The project has grown, the library now solves all the basic tasks of processing the natural Russian language: segmentation into tokens and sentences, morphological and syntactic analysis, lemmatization, extraction of named entities.

For news articles, the quality on all tasks is comparable or superior to existing solutions... For example, Natasha copes with the NER task by 1 percentage point worse than Deeppavlov BERT NER (F1 PER 0.97, LOC 0.91, ORG 0.85), the model weighs 75 times less (27MB), works on the CPU 2 times faster (25 articles / sec ) than BERT NER on GPU.
There are 9 repositories in the project , the Natasha library combines them under one interface. In this article, we will talk about new tools, compare them with existing solutions: Deeppavlov , SpaCy , UDPipe .

This longread was preceded by a series of posts on natasha.github.io :If you are intimidated by the size of the text below, watch the first 20 minutes of the tube stream about the history of the Natasha project, there is a short retelling:
- Natasha - high-quality compact NER for the Russian language
- Navec - compact embeddings for the Russian language
- Corus - collection of Russian-language NLP datasets
- Razdel - segmentation of Russian-language text into tokens and offers
- Naeval - quantitative comparison of systems for Russian-speaking NLP
- Nerus is a large synthetic Russian-language dataset with markup of morphology, syntax and named entities
The text uses notes and discussions from the t.me/natural_language_processing chat , links to new materials appear in the same place:
- Why Natasha isn't using Transformers. BERT in 100 lines
- Slovnet BERT models
- Tube stream about the history of the Natasha project
- Updated Yargy Documentation
- Additional resources on the Yargy parser
For those who like to listen more, check out the hourly talk at Datafest 2020, it almost covers this post:
Content:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Previously, the Natasha library solved the NER problem for the Russian language, was built on rules , showed average quality and performance. Now Natasha is a whole big project, it consists of 9 repositories . The Natasha library unites them under one interface, solves the basic tasks of processing the natural Russian language: segmentation into tokens and sentences, pre-trained embeddings, morphology and syntax analysis, lemmatization, NER. All solutions show top results in news topics , run fast on CPU.
Natasha is similar to other combine libraries: SpaCy , UDPipe , Stanza... SpaCy initializes and calls models implicitly, the user passes the text to the magic function
nlp, gets a fully parsed document.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
Natasha's interface is more verbose. The user explicitly initializes components: loads pretrained embeddings, passes them to model constructors. Sam calls methods
segment, tag_morph, parse_syntaxsegmentation into tokens and demand, analysis of morphology and syntax.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
The named entity extractor does not depend on the results of morphological and parsing, it can be used separately.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha solves the problem of lemmatization, uses Pymorphy2 and the results of morphological analysis.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
To bring the phrase to a normal form, it is not enough to find the lemmas of individual words, for the Russian Foreign Ministry it will turn out to be the Russian Foreign Ministry, for the Organization of Ukrainian Nationalists - the Ukrainian Nationalist Organization. Natasha uses the results of parsing, takes into account relationships between words, normalizes named entities.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha finds names, names of organizations and place names in the text. For names in the library there is a set of ready-made rules for the Yargy-parser , the module divides the normalized names into parts, from "Viktor Fedorovich Yushchenko" is obtained
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
The library contains rules for parsing dates, amounts of money and addresses, they are described in the documentation and reference book .
The Natasha library is well suited for demonstrating project technologies, used in education. Archives with model weights are built into the package, after installation you do not need to download and configure anything.
Natasha combines other project libraries under one interface. To solve practical problems, you should use them directly:
- Razdel - segmentation of text into sentences and tokens;
- Navec - high quality compact embeddings;
- Slovnet - modern compact models for morphology, syntax, NER;
- Yargy - rules and vocabularies for extracting structured information;
- Ipymarkup - visualization of NER and syntactic markup;
- Corus - collection of links to public Russian-language datasets;
- Nerus is a large corpus with automatic markup of named entities, morphology and syntax.
Razdel - segmentation of Russian-language text into tokens and offers

The Razdel library is part of the Natasha project, divides the Russian-language text into tokens and sentences. Installation instructions , usage example and performance measurements in the Razdel repository.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Modern models often don't bother with segmentation, use BPE , show remarkable results, remember all versions of GPT and the BERT zoo . Natasha solves the problems of parsing morphology and syntax, they make sense only for separate words within one sentence. Therefore, we responsibly approach the stage of segmentation, trying to repeat the markup from popular open datasets: SynTagRus , OpenCorpora , GICRYA .
Razdel's speed and quality are comparable or better than other open source solutions for the Russian language.
| Token segmentation solutions | Errors per 1000 tokens | Processing time, seconds |
| Regexp-baseline | 19 | 0.5 |
| SpaCy
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| Moses
|
eleven | 1.9 |
| SegTok
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
The number of errors is average over 4 datasets : SynTagRus , OpenCorpora , GICRYA and RNC . More details in the Razdel repository .
Why do we need Razdel at all, if a baseline with a regular line gives a similar quality and there are a lot of ready-made solutions for the Russian language? In fact, Razdel is not just a tokenizer, but a small rules-based segmentation engine. Segmentation is a basic task, often encountered in practice. For example, there is a judicial act, you need to highlight the operative part in it and divide it into paragraphs. Naturally, off-the-shelf solutions cannot do that. Read how to write your own rules in the source code . Further we will talk about how to push yourself and make a top solution for tokens and offers on our engine.
What is the difficulty?
In Russian, sentences usually end with a period, question mark or exclamation mark. Let's just split the text with a regular expression
[.?!]\s+. This solution will give 76 errors per 1000 sentences. Types and examples of mistakes:
Abbreviations
... any platform with an audience of 3,000 or more people is a blogger.
... a beat stood over them from the end of the 17th century;
… At the Chamber Musical Theater named after ▒B.A. Pokrovsky.
Initials
Following the operas "Idomeneo" by V.A.▒Mozart - R.▒Strauss ...
Lists
2. I thought there would be a beautiful long queue at the Finnish consulate ...
g . Tickets for trains of Russian railways ...
At the end of the sentence, a smiley face or typographic ellipsis
Whoever proposes a way to get rid of the minuses - thanks to that :) ▒ I looked, thoughtful ... ▒ Now this is more unpleasant, since the content will be broken.
Quotes, direct speech, at the end of the sentence a quotation mark
- do you have a bride in town? ”▒“ Who has a bride for? ”.
“It's so good that I'm not like that!” ▒Now, while translating, I made a Freudian mistake: “idology”.
Razdel takes these nuances into account, reducing the number of errors from 76 to 43 per 1000 sentences.
The situation is similar with tokens. A good basic solution is a regex
[--]+|[0-9]+|[^-0-9 ], it makes 19 errors per 1000 tokens. Examples:
Fractional numbers, complex punctuation
... In the late 1980s - early 1990s
... BS-▒3 can be noted slightly less mass (3▒, ▒6 t)
- and she died ▒.▒. Do you understand the girl, falcon? ▒!
Razdel is reducing the error rate to 7 per 1000 tokens.
Principle of operation
The system is built on rules. The principle of segmentation into tokens and offers is the same.
Collection of candidates
We find in the text all candidates for the end of the sentence: periods, ellipses, brackets, quotes.
6.▒The most frequent and at the same time highly rated option of answers “I am glad” ▒ (13 statements, 25 points) ▒– situations of receiving approval and encouragement. ▒7.▒ It is noteworthy that in the answer “I know” it is estimated as the most stereotypical , but only once the answer “I am a woman” is encountered ▒; there are statements “one marriage is all that awaits me in this life” ▒ and “sooner or later I will have to give birth” ▒.▒ Compilers: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
For tokens, we split the text into atoms. The token border does not exactly pass inside the atom.
At the end of 1980▒-▒▒-beginning1990▒-▒▒
BS▒-▒3▒ it is possible▒to mark▒ a slightly▒ smaller▒mass▒ (▒3▒, ▒6▒▒) ▒
▒— Da▒and▒umerla▒.▒.▒.▒Got ▒ligirl, ▒the falcon▒? ▒!
Union
We consistently bypass candidates for separation, remove unnecessary ones. We use a list of heuristics.
List item. The separator is a period or a parenthesis, on the left is a number or letter
6.▒The most frequent and at the same time highly appreciated answer “I'm glad” (13 statements, 25 points) is a situation of receiving approval and encouragement. 7.▒ It is noteworthy that in the answer "I know" ...
Initials. Separator - dot, one capital letter on the left
... Compilers: V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov ...
There is no space to the right of the separator
... but only once is the answer "I am a woman" ▒; there are statements “one marriage is all that awaits me in this life” and “sooner or later I will have to give birth” ▒.
There is no end-of-sentence mark before the closing quotation mark or parenthesis, this is not a quote or direct speech
6. The most frequent and highly appreciated answer is “I'm glad” «(13 statements, 25 points) ▒ - situations of getting approval and encouragement. ... "one marriage is all that awaits me in this life" and "sooner or later I will have to give birth."
As a result, there are two separators left, we consider them the ends of sentences.
6. The most frequent and at the same time highly appreciated variant of answers “I am glad” (13 statements, 25 points) is a situation of receiving approval and encouragement.▒7. It is noteworthy that in the answer “I know” it is assessed as the most stereotypical, but only once the answer “I am a woman” is encountered; there are statements “one marriage is all that awaits me in this life” and “sooner or later I will have to give birth.” ▒Composers: V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
The procedure is similar for tokens, the rules are different.
Fraction or rational number
... (3▒, ▒6 t) ...
Complex punctuation
- yes, and died.▒.▒. Do you understand the girl, falcon? ▒!
There are no spaces around the hyphen, this is not the beginning of direct speech
At the end of 1980▒-▒ - early 1990▒-▒
BS▒-▒3 it can be noted ...
All that remains is considered the boundaries of tokens.
At the end of 1980s-x▒-early▒1990-x▒
BS-3▒ it is possible▒tonoticeslightly▒lower▒mass▒ (▒3,6▒t▒) ▒
▒ — yes and died. ..▒Got it▒li▒girl, ▒sokol▒ ?!
Limitations
Razdel rules are optimized for neatly written text with correct punctuation. The solution works well with news articles, literary texts. On posts from social networks, transcripts of telephone conversations, the quality is lower. If there is no space between sentences or no period at the end, or the sentence starts with a lowercase letter, Razdel will make a mistake. Read
how to write rules for your tasks in the source code , this topic has not yet been disclosed in the documentation.
Slovnet - deep learning modeling for natural Russian language processing

In the project Natasha Slovnet is engaged in teaching and inferencing modern models for Russian-speaking NLP. The library contains high-quality compact models for extracting named entities, parsing morphology and syntax. The quality on all tasks is comparable or superior to other open solutions for the Russian language on news texts. Installation instructions , examples of use - in the Slovnet repository . Let's take a closer look at how the solution for the NER problem is arranged, for morphology and syntax everything is by analogy.
At the end of 2018, after an article from Google about BERT , there was a lot of progress in English-language NLP. In 2019, the guys from the DeepPavlov projectadapted multilingual BERT for Russian, RuBERT appeared . A CRF head was trained on top , it turned out DeepPavlov BERT NER - SOTA for the Russian language. The model has excellent quality, 2 times fewer errors than the closest pursuer DeepPavlov NER , but the size and performance are scary: 6GB - consumption of GPU RAM, 2GB - size of the model, 13 articles per second - performance on a good GPU.
In 2020, in the Natasha project, we managed to come close in quality to DeepPavlov BERT NER, the model size turned out to be 75 times smaller (27MB), memory consumption is 30 times less (205MB), the speed is 2 times higher on the CPU (25 articles per second ).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 by tokens, average by Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0.97 / 0.91 / 0.85 | 0.98 / 0.92 / 0.86 |
| Model size | 27MB | 2GB |
| Memory consumption | 205MB | 6GB (GPU) |
| Performance, news articles per second (1 article ≈ 1KB) | 25 per CPU (Core i5) | 13 GPU (RTX 2080 Ti), 1 CPU |
| Initialization time, seconds | 1 | 35 |
| The library supports | Python 3.5+, PyPy3 | Python 3.6+ |
| Dependencies | NumPy | TensorFlow |
The quality of Slovnet NER is 1 percentage point lower than that of SOTA DeepPavlov BERT NER, the size of the model is 75 times smaller, the memory consumption is 30 times less, the speed is 2 times higher on the CPU. Comparison with SpaCy, PullEnti and other solutions for Russian-speaking NER in the Slovnet repository .
How do you get this result? Short recipe:
Slovnet NER = Slovnet BERT NER - analogue of DeepPavlov BERT NER + distillation through synthetic markup ( Nerus ) in WordCNN-CRF with quantized embeddings ( Navec ) + engine for inference on NumPy.
Now in order. The plan is as follows: train a heavy model with BERT architecture on a small manually annotated dataset. We mark it with a news corpus, and we get a big dirty synthetic training dataset. Let's train a compact primitive model on it. This process is called distillation: the heavy model is the teacher, the compact model is the student. We expect that the BERT architecture is redundant for the NER problem, the compact model will not lose much in quality to the heavy one.
Model teacher
DeepPavlov BERT NER consists of a RuBERT encoder and a CRF head. Our heavy teacher model repeats this architecture with minor improvements.
All benchmarks measure NER quality on news texts. Let's train RuBERT on the news. The Corus repository contains links to public Russian-language news corpus, a total of 12 GB of texts. We use techniques from the Facebook article about RoBERTa : large aggregated batches, dynamic mask, refusal to predict the next sentence (NSP). RuBERT uses a huge vocabulary of 120,000 subtokens - a legacy of Google's multilingual BERT. Reducing the size to the 50,000 most frequent news items, coverage will decrease by 5%. Get NewsRuBERTThe model predicts disguised subtokens in the news 5 percentage points better than RuBERT (63% in the top 1).
Let's train NewsRuBERT encoder and CRF head for 1000 articles from Collection5 . We get Slovnet BERT NER , the quality is 0.5 percentage points better than that of DeepPavlov BERT NER, the size of the model is 4 times smaller (473MB), it works 3 times faster (40 articles per second).
NewsRuBERT = RuBERT + 12GB of news + techniques from RoBERTa + 50K dictionary.
Slovnet BERT NER (analogue of DeepPavlov BERT NER) = NewsRuBERT + CRF head + Collection5.
Now, to train models with BERT-like architecture, it is customary to use Transformers from Hugging Face. Transformers are 100,000 lines of Python code. When loss or garbage explodes on inference, it's hard to figure out what went wrong. Okay, a lot of code is duplicated there. Even if we train RoBERTa, we can quickly localize the problem to ~ 3000 lines of code, but this is also a lot. With modern PyTorch, the Transformers library isn't nearly as relevant. With
torch.nn.TransformerEncoderLayerthe RoBERTa-like model code takes 100 lines:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
This is not a prototype, the code is copied from the Slovnet repository . Transformers are useful to read, they do a lot of work, stuff the code for articles with Arxiv, often the Python source is clearer than the explanation in a scientific article.
Synthetic dataset
Let's mark 700,000 articles from the Lenta.ru corpus with a heavy model. We get a huge synthetic training dataset. The archive is available in the Nerus repository of the Natasha project. The markup is very high quality, F1 estimates by tokens: PER - 99.7%, LOC - 98.6%, ORG - 97.2%. Rare examples of errors:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Model learner
There were no problems with the choice of the architecture of the heavy teacher model, there was only one option - transformers. The compact student model is more difficult, there are many options. From 2013 to 2018, from the advent of word2vec to the article on BERT, mankind came up with a bunch of neural network architectures to solve the NER problem. All have a common scheme:
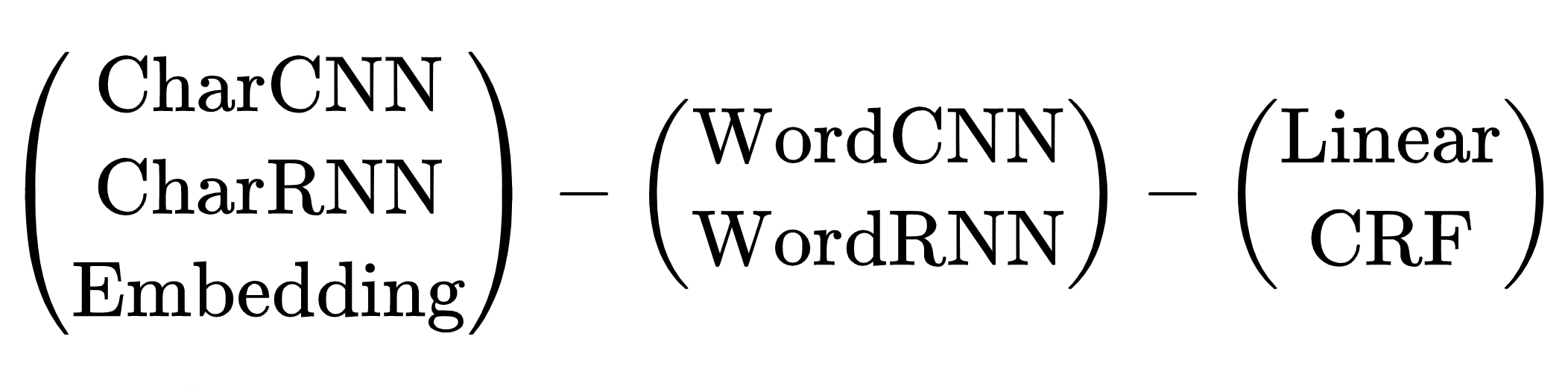
Scheme of neural network architectures for the NER task: token encoder, context encoder, tag decoder. Explanations of abbreviations in a review article by Yang (2018) .
There are many combinations of architectures. Which one to choose? For example, (CharCNN + Embedding) -WordBiLSTM-CRF is a model diagram from an article about DeepPavlov NER , SOTA for the Russian language until 2019.
We skip the options with CharCNN, CharRNN, launching a small neural network by symbols on each token is not our way, too slow. I would also like to avoid WordRNN, the solution should work on the CPU, multiply matrices on each token slowly. For NER, the choice between Linear and CRF is conditional. We use BIO encoding, the order of the tags is important. We have to endure terrible brakes, use CRF. There remains one option - Embedding-WordCNN-CRF. This model is not case sensitive, for NER it is important, "hope" is just a word, "Hope" is possibly a name. Add ShapeEmbedding - embedding with token outlines, for example: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_ !, "and" - RU_x, "5.1" - NUM, "New York" - RU_Xx-Xx. Slovnet NER Scheme - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Distillation
Let's train Slovnet NER on a huge synthetic dataset. Let's compare the result with the heavy model-teacher Slovnet BERT NER. The quality is calculated and averaged over the manually marked Collection5, Gareev, factRuEval-2016, BSNLP-2019. The size of the training sample is very important: for 250 news articles (factRuEval-2016), the average for PER, LOC, LOG F1 is 0.64, for 1000 (analogous to Collection5) - 0.81, for the entire dataset - 0.91, Slovnet BERT NER quality is 0.92.
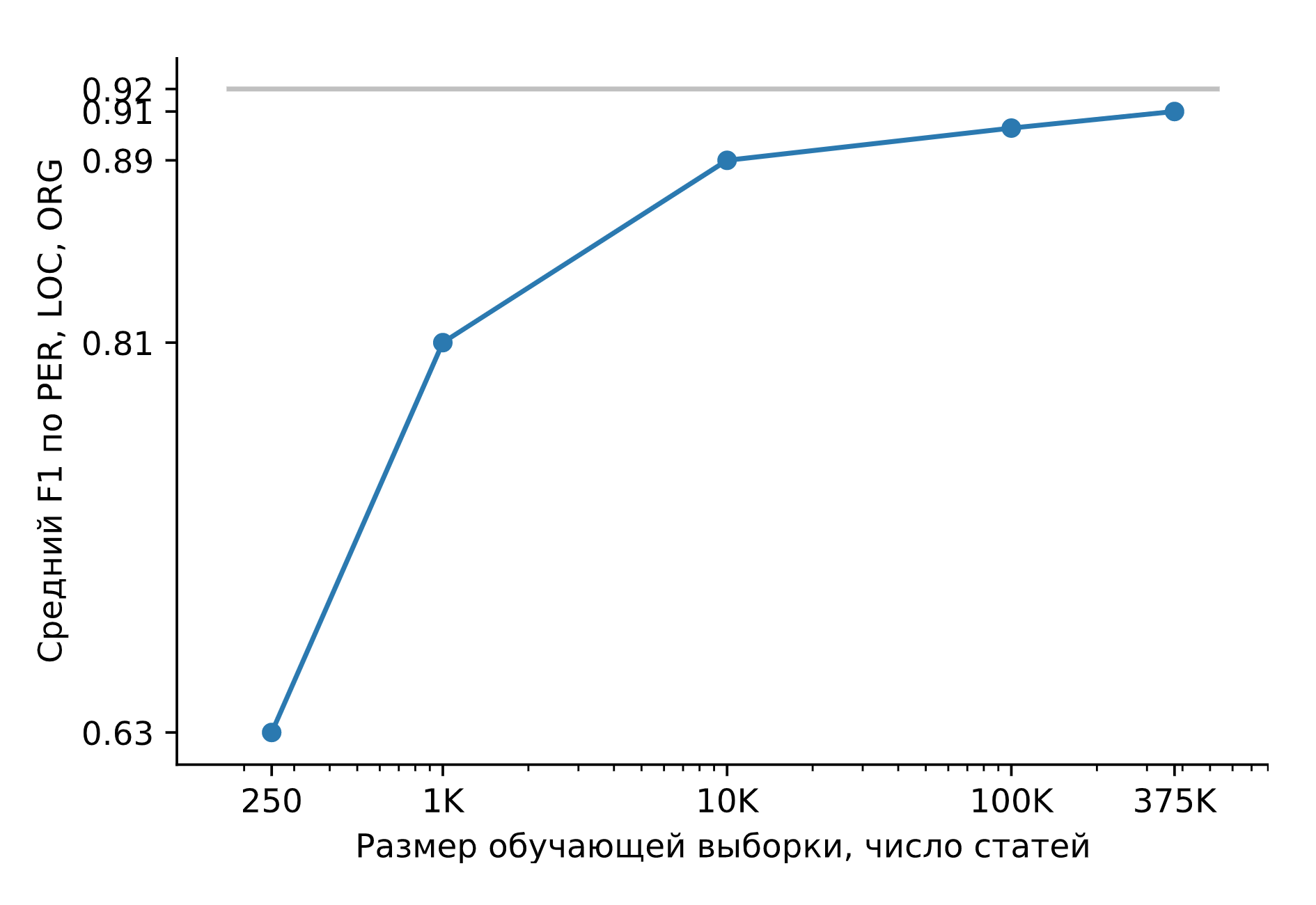
Slovnet NER quality, dependence on the number of synthetic training examples. Gray line - Slovnet BERT NER quality. Slovnet NER does not see hand-marked examples, it trains only on synthetic data.
The primitive student model is 1 percentage point worse than the hard teacher model. This is a wonderful result. A universal recipe suggests itself:
We mark up some data manually. We train a heavy transformer. We generate a lot of synthetic data. We train a simple model on a large sample. We get the quality of the transformer, the size and performance of a simple model.
In the Slovnet library there are two more models trained according to this recipe: Slovnet Morph - morphological tagger, Slovnet Syntax - syntactic parser. Slovnet Morph lags behind the heavy teacher model by 2 percentage points , Slovnet Syntax - by 5 . Both models have better quality and performance than existing Russian solutions for news articles.
Quantization
Slovnet NER is 289MB in size. 287MB is occupied by a table with embeddings. The model uses a large vocabulary of 250,000 lines, which covers 98% of words in news texts. Using quantization , replace 300-dimensional float vectors with 100-dimensional 8-bit ones. The size of the model will be reduced 10 times (27MB), the quality will not change. The Navec library is part of the Natasha project, a collection of quantized pre-trained embeddings. Weights trained on fiction take 50MB, bypassing all static RusVectores models according to synthetic estimates .
Inference
Slovnet NER uses PyTorch for training. The PyTorch package weighs 700MB, I don't want to drag it into production for inference. PyTorch also does not work with the PyPy interpreter . Slovnet is used in conjunction with a Yargy parser, an analogue of the Yandex Tomita parser . With PyPy, Yargy works 2-10 times faster, depending on the complexity of the grammars. I don't want to lose speed due to dependence on PyTorch.
The standard solution is to use TorchScript or convert the model to ONNX , make the inference in ONNXRuntime . Slovnet NER uses non-standard blocks: quantized embeddings, CRF decoder. TorchScript and ONNXRuntime do not support PyPy.
Slovnet NER is a simple model,manually implement all blocks in NumPy , use weights calculated by PyTorch. Let's apply a little NumPy magic, carefully implement the CNN block , CRF decoder , unpacking the quantized embedding takes 5 lines . Inference speed on CPU is the same as with ONNXRuntime and PyTorch, 25 news articles per second on Core i5.
The technique works on more complex models: Slovnet Morph and Slovnet Syntax are also implemented in NumPy. Slovnet NER, Morph and Syntax share a common embedding table. Let's take out the weights in a separate file, the table is not duplicated in memory and on disk:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Limitations
Natasha extracts standard entities: names, names of toponyms and organizations. The solution shows good quality on the news. How to work with other entities and types of texts? We need to train a new model. This is not easy to do. We pay for the compact size and speed of work by the complexity of model preparation. Script laptop for preparing a heavy teacher model , script laptop for a student model , instructions for preparing quantized embeddings .
Navec - compact embeddings for the Russian language

Compact models are convenient to work with. They start quickly, use little memory, and more parallel processes fit on one instance.
In NLP, 80-90% of the model weights are in the embedding table. The Navec library is part of the Natasha project, a collection of pre-trained embeddings for the Russian language. In terms of intrinsic quality metrics, they are slightly below the top solutions of RusVectores , but the size of the archive with weights is 5-6 times smaller (51MB), the dictionary is 2-3 times larger (500K words).
| Quality * | Model size, MB | Dictionary size, × 10 3 | |
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0.638-0.726 | 220.6–290.7 | 189-249 |
This is about the good old word-by-word embeddings that revolutionized NLP in 2013. The technology is still relevant today. In the Natasha project, models for parsing morphology , syntax, and extraction of named entities work on word-by-word Navec embeddings, and show quality above other open solutions .
RusVectores
For the Russian language, it is customary to use pre-trained embeddings from RusVectores , they have an unpleasant feature: the table contains not words, but pairs “word_POS-tag”. The idea is good, for the pair "oven_VERB" we expect a vector similar to "cook_VERB", "cook_VERB", and for "oven_NOUN" - "hut_NOUN", "furnace_NOUN".
In practice, it is inconvenient to use such embeddings. It is not enough to divide the text into tokens, for each you need to somehow define the POS tag. The embedding table is swelling. Instead of one word “become”, we store 6: 2 reasonable “become_VERB”, “become_NOUN” and 4 strange “become_ADV”, “become_PROPN”, “become_NUM”, “become_ADJ”. There are 195,000 unique words in a table with 250,000 entries.
Quality
Let us estimate the quality of embeddings on the semantic proximity problem. Let's take a couple of words, for each we will find an embedding vector, we will calculate the cosine similarity. Navec for similar words "cup" and "jug" will return 0.49, for "fruit" and "oven" - -0.0047. Let's collect many pairs with reference marks of similarity, calculate Spearman's correlation with our answers.
The authors of RusVectores use a small, carefully checked and revised test list of SimLex965 pairs . Let's add a fresh Yandex LRWC and datasets from the RUSSE project : HJ , RT , AE , AE2 :
| Average quality on 6 datasets | Loading time, seconds | Model size, MB | Dictionary size, × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0.719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0.653 | 0.5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0.692 | 3.3 | 220.6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0.691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0.726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0.638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0.664 | 16.4 | 2752.1 | 195 |
The quality is
hudlit_12B_500K_300d_100qcomparable or better than that of RusVectores solutions, the dictionary is 2-3 times larger, the model size is 5-6 times smaller. How did you get this quality and size?
Principle of operation
hudlit_12B_500K_300d_100q- GloVe embeddings trained for 145GB of fiction . Let's take the archive with the texts from the RUSSE project . Let's use the original implementation of GloVe in C and wrap it in a convenient Python interface .
Why not word2vec? Experiments on a large dataset are faster with GloVe. Once we calculate the collocation matrix, use it to prepare embeddings of different dimensions, choose the best option.
Why not fastText? In the Natasha project we work with news texts. There are few typos in them, the problem of OOV tokens is solved by a large dictionary. 250,000 rows in the table
news_1B_250K_300d_100qcover 98% of words in news articles.
Dictionary size
hudlit_12B_500K_300d_100q- 500,000 entries, it covers 98% of words in fiction texts. The optimal dimension of vectors is 300. A table of 500,000 × 300 of float numbers takes 578MB, the size of the archive with weights hudlit_12B_500K_300d_100qis 12 times smaller (48MB). It's about quantization.
Quantization
Replace 32-bit float numbers with 8-bit codes: [−∞, −0.86) - code 0, [−0.86, -0.79) - code 1, [-0.79, -0.74) - 2,…, [0.86, ∞) - 255. The size of the table is reduced by 4 times (143MB).
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
The data is coarse, different values -0.005 and -0.003 replace one code 127, -0.030 and -0.031 - 118
Let's replace with the code not one, but 3 numbers. We cluster all triplets of numbers from the embedding table using the k-means algorithm into 256 clusters, instead of each triplet we will store a code from 0 to 255. The table will decrease by 3 times (48MB). Navec uses the PQk-means library , it splits the matrix into 100 columns, clusters each one separately, the quality on synthetic tests will drop by 1 percentage point. It is clear about quantization in the article Product Quantizers for k-NN .
Quantized embeddings are slower than usual ones. The compressed vector must be unpacked before use. We carefully implement the procedure, apply Numpy magic, in PyTorch we use torch.gather . In Slovnet NER, access to the embedding table takes 0.1% of the total computation time.
A module
NavecEmbeddingfrom the Slovnet library integrates Navec into PyTorch models:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus is a large synthetic dataset with markup of morphology, syntax and named entities

In the Natasha project, morphology, syntax analysis and named entity extraction are made by 3 compact models: Slovnet NER , Slovnet Morph and Slovnet Syntax . The quality of solutions is 1-5 percentage points worse than that of their heavy counterparts with BERT architecture, the size is 50-75 times smaller, the speed on the CPU is 2 times higher. The models are trained on a huge synthetic Nerus dataset , in an archive of 700,000 news articles with CoNLL-U markup of morphology, syntax and named entities:
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax - primitive models. When there are 1000 examples in the training set, Slovnet NER lags behind the heavy BERT analog by 11 percentage points, when 10,000 examples - by 3 points, when 500,000 - by 1.
Nerus is the result of work, heavy models with BERT architecture: Slovnet BERT NER , Slovnet BERT Morph , Slovnet BERT Syntax . Processing 700,000 news articles takes 20 hours on the Tesla V100. We save the time of other researchers, we put the finished archive in open access. In SpaCy-Ru teach at Nerus qualitative model for the Russian-speaking SpaCy, prepare a patch in the official repository.

Synthetic markup has a high quality: the accuracy of determining morphological tags is 98%, syntactic links - 96%. For NER, F1 estimates by tokens: PER - 99%, LOC - 98%, ORG - 97%. To assess the quality, we mark up SynTagRus , Collection5 and the news slice GramEval2020 , compare the reference markup with ours, for more details in the Nerus repository . Due to errors in the markup of the syntax, there are loops and multiple roots, POS tags sometimes do not correspond to syntactic edges. It is useful to use the validator from Universal Dependencies , skip such examples.
Python package Nerus organizes a convenient interface for loading and rendering markup:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Installation instructions, examples of use , quality assessments in the Nerus repository.
Corus - a collection of links to public Russian-language datasets + functions for download

The Corus library is part of the Natasha project, a collection of links to public Russian-language NLP datasets + Python package with loader functions. List of links to sources , installation instructions and examples of use in the Corus repository.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Useful open datasets for the Russian language are so well hidden that few people know about them.
Examples of
Corpus of news articles
We want to train the language model on news articles, we need a lot of texts. The first thing that comes to mind is a news slice of the Taiga dataset (~ 1GB). Many people know about the Lenta.ru dump (2GB). Other sources are more difficult to find. In 2019, Dialogue hosted a competition for generating headlines , the organizers prepared a dump of RIA Novosti for 4 years (3.7GB). In 2018, Yuri Baburov published an upload from 40 Russian-language news resources (7.5GB). Volunteers from ODS share the archives (7GB) collected for the news agenda analysis project .
In the Corus registrylinks to those datasets tagged «news», for all sources have a function-loaders:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
We want to teach NER for the Russian language, we need annotated texts. First of all, we recall the data of the factRuEval-2016 competition . The markup has drawbacks: its complex format, entity spans overlap, there is an ambiguous "LocOrg" categories. Not everyone knows about the Named Entities 5 collection, the successor to Persons-1000 . Layout in standard format , spans do not intersect, beauty! The other three sources are known only to the most dedicated fans of the Russian-speaking NER. We will write to Rinat Gareev by mail, attach a link to his article of 2013 , in response we will receive 250 news articles with tagged names and organizations. BSNLP-2019 competition was held in 2019about NER for Slavic languages, we will write to the organizers, we will get 450 more marked texts. The WiNER project came up with the idea of making semi-automatic NER markup from Wikipedia dumps , a large download for Russian is available on Github .
Links and functions to load the register Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Collection of links
Before you get a bootloader and get into the registry, links to sources are accumulated in the section with Tickets . The collection of 30 datasets: a new version of Taiga , 568GB Russian text from Crawl the Common , reviews c Banki.ru and Auto.ru . We invite you to share your findings, create tickets with links.
Loader functions
The code for a simple dataset is easy to write yourself. The Lenta.ru dump is well-formed, the implementation is simple . Taiga is made up of ~ 15 million CoNLL-U zip files. In order for the download to work quickly, not use a lot of memory and ruin the file system, you need to get confused, carefully implement work with zip files at a low level .
For 35 sources, the Corus Python package has loader functions. The interface for accessing Taiga is no more complicated than accessing the Lenta.ru dump:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
We invite users to make pull requests, send their loader functions, a short instruction in the Corus repository.
Naeval - quantitative comparison of systems for Russian-speaking NLP

Natasha is not a scientific project, there is no goal to beat SOTA, but it is important to check the quality on public benchmarks, to try to take a high place without losing much in performance. As they do in the academy: they measure the quality, get a number, take tablets from other articles, compare these numbers with their own. This scheme has two problems:
- Forget about performance. They do not compare the size of the model, the speed of work. The emphasis is on quality only.
- Don't publish the code. There are usually a million nuances in calculating a quality metric. How exactly was it counted in other articles? Unknown.
Naeval is part of the Natasha project, a set of scripts for assessing the quality and speed of open-source tools for processing the natural Russian language:
| Task | Datasets | Solutions |
| Tokenization | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavic BERT NER , PullEnti , SpaCy , Stanza , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Let's take a closer look at the NER problem below.
Datasets
There are 5 public benchmarks for the Russian-speaking NER: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , WiNER . Source links are collected in the Corus registry . All datasets consist of news articles, substrings with names, names of organizations and toponyms are marked in the texts. What could be easier?
All sources have a different markup format. Collection5 uses the Standoff format of the Brat , Gareev and WiNER utilities - different dialects of BIO markup , BSNLP-2019 has its own format , factRuEval-2016 also has its own non-trivial specification... Naeval converts all sources to a common format. The markup consists of spans. Span - three: entity type, beginning and end of substring.
Entity types. factRuEval-2016 and Collection5 separately mark the semi-names-semi-organizations: "Kremlin", "EU", "USSR". BSNLP-2019 and WiNER highlight the names of the events: "Championship of Russia", "Brexit". Naeval adapts and removes some of the tags, leaves the reference tags PER, LOC, ORG: names of people, names of toponyms and organizations.
Nested spans. In factRuEval-2016, the spans overlap. Naeval simplifies the markup:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Models
Naeval compares 12 open solutions to the Russian NER problem. All tools are wrapped in Docker containers with a web interface:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Some solutions are so difficult to launch and configure that few people use them. PullEnti , a sophisticated rules-based system, took first place in the factRuEval competition in 2016. The tool is distributed as an SDK for C #. Work on Naeval resulted in a separate project with a set of wrappers for PullEnti: PullentiServer is a C # web server, pullenti-client is a Python client for PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
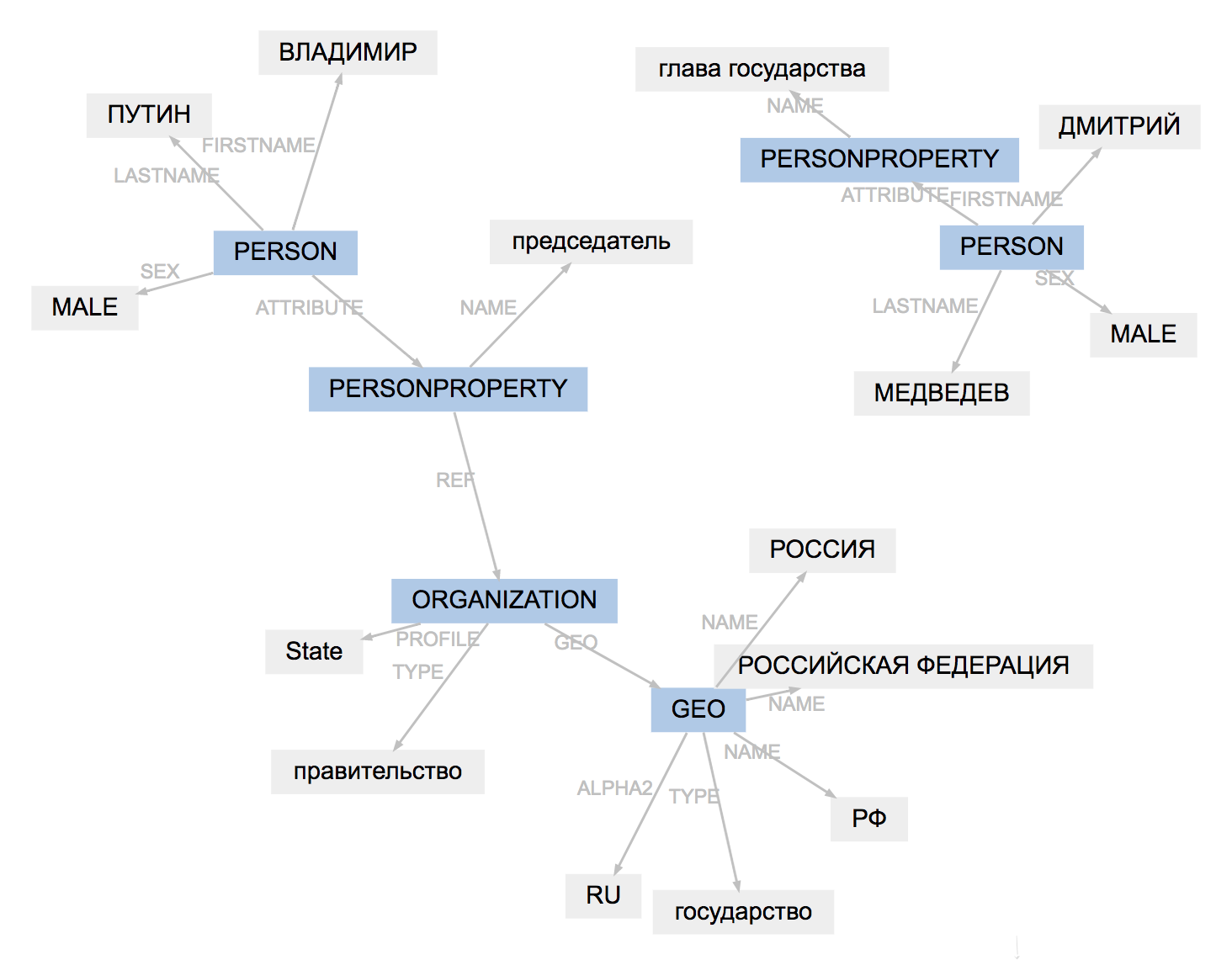
The markup format for all tools is slightly different. Naeval loads results, adapts entity types, simplifies the structure of spans:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
The result of PullEnti's work is more difficult to adapt than the factRuEval-2016 markup. The algorithm removes the PERSONPROPERTY tag, splits the nested PERSON, ORGANIZATION and GEO into non-overlapping PER, LOC, ORG.
Comparison
For each pair "model, dataset" Naeval calculates the F1-measure by tokens , publishes a table with quality scores .
Natasha is not a scientific project, the practicality of the solution is important for us. Naeval measures start time, run speed, model size and RAM consumption. Table with results in the repository .
We prepared datasets, wrapped 20 systems in Docker containers and calculated metrics for 5 other tasks of Russian-language NLP, results in the Naeval repository: tokenization , segmentation into sentences , embeddings , morphology and syntax analysis .
Yargy- —

Yargy parser is an analogue of the Yandex Tomita parser for Python. Installation instructions , example of use , documentation in the Yargy repository. The rules for extracting entities are described using context-free grammars and dictionaries. Two years ago I wrote on Habr an article about Yargy and the Natasha library , talking about solving the NER problem for the Russian language. The project was well received. Yargy-parser replaced Tomita in large projects inside Sberbank, Interfax and RIA Novosti. A lot of educational materials have appeared. A large video from a workshop in Yandex, an hour and a half about the process of developing grammars with examples:
The documentation was updated, I combed the introductory section and reference book . Most importantly, the Cookbook has appeared - a section with useful practices. It contains answers to the most frequently asked questions from t.me/natural_language_processing :
- how to skip part of the text ;
- how to submit tokens, not text ;
- what to do if the parser slows down .
Yargy parser is a complex tool. The Cookbook describes the non-obvious points that come up when working with large sets of rules:
We have several large services running in the Yargy lab. I re-read the code, collected patterns in the Cookbook that are not described in the public:
- generation of rules ;
- inheritance fact (especially useful, no solution in practice can do without this technique).
After reading the documentation, it's helpful to look at the repository with examples :
The Natasha project also has a natasha-usage repository . This is where the code of the Yargy parser users published on Github goes. 80% of the links are educational projects, but there are also informative examples:
- analysis of the feed on the work of the metro in St. Petersburg ;
- parsing advertisements for renting housing in social networks ;
- extraction of attributes from the names of auto tires ;
- parsing vacancies from the jobs channel of the ODS chat ;
The most interesting cases of using the Yargy parser, of course, are not publicly published on Github. Write to PM if the company uses Yargy and, if you don't mind, add your logo to natasha.github.io .
Ipymarkup - visualization of named entity markup and syntactic relationships

Ipymarkup is a primitive library needed for highlighting substrings in text, NER visualization. Installation instructions , example of use in the Ipymarkup repository. The library is similar to displaCy and displaCy ENT , invaluable for debugging grammars for Yargy parser.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

The Natasha project has a solution to the parsing problem . It was necessary not only to highlight words in the text, but also to draw arrows between them. There are a lot of ready-made solutions, there is even a scientific article on the topic .
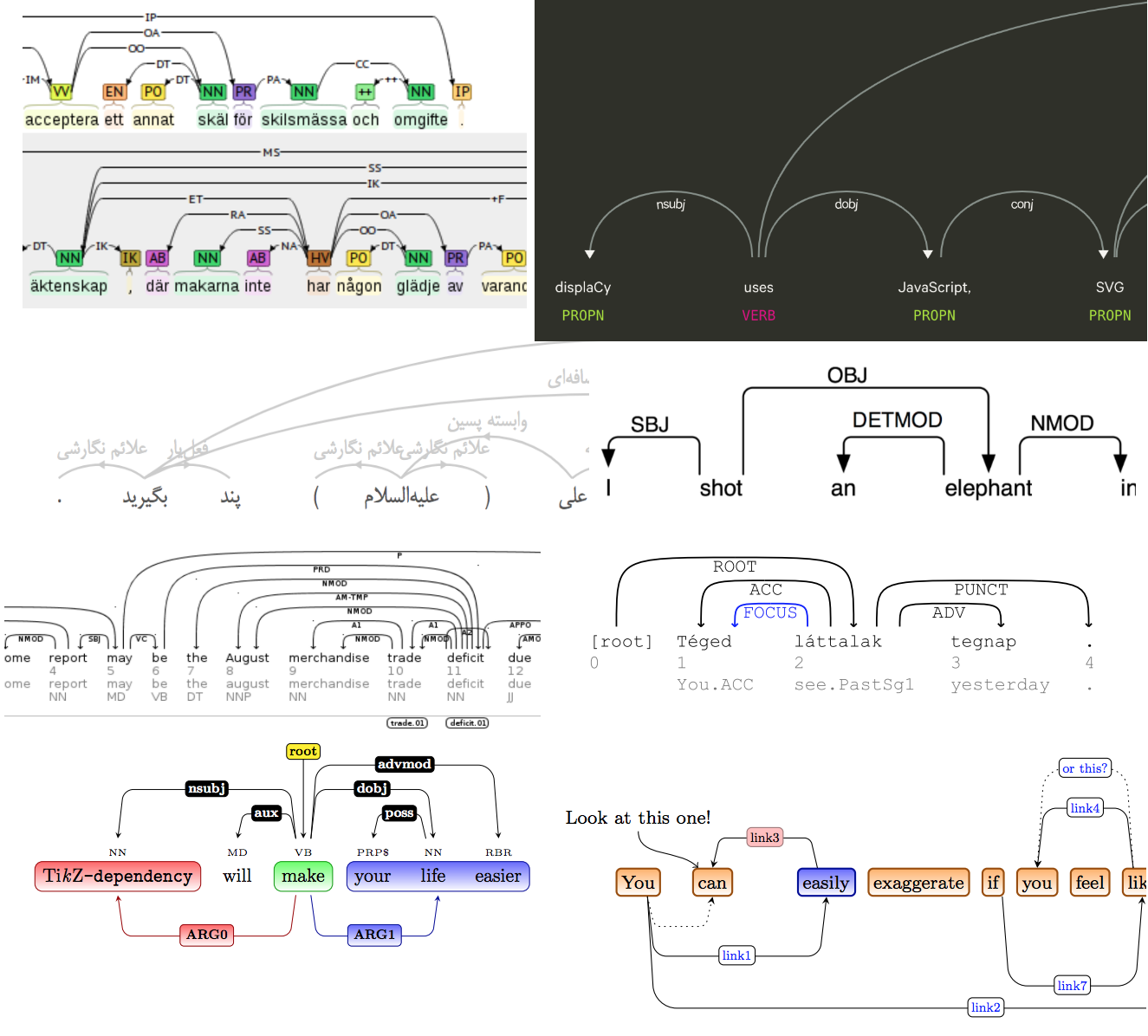
Of course, none of the existing ones came up, and one day I got really confused, applied all the famous magic of CSS and HTML, added a new visualization to Ipymarkup. Instructions for use in the dock.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
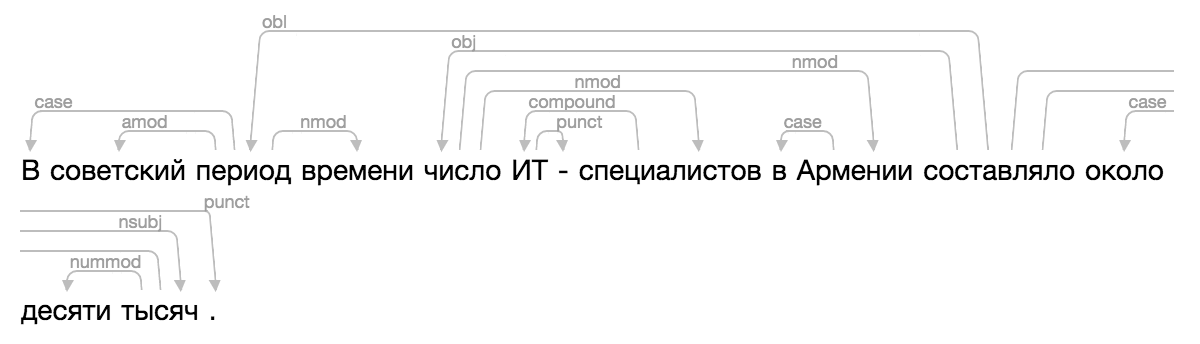
Now in Natasha and Nerus it is convenient to see the results of parsing.
