ,
// , -,
// , .
var (
userDBInstance userDB
configDBInstance configDB
rolePermissions map[string][]string
)
func main() {
// ,
// ,
// .
//
// , , ,
// .
userDBInstance = &someUserDB{}
configDBInstance = &someConfigDB{}
initPermissions()
http.HandleFunc("/", UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
// , , .
func initPermissions() {
rolePermissions = configDBInstance.allPermissions()
go func() {
for {
time.Sleep(time.Hour)
rolePermissions = configDBInstance.allPermissions()
}
}()
}
/database.go
package main
// ,
// .
type userDB interface {
userRoleByID(id string) string
}
// `someConfigDB`.
//
// , MongoDB,
// `mongoConfigDB`.
// `mockConfigDB`.
type someUserDB struct {}
func (db *someUserDB) userRoleByID(id string) string {
// ...
}
type configDB interface {
allPermissions() map[string][]string //
}
type someConfigDB struct {}
func (db *someConfigDB) allPermissions() map[string][]string {
//
}
/handler.go
package main
import (
"fmt"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := userDBInstance.userRoleByID(id)
permissions := rolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Please note: we still use different files, this is for separation of concerns. This makes the code more readable and easier to maintain.
Approach II: Paired Packages
In this approach, let's learn what batching is. The package must be solely responsible for some specific behavior. Here we allow packages to interact with each other - thus we have to maintain less code. However, we need to make sure that we do not violate the principle of sole responsibility and therefore ensure that each piece of logic is fully implemented in a separate package. Another important guideline for this approach is that since Go does not allow circular dependencies between packages, you need to create a neutral package that contains only bare interface definitions and singleton instances . This will get rid of the ring dependencies. The whole code...
/main.go
package main
// : main – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/definition"
"github.com/myproject/handler"
"net/http"
)
func main() {
// , ,
// , ,
// .
definition.UserDBInstance = &database.SomeUserDB{}
definition.ConfigDBInstance = &database.SomeConfigDB{}
config.InitPermissions()
http.HandleFunc("/", handler.UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
/definition/database.go
package definition
// , ,
// .
// , ;
// , , ,
// .
var (
UserDBInstance UserDB
ConfigDBInstance ConfigDB
)
type UserDB interface {
UserRoleByID(id string) string
}
type ConfigDB interface {
AllPermissions() map[string][]string //
}
/definition/config.go
package definition
var RolePermissions map[string][]string
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"github.com/myproject/definition"
"time"
)
// ,
// config.
func InitPermissions() {
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
}
}()
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"github.com/myproject/definition"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := definition.UserDBInstance.UserRoleByID(id)
permissions := definition.RolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}Approach III: Independent packages
With this approach, the project is also organized in packages. In this case, each package must integrate all of its dependencies locally , via interfaces and variables . Thus, it knows absolutely nothing about other packages . With this approach, the package with definitions mentioned in the previous approach will actually be spread out between all other packages; each package declares its own interface for each service. At first glance, this may seem like annoying duplication, but in reality it is not. Each package that uses a service must declare its own interface, which specifies only what it needs from this service and nothing else. The whole code...
/main.go
package main
// : – ,
// .
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/handler"
"net/http"
)
func main() {
userDB := &database.SomeUserDB{}
configDB := &database.SomeConfigDB{}
permissionStorage := config.NewPermissionStorage(configDB)
h := &handler.UserPermissionsByID{UserDB: userDB, PermissionsStorage: permissionStorage}
http.Handle("/", h)
http.ListenAndServe(":8080", nil)
}
/database/user.go
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
//
}
/database/config.go
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
//
}
/config/permissions.go
package config
import (
"time"
)
// , ,
// , ,
// `AllPermissions`.
type PermissionDB interface {
AllPermissions() map[string][]string //
}
// ,
// , , ,
//
type PermissionStorage struct {
permissions map[string][]string
}
func NewPermissionStorage(db PermissionDB) *PermissionStorage {
s := &PermissionStorage{}
s.permissions = db.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
s.permissions = db.AllPermissions()
}
}()
return s
}
func (s *PermissionStorage) RolePermissions(role string) []string {
return s.permissions[role]
}
/handler/user_permissions_by_id.go
package handler
import (
"fmt"
"net/http"
"strings"
)
//
type UserDB interface {
UserRoleByID(id string) string
}
// ... .
type PermissionStorage interface {
RolePermissions(role string) []string
}
// ,
// , .
type UserPermissionsByID struct {
UserDB UserDB
PermissionsStorage PermissionStorage
}
func (u *UserPermissionsByID) ServeHTTP(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := u.UserDB.UserRoleByID(id)
permissions := u.PermissionsStorage.RolePermissions(role)
fmt.Fprint(w, strings.Join(permissions, ", "))
}That's all! We've looked at three levels of abstraction, the first of which is the thinnest, containing global state and tightly coupled logic, but providing the fastest implementation and the least amount of code to write and maintain. The second option is a mild hybrid, and the third is completely self-contained and suitable for repeated use, but comes with maximum effort with support.
Pros and cons
Approach I: Single Package
For
- Less code, much faster implementation, less maintenance work
- No packets, which means you don't have to worry about ring dependencies
- Easy to test as service interfaces exist. To test a piece of logic, you can specify any implementation of your choice (concrete or mocked) for the singleton, and then run the test logic.
Against
- The only package also does not provide for private access, everything is open from everywhere. As a result, developer responsibility increases. For example, remember that you cannot directly instantiate a structure when a constructor function is required to perform some initialization logic.
- Global state (singleton instances) can create unfulfilled assumptions, for example, an uninitialized singleton instance can trigger a null pointer panic at runtime.
- Since the logic is tightly coupled, nothing in this project can be easily reused, and it will be difficult to extract any components from it.
- When you don't have packages that independently manage each piece of logic, the developer must be very careful and place all the pieces of code correctly, otherwise unexpected behaviors may occur.
Approach II: Paired Packages
Per
- When packaging a project, it is more convenient to guarantee responsibility for specific logic within the package, and this can be enforced using the compiler. In addition, we will be able to use private access and control which elements of the code are open to us.
- Using a package with definitions allows you to work with singleton instances while avoiding circular dependencies. This way you can write less code, avoid passing references when managing instances, and avoid wasting time on problems that can potentially arise during compilation.
- This approach is also conducive to testing, because there are service interfaces. With this approach, internal testing of each package is possible.
Against
- There are some overheads when organizing a project in packages - for example, the initial implementation should take longer than with a single package approach.
- Using global state (singleton instances) with this approach can also cause problems.
- The project is divided into packages, which greatly facilitates the extraction and reuse of individual elements. However, packages are not completely independent as they all interact with a definition package. With this approach, code extraction and reuse is not completely automatic.
Approach III: Independent
Pros
- When using packages, we ensure that the specific logic is implemented within a single package and we have complete control over access.
- There should be no potential circular dependencies as the packages are completely self-contained.
- All packages are highly recoverable and reusable. In all those cases when we need a package in another project, we simply transfer it to a shared space and use it without changing anything in it.
- If there is no global state, then there are no unintended behaviors.
- This approach is best for testing. Each package can be fully tested without worrying that it might depend on other packages through local interfaces.
Against
- This approach is much slower to implement than the previous two.
- Much more code needs to be maintained. Because links are being passed, many places have to be updated after major changes are made. Also, when we have multiple interfaces that provide the same service, we have to update those interfaces every time we make changes to that service.
Conclusions and examples of use
Given the lack of guidelines for writing code in Go, it takes many different shapes and forms, and each option has its own interesting merits. However, mixing different design patterns can cause problems. To give you an idea of them, I've covered three different approaches to writing and structuring Go code.
So when should each approach be used? I suggest this arrangement:
Approach I : The single-package approach is perhaps most appropriate when working in small, highly experienced teams on small projects where quick results are required. This approach is simpler and more reliable for a quick start, although it requires serious attention and coordination at the stage of project support.
Approach II: The paired-packet approach can be called a hybrid synthesis of the other two approaches: among its advantages are relatively quick start and ease of support, while at the same time, it creates conditions for strict adherence to the rules. It is appropriate for relatively large projects and large teams, but it has limited reusability of the code and there are certain difficulties in maintaining.
Approach III : The independent packages approach is most appropriate for projects that are complex in themselves, are long-term, developed by large teams, and for projects that have pieces of logic that are created with an eye to further reuse. This approach takes a long time to implement and is difficult to maintain.