Parsing
What is parsing? This is the collection and systematization of information that is posted on websites using special programs that automate the process.
Parsing is commonly used for pricing analysis and content retrieval.
Start
To collect money from bookmakers, I had to promptly receive information about the odds for certain events from several sites. We will not go into the mathematical part.
Since I studied C # in my sharaga, I decided to write everything in it. The guys at Stack Overflow advised using Selenium WebDriver. It is a browser driver (software library) that allows you to develop programs that control browser behavior. That's what we need, I thought.
I installed the library and ran to watch the guides on the Internet. After a while, I wrote a program that could open a browser and follow some links.
Hooray! Although stop, how to press the buttons, how to get the necessary information? XPath will help us here.
XPath
In simple terms, it is a language for querying XML and XHTML document elements.
For this article, I will be using Google Chrome. However, other modern browsers should have, if not the same, then a very similar interface.
To see the code of the page you are on, press F12.

To see where in the code there is an element on the page (text, picture, button), click on the arrow in the upper left corner and select this element on the page. Now let's move on to the syntax.
Standard syntax for writing XPath:
// tagname [@ attribute = 'value']
// : Selects all nodes in the html document starting from the current node
Tagname : Tag of the current node.
@ : Selects attributes
Attribute : The name of the attribute of the node.
Value : The value of the attribute.
It may be confusing at first, but after the examples, everything should fall into place.
Let's look at some simple examples:
// input [@ type = 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart. com ']
Consider more complex examples for the given html'i:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
The following elements will be selected for this XPath:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Note the difference between / (fetches from the root node) and // (fetches nodes from the current node regardless of their location). If it is not clear, then look at the examples above again.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
This request is the same with this html :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' link 'andhref= 'habr.com'] / span
// span [text () = 'habr' or text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [contains (href, 'habr')] / span
// span [contains (text (), 'habr')]
Result:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text () = 'habr'] / parent :: a / parent :: div
Equal to
// div / div [@ class = 'listItem'] [1]
Result:
<div class = 'listItem'>parent :: - Returns the parent one level up.
There is also a super cool feature such as following-sibling :: - returns many elements at the same level following the current one, similar to preceding-sibling :: - returns many elements at the same level preceding the current one.
// span [@ class = 'name'] / following-sibiling :: text () [1]
Result:
"text1"
"text2"I think it's clearer now. To consolidate the material, I advise you to go to this site and write a few requests to find some elements of this html'i.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Now that we know what XPath is, let's get back to writing the code. Since the Habr moderators do not like bookmakers, they will parse the prices for coffee in Walmart
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep's were written so that the web page had time to load.
The program will open the Walmart store website, press a couple of buttons, open the coffee section and get the name and prices of the goods.
If the web page is quite large and therefore XPaths take a long time or are difficult to write, then you need to use some other method.
HTTP requests
First, let's look at how content appears on the site.

In simple words, the browser makes a request to the server with a request to provide the necessary information, and the server, in turn, provides this information. All this is done using HTTP requests.
To look at the requests that your browser sends on a specific site, just open this site, press F12 and go to the Network tab, then reload the page.

Now it remains to find the request we need.
How to do it? - consider all requests with the fetch type (third column in the picture above) and look at the Preview tab.

If it is not empty, then it must be in XML or JSON format, if not, keep looking. If so, see if the information you need is here. To check this, I advise you to use some kind of JSON Viewer or XML Viewer (google and open the first link, copy the text from the Response tab and paste it into the Viewer). When you find the request you need, then save its name (left column) or the URL host (Headers tab) somewhere, so that you do not search later. For example, if you open a coffee department on the walmart website, then a request will be sent, the legal of which begins with walmart.com/cp/api/wpa. There will be all the information about coffee on sale.
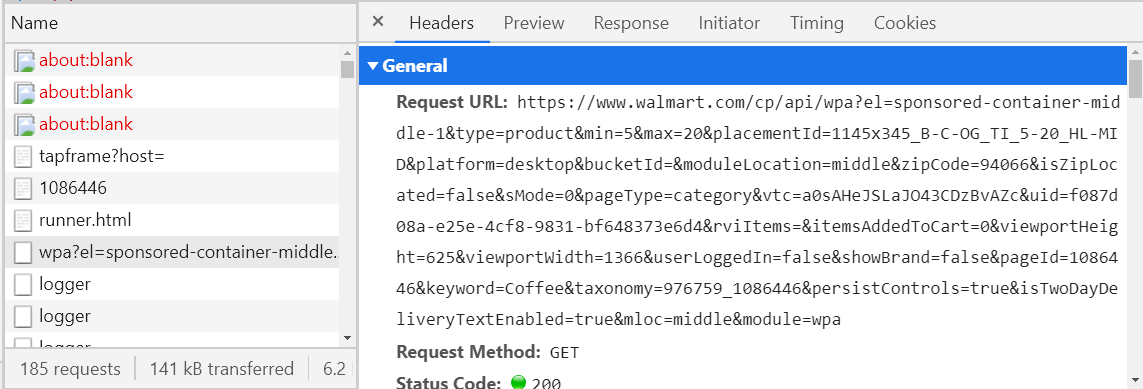
Halfway passed, now this request can be "faked" and sent immediately through the program, receiving the necessary information in a matter of seconds. It remains to parse JSON or XML, and this is much easier than writing XPaths. But often the formation of such requests is a rather unpleasant thing (see the URL in the picture above) and if you even succeed, then in some cases you will receive such a response.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Now you will learn how you can avoid problems with imitating a request using an alternative - a proxy server.
Proxy server
A proxy server is a device that mediates between a computer and the Internet.
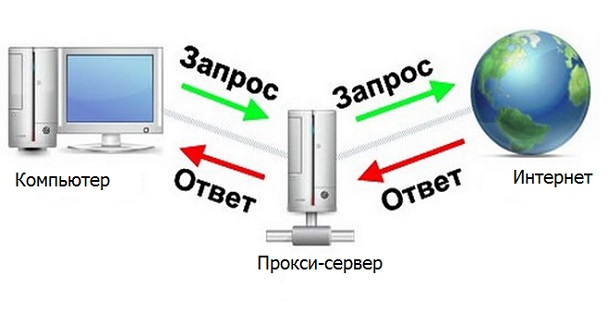
It would be great if our program were a proxy server, then you can quickly and conveniently process the necessary responses from the server. Then there would be such a chain Browser - Program - Internet (site server that is parsed).
Fortunately for si sharp there is a wonderful library for such needs - Titanium Web Proxy.
Let's create the PServer class
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Now let's go over each method separately.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone - add a method for processing a response from the server. It will be called automatically when the response arrives.
explicitEndPoint - Proxy server configuration,
ExplicitProxyEndPoint (IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress and port on which the proxy server is running.
decryptSsl - whether to decrypt SSL. In other words, if decrtyptSsl = true, then the proxy server will process all requests and responses.
explicitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest - add a method for processing the request before sending it to the server. It will also be called automatically before the request is sent.
proxyServer.Start () - "starting" the proxy server, from this moment it starts processing requests and responses.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false - the current request and response will not be processed.
If we are not interested in the request or the response to it (for example, a picture or some kind of script), then why decrypt it? Quite a lot of resources are spent on this, and if all requests and responses are decrypted, the program will work for a long time. Therefore, if the current request does not contain the host of the request we are interested in, then there is no point in decrypting it.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString () - returns a response as a string.
For WebDriver to connect to the proxy server, you need to write the following:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Now you can handle the requests you want.
Conclusion
With WebDriver, you can navigate pages, click on buttons and imitate the behavior of a regular user. With XPaths, you can extract the information you need from web pages. If XPaths do not work, then a proxy server can always help, which can intercept requests between the browser and the site.