Much in the life of a project depends on how well thought out the object model and base structure at the start.
The generally accepted approach has been and remains various options for combining the “star” scheme with the third normal form. As a rule, according to the principle: initial data - 3NF, showcases - star. This time-tested approach, backed up by a lot of research, is the first (and sometimes the only) thing that an experienced DWH person thinks of when thinking about what an analytical repository should look like.
On the other hand, business in general and customer requirements in particular tend to change quickly, and data grows both “in depth” and “in breadth”. And this is where the star's main drawback manifests itself - limited flexibility .
And if in your quiet and cozy life as a DWH developer, suddenly:
- the task arose “to do at least something quickly, and then we'll see”;
- a rapidly developing project appeared, with the connection of new sources and reworking of the business model at least once a week;
- a customer has appeared who does not imagine how the system should look and what functions it should perform in the end, but is ready for experiments and consistent refinement of the desired result with a consistent approach to it;
- the project manager dropped in with the good news: "And now we have agile!"
Or if you are just curious to know how else you can build storage - welcome under the cat!

What does flexibility mean?
First, let's define what properties the system must have in order to be called “flexible”.
Separately, it should be noted that the described properties should relate specifically to the system , and not to the process of its development. Therefore, if you wanted to read about Agile as a development methodology, it is better to read other articles. For example, right there, on Habré, there is a lot of interesting materials (both survey and practical , and problematic ).
This does not mean that the development process and the structure of the CD are not at all connected. In general, it should be much easier to develop Agile storage of flexible architecture. However, in practice, there are more options with Agile development of classic DWH by Kimball and DataVault by waterfall than happy coincidences of flexibility in its two hypostases on one project.
So, what capabilities should flexible storage have? There are three points here:
- Early delivery and quick revision means that ideally, the first business result (for example, the first working reports) should be received as early as possible, that is, even before the entire system is fully designed and implemented. Moreover, each subsequent revision should also take as little time as possible.
- — , . — , , . , , — .
- Constant adaptation to changing business requirements - the overall object structure should be designed not just taking into account possible expansion, but with the expectation that the direction of this next expansion might not even dream of you at the design stage.
And yes, meeting all these requirements in one system is possible (of course, in certain cases and with some caveats).
Below I will consider two of the most popular agile design methodologies for HD - Anchor model and Data Vault.... Behind brackets are such excellent techniques as EAV, 6NF (in its pure form) and everything related to NoSQL solutions - not because they are somehow worse, and not even because in this case the article would threaten to acquire the volume of the average dissera. It's just that all this refers to solutions of a slightly different class - either to techniques that you can apply in specific cases, regardless of the general architecture of your project (like EAV), or to globally other paradigms of information storage (such as graph databases and other options NoSQL).
Problems of the "classical" approach and their solutions in agile methodologies
By the "classic" approach I mean a good old star (regardless of the specific implementation of the underlying layers, forgive me the followers of Kimball, Inmon and CDM).
1. Rigid cardinality of ties
This model is based on a clear separation of data into dimensions (Dimension) and facts (Fact) . And this, damn it, is logical - after all, data analysis in the overwhelming majority of cases comes down to just the analysis of certain numerical indicators (facts) in certain sections (dimensions).
In this case, links between objects are laid in the form of links between tables by a foreign key. This looks quite natural, but immediately leads to the first limitation of flexibility - a rigid definition of the cardinality of connections .
This means that at the design stage of tables, you must define precisely for each pair of related objects whether they can be many-to-many, or only 1-to-many, and "in which direction." This directly determines which of the tables will have a primary key and which will have an external key. Changing this attitude when new requirements are received will most likely lead to a redesign of the base.
For example, while designing the “cashier's check” object, you, relying on the oaths of the sales department, laid down the possibility of one promotion acting on several check positions (but not vice versa):
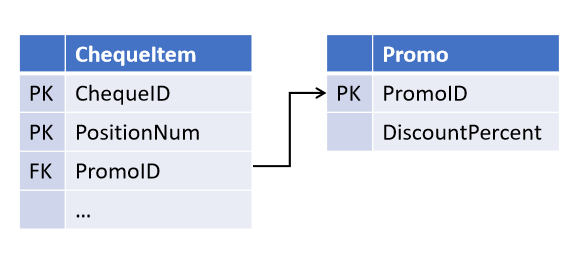
And after a while, colleagues introduced a new marketing strategy, in which several promotions can act simultaneously on the same position . And now you need to modify the tables by selecting the link into a separate object.
(All derived objects, in which a promo check is performed, now also need to be improved).
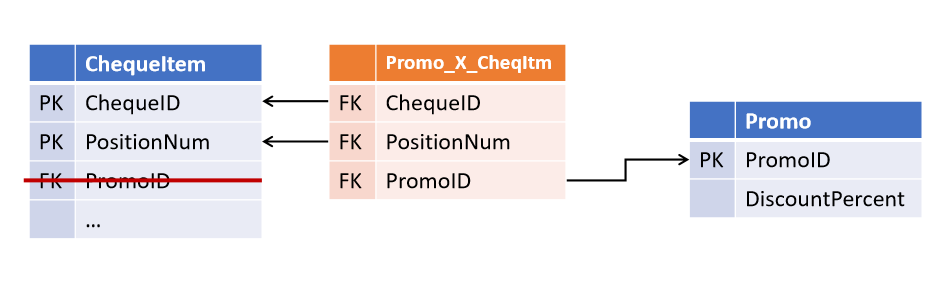
Links in the Data Vault and Anchor Model It
turned out to be quite simple to avoid this situation: you
This approach was proposed by Dan Linstedt as part of the Data Vault paradigm and is fully supported by Lars Rönnbäck in the Anchor Model .
As a result, we get the first distinguishing feature of agile methodologies:
Relationships between objects are not stored in the attributes of parent entities, but are a separate type of object.The Data Vault are table-ligament called Link , and the Anchor Models - the Tie . At first glance, they are very similar, although their differences are not limited to the name (which will be discussed below). In both architectures, link tables can link any number of entities (not necessarily 2).
At first glance, this redundancy provides significant flexibility for modifications. Such a structure becomes tolerant not only to changing the cardinality of existing links, but also to adding new ones - if now the check position also has a link to the cashier who punched it, the appearance of such a link will simply become an add-on over existing tables without affecting any existing objects and processes.

2. Data duplication
The second problem, solved by flexible architectures, is less obvious and is inherent primarily to measurements of the SCD2 type (slowly changing dimensions of the second type), although not only to them.
In a classic store, a dimension is usually a table that contains a surrogate key (as PK) and a set of business keys and attributes in separate columns.

If the dimension is versioned, version time bounds are added to the standard set of fields, and multiple versions appear per line in the source in the store (one for each change to the versioned attributes).
If a dimension contains at least one frequently changing versioned attribute, the number of versions of such a dimension will be impressive (even if the other attributes are not versioned, or never change), and if there are several such attributes, the number of versions can grow exponentially from their number. Such a dimension can take up a significant amount of disk space, although most of the data stored in it is simply duplicate values of unchanged attributes from other rows.

At the same time, denormalization is also very often used - some of the attributes are intentionally stored as a value, and not a reference to a directory or another dimension. This approach speeds up data access by reducing the number of joins when accessing a dimension.
As a rule, this leads to the fact thatthe same information is stored simultaneously in several places . For example, information about the region of residence and belonging to the customer's category can be simultaneously stored in the dimensions “Customer” and the facts “Purchase”, “Delivery” and “Calls to the call center”, as well as in the linking table “Customer - Customer manager”.
In general, the above applies to regular (non-versioned) measurements, but in versioned ones they can have a different scale: the appearance of a new version of an object (especially in hindsight) leads not just to updating all related tables, but to the cascading appearance of new versions of related objects - when Table 1 is used to construct Table 2, and Table 2 is used to construct Table 3, etc. Even if none of the attributes of Table 1 participate in the construction of Table 3 (and other attributes of Table 2 obtained from other sources are involved), a versioned update of this construction will at least lead to additional overhead costs, and at most - to unnecessary versions in Table 3. which has nothing to do with it and further along the chain.

3. Non-linear complexity of revision
In addition, each new mart, built on top of another, increases the number of places in which data can "diverge" when making changes to ETL. This, in turn, leads to an increase in the complexity (and duration) of each subsequent revision.
If the above concerns systems with rarely modified ETL processes, you can live in such a paradigm - you just need to make sure that new modifications are correctly introduced into all related objects. If revisions occur frequently, the likelihood of accidentally "missing" a few links increases significantly.
If, in addition, we take into account that “versioned” ETL is much more complicated than “non-versioned”, it becomes quite difficult to avoid mistakes with frequent revision of this entire economy.
Storing objects and attributes in the Data Vault and Anchor Model
The approach proposed by the authors of agile architectures can be formulated as follows:
It is necessary to separate what changes from what remains unchanged. That is, keep keys separate from attributes.At the same time, you should not confuse a non-versioned attribute with an unchanging one : the first does not store the history of its change, but it can change (for example, when an input error is corrected or new data is received); the second never changes.
The points of view on what exactly can be considered immutable in the Data Vault and the Anchor Model differ.
From the point of view of the Data Vault architecture , the entire set of keys can be considered unchanged - natural (TIN of the organization, product code in the source system, etc.) and surrogate. In this case, the remaining attributes can be divided into groups by source and / or frequency of changes, and a separate table with an independent set of versions can be maintained for each group .
In the paradigmAnchor Model is considered immutable only entity surrogate key . Everything else (including natural keys) is just a special case of its attributes. At the same time, all attributes by default are independent from each other , therefore, a separate table must be created for each attribute .
In Data Vault, tables containing entity keys are called Hubs . Hubs always contain a fixed set of fields:
- Entity natural keys
- Surrogate key
- Link to source
- Record adding time
Entries in Hubs are never changed and have no version . Outwardly, hubs are very similar to tables of the ID-map type used in some systems to generate surrogates, however, it is recommended to use not an integer sequence as surrogates in Data Vault, but a hash from a set of business keys. This approach simplifies loading links and attributes from sources (you don't need to join the hub to get a surrogate, you just need to calculate the hash from the natural key), but can cause other problems (related, for example, to collisions, case and non-printable characters in string keys, etc.) .p.), therefore it is not generally accepted.
All other attributes of entities are stored in special tables called Satellites... One hub can have several satellites storing different sets of attributes.
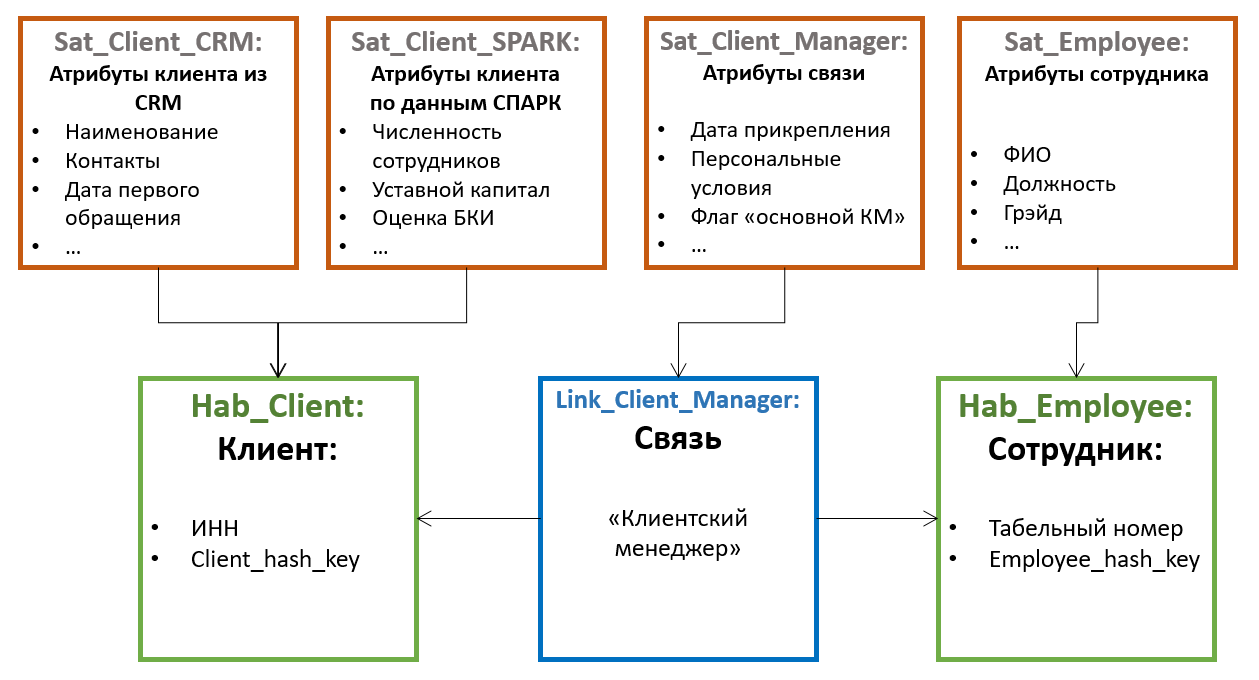
The distribution of attributes among satellites is based on the principle of joint change - one satellite can store non-versioned attributes (for example, date of birth and SNILS for an individual), in another - rarely changing versioned ones (for example, last name and passport number), in the third - often changing (for example, delivery address, category, date of last order, etc.). In this case, versioning is carried out at the level of individual satellites, and not the entity as a whole; therefore, it is advisable to distribute the attributes so that the intersection of versions within one satellite is minimal (which reduces the total number of stored versions).
Also, in order to optimize the data loading process, attributes obtained from various sources are often placed in separate satellites.
Satellites communicate with the Hub using a foreign key (which corresponds to a 1-to-many cardinality). This means that multiple attribute values (for example, multiple contact phone numbers for one customer) are supported by this "default" architecture.
In the Anchor Model, tables that hold keys are called Anchor . And they keep:
- Surrogate keys only
- Link to source
- Record adding time
Natural keys are considered ordinary attributes from the point of view of the Anchor Model . This option may seem more difficult to understand, but it gives a lot more room for object identification.

For example, if data about the same entity can come from different systems, each of which uses its own natural key. In the Data Vault, this can lead to rather cumbersome structures of several hubs (one per source + the unifying master version), while in the Anchor model, the natural key of each source falls into its own attribute and can be used during loading independently of all the others.
But there is one insidious point here: if attributes from different systems are combined in one entity, most likely there are somerules of "gluing" , according to which the system must understand that records from different sources correspond to one instance of an entity.
In Data Vault, these rules will most likely determine the formation of the “surrogate hub” of the master entity and will not in any way affect the Hubs that store the natural keys of sources and their original attributes. If at some point the splicing rules change (or an update of the attributes by which it is made) comes, it will be enough to re-form the surrogate hubs.
In the Anchor model, however, such an entity will most likely be stored in a single anchor.... This means that all attributes, regardless of which source they come from, will be bound to the same surrogate. Separating erroneously merged records and, in general, keeping track of the relevance of merging in such a system can be significantly more difficult, especially if the rules are complex enough and often change, and the same attribute can be obtained from different sources (although it is definitely possible, since each the attribute version retains a link to its source).
In any case, if your system is supposed to implement the functionality of deduplication, merging records and other MDM elements, it is worth taking a close look at the aspects of storing natural keys in agile methodologies. The more cumbersome Data Vault design is likely to suddenly prove more secure in terms of merge errors.
The anchor model also provides for an additional type of object called a Knot, in fact it is a special degenerate kind of anchor that can contain only one attribute. The nodes are supposed to be used for storing flat directories (for example, gender, marital status, customer service category, etc.). Unlike Anchor, Node has no associated attribute tables, and its only attribute (name) is always stored in the same table with the key. Nodes are linked to Anchors by Tie tables, just like anchors are to each other.
There is no unequivocal opinion about the use of Nodes. For example, Nikolai Golov , who is actively promoting the use of the Anchor model in Russia, believes (not unreasonably) that for no reference book it is impossible to say for sure that it will always be static and single-level, therefore it is better to use a full-fledged Anchor for all objects at once.
Another important difference between the Data Vault and the Anchor model is the presence of attributes for the links :
In the Data Vault, the Links are the same full-fledged objects as Hubs, and can haveown attributes . In the Anchor model, Links are used only to connect Anchors and cannot have their own attributes . This difference gives significantly different approaches to modeling facts , which will be discussed below.
Storing facts
Before that, we talked mainly about modeling measurements. With the facts, the situation is a little less straightforward.
In Data Vault, a typical object for storing facts is a Link , in the Satellites of which real indicators are added.
This approach looks intuitive. It provides easy access to the analyzed indicators and is generally similar to a traditional fact table (only the indicators are stored not in the table itself, but in the “adjacent” one). But there are also pitfalls: one of the typical model modifications - expanding the fact key - necessitates adding a new foreign key to Link . And this, in turn, "breaks" modularity and potentially causes the need for improvements to other objects.
In the Anchor ModelA link cannot have its own attributes, so this approach will not work - absolutely all attributes and indicators must be bound to one specific anchor. The conclusion from this is simple - each fact also needs its own anchor . For some of what we are used to taking as facts, it may look natural - for example, the fact of a purchase is perfectly reduced to the object “order” or “check”, a visit to a site - to a session, etc. But there are also facts for which it is not so easy to find such a natural “carrier object” - for example, the remains of goods in warehouses at the beginning of each day.
Accordingly, there are no problems with modularity when expanding the fact key in the Anchor model (you just need to add a new Link to the corresponding Anchor), but the design of the model to display facts is less unambiguous, “artificial” Anchors may appear that reflect the business object model is not obvious.
How flexibility is achieved
The resulting construction in both cases contains significantly more tables than the traditional dimension. But it can take up significantly less disk space with the same set of versioned attributes as a traditional dimension. Naturally, there is no magic here - it's all about normalization. By distributing attributes across Satellites (in the Data Vault) or separate tables (Anchor Model), we reduce (or completely eliminate) duplication of values of some attributes when changing others .
For the Data Vault, the gain will depend on the distribution of attributes across the Satellites, and for the Anchor Model , it will be almost directly proportional to the average number of versions per measurement object.
However, gaining space is an important but not the main advantage of storing attributes separately. Together with storing links separately, this approach makes the repository a modular design . This means that the addition of both individual attributes and entire new subject areas in such a model looks like an add- on over an existing set of objects without changing them. And this is exactly what makes the described methodologies flexible.
It also resembles the transition from piece production to mass production - if in the traditional approach each model table is unique and requires separate attention, then in flexible methodologies it is already a set of typical “details”. On the one hand, there are more tables, the processes of loading and fetching data should look more complicated. On the other hand, they become typical . This means they can be automated and managed by metadata . The question “how are we going to lay it?”, The answer to which could take up a significant part of the design of improvements, is now simply not worth it (as well as the question of the impact of model changes on working processes).
This does not mean that analysts are not needed in such a system at all - someone still has to work through a set of objects with attributes and figure out where and how to load all this. But the amount of work, as well as the probability and cost of an error, is significantly reduced. Both at the stage of analysis and during the development of ETL, which in an essential part can be reduced to editing metadata.
Dark side
All of the above makes both approaches really flexible, technologically advanced and suitable for iterative refinement. Of course, there is also a “barrel of ointment”, which I think you are already guessing about.
Data decomposition, which is the basis for modularity of flexible architectures, leads to an increase in the number of tables and, accordingly, the overhead of joins when fetching. In order to simply get all the attributes of a dimension, one select is sufficient in the classical repository, and a flexible architecture will require a number of joins. Moreover, if for reports all these joins can be written in advance, then analysts who are accustomed to writing SQL by hand will suffer doubly.
There are several facts that make this situation easier:
When working with large dimensions, all of its attributes are almost never used at the same time. This means that there may be fewer joins than it seems when you first look at the model. In the Data Vault, you can also factor in the expected sharing frequency when distributing attributes across satellites. At the same time, the Hubs or Anchors themselves are needed primarily for generating and mapping surrogates at the loading stage and are rarely used in requests (especially for Anchors).
All joins are by key.In addition, a more “concise” way of storing data reduces the overhead of scanning tables where necessary (for example, when filtering by attribute value). This can lead to the fact that fetching from a normalized database with a bunch of joins will be even faster than scanning one heavy dimension with many versions per line.
For example, here in this article there is a detailed comparative performance test of the Anchor Model with a selection from a single table.
Much depends on the engine. Many modern platforms have internal join optimization mechanisms. For example, MS SQL and Oracle are able to “skip” joins to tables if their data is not used anywhere except for other joins and does not affect the final selection (table / join elimination), while MPP Vertica isexperience of colleagues from Avito , proved to be an excellent engine for the Anchor model, taking into account some manual optimization of the query plan. On the other hand, keeping the Anchor Model, for example, on Click House, which has limited join support, doesn't seem like a good idea for now.
In addition, there are special techniques for both architectures to make data easier to access (both from a query performance perspective and for end users). For example, Point-In-Time tables in the Data Vault or special table functions in the Anchor Model.
Total
The main essence of the considered flexible architectures is the modularity of their “design”.
It is this property that allows:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- Due to the decomposition into standard elements, ETL processes in such systems look the same type, their writing lends itself to algorithmicization and, ultimately, automation .
The price of this flexibility is performance . This does not mean that it is impossible to achieve acceptable performance on such models. More often than not, you just need more effort and attention to detail to achieve the metrics you want.
Applications
Data Vault Entity Types

Read more about Data Vault:
Dan Listadt's site
All about Data Vault in Russian
About Data Vault on Habré
Anchor Model Entity Types

More information about Anchor Model:
Site of Anchor Model creators
An article about the experience of implementing the Anchor Model in Avito
A summary table with the common features and differences of the considered approaches:
